一 : 百度文库怎么复制 如何复制百度文库中的文章解决方法
很多人经常会上百度搜索资料,结果发现在百度文库那边可以找到,兴奋了半天却发现下载时要币的,或者登陆上去麻烦。针对这种情况,今天我给大家带来一个破解百度文库下载的方法,其实非常简单,而且不用下载任何软件。
方法/步骤
首先,我们按照平常的习惯,找到自己要的:
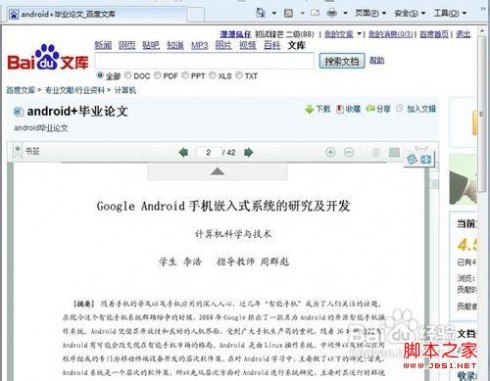
文章不能复制,题目总是可以的吧。我们把题目记住之后, 在搜索引擎的框框里输入:site:wenku.baidu.com +题目【site命令是指在制定的网站里搜索,加号也是要的,如果嫌输入加号麻烦,可以用空格代替。】如搜索android+论文,输入:site:wenku.baidu.com android+论文 (中间有空格)搜索引擎都有网页网页快照,如百度有百度快照,谷歌有网页快照,我们点击快照进入网址.
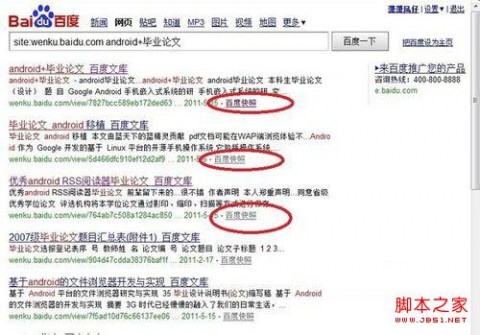
打开网页快照或百度快照之后,我们就可以看到以网页形式显示的百度文库正文内容了

最后,我们只需要将内容复制下来就可以,粘贴到WORD等文本编辑器里,就可以保存下来了。
百度快照:任意搜一个东西,每一条信息最后会有一项是--百度快照,就是它。就这几步,就轻松的破解百度文库下载,简单又实用。
二 : 如何复制百度文库里的文章(百度文库破解)
很多人经常会上百度搜索资料,结果发现在百度文库那边可以找到,兴奋了半天却发现下载时要币的,或者登陆上去麻烦。针对这种情况,今天我给大家带来一个破解百度文库下载的方法,其实非常简单,而且不用下载任何软件。好了,废话不多说,直接进入正题。首先,我们按照平常的习惯找到自己需要的文档,然后复制文章的题目,如下图:

然后,我们把复制到的题目粘贴进搜索引擎的框框里,格式是这样的:site:wenku.baidu.com(空格)题目,如下图:

接着,我们点击下方的“网页快照”(搜索出的内容搜索引擎都有网页网页快照,如百度有百度快照,谷歌有网页快照)。

最后,在打开网页快照或百度快照之后,我们就可以看到以网页形式显示的百度文库正文内容了。这是,我们只需要将内容复制下来就可以,粘贴到WORD等文本编辑器里,就可以保存下来了。 
三 : 百度如何判断网页文章的重复度?两个页面相似度确认方法介绍
在这个科技高度发达的时代,百度已经成为人们能获取消息的主要途径。但如今的百度,到处充斥着一些重复的内容,对用户的访问造成很大的困扰。因此,百度需要对网页重复进行判断,对重复的网页,只选取一些高质量的我那工业,共用户浏览。然而,现有技术中一般是通过比较两个页面的内容和借点,来确认两个页面的相似度。
这种方法能够计算的比较准确,可时间复杂度太高,计算很费时间。通过对一个页面中的某些重要信息进行签名,然后比较两个页面的签名,来计算相似度,这种方式比较简单高效,计算速度比较快,比较适合百度这种海量信息的应用场景。
1,网站重复内容的判断
A,获取多个网页;
B,分别提取网页的网页正文;
C,从网页正文中提取一个或多个句子,并根据一个或多个句子计算网页正文句子签名;
D,根据网页正文句子签名对多个网页进行聚类;
E,针对每一类下的网页,计算网页的附加签名;
F,根据附加签名判断每一类下的网页是否重复。
通过上述方式,网页重复的判断系统及其判断方法通过包括网页正文句子签名在内的多维度签名有效且快速地判断网页是否重复。

网站页面基本架构
提取正文
A,对网页进行分块;
B,对分块后的网页进行块过滤,以获取包含网页正文的内容快;
C,从内容块中提取网页正文。
正文分句
A,对网页正文进行分句;
在本步骤中,可利用分号,句号,感叹号等表示句子完结的标志符号来对网页正文进行分句。此外,还可以通过网页正文的视觉信息来对网页正文进行分句。
B,对分句后的网页正文进行过滤及转换;
在步骤中,首先过滤掉句子中的数字信息;版权信息以及其他对网页重复判断不起决定性作用的信息。随后,对句子进行转换,例如,进行全角/半角转换或者繁体/简体转换,以使得转换后的句子的格式统一。
C,从过滤及转换后的网页正文中提取最长的一个或多个句子;
在本步骤中,过滤及转换后的网页正文提取出最长的一个句子或者做场的预定数量连续句子的组合。例如,某个网页实例中,经过过滤及转换后的某段最长,远超其他句子,因此可选择该段为网页正文句子,或者选择最长的连续句子组合作为网页正文句子。
D,对一个或多个句子进行hash签名运算,以获取网页正文句子签名。
simhash算法就是比较各网页的附加签名是否相同或相似来判断网页是否重复。具体来说,在比较利用simhash签名运算获得的网页正文签名时,比较网页正文签名的不同位数,不同位越少,表示网页重复的可能性越高,在比较其他的附加签名时,若附加签名相等,表示网页在该纬度上重复。
总结:
1、两个网页的真实标题签名相同。
2、两个我那工业的网页内容签名相同。
3、两个网页的网页正文签名的不同位数小于6.。
4、两个网页的网页位置签名相同,并且url文件名签名相同。
5、评论块签名、资源签名、标签标题签名、摘要签名、url文件名签名中有三个签名相同。
附加信息整站判断重复标准:
通过两两页面比较,可以得到真重复url的集合。一般来说,如果这个真重复url集合中的网页的数量/整个网页集中网页的数量大于30%,则认为整个网页集都是真重复,否则就是假重复。
四 : 浅谈文章排名 百度是如何给网页排序的
我们向搜索引擎提交一个查询,搜索引擎会从先到后列出大量的结果,排序的不同带来的经济效应也不同,我们想要的就是让自己的搜索结果靠前,最好是能得到NO.1。那么这些搜索结果排序的标准是什么呢?
还是看看百度搜索研发部以求医为例谈搜索引擎排序算法的基础原理。

比如,如果我牙疼,应该去看怎样的医生呢?假设只有三种选择:
A医生,既治眼病,又治胃病;
B医生,既治牙病,又治胃病,还治眼病;
C医生,专治牙病。
A医生肯定不在考虑之列,B医生和C医生之间,貌视更应该选择C医生,因为他更专注,更适合我的病情。假如再加一个条件:B医生经验丰富,有二十年从医经历,医术高明,而C医生只有五年从医经验,这个问题就不那么容易判断了,是优先选择更加专注的C医生,还是优先选择医术更加高明的B医生,的确成了一个需要仔细权衡的问题。
至少,我们得到了一个结论,择医需要考虑两个条件:医生的专长与病情的适配程度、医生的医术。大家肯定觉得这个结论理所当然,而且可以很自然地联想到,搜索引擎排序不也是这样吗,既要考虑网页内容与用户搜索查询的匹配程度,又要考虑网页本身的质量。
但是,怎么把这两种因素结合起来,得到一个,而不是两个或多个排序标准呢?简单的加减乘除是不够严谨的,最好能跟数学这样坚实的学科联系起来。人类在古代就能建造出高楼,但要建造出高达数百米的摩天大厦,如果没有建筑力学、材料力学这样坚实的学科作为后盾,则是非常非常困难的。同理,搜索引擎算法要处理上亿的网页,也需要更为牢固的理论基础。
求医,病人会优先选择诊断准确、治疗效果好的医生。而对于搜索引擎来说,一般按网页满足用户需求的概率从大到小排序。如果用q表示用户给出了一个特定的搜索查询,用d表示一个特定的网页满足了用户的需求,那么排序的依据可以用一个条件概率来表示:
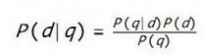
这个简单的条件概率,将搜索引擎排序算法与概率论这门坚实的学科联系了起来。可以看到,搜索引擎的排序标准,是由三个部分组成的:搜索查询本身的属性P(q)、网页本身的属性P(d)、两者的匹配关系P(q|d)。对于同一次查询来说,所有网页对应的P(q)都是一样的,因此排序时可以不考虑,即
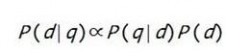
搜索引擎为了提高响应用户搜索查询的性能,需要事先对所有待查询的网页做预处理。预处理时,搜索引擎预处理只知道网页,还不知道用户查询,因此需要倒过来计算,即分析每个网页能满足哪些需求,该网页分了多大比例来满足该需求,即得到公式右边的第一项P(q|d),这相当于医生的专注程度。
比如,一个网页专门介绍牙病,另一个网页既介绍牙病又介绍胃病,那么对于“牙疼”这个查询来说,前一个网页的P(q|d)值就会更高一些。
公式右边的第二项P(d),是一个网页满足用户需求的概率,它反映了网页本身的好坏,与查询无关。假如要向一个陌生人推荐网页(我们并不知道他需要什么),那么P(d)就相当于某个特定的网页被推荐的概率。在传统的信息检索模型中,这个不太被重视,之前都试图只根据查询与文档的匹配关系来得到排序的权重。而实际上,这个与查询无关的量是非常重要的。
假如我们用网页被访问的频次来估计它满足用户需求的概率,可以看出对于两个不同的网页,这个量有着极其巨大的差异:有的网页每天只被访问一两次,而有的网页每天被访问成千上万次,这对于排序非常重要。
总而言之,这个公式模型告诉了我们网页与查询的匹配程度,和网页本身的好坏都是参与排序排名的重要因素。
怎么样?文章中的内容在现在是不是有很多都似曾相似,是不是在互联网上看到很多文章都和这类似?其实很多内容都是从这里衍生出去的。比如搜索引擎的综合得分排序、比如关键词与网页内容的相关度、比如网页本身好坏对排序影响等等。
一个最简单的例子,著名的搜索引擎排序算法pagerank算法,其实就是为了弥补传统算法对P(d)值(页面本身好坏判断)的不足而产生的,Pagerank是对网页好坏判断的一个不错的标准。而现在的网页点击量、停留时间、跳出率、页面访问速度等都是对网页满足用户需求概率的预估,这一个因素越来越重要。
其实也是大篇幅的在谈谈网页本身好坏这一点。随着用户时代来临,用户投票越来越影响搜索排名,而用户主要衡量的除了需求满足外就是网页本身质量。所以,网页本身质量不管对于用户还是搜索引擎,在排序上都变得越来越重要。
一句话,很多时候需要透过现象去看本质,而你看透这个本质后,再看其他现象,一切都那么明了。谢谢阅读,希望能帮到大家,请继续关注61阅读,我们会努力分享更多优秀的文章。
本文标题:如何复制百度文库中的文章-百度文库怎么复制 如何复制百度文库中的文章解决方法61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1