一 : 机器学习笔记 Week3 逻辑回归
学习笔记(Machine Learning) Week3



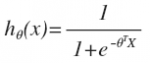




 带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convex function)。
带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convex function)。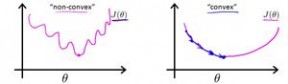
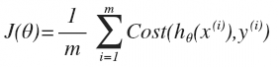


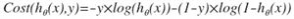



 yiz
yiz 。接着,类似地第我们选择另一个类标记为正向类(y=2),再将其它类都标记为负向类,将这个模型记作
。接着,类似地第我们选择另一个类标记为正向类(y=2),再将其它类都标记为负向类,将这个模型记作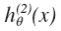 ,依此类推。
,依此类推。

 机器学习笔记 Week8 聚类
机器学习笔记 Week8 聚类 机器学习笔记 Week9 异常检测
机器学习笔记 Week9 异常检测 机器学习笔记 Week7 支持向量机
机器学习笔记 Week7 支持向量机 笔记 逻辑学导论 Week3
笔记 逻辑学导论 Week3 笔记 逻辑学导论 Week5
笔记 逻辑学导论 Week5二 : 逻辑斯谛回归/曲线(方程、模型)
(2011-02-16 15:15:19)标签:校园 | 分类: 工作篇 |
S型曲线(S-Curve) S型曲线(S-Curve)多存在于分类评定模型(Logitmodel),逻辑回归(Logisticregression)模型,属于多重变数分析范畴,是社会学、生物统计学、临床、数量心理学、市场营销等统计实证分析的常用方法。
难道一切真的都得依照S型曲线发展,社会、经济总有一天会衰败吗?难道我们就不能阻止这个让人失望的结局发生吗?难道我们就不能阻止这个让人失望的结局发生吗?而且,除了徐熙娣的S型曲线之外,我们也可以有查尔斯•汉迪组合式人生。
十九世纪末,法国的社会学家塔尔德(GabrielTarde)观察到,一个新思想的采纳率在时间中遵循一种S型曲线。1890年,塔尔德的《模仿律》》(《The Laws ofImitation 》)这部著作影响了两个当代的研究传统,即扩散理论和社会学习理论。也有人说,塔尔德实际是提出了经济增长的S型曲线。
塔尔德认为,模拟是最基本的社会关系。一切社会过程无非是个人之间的互动。每一种人的行动都在重复某种东西,是一种模拟。社会事实是由模拟而传播、交流的个人情感与观念。
塔尔德(1843—1904)是一名律师和法官,后来成为一名社会学家。他还撰写了《意见和大众》(1901)、《隐蔽的人》(1905)等著作,是有关未来社会的风气变化的未来主义乌托邦。
塔尔德把社会规律还原为支配、模拟的规律,社会互动还原为个人间的心理联系,认为社会学即是研究这种心理联系的“精神间的心理学”。这种思路应该追溯到S型曲线控制法(逻辑斯谛曲线)及其早期的应用。
1833年,费尔许尔斯特以其著名的逻辑斯谛曲线描述人口增长速度与人口密度的关系,把数学分析方法引入生态学。
历史上,当孟德尔提出其著名的遗传定律时,也曾遇到过无法解释的尴尬:按照他的理论,通过简单数学计算将得出,某一生物群体中的表现型比例将会逐渐呈现一边倒的现象。就在这一理论遭到质疑的时候,数学家哈代等人建立起了数学模型,对其定律进行了修正与论证,得到了“遗传不会影响基因频率”的正确结论。
数学不仅拯救了生物学支柱之一的孟德尔定律,科学家还通过它得到了费尔许尔斯特—珀尔方程和洛特卡—沃尔泰拉方程。费尔许尔斯特—珀尔方程描述生物种群增长的规律,可以帮助人们计算出人口增长速度与人口密度的关系;而洛特卡-沃尔泰拉方程则帮助人们认识到农药的滥用在毒杀害虫的同时也杀死了害虫的天敌,如今在农作物的防病虫害斗争中发挥着重要作用。
马尔萨斯于1798年发表的《人口论》一书造成了广泛的影响。费尔许尔斯特1833年以其著名的逻辑斯谛曲线描述人口增长速度与人口密度的关系。
S型曲线控制法逻辑斯谛方程,即常微分方程:dN/dt=rN(K-N)/K.
字母含义
式中N为种群个体总数,t为时间,r为种群增长潜力指数,K为环境最大容纳量。
意义
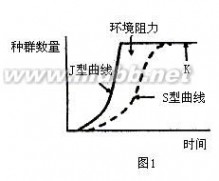
当一个物种迁入到一个新生态系统中后,其数量会发生变化.假设该物种的起始数量小于环境的最大容纳量,则数量会增长.增长方式有以下两种:
(1)J型增长若该物种在此生态系统中无天敌,且食物空间等资源充足(理想环境),则增长函数为N(t)=n(p^t).其中,N(t)为第t年的种群数量,t为时间,p为每年的增长率(大于1).图象形似J形。
(2)S型增长若该物种在此生态系统中有天敌,食物空间等资源也不充足(非理想环境),则增长函数满足逻辑斯谛方程。图象形似S形.
即按照对应时间点给出的累计的成本、工时或其他数值的图形。该名称来自曲线的形状如英文字母S(起点和终点处平缓,中间陡峭),项目开始时缓慢,中期加快,收尾平缓的情况造成这种曲线。
通常人们将“Logistic回归”、“Logistic模型”、“Logistic回归模型”及“Logit模型”的称谓相互通用,来指同一个模型,唯一的区别是形式有所不同:logistic回归是直接估计概率,而logit模型对概率做了Logit转换。不过,SPSS软件好像将以分类自变量构成的模型称为Logit模型,而将既有分类自变量又有连续自变量的模型称为Logistic回归模型。至于是二元还是多元,关键是看因变量类别的多少,多元是二元的扩展。
1979年,美国城市地理学家诺瑟姆Ray.M.Northam发现并提出了“诺瑟姆曲线”,这个曲线表明:发达国家的城市化大体上都经历了类似正弦波曲线上升的过程。
城市化进程呈现一条被拉平的倒S型曲线,当城市化超过30%时,进入了快速提升阶段。城市化的发展在时间和空间两个维度展开,表现为阶段性和地区差异。
诺瑟姆在总结欧美城市化发展历程的基础上,把城市化的轨迹概括为拉长的S型曲线。他把城市化进程分为三个阶段:第一是城市化起步阶段,城市化水平较低,发展速度也较慢,农业占据主导地位;第二是城市化加速阶段,人口向城市迅速聚集,城市化推进很快。随着人口和产业向城市集中,市区出现了劳动力过剩、交通拥挤、住房紧张、环境恶化等问题。小汽车普及后,许多人和企业开始迁往郊区,出现了郊区城市化现象;第三是城市化成熟阶段,城市化水平比较高,城市人口比重的增长趋缓甚至停滞。在有些地区,城市化地域不断向农村推进,一些大城市的人口和工商业迁往离城市更远的农村和小城镇,使整个大城市人口减少,出现逆城市化现象。
“前景理论”由丹尼尔•卡尼曼 (Daniel .Kahneman )教授提出,获得2002 年诺贝尔经济学奖。卡尼曼通过一个s型价值函数更为准确的描述了决策过程,并表明非理性行为可以被识别及预测。
长期以来,正统经济学一直以“理性人”为理论基础,通过一个个精密的数学模型构筑起完美的理论体系。而卡尼曼教授等人的行为经济学研究则从实证出发,从人自身的心理特质、行为特征出发,去揭示影响选择行为的非理性心理因素,其矛头直指正统经济学的逻辑基础——理性人假定。
瑞典皇家科学院称,卡尼曼因为“将来自心理研究领域的综合洞察力应用在了经济学当中,尤其是在不确定情况下的人为判断和决策方面作出了突出贡献”,摘得2002年度诺贝尔经济学奖的桂冠。
而1947年HerbertSimon(1978年荣获诺贝尔经济学奖)考虑到人的心理因素在经济行为中的作用,提出“有限理性”理论。他认为,在当今的复杂社会里,一个人不可能获得所有必要的信息来做出合理的决定。
空雨衣是一个象征。在这个变化迅猛的世界,竞争日益激烈,以企业为主要代表的组织忙于在激烈的竞争中求生存,因此变得越来越机械、越来越没有人性,越来越强迫员工长时间工作;而个人要在激烈的竞争中求得生存与发展,只有疲于奔命,许多人实际上除了工作外几乎不再有别的自由空间,即双休日、节假日也都在公司中度过,对他们来说,人生就是完成一项又一项永远也完成不了的任务。空雨衣是我们时代的最急迫的悖论的象征。
查尔斯•汉迪(CharlesHandy)的《空雨衣》(又译为《觉醒的年代》)在《觉醒的年代》提出了三种管理思想架构:一是在持续成长的同时施行新变革的“S型曲线”,二是必须在做与做得到之间取得平衡的“甜甜圈原理”,三是充分运用双赢艺术的“中国式契约”。
汉迪毕业于牛津大学,并曾在麻省理工学院的史隆管理学院追随本尼斯、雪恩、阿奇利斯等大师进行组织研究。曾任教于英国伦敦商学院,担任过英国石油公司顾问、以及英国皇家艺术及工商促进会主席。
中国人民大学出版社组织出版了一批查尔斯•汉迪的著作,有《思想者》、《觉醒的年代》、《饥
饿的灵魂》、《个人与组织的未来》、《工作与生活的未来》、《经理人制造》、《组织的概念》与《大师论大师》。
在组合式人生的时间分配上,他及妻子伊丽沙白每年分配150天用于纯粹的创造性工作,写作和摄影以及相关的阅读与研究,100天用于商业和管理活动,基本是到国外做巡回演讲,再拿30天时间用于各种志愿性工作,除此之外还有85天自由时间,可用于每周的休息和应对突发事件,这种安排很好地实现了生活的平衡。
汉迪对政治和社会的兴趣跟管理一样大,属通识型学者。他晚年的著述是糅合了市场经济、企业文化与人道观点,低声地在提倡营利,大声地在鼓吹对人的尊重。近年来他一直在探讨:什么样的工作方式与生活方式是最适合21世纪的社会?汉迪在西方社会一生的体验使他相信:个人的自由与独立,要与财富的分享、社会的正义相互平衡。汉迪不仅是管理大师,更是人道主义者。
在Photoshop中,一般指用曲线调整时候,S形是提高对比度.,反s形正好相反。
S函数是SystemFunction的简称。在很多情况下,Simulink现有的模块已经不能满足用户的需要,这时可以自己编写相应的代码来完成对模块功能的需求。S函数则提供了一个代码和Simulink模块之间的接口,用来实现对模块的编程。其中S函数的代码可以用Matlab语言编写,也可以是C、C++、Ada、Fortran等语言编写。
逻辑斯蒂回归模型
8.逻辑斯蒂模型
200年前马尔萨斯提出的人口增长指数模型,在较短时间内比较符合实际情况,但从长期看不可能永远按相同的(相对)增长率增长.事实上,人口较少时增长越来越快,但人口数量较大时,由于资源、环境、战争、灾害等因素,人口增长率会慢下来.因此必须修改马尔萨斯的模型.实际上主要修改增长率是常数的这个基本假设.19世纪30年代比利时生物数学家维尔豪斯提出了修改的增长模型¾¾阻滞增长模型,也称逻辑斯蒂模型.其基本假设是:人口的增长率是关于人口数量的线性递减函数.
现设初始人口数量为y(0)=y0,y(t)表示时刻t的人口数,增长率r(y)=r0-sy为y的线性递减函数,其中r0,s是正的常数,见上图.
我们称r0为固有增长率,即人口很少(y»0)时的增长率.为确定s的意义,引入资源、环境等条件所能容纳的最大人口数量ym,称为人口容量.在y=ym时人口不再增长,即r(ym)=0.于是s=.现在,(相对)增长率是
r(y)=r0-y,从而
,
即 ,我们得到模型方程
,
其中因子体现了对人口增长的阻滞作用,y越大,因子越小,阻滞作用越大,增长越慢.现求解此方程:
分离变量:.
积分:
,
得通解
,
代入初值y0=y(0),得C=,
得特解
.
例2.7.17 已知1960年的世界人口为29.8亿,当时增长率是1.85%.假如某些人口学家估计世界人口的固有增长率r0=2.9%,试估计世界人口容量ym,并估算2000年的世界人口数.
解.以1960年为初始年份:t=0.
现y0=29.8(亿),r0=0.029,r(29.8)=0.0185.
故r(29.8)=0.029-29.8s,解出
,
而
»82.3(亿).
其次,
.
注.如计算结果与实际数字的误差较大,说明估计的参数r0必须进行修正.
实验题.你找几位同学组成调查小组,到一个社区做人口调查,记录最近10年内该社区人口变化情况,由此分析该社区人口变化的规律,将分析结果与逻辑斯蒂模型作一对照.
逻辑斯蒂增长模型又叫自我抑制性方程。用植物群体中发病的普遍率或严重度表示病害数量(x),将环境最大容纳量k定为1(100%),逻辑斯蒂模型的微分式是:
dx/dt=rx(1-x)
式中的r为速率参数,来源于实际调查时观察到的症状明显的病害,范.德.普朗克(1963)将r称作表观侵染速率(apparentinfectionrate),该方程与指数模型的主要不同之处,是方程的右边增加了(1-x)修正因子,使模型包含自我抑制作用。
模型的积分式为:
或
上式中的B为积分常数,因为x是经过t时间后的病害数量,
图4.4 “S”型曲线与逻值线对应图
当t=0时,x的初始值为x0,则积分常数B为(1-x0)/x0。经过整理可写成:
其线性方程为:
式中:ln(x/(1-x))称作x的逻辑斯蒂转换值,通常简称逻值(logit(x));
当x=0.5时,逻值(ln(x/(1-x))等于0;x<0.5时,逻值为负值;x>0.5时,逻值为正值。S型曲线的直线化,就是将病情(x)百分率转换成逻值后,用普通座标纸以逻值为纵座标对时间(t)作图,则病情进展曲线就成为一条直线,也称逻值线(图中B)。逻值线与纵轴相交的截点,为初始病害数量(x0),逻值线的斜率就是病害的流行速度,即表观侵染速率。
当一种新产品刚面世时,厂家和商家总是采取各种措施促进销售。他们都希望对这种产品的推销速度做到心中有数,这样厂家便于组织生产,商家便于安排进货。怎样建立数学模型描述新产品推销速度呢?
首先要考虑社会的需求量.社会对产品的需求状况一般依如下两个特性确定:
1.对产品的需求有一个饱和水平.当产品需求量达到一定数量时,对这种产品的需求也饱和了,设饱和水平为a;
2.假设在时刻t,社会对产品的需求量为x=x(t),需求的增长速度dx/dt正比于需求量x(t)与需求接近饱和水平的程度a-x(t)之乘积,记比例系数为k;
根据上述实际背景的两个特征,可建立如下微分方程:
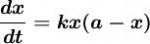 .......................(1)
.......................(1)
分离变量,得:

两边积分,得:
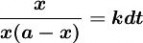
其中: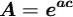
从而,通解为:
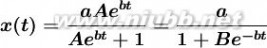 ......(2)
......(2)
其中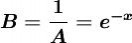 ,B和b为正常数,可由初始条件确定。式(1)称为逻辑斯蒂方程(1ogisticequation),式(2)称为逻辑斯蒂曲线。
,B和b为正常数,可由初始条件确定。式(1)称为逻辑斯蒂方程(1ogisticequation),式(2)称为逻辑斯蒂曲线。
1.当t=O时,x(t)的值为: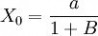 ;
;
2.x(t)的增长率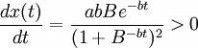 ,因此,x(t)是增函数;
,因此,x(t)是增函数;
3.当B值较大而t较小时,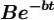 将很大,
将很大,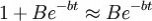 ,于是
,于是
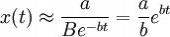
x(t)近似于依指数函数增大,销售速度不断增大;
4.当t增大以后,越来越接近于零,分母越来越接近于1,销售速度开始下降,x(t)的值接近于a(饱和值)。
1.人口限制增长问题
人口的增长不是呈指数型增长的,这是由于环境的限制、有限的资源和人为的影响,最终人口的增长将减慢下来。实际上,人口增长规律满足逻辑斯蒂方程。
2.信息传播问题
所谓信息传播可以是一则新闻,一条谣言或市场上某种新商品有关的知识,在初期,知道这一信息的人很少,但是随时间的推移,知道的人越来越多,到一定时间,社会上大部分人都知道了这一信息.这里的数量关系可以用逻辑斯蒂方程来描述。若以t表示从信息产生算起的时间,P表示已知信息的人口比例,则逻辑斯蒂方程变为:
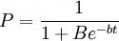 ...................(3)
...................(3)
例如,当某种商品调价的通知下达时,有10%的市民听到这一通知,2小时以后,25%的市民知道了这一信息,由逻辑斯蒂方程可算出有75%的市民了解这一情况所需要的时间。
在方程(3)中,由t=0时,P=10%可得B=9;再由t=2时,P=25%可得, 。
。
当P=75%时,有:

解得t=6,即6小时后,全市有75%的人了解这一通知。
3.商品销售预测问题
例如,某种商品的销售,开始时,知道的人很少,销售量也很小。当这种商品信息传播出去后,销售量大量增加,到接近饱和时销售量增加极为缓慢。比如,这种商品饱和量估计a=500(百万件),大约5年可达饱和,常数b经测定为b=lnl0,B=100。下面我们来预测一下第3年末的销售量是多少。
由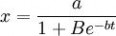 ,有:
,有:
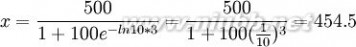 (百万件)
(百万件)
所以第三年末的市场销售量大约为454.5百万件,这样可以做到有计划地生产。
逻辑斯蒂方程的应用比较广泛。如果问题的基本数量特征是:在时间t很小时,呈指数型增长,而当t增大时,增长速度就下降,且越来越接近于一个确定的值,这类问题可以用逻辑斯蒂方程加以解决。
http://wiki.mbalib.com/wiki/逻辑斯蒂方程
逻辑斯蒂增长模型(Logisticgrowth model)
逻辑斯蒂增长模型又叫自我抑制性方程。用植物群体中发病的普遍率或严重度表示病害数量(x),将环境最大容纳量k定为1(100%),逻辑斯蒂模型的微分式是:
dx/dt=rx(1-x)
式中的r为速率参数,来源于实际调查时观察到的症状明显的病害,范.德.普朗克(1963)将r称作表观侵染速率(apparentinfectionrate),该方程与指数模型的主要不同之处,是方程的右边增加了(1-x)修正因子,使模型包含自我抑制作用。
模型的积分式为:
或
上式中的B为积分常数,因为x是经过t时间后的病害数量,
图4.4“S”型曲线与逻值线对应图
当t=0时,x的初始值为x0,则积分常数B为(1-x0)/x0。经过整理可写成:
其线性方程为:
式中:ln(x/(1-x))称作x的逻辑斯蒂转换值,通常简称逻值(logit(x));
当x=0.5时,逻值(ln(x/(1-x))等于0;x<0.5时,逻值为负值;x>0.5时,逻值为正值。S型曲线的直线化,就是将病情(x)百分率转换成逻值后,用普通坐标纸以逻值为纵坐标对时间(t)作图,则病情进展曲线就成为一条直线,也称逻值线(图中B)。逻值线与纵轴相交的截点,为初始病害数量(x0),逻值线的斜率就是病害的流行速度,即表观侵染速率。
与一般回归的区别在于,逻辑斯蒂变换能解决一般回归模型遇到的如下困难: 1. 模型的预测概率可能落在[0,1]区间之外; 2. 独立变量不是正态分布的; 3. 因变量的方差是不一致的。
Logistic回归处理因变量是分类型变量如“0、1”的情形。一下就假设你至少对它模模糊糊有些印象,比如说我们用p表示正例(如输出变量为“1”)的概率,那么p/(1-p)就被称作odds ratio,对p做logit变换记做logit(p),它等于log(p/(1-p),我们回归方程的形式就如logit(p)=log(p/(1-p)=a+bx,你可以把它理解成向量形式。
假设我们有一个数据,45个观测值,四个变量,包括:
种族增长曲线
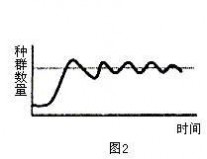
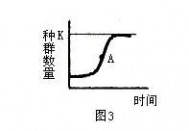
在高中生物教材中,种群增长曲线是一个重要的知识点。在种群增长曲线中,增长率不等于曲线的斜率,只有增长速率才可等于曲线的斜率。“J”型增长曲线的增长率不变,但其增长速率(等于曲线的斜率)却逐渐增大。而呈“S”型增长曲线的种群增长率是先增后减的,且其增长速率(同于曲线斜率)也是先增后减的。
 |
| 种族增长曲线 |
 |
| 种族增长曲线 |
 |
| 种族增长曲线 |
实例:研究种群数量变化的规律,有利于对野生生物资源的合理利用和保护。
释义:一般野生动植物种群的数量控制在环境容纳量的一半,即K/2值时,此时种群增长速度最快,可提供的资源数量也最多,而又不影响资源的再生,当种群数量大于K/2值,种群增长的速度将开始下降。所以在开发动植物资源时,种群数大于K/2值时就可以猎取一定数量的该生物资源,而且获得的量最大,当过程猎取导致种群数量小于K/2值时,种群增长的速度将会减慢,获取的资源数量将减少,而且还会影响资源的再生。
种群变化规律,对于控制世界人口增长,解决环境危机同样具有重要的指导意义。人类目前面临的生存危机,其根源就在于人口种群的急速增长与有限的环境资源之间的矛盾。世界人口长期以来呈指数增长趋势,主要是由于人类能够不断的开发新能源,并通过工业革命、农业革命等手段,适当地提高了自然界对人类的最大负荷量(K值)。但环境资源毕竟有限,假如人口数量增加到K值,将会引起生物圈的崩溃,后果不堪设想。所以科学的控制人口增长率,是解决环境问题的根本措施。
Logistic回归延伸了多元线性回归思想,即因变量是二值(为了方便起见通常设这些值为0和1)的情形。和在多元线性回归中一样,自变量也许是类别变量或连续变量或是两种类型的混合。
标准的多元线性回归模型不合适这些数据:
1. 模型的预测概率可能落在[0,1]区间之外;
2.独立变量不是正态分布的。实际上,二项式模型会更合适。例如,如果单元格个数是11,那么变量只能取0,1,2…11。设想在每个单元格中家庭的(做出的)反应是由独立的抛硬币来决定,在单元格中的采用概率由头像正面向上的概率表示。
3.如果我们认为正态分布是对二项分布的近似,在所有单元格中因变量的方差是不一致的:它将会比在单元格中采用概率p高,是接近0.5而不是接近0或1。这将增加落在单元格中家庭的总数量n。这个方差等于n(p(1-p))。
Logistic回归模型被发展来处理这些困难。它在经济计量学中描述选择行为和在流行病风险因素建模中变得非常流行。在选择行为的环境中,它通常被表现为服从随机效用理论,这个理论是由Manski对标准消费者行为经济理论的拓展。
实质上,消费者理论陈述了当面对一个选择集时,消费者会做出有最高的效用的选择(对价值做出的主观的、由0或一些标称变量表示的定量化衡量)。它假设消费者有一个满足如传递性等标准的合理的选择排序。这个偏好序列能依靠个人(如上例1所示的社会经济学的特征)及选择的属性。随机效用模型认为选择的效用包含了一个随机因素。当我们对来自“合理”的分布的随机因素建模,我们能从逻辑上建立预测选择行为的Logistic模型。
如果我们让y=1代表做了一个选择,y=0表示不选择它,Logistic回归模型规定: 1
概率)...exp(1)...exp()...,|1(11011021kkkkkxxxxxxxYββββββ+++++==
其中,kβββ,...,10是未知的和多元线性回归模型相似的常数。
对我们模型中的自变量是:
≡1x(教育:高中以下=0,大学以上=1)
≡2x(居住稳定性:在过去5年中没有变化=0,在过去5年有变化=1)
≡3x(收入:低=0,高=1)
对系数的估计通常基于最大似然原则来执行,这个原则可以保持很好的渐近的估计。在通常情况下最大似然估计是:
一致的:随着例子规模的增长,估计出的概率和从真值之间的差异接近于0;
渐进有效的:方差在所有一致的估计中是最小可能的;
渐进的正态分布:倘若例子规模是很大的,将会允许我们计算置信区间和采用类似于线性多元回归模型的统计检验。
和线性回归相比,系数估计和计算置信区间的算法是迭代的和缺少鲁棒性的。对于数据质量好的数据集来说,计算出的估计通常是可靠的。数据质量好通常是指,这个数据集中因变量取值是0或1的事例数较大;它们的比率是“不太接近于”0或1;并且在Logistic回归模型中系数的数目相对于样本的大小是很小的(不超过10%)。与线性回归一样,当遇到共线性(在自变量中有很强的相关性)时Logistic回归能导致计算困难。近来计算的强度算法被发展起来可以解决一些这样的困难。
7
http://www.core.org.cn/NR/rdonlyres/Sloan-School-of-Management/15-062Data-MiningSpring2003/B2EC3803-F8A7-46CF-8B9E-D0D080E52A6B/0/logreg.pdf
http://www.physics.sdnu.edu.cn/sdnujpkc/zl/ckzl/logistic�ع�.ppt
http://jpkc.njust.edu.cn/gltj/files/Logistic�ع������Ӧ��.ppt
http://www.tcmcec.com/conference/lecture/lecture2006010907.ppt
logistic回归分析,是当因变量是分类变量时的回归。
主要在流行病学中应用较多,比较常用的情形是探索某疾病的危险因素,根据危险因素预测某疾病发生的概率,等等。自变量既可以是连续的,也可以是分类的。通过logistic回归分析,就可以大致了解到底哪些因素是胃癌的危险因素。
logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于他们的因变量不同,其他的基本都差不多,正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinearmodel)。这一家族中的模型形式基本上都差不多,不同的就是因变量不同,如果是连续的,就是多重线性回归,如果是二项分布,就是logistic回归,如果是poisson分布,就是poisson回归,如果是负二项分布,就是负二项回归,等等。只要注意区分它们的因变量就可以了。
logistic回归的因变量可以是二分类的,也可以是多分类的,(www.61k.com)但是二分类的更为常用,也更加容易解释。所以实际中最为常用的就是二分类的logistic回归。
logistic回归的主要用途:一是寻找危险因素,正如上面所说的寻找某一疾病的危险因素等。二是预测,如果已经建立了logistic回归模型,则可以根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大。三是判别,实际上跟预测有些类似,也是根据logistic模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
这是logistic回归最常用的三个用途,实际中的logistic回归用途是极为广泛的,logistic回归几乎已经成了流行病学和医学中最常用的分析方法,因为它与多重线性回归相比有很多的优势。
实现
在SAS中用STAT模块的logistic过程
spss中regression 中有相关的分析。
stata做logistic回归做的不错。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/duanshuyong0/archive/2010/03/19/5397541.aspx
logistic回归对因变量的比数的对数值( logit值)建立模型
因变量的logit值的改变与多个自变量的加权和呈线性关系
因变量呈二项分布
logistic回归的局限性
理论上的不足:自变量对疾病的影响是独立的,但实际情况及推导结果不同。
模型有不合理性:“乘法模型”与一般希望的“相加模型”相矛盾。
最大似然法估计参数的局限
样本含量不宜太少:例数大于200例时才可不考虑参数估计的偏性。
能否用发病的概率P来直接代替 y呢?
p=β0+β1X1+β2X2+…+βpXp
定义:logit(P)= ln[P/(1-P)]为 Logistic变换, Logistic 回归模型为:
logit(P)=β0+β1X1+…+βpXp ;
经数学变换可得:
exp(β0+β1X1+…+βpXp)
P=─────────────
1+ exp(β0+β1X1+…+βpXp);
exp表示指数函数。
Logistic回归模型是一种概率模型, 它是以疾病,死亡等结果发生的概率为因变量,影响疾病发生的因素为自变量建立回归模型。它特别适用于因变量为二项,多项分类的资料。
http://idv.kh.usc.edu.tw/yclin/teaching/MultuvariateAnalysis/Logistic�j�k��R��q.doc
http://www.physics.sdnu.edu.cn/sdnujpkc/zl/ckzl/logistic�ع�.ppt
http://www.6lib.com/pdf/059F92EA4081179805.pdf
Logistic回归模型:方法与应用(当代科学前沿论丛)
作者:王济川 等
出版社:高等教育出版社
出版日期:2001年9月
三 : 逻辑回归模型(Logistic Regression, LR)基础 - 文赛平
逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函数,使得逻辑回归模型成为了机器学习领域一颗耀眼的明星,更是计算广告学的核心。[www.61k.com]本文主要详述逻辑回归模型的基础,至于逻辑回归模型的优化、逻辑回归与计算广告学等,请关注后续文章。
1逻辑回归模型
回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。
最简单的回归是线性回归,在此借用Andrew NG的讲义,有如图1.a所示,X为数据点——肿瘤的大小,Y为观测值——是否是恶性肿瘤。通过构建线性回归模型,如hθ(x)所示,构建线性回归模型后,即可以根据肿瘤大小,预测是否为恶性肿瘤hθ(x)≥.05为恶性,hθ(x)<0.5为良性。
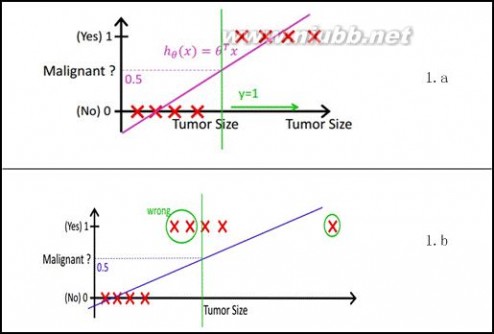
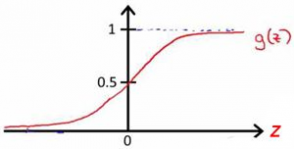
然而线性回归的鲁棒性很差,例如在图1.b的数据集上建立回归,因最右边噪点的存在,使回归模型在训练集上表现都很差。这主要是由于线性回归在整个实数域内敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,其回归方程与回归曲线如图2所示。逻辑曲线在z=0时,十分敏感,在z>>0或z<<0处,都不敏感,将预测值限定为(0,1)。
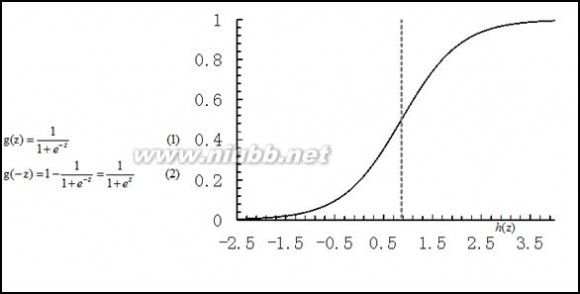 图2 逻辑方程与逻辑曲线
图2 逻辑方程与逻辑曲线
逻辑回归其实仅为在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函数,逻辑回归成为了机器学习领域一颗耀眼的明星,更是计算广告学的核心。对于多元逻辑回归,可用如下公式似合分类,其中公式(4)的变换,将在逻辑回归模型参数估计时,化简公式带来很多益处,y={0,1}为分类结果。
对于训练数据集,特征数据x={x1, x2, … , xm}和对应的分类数据y={y1, y2, … , ym}。构建逻辑回归模型f(θ),最典型的构建方法便是应用极大似然估计。首先,对于单个样本,其后验概率为:
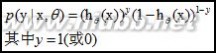 那么,极大似然函数为:
那么,极大似然函数为:
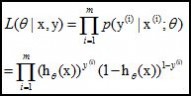 log似然是:
log似然是:

2梯度下降
由第1节可知,求逻辑回归模型f(θ),等价于:
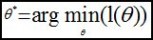 采用梯度下降法:
采用梯度下降法:
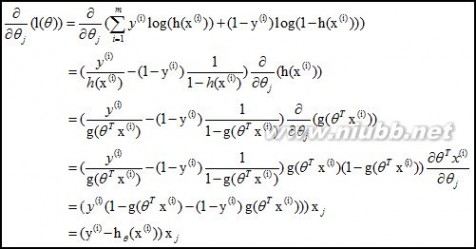 从而迭代θ至收敛即可:
从而迭代θ至收敛即可:

3模型评估
对于LR分类模型的评估,常用AUC来评估,关于AUC的更多定义与介绍,可见参考文献2,在此只介绍一种极简单的计算与理解方法。
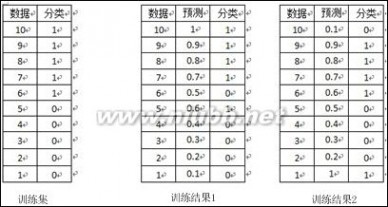 对于训练集的分类,训练方法1和训练方法2分类正确率都为80%,但明显可以感觉到训练方法1要比训练方法2好。因为训练方法1中,5和6两数据分类错误,但这两个数据位于分类面附近,而训练方法2中,将10和1两个数据分类错误,但这两个数据均离分类面较远。
对于训练集的分类,训练方法1和训练方法2分类正确率都为80%,但明显可以感觉到训练方法1要比训练方法2好。因为训练方法1中,5和6两数据分类错误,但这两个数据位于分类面附近,而训练方法2中,将10和1两个数据分类错误,但这两个数据均离分类面较远。
AUC正是衡量分类正确度的方法,将训练集中的label看两类{0,1}的分类问题,分类目标是将预测结果尽量将两者分开。将每个0和1看成一个pair关系,团中的训练集共有5*5=25个pair关系,只有将所有pair关系一至时,分类结果才是最好的,而auc为1。在训练方法1中,与10相关的pair关系完全正确,同样9、8、7的pair关系也完全正确,但对于6,其pair关系(6,5)关系错误,而与4、3、2、1的关系正确,故其auc为(25-1)/25=0.96;对于分类方法2,其6、7、8、9的pair关系,均有一个错误,即(6,1)、(7,1)、(8,1)、(9,1),对于数据点10,其正任何数据点的pair关系,都错误,即(10,1)、(10,2)、(10,3)、(10,4)、(10,5),故方法2的auc为(25-4-5)/25=0.64,因而正如直观所见,分类方法1要优于分类方法2。
参考文献:
1 Andrew NG. Logistic Regression Classification
2
四 : 教育回归本谛
千教万教教人求真,千学万学学做真人。教育,关乎民族、国家、世界兴旺发达,是一个人类永恒不变的话题。
教育担负着传道授业解惑的媒介作用,当教育的本谛丢失、误区的突出显现,绝对的、精致的利己主义成为主流,时代的悲哀在不经意间成了大众学生追求的方向。
与高考无关的课,不学;与就业无关的知识,不问;与生计无关的事,不做。言语行为,俨然是一副事不关己高高挂起的令人生厌的嘴脸。这个社会是因为什么而变成了这样?道德的沦丧?亦或是价值观的扭曲?
哲学教导我们用唯物辩证的方法,一分为二的角度看待问题,看起来矛盾的相互对立事物,往往存在多样联系,其本质和内部的联系常常决定了事物的意识。
教育求真诲人,利己功利毁人。到现今的体系中,诲人却和毁人挂上了等号。家长灌输学生课本至上,忘记了输送书外认知;老师看重学生分数增长,忘记了重视人格提升;学校教授学生科学知识,忘记了传授做人道理;社会着意学生名牌大学,忘记了在意能力大小。
孔子弟子三千,射、御、骑、书、数五艺习学,推行有教无类,因材施教。根据弟子长处着力培养,有名者七十二贤德之名传列国。
现行的教育将学生一揽子培养,强硬的灌输知识,无视学生的爱好与乐趣,学生只有被迫接受。补习班如雨后春笋,拔地而起,家长趋之若鹜,抱着不能输在起跑线上的心态,争先恐后地报名补习班。殊不知,物极必反!弹簧压力越大,反弹便越大。急功近利的教育模式、实用至上的处世之道,遮蔽了太多人的长远目光,只顾眼前,显得短视。
“我觉得我们现在的教育,正在培养出一批绝对的、精致的积极主义者。”钱理群教授的话不啻一针见血,振聋发聩,明确指出来了高考模式下现在教育的弊端。
1977年高考制度重新实行的第一批考生,现以成为各阶层领域的骨干精英,是社会主义建设的顶梁支柱。同样的高考,反观今天的我们,为了上更优秀的大学而高考,这本无可厚非。但只有上更好的大学,未来才会“钱途”无限。以金钱作为衡量人成功的大小,地位看待人身份的高低。教育似乎丢失了教导我们为人处世的真正真谛,而错误的思维则把人引向了误区。
近些年来的教育改革说明人们意识到了该问题,探索过程中摸索前进。如今教育的弊端非一日之功可以改变,思想禁锢一时间积重难返。改革还需反复推敲,精益求精,一蹴而就是不可能其改变本质。
教育制度渐趋完善,但仍是一个长期且艰难的过程,所谓“没有比人更高的山,没有比脚更长的路”。智慧的中国人民从来不畏惧困难,我相信教育新的
春天一定会来到的!
高三:程亿
本文标题:逻辑斯谛回归-机器学习笔记 Week3 逻辑回归61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1