一 : Google删除网站索引浅析
在公司维护一些英文网站,主要是日常一些SEO方面的工作,如增加链接,做一些关键词等,但自从2009年3月份以后,网站经常被挂满了隐藏链接,这是典型的黑客侵入了网站系统,可能已经加了后门,从那以后,首页经常被加入隐藏链接,虽然一直被覆盖,但一两天以后,首页又被重新加上了隐藏链接。但对于这件事,我也只是敷衍了事,检查日志文件看不出什么眉目,也就没当回事,想就只是加几个链接而已,也没有什么大不了的。
六月十九日,早晨检查网站,看到网站访问量大减,心中觉得奇怪,看一下访问者都是从Yahoo! 和 Bing 进来的,就是没有从Google 进来的,看一下 Google 管理员工具看到 Google 早在十七日就已经发邮件过来通知我,网站因为添加隐藏文本而被删除,吓了一跳,于是下载了整个网站,找到了黑客后门,删除掉,修改页面,重新提交审核,两天以后,也就是二十一号早晨发现网站已经被重新收录,而且排名位置基本没变。
从中,有几个问题比较值得注意,从十七日Google 发邮件通知删除索引,但那一天还是有从 Google来的流量,到十九日就完全没有从Google来的流量了,导致访问量变化非常明显,那就是说即使 Google 搜索质量小组发邮件来说已经删除索引了,但实际上索引并未完全删除,还是有流量从Google 过来的,而且两天后,Google 重新收录网站,排名基本都没变,索引页面数也和以前比没有变化多少,但尤其值得注意的一点是,居然发现首页的 Google 快照是 六月十八日, 这一发现确实是挺让人震撼的,那也就是说,Google spider 在删除索引以后,还是来抓取页面的。
在十九日删除索引后,整个网站在Google是搜索不到的,后来重新收录,看到大部分的页面的快照还是在十七日之前的,认真分析一下的话,会想说,索引真的是完全被 Google 从索引数据库中抹除了吗,恐怕未必,否则快照日期不会是在删除之前的日期,而应该是审核通过重新抓取的日期。
在此,大胆提出一个猜想,Google 搜索引擎的算法没人知道,但有一些痕迹是可以猜想的,我想:Google 是不是采取这样的一种策略,专门有服务器存放被惩罚的或者是被删除的网站,就像google sandbox 一样,甚至被删除索引的网页的处理方法就是 google sandbox 的另一种表现,当一个网站被删除索引时,索引全部移动到这样的一个服务器中,在正常排名的索引中再也不会有这些网站存在了,但蜘蛛还是会访问这些被屏蔽的网站的,可以通过快照日期能够看出来,不然的话,通过服务器的日志文件也能看出来,一旦网站被重新审核通过,从这样的一个服务器中移动到正常索引中,时间会很短,这也是为什么一旦审核通过,收录页面数量会从0回来以前的水平,如果是重新收录的话,不应该会有这么快的收录速度。
只是把自己发现的一些问题提出来,希望朋友们提出自己的看法,和我一起交流。
二 : Oracle与MySQL删除字段时对索引和约束的处理
不知道有多少人清楚的知道,在Oracle中,如果一个复合索引,假定索引(a,b,c)三个字段,删除了(包括unused)其中一个字段,Oracle会怎么处理这个索引。同样,如果是约束,Oracle又怎么处理?
用Oracle为例子,我又拿mysql做了一个对比,看看mysql是怎么处理这个问题的。我这里不讨论谁好谁差,只是希望大家知道其中的差别与细节而已。
我们先看Oracle的例子,我们创建一个表,然后在上面创建一个约束,创建一个索引:
| 以下为引用的内容: SQL10G>createtabletest(aint,bint,cint); Tablecreated. SQL10G>altertabletestaddconstraintpk_testprimarykey(a,b); Tablealtered. SQL10G>createindexind_testontest(b,c); Indexcreated. |
然后,我们检查刚才创建的约束与索引
| 以下为引用的内容: SQL10G>selectt.constraint_name,c.constraint_type,t.column_name,t.position,c.status,c.validated 2fromuser_cons_columnst,user_constraintsc 3wherec.constraint_name=t.constraint_name 4andc.constraint_type!='C' 5andt.table_name='TEST' 6orderbyconstraint_name,position; CONSTRAINT_NAMECCOLUMN_NAMEPOSITIONSTATUSVALIDATED ------------------------------------------------------------ PK_TESTPA1ENABLEDVALIDATED PK_TESTPB2ENABLEDVALIDATED SQL10G>selectt.index_name,t.column_name,t.column_position,i.status 2fromuser_ind_columnst,user_indexesi 3wheret.index_name=i.index_name 4andt.table_name='TEST' 5*orderbyindex_name,column_position INDEX_NAMECOLUMN_NAMECOLUMN_POSITIONSTATUS ------------------------------------------------- IND_TESTB1VALID IND_TESTC2VALID
Tablealtered. SQL10G>selectt.index_name,t.column_name,t.column_position,i.status 2fromuser_ind_columnst,user_indexesi 3wheret.index_name=i.index_name 4andt.table_name='TEST' 5orderbyindex_name,column_position; norowsselected |
发现了什么,索引也删除了。那我们再删除约束上的字段呢?
| 以下为引用的内容: SQL10G>ALTERTABLEtestSETUNUSED(b); ALTERTABLEtestSETUNUSED(b) * ERRORatline1: ORA-12991:columnisreferencedinamulti-columnconstraint SQL10G>ALTERTABLEtestSETUNUSED(b)CASCADECONSTRAINTS; Tablealtered. SQL10G>selectt.constraint_name,c.constraint_type,t.column_name,t.position,c.status,c.validated 2fromuser_cons_columnst,user_constraintsc 3wherec.constraint_name=t.constraint_name 4andc.constraint_type!='C' 5andt.table_name='TEST' 6orderbyconstraint_name,position; norowsselected |
我们可以看到,正常的删除会报一个错误,如果我们指定了cascade,将会把对应的约束也删除。
我们看完了Oracle的处理过程,再看看mysql是这么处理删除索引上字段这个事情的
| 以下为引用的内容:
QueryOK,0rowsaffected(0.72sec) mysql>altertabletestaddprimarykey(a,b); QueryOK,0rowsaffected(0.27sec) Records:0Duplicates:0Warnings:0 mysql>createindexind_testontest(b,c); QueryOK,0rowsaffected(0.32sec) Records:0Duplicates:0Warnings:0 |
我们执行同样的操作,先删除复合索引中的一个字段,然后删除约束中的一个字段。
| 以下为引用的内容: mysql>altertabletestdropc; QueryOK,0rowsaffected(0.58sec) Records:0Duplicates:0Warnings:0 mysql>showindexfromtest; +-------+------------+----------+--------------+-------------+-----------+ |Table|Non_unique|Key_name|Seq_in_index|Column_name|Collation| +-------+------------+----------+--------------+-------------+-----------+ |test|0|PRIMARY|1|a|A| |test|0|PRIMARY|2|b|A| |test|1|ind_test|1|b|A| +-------+------------+----------+--------------+-------------+-----------+ 3rowsinset(0.06sec) mysql>altertabletestdropb; QueryOK,0rowsaffected(0.28sec) Records:0Duplicates:0Warnings:0 mysql>showindexfromtest; +-------+------------+----------+--------------+-------------+-----------+ |Table|Non_unique|Key_name|Seq_in_index|Column_name|Collation| +-------+------------+----------+--------------+-------------+-----------+ |test|0|PRIMARY|1|a|A| +-------+------------+----------+--------------+-------------+-----------+ 1rowinset(0.03sec) |
可以看到,mysql的处理方式是有差别的,mysql仅仅是把字段从索引中拿掉,而不是删除该索引。
本文的意思,就是想提醒大家,平常在做columns删除的时候,包括unused,一定要小心,是否有复合索引包含了该字段,否则,一不小心把索引删除了,可能将引发大的错误。
三 : 申请从谷歌的索引中删除内容
(译者注: 本文讲述了如何申请从谷歌的索引中删除内容,包括你自己拥有的内容及其他你所不拥有但是包含特殊信息的内容,如不健康内容或你的个人信息)
作为网站拥有者,网站的什么内容被搜索引擎索引,你完全可以控制。当你想让搜索引擎知道什么样的内容您不希望它们索引时,最简单的方法是使用robots.txt文件或robots元标记。但有时候,你想要删除已经被索引的内容。有什么最好的方法来做到这一点呢?
同以往一样,我们的回答总是这样开始:这取决于你想要删除的内容的类型。我们的网络管理员帮助中心提供了每种情况的详细资料。每当我们重新爬行该网页, 我们就会从我们的索引中自动移去你要删除的内容。但如果你想更快地删除你的内容,而不是等待下一次的爬行,我们刚刚有了一些方法使做到这一点变得更为容易。
如果你的网站已经通过了网站管理员工具帐号的网站拥有者验证,你就会看到在"工具"下有一个删除网址链接。要想删除,你可以点击删除网址链接,然后再点击新增删除请求。请选择你想要的删除类型。
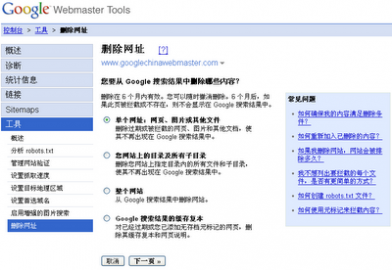
单个网址
如果你想移除一个URL或图像,请选择此项。一个可以删除的URL必须符合以下条件之一:
* 该URL必须返回一个404或410的状态码。
* 该URL必须被该网站的robots.txt文件所阻截。
* 该URL必须被robots元标记所阻截。
如果一个URL可以被删除了,你输入该URL,看看它是否出现在我们的网页搜索结果或图像搜索结果里。然后点击添加。您可以一次添加多达100个URL的请求。当你添加完所有你想删除的URL后,点击“提交删除请求”。
单个目录
如果你想删除你站点的一个目录下的所有文件和子目录,请选择此选项。例如,如果你请求删除以下内容:
http://www.example.com/myfolder
这将删除所有以该路径为开头的URL,譬如:
http://www.example.com/myfolder
http://www.example.com/myfolder/images/image.jpg
为了使目录可以被清除,你必须用robots.txt文件来阻截搜索引擎。例如,上面的例子中, http://www.example.com/robots.txt可以包括以下内容:
User-agent: Googlebot
Disallow: /myfolder
你的整个网站
只有当你想从Google索引删除你的整个网站时,才选择此选项。此选项将删除所有子目录及文件。对于你网站的被索引的URL中你不喜欢的版本,请不要使用此选项来删除。举例来说,如果你想你的全部URL只有www的版本才被索引,请不要使用这一选项来请求删除非www的版本。你可以使用设置首选域名工具来指定你希望被索引的版本(如果可能的话,做一个301重定向到你喜欢的版本)。使用此选项,你必须使用robots.txt文件拦截或删除整个网站。
缓存副本
要删除你的网页在我们索引中的缓存副本(又称网页快照--译者注),请选择此项。你有两种方法来使你的页面符合删除页面缓存的条件。
使用noarchive元标记来要求快速删除
如果你根本不想让你的页面被缓存,你可以在该页面上加一个noarchive元标记,然后再在工具中要求快速删除缓存副本。通过使用工具来要求删除缓存副本,我们会立刻执行。由于添加了noarchive元标记,我们将永远不会有该页的缓存版本。 (当然,如果你以后改变主意,你可以去掉noarchive元标记)。
改变网页内容
如果你的某一页面已被删除,你也不想让它的缓存版本存在于Google的索引中,你可以在工具里请求删除缓存。我们会先检查一下该页的现有内容是否真的有别于缓存版本。如果是,我们就会清除缓存版本。我们会在6个月后自动显示最新的缓存页面版本(6个月后,我们可能已经又爬行过你的页面,缓存版本会反映最新的内容),或者,如果你发现我们早于6个月重新爬行了你的页面,你可以用工具要求我们早一点重新包含缓存版本。
注:相关网站建设技巧阅读请移步到建站教程频道。
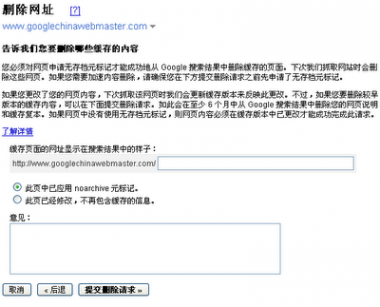
查阅删除请求状态
你的删除请求状态将是“等待中(Pengding)”,直到他们被处理。处理后的状态变化,要么是“被拒了(Denied)”或者是“删除了”。一般来说,如果被拒绝,它一定是不满足被删除的条件。
请求内容的重新收录
如果请求是成功的,它就会出现在删掉的内容栏里。你可以随时重新收录你的网页,只要删掉robots.txt中的相关内容或相关页上的robots元标记,然后点击Reinclude。删除内容的有效期是六个月。六个月后,如果我们重新爬行网页时网页内容仍然是被阻截的或者返回一个404或410状态信息,它就不会被重新索引。不过,如果六个月后该页面可以被我们的抓取工具抓取,我们将再次把它列入我们的索引。
请求删除不是你拥有的内容
如果您想要求删除的内容在不属于你的网站上,怎么办呢?现在做到这一点更容易了。我们的新的网页删除请求工具逐步和你完成每个类型的删除过程。
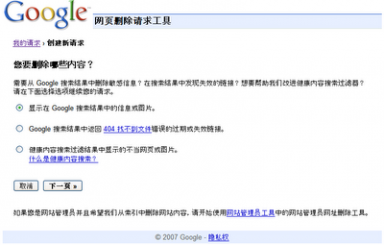
因为Google仅仅索引网页,并不能控制网页的内容,我们通常不能从我们的索引中随便删除一些结果,除非网络管理员阻截Google、修改了内容或删除了页面。如果您想删除某些内容,你可以和网站所有者进行一下沟通,然后用此工具来加速从我们的搜索结果删除。
但是,如果您发现搜索结果中包含特定类型的个人信息,你可以请求删除,即使你不能和网站所有者沟通。对于这种类型的删除,请提供您的电子邮件地址,以便我们能够与您直接沟通。
当启动健康内容搜索时,如果您发现一些搜索结果中有不健康的内容,你也可以使用工具通知我们。
你可以查阅“等候中”请求的状态。在当前网站管理员工具的版本中,一旦请求被处理,请求状态将会变成“已删除”或“拒绝”。一般来说,如果被拒绝,它一定是不满足被删除的条件。对涉及个人信息的请求,您看不到任何状态,但是你会收到一封电子邮件来要求你为以后的步骤提供更多的资料。
老的URL删除工具中的请求会有什么样的结果呢?
如果您已经用老的URL删除工具提交了删除请求,你仍然可以登录来查阅这些请求的状态。但是,如果你有新的请求,请使用现在的新的和改进的工具版本。
注:相关网站建设技巧阅读请移步到建站教程频道。
本文标题:删除索引-Google删除网站索引浅析61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1