一 : 谷歌官方《搜索引擎优化指南》网站内容篇
提供高质量的内容和服务
创建让人眼前一亮且有价值的内容较之于这个指南里讨论的因素更容易影响你的网站。用户看到后知道你网站上提供的内容质量很不错,这样他们也更喜欢引导其它用户到你的网站上来。比如说通过博客文章、社会媒体服务、电子邮箱、论坛或者其它方式。口口相传可以在用户和Google两者里构建你网站的信誉,而如果没有高质量的内容这一点是很难实现的。

一个Blogger发现你网站的一些很不错的内容后,比如说这个棒球卡片网站,很可能在他的博客里提到。不管怎样,你创建的内容可以涉及任何可以想象得到的主题,不过这里也有一些很值得推荐的实践经验。
网站内容优化实战经验
1.撰写容易阅读的文字——用户常常很喜欢那些写得很不错又很容易阅读的内容,但是可能要注意下面提到的几点:
写一些含有大量拼写或语法错误的马虎文章。
直接把文字插入到图片里以当网页的文字内容。(这样的话用户就不可以复制并粘贴了,而搜索引擎也没法识别图片里的文字。)(因为Google是极其重视原创的,你完全可以打消文章被人窃取的顾虑,译者注。)
2.尽量有序地围绕你的主题——有序地组织你的内容常常是很有帮助的,它可以让用户对哪里是开头哪里是结尾有一个很直观的判断。把你的内容分解成一块一块的,可以帮助用户更快地找到他们想要的。只是你可能需要避免以下问题:
把不同主题的大量文字扔在一张网页且,甚至没有分段,没有副标题,没有分层布局。
3.使用相关的语言——试着想一下用户如果要查询你网站里的一部分内容他会使用的关键词。对某个话题是行家的人来说,他们使用的关键词和那些新手比起差别是很大的。 Google AdWords提供了一个便捷的关键词工具可以帮助你发现一些不断变化的新关键词也可以为某一个关键词提供一些接近搜索关键词。同样的,Google网站管理员工具也为你提供一个热门搜索查询来列出那些在搜索结果中你网站内容出现次数最多和为你网站带来了有效点击的关键词。
4.创建一些新鲜而又独特的内容——新的内容不仅可以保证你现有的用户群的回访,与此同时还会带来更多的新访客。在这一点上尤其需要注意避免:
大量不断重复(甚至是复制)的内容不会给你的用户带来多少好处的。
在你的网站里有大量重复或者接近重复的版本。
5.提供别人没有的内容或服务——试着创建一些其它站点无法提供的有用且新鲜的服务。你可以写一些研究的原始报告,打破一些现已存在的新闻故事或者平衡一下你唯一的用户群。其它站点可能正缺乏做这些事的资源或者能力。
6.优先为你的用户提供内容,而不是搜索引擎——在保证搜索引擎可以为你的网站生成积极结果的同时,应根据用户的需要来设计你的网站。只是要避免:
针对搜索引擎插入大量无任何意义的关键词,这只会用户感到厌恶。
让一些文字只供搜索引擎查看,对用户却是隐藏的。(来源:Google网站管理员博客 翻译:个篱遐想录)
注:相关网站建设技巧阅读请移步到建站教程频道。
二 : zabbix优化指南
很不错的文章,收藏,学习用~原文地址:zabbix优化指南作者:polygun2000本文是我综合了参考资料中的1大堆东西捏在一起的,单纯是翻译整理了一下,另外配了一些图,其他基本没有什么原创内容。
1.如何度量Zabbix性能
通过Zabbix的NVPS(每秒处理数值数)来衡量其性能。
在Zabbix的dashboard上有1个错略的估值。
![[转载]zabbix优化指南](http://p.61k.com/cpic/f2/21/d110e9ea204b47089edf4f14fde221f2.jpg)
在4核CPU,6GB内存,RAID10(带有写入缓存)这样的配置条件下,Zabbix可以处理每分钟1M个数值,大约每秒15000个。
2.性能低下的可见症兆
3.哪些因素造成Zabbix性能低下
因素 | 慢 | 快 |
数据库大小 | 巨大 | 适应内存大小 |
触发器表达式的复杂程度 | Min(),max(),avg() | Last(),nodata() |
数据收集方法 | 轮讯(SNMP,无代理,Passive代理) | Trapping(active代理) |
数据类型 | 文本,字符串 | 数值 |
前端用户数量 | 多 | 少 |
主机数量也是影响性能的主要因素
![[转载]zabbix优化指南](http://p.61k.com/cpic/7b/3d/b627ccfd424b71cd2fd28215abe43d7b.jpg)
4.了解Zabbix工作状态
获得zabbix内部状态
zabbix[wcache,values,all]
zabbix[queue,1m]----延迟超过1分钟的item
![[转载]zabbix优化指南](http://p.61k.com/cpic/68/b1/48380a745d2c06519c48add1f18eb168.jpg)
获得zabbix内部组件工作状态(该组件处于BUSY状态的时间百分比)
zabbix[process,type,mode,state]
其中可用的参数为:
type: trapper,discoverer,escalator,alerter,etc
mode: avg,count,min,max
state: busy,idel
![[转载]zabbix优化指南](http://p.61k.com/cpic/e6/54/88028d14175286a13fb4be179d9d54e6.jpg)
![[转载]zabbix优化指南](http://p.61k.com/cpic/5b/67/0ee501b5ca52ee671f48825fd832675b.jpg)
5.Zabbix调优大的原则性建议
6.Zabbix数据库调优
a.使用专用数据服务器,配置应该较高
给1个参考配置,可以处理NVPS为3000
Dell PowerEdge R610
CPU:Intel Xeon L5520 2.27GHz (16 cores)
Memory: 24GB RAM
Disks:6x SAS 10k 配置 RAID10
b.每个table1个文件,修改my.cnf
innodb_file_per_table=1
c.使用percona替代MySQL
d.使用分区表,关闭Houerkeeper
关闭Houserkeeper,zabbix_server.conf
DisableHousekeeper=1
![[转载]zabbix优化指南](http://p.61k.com/cpic/e2/6f/96a32c2f58ebb3eeaadea96930486fe2.png)
step1.准备相关表
ALTERTABLE `acknowledges` DROP PRIMARY KEY, ADD KEY `acknowledgedid`(`acknowledgeid`);
ALTERTABLE `alerts` DROP PRIMARY KEY, ADD KEY `alertid`(`alertid`);
ALTERTABLE `auditlog` DROP PRIMARY KEY, ADD KEY `auditid`(`auditid`);
ALTERTABLE `events` DROP PRIMARY KEY, ADD KEY `eventid`(`eventid`);
ALTERTABLE `service_alarms` DROP PRIMARY KEY, ADD KEY `servicealarmid`(`servicealarmid`);
ALTERTABLE `history_log` DROP PRIMARY KEY, ADD PRIMARY KEY(`itemid`,`id`,`clock`);
ALTERTABLE `history_log` DROP KEY `history_log_2`;
ALTERTABLE `history_text` DROP PRIMARY KEY, ADD PRIMARY KEY(`itemid`,`id`,`clock`);
ALTERTABLE `history_text` DROP KEY `history_text_2`;
step2.设置每月的分区
以下步骤请在第1步的所有表中重复,下例是为events表创建2011-5到2011-12之间的月度分区。
ALTERTABLE `events` PARTITION BY RANGE( clock ) (
PARTITION p201105 VALUES LESS THAN(UNIX_TIMESTAMP("2011-06-01 00:00:00")),
PARTITION p201106 VALUES LESS THAN(UNIX_TIMESTAMP("2011-07-01 00:00:00")),
PARTITION p201107 VALUES LESS THAN(UNIX_TIMESTAMP("2011-08-01 00:00:00")),
PARTITION p201108 VALUES LESS THAN(UNIX_TIMESTAMP("2011-09-01 00:00:00")),
PARTITION p201109 VALUES LESS THAN(UNIX_TIMESTAMP("2011-10-01 00:00:00")),
PARTITION p201110 VALUES LESS THAN(UNIX_TIMESTAMP("2011-11-01 00:00:00")),
PARTITION p201111 VALUES LESS THAN(UNIX_TIMESTAMP("2011-12-01 00:00:00")),
PARTITION p201112 VALUES LESS THAN(UNIX_TIMESTAMP("2012-01-01 00:00:00"))
);
step3.设置每日的分区
以下步骤请在第1步的所有表中重复,下例是为history_uint表创建5.15到5.22之间的每日分区。
ALTERTABLE `history_uint` PARTITION BY RANGE( clock ) (
PARTITION p20110515 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-16 00:00:00")),
PARTITION p20110516 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-17 00:00:00")),
PARTITION p20110517 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-18 00:00:00")),
PARTITION p20110518 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-19 00:00:00")),
PARTITION p20110519 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-20 00:00:00")),
PARTITION p20110520 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-21 00:00:00")),
PARTITION p20110521 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-22 00:00:00")),
PARTITION p20110522 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-23 00:00:00"))
);
手动维护分区:
增加新分区
ALTERTABLE `history_uint` ADD PARTITION (
PARTITION p20110523 VALUES LESS THAN(UNIX_TIMESTAMP("2011-05-24 00:00:00"))
);
删除分区(使用Housekeepeing)
ALTERTABLE `history_uint` DROP PARTITION p20110515;
step4.自动每日分区
确认已经在step3的时候为history表正确创建了分区。
以下脚本自动drop和创建每日分区,默认只保留最近3天,如果你需要更多天的,请修改
@mindays 这个变量。
不要忘记将这条命令加入到你的cron中!
mysql-B -h localhost -u zabbix -pPASSWORD zabbix -e "CALLcreate_zabbix_partitions();"
自动创建分区的脚本:
https://github.com/xsbr/zabbixzone/blob/master/zabbix-mysql-autopartitioning.sql
DELIMITER //
DROP PROCEDURE IF EXISTS`zabbix`.`create_zabbix_partitions` //
CREATE PROCEDURE`zabbix`.`create_zabbix_partitions` ()
BEGIN
CALLzabbix.create_next_partitions("zabbix","history");
CALLzabbix.create_next_partitions("zabbix","history_log");
CALLzabbix.create_next_partitions("zabbix","history_str");
CALLzabbix.create_next_partitions("zabbix","history_text");
CALLzabbix.create_next_partitions("zabbix","history_uint");
CALLzabbix.drop_old_partitions("zabbix","history");
CALLzabbix.drop_old_partitions("zabbix","history_log");
CALLzabbix.drop_old_partitions("zabbix","history_str");
CALLzabbix.drop_old_partitions("zabbix","history_text");
CALLzabbix.drop_old_partitions("zabbix","history_uint");
END //
DROP PROCEDURE IF EXISTS`zabbix`.`create_next_partitions` //
CREATE PROCEDURE`zabbix`.`create_next_partitions` (SCHEMANAME varchar(64),TABLENAME varchar(64))
BEGIN
DECLARE NEXTCLOCK timestamp;
DECLARE PARTITIONNAMEvarchar(16);
DECLARE CLOCK int;
SET @totaldays = 7;
SET @i = 1;
createloop: LOOP
SET NEXTCLOCK = DATE_ADD(NOW(),INTERVAL @iDAY);
SET PARTITIONNAME = DATE_FORMAT(NEXTCLOCK, 'p%Y%m%d' );
SET CLOCK =UNIX_TIMESTAMP(DATE_FORMAT(DATE_ADD( NEXTCLOCK ,INTERVAL 1DAY),'%Y-%m-%d 00:00:00'));
CALL zabbix.create_partition( SCHEMANAME,TABLENAME, PARTITIONNAME, CLOCK );
SET @i=@i+1;
IF @i > @totaldaysTHEN
LEAVE createloop;
END IF;
END LOOP;
END //
DROP PROCEDURE IF EXISTS`zabbix`.`drop_old_partitions` //
CREATE PROCEDURE`zabbix`.`drop_old_partitions` (SCHEMANAME varchar(64), TABLENAMEvarchar(64))
BEGIN
DECLARE OLDCLOCK timestamp;
DECLARE PARTITIONNAMEvarchar(16);
DECLARE CLOCK int;
SET @mindays = 3;
SET @maxdays = @mindays+4;
SET @i = @maxdays;
droploop: LOOP
SET OLDCLOCK = DATE_SUB(NOW(),INTERVAL @iDAY);
SET PARTITIONNAME = DATE_FORMAT( OLDCLOCK,'p%Y%m%d' );
CALL zabbix.drop_partition( SCHEMANAME,TABLENAME, PARTITIONNAME );
SET @i=@i-1;
IF @i <= @mindaysTHEN
LEAVE droploop;
END IF;
END LOOP;
END //
DROP PROCEDURE IF EXISTS`zabbix`.`create_partition` //
CREATE PROCEDURE`zabbix`.`create_partition` (SCHEMANAME varchar(64), TABLENAMEvarchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN
DECLARE RETROWS int;
SELECT COUNT(1) INTO RETROWS
FROM`information_schema`.`partitions`
WHERE `table_schema` = SCHEMANAME AND`table_name` = TABLENAME AND `partition_name` =PARTITIONNAME;
IF RETROWS = 0 THEN
SELECT CONCAT( "create_partition(",SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" )AS msg;
SET @sql = CONCAT( 'ALTER TABLE `',SCHEMANAME, '`.`', TABLENAME, '`',
' ADD PARTITION (PARTITION ',PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END //
DROP PROCEDURE IF EXISTS`zabbix`.`drop_partition` //
CREATE PROCEDURE `zabbix`.`drop_partition`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAMEvarchar(64))
BEGIN
DECLARE RETROWS int;
SELECT COUNT(1) INTO RETROWS
FROM`information_schema`.`partitions`
WHERE `table_schema` = SCHEMANAME AND`table_name` = TABLENAME AND `partition_name` =PARTITIONNAME;
IF RETROWS = 1 THEN
SELECT CONCAT( "drop_partition(",SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ")" ) ASmsg;
SET @sql = CONCAT( 'ALTER TABLE `',SCHEMANAME, '`.`', TABLENAME, '`',
' DROP PARTITION ', PARTITIONNAME, ';');
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END //
DELIMITER ;
e.使用tmpfs存储临时文件
mkdir /tmp/mysqltmp
修改/etc/fstab:
tmfs /tmp/mysqltmp tmpfsrw,uid=mysql,gid=mysql,size=1G,nr_inodes=10k,mode=0700 0 0
修改my.cnf
tmpdir=/tmp/mysqltmp
f.设置正确的buffer pool
设置Innodb可用多少内存,建议设置成物理内存的70%~80%
修改my.cnf
innodb_buffer_pool_size=14G
设置innodb使用O_DIRECT,这样buffer_pool中的数据就不会与系统缓存中的重复。
innodb_flush_method=O_DIRECT
以下给1个示例my.cnf,物理内存大小为24G:
![[转载]zabbix优化指南](http://p.61k.com/cpic/da/8f/a21ecadc2b46cced3fcd4b408b508fda.jpg)
g.设置合适的log大小
zabbix数据库属于写入较多的数据库,因此设置大一点可以避免MySQL持续将log文件flush到表中。
不过有1个副作用,就是启动和关闭数据库会变慢一点。
修改my.cnf
innodb_log_file_size=64M
h.打开慢查询日志
修改my.cnf
log_slow_queries=/var/log/mysql.slow.log
i.设置thread_cache_size
这个值似乎会影响show global status输出中Threads_created perConnection的hit rate
当设置成4的时候,有3228483 Connections和5840 Threads_created,hitrate达到了99.2%
Threads_created这个数值应该越小越好。
j.其他MySQL文档建议的参数调整
query_cache_limit=1M
query_cache_size=128M
tmp_table_size=256M
max_heap_table_size=256M
table_cache=256
max_connections = 300
innodb_flush_log_at_trx_commit=2
join_buffer_size=256k
read_buffer_size=256k
read_rnd_buffer_size=256k
7.调整zabbix工作进程数量,zabbix_server.conf
StartPollers=90
StartPingers=10
StartPollersUnreacheable=80
StartIPMIPollers=10
StartTrappers=20
StartDBSyncers=8
LogSlowQueries=1000
参考文档:
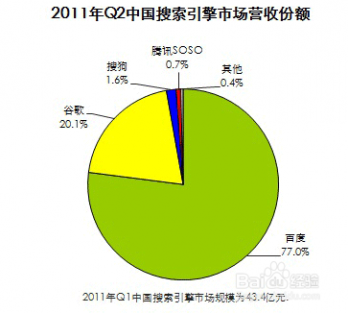
三 : 搜索引擎优化指南知多少
[搜索引擎优化指南]搜索引擎优化指南知多少——简介 [搜索引擎优化指南]搜索引擎优化指南知多少——搜索引擎优化
[搜索引擎优化指南]搜索引擎优化指南知多少——搜索引擎优化 [搜索引擎优化指南]搜索引擎优化指南知多少——搜索引擎优化
[搜索引擎优化指南]搜索引擎优化指南知多少——搜索引擎优化



 [搜索引擎优化指南]搜索引擎优化指南知多少——日月之美003
[搜索引擎优化指南]搜索引擎优化指南知多少——日月之美003
四 : 用Python和OpenCV创建一个图片搜索引擎的完整指南 - Python
本文由 伯乐在线 - Daetalus 翻译,sunbiaobiao 校稿。未经许可,禁止转载!大家都知道,通过文本或标签来搜索图片的体验非常糟糕。
无论你是将个人照片贴标签并分类,或是在公司的网站上搜索一堆照片,还是在为下一篇博客寻找合适的图片。在用文本和关键字来描述图片是非常痛苦的事。
我就遇到了这样的痛苦的事情,上周二我打开了一个很老的家庭相册,其中的照片是9年前扫描成电子档的。
我想找到我家在夏威夷海滩拍的照片。我用iPhoto打开相册,慢慢的浏览。这个过程非常辛苦,每个JPEG图像的元信息中的日期都是错的。我已经不记得文件夹中的图片是如何排列的,我绝望的搜索海滩的照片,但还是找不到。
也许是运气,我跌跌撞撞的找到了其中一幅海滩上的照片。多美的一幅照片啊。蓝天中飘着棉花糖般的白云。晶莹透彻的海水,像丝绸一样掠过在金色的沙滩上。我几乎可以感觉微风轻抚着面庞,呼吸着海边湿润的空气。
找到这幅照片后,我停止了手动搜索,打开一个代码编辑器。
虽然iPhoto这样的应用能让你将相片分组,甚至可以检测人脸,但我们可以做的更多。
注意,我并不是介绍如何手动给图片添加标签。我是在介绍更强大的东西。比如通过一幅图片来搜索一组相似的图片。
这是不是很酷?只需鼠标点击一次就可以可视化搜索图片。
这就是我的工作内容。我用半个小时写好代码,完成了一个针对家庭假期相册的图片搜索引擎。
然后用上面找到的那张海滩图片作为搜索源。几秒后我就找到了相册中其他的海滩图片,其中没有任何为某张图片添加标签的动作。
感兴趣吗,我们继续。
在本文的其他部分,我将介绍如何自己创建一个图像搜索引擎。
想要文本中的代码?
直接跳到文本中的最后的“下载”一节。
读者也许会问,什么才是一个真正的图像搜素引擎?
我的意思是,我们都熟悉基于文本的搜索引擎,如Google、Bing、Baidu等。用户只需输入几个与内容相关的关键字,接着就会获得搜索结果。但对于图像搜索引擎,其工作方式就有点区别。搜索时使用的不是文字,而是图片。
听起来很困难,我的意思是,如何量化图像的内容,让其可搜索呢?
本文将逐步回答这个问题。首先,先了解一下图像搜索引擎的内容。
一般来说,有三种类型的图像搜索引擎:基于元数据、基于例子、混合模式。
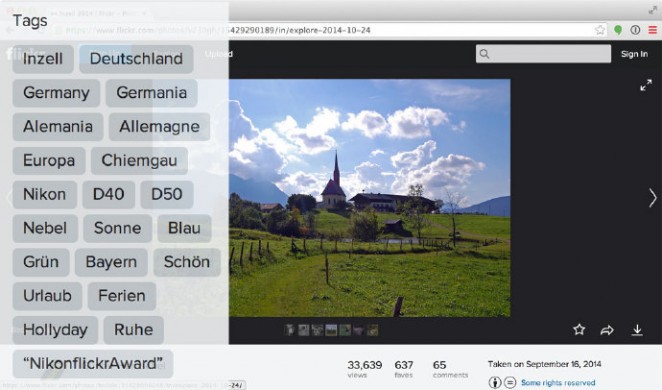
图1:基于元数据的图像搜索引擎的例子。注意其中关键字和标签是手动关联到图像上的。
通过元数据搜索与标准的关键字搜索引擎没有本质的不同。这种方式很少检测图像本身的内容。而是用相关的文本信息:如手动注释或添加标签;以及自动上下文提示(如网页中该图片附近的文字信息)。
当用户在基于元数据的系统上进行搜索时,与传统的文本搜索引擎其实差点不多的。得到的是含有类似标签或注释的图片。
再次说明,使用基于元数据系统的工具进行搜索,基本上是不查找图像本身的。
用基于元数据进行搜索的应用中,一个比较好的例子就是Flickr。将图像上传到Flickr后,输入一些文本作为标签描述这幅图像。接着Flickr会使用这些关键字进行搜索,查找并推荐其他相关的图像。

图2:TinEye就是一个基于例子的图像搜索引擎。该搜索引擎会使用图像本身的内容进行搜索,而不是使用文本搜索。
另一方面,基于例子搜索仅仅依赖于图像的内容,不需要提供关键字。引擎会分析、量化并存储图像,然后返回其他相关的图像。
图像搜索引擎量化图像内容的过程称为基于内容的图像信息获取(Content-Based Image Retrieval,CBIR)系统。术语CBIR通常用在学术文献中,但在实际上,这是“图像搜索引擎”的另一种表述,并特意指明该搜索引擎是严格基于图像的内容的,没有任何关于图像的文本的信息。
基于例子系统的一个比较好的例子就是TinEye。向TinEyet提交待查找图像时,TinEye实际上是一个逆向图像搜索引擎,TinEye返回该图像最相近的匹配,以及该图像位于的原始网页地址。
看下本节刚开始的示例图像。我上传了一个Google logo图像。TinEye检测了图像的内容,在搜索了超过60亿幅图片后,返回了1.3万个含有Google logo图片的网页。
所以仔细想一下:你需要为TinEye中的60亿幅图像收到添加标签吗?当然不需要,为这么多图片手动添加标签需要庞大的人力物力。
取而代之,使用某些算法从图像本身中提取“特征”(如用一组数字来量化并抽象表示图像)。接着,当用户提交了需要查找的图像,从这幅图像中提取特征,将其与数据库中的特征进行比较,尝试返回相似的图像。
同样,依然需要强调,基于例子的搜索系统非常依赖图像的内容。这种类型的系统很难构建并扩展,但可以用算法全自动的搜索,无需人工干预。
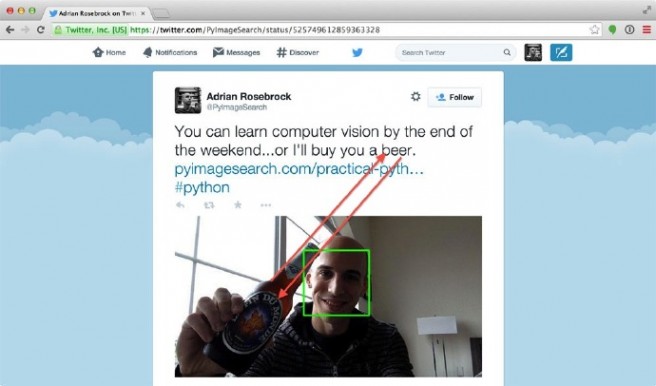
图3:混合式图像搜索引擎可以同时基于图像和文本描述搜索。
当然,除了前面介绍的两种方式,还有一种介于两者之间的方式,如Twitter使用的。
在Twitter上,可以与推文一起上传图像。这样就可以即使用提取图像本身的特征,也可以使用推文中的文本,从而诞生一种混合方式。基于这种方式可以可以构建一个即使用上下文关系,又使用基于例子搜索的策略的图像搜索引擎。
提示:有兴趣阅读更多关于不同类型的图像搜索引擎的资料?我有一篇完整的博客介绍比较这些搜索引擎的,链接在此。
在进一步描述和构建图像搜索引擎之前,让我们先来了解一些重要的术语。
在深入了解之前,先花点时间了解一些重要的术语。
在构建图像搜索引擎时,首先要对数据集编列索引。索引化数据集是量化数据集的过程,即通过图像描述符(image descriptor,也称描述子)提取每幅图像的特征。
图像描述符就是用来描述图像的算法。
例如:
R、G、B三色通道的均值和标准差。图像特征形状的统计矩.形状和纹理的梯度和朝向。这里最重要的是图像描述符确定了图像是如何量化的。
另一方面,特征是图像描述符的输出。当将一幅图像放入图像描述符中时,就会获得这幅图像的特征。
以基本的术语来说。特征(或特征向量)仅仅是一个用来抽象表示或量化的图像的数字列表。
来看下面这幅示例图像:
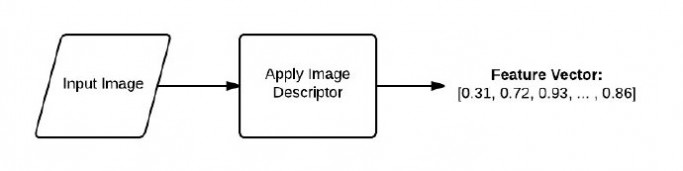
图4:图像描述符的管道。描述符中有一幅输入图像,使用图像描述符会返回一个特征向量(一个数字列表),
这里对一幅输入图像使用图像描述符,输出是一组用来量化图像的数字。
通过距离量测或其他相似度比较函数,特征向量可以用来表示比较的相似度。距离量测和相似度函数采用两个特征向量作为输入,返回一个数值来描述着两个特征向量的相似度。
下图以可视化的方式比较了两幅图的比较过程:
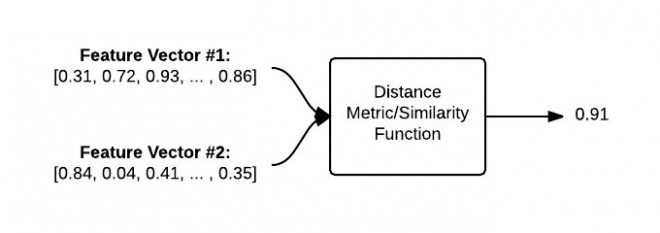
图5:为了比较两幅图,必须将对应的特征向量输入进距离量测/相似度比较函数。输出结果是一个数值,量化地描述两幅图下的相似度。
给定两个特征向量,使用距离函数来确定这两个特征向量的相似度。距离函数的输出是一个浮点数,用来描述两幅图像的相似度。
无论构建的是什么样的CBIR系统,最终都可以分解成4个不同的步骤。
定义图像描述符:在这一阶段,需要决定描述图像的哪一方面。是关注图像的颜色,还是图像中的物体形状,或是图像中的纹理?索引化数据集:现在有了图像描述符,接着就是将这个图像描述符应用得到数据集中的每幅图像,提取这些图像的特征,将其存储起来(如CSV文件、RDBMS、Redis数据库中,等),这样后续步骤就能使用以便比较。定义相似矩阵:很好,现在有了许多特征向量。但如何比较这些特征向量呢?流行的方式是比较欧几里德距离、余弦距离、或卡方距离。但实际中取决于两点:1、数据集;2、提取的特征类型。搜索:最后一步是进行实际的搜索。用户会向系统提交一幅需要搜索的图片(例如从上传窗口或通过移动App提交),而你的任务是:1、提取这幅图像的特征;2、使用相似度函数将这幅图像的特征与已经索引化的特征进行比较。这样,只需根据相似度函数的结果,返回相关的图像就可以了。再次强调,这是所有CBIR系统中最基本的4步。如果使用的特征表示不同,则步骤数会增加,也会为每个步骤增加一定数量的子步骤。就目前而言,让我们关注并使用这4步。
下面通过图像来具体了解这4个大步骤。下图表述的是步骤1和2:
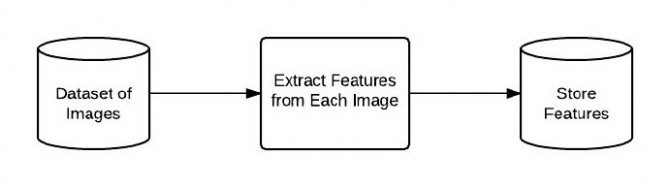
图6:处理并提取数据集中的每幅图像的流程图。
首先提取数据集中每幅图像的特征,将这些特征存入一个数据库。
接着可以执行搜索(步骤3和4):
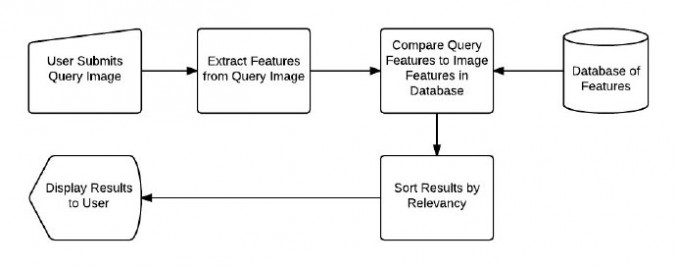
图7:在CBIR系统中执行搜索。用户提交一个搜索请求,系统对搜索图像进行描述,其特征会与数据集中已有的特征进行比较,并对结果根据相关度进行排序,返回给用户。
首先,用户必须像搜索引擎提交一幅需要查找的图像。接着对这幅图像提取特征信息。将这些特征信息与数据集中已有的图像的特征信息进行比较。最后,对结果根据相关度进行排序并返回给用户。
这里将INRIA假期数据集作为图像搜索的数据集。
这个数据集含有全世界许多地方的假期旅行,包括埃及金字塔、潜水、山区的森林、餐桌上的瓶子和盘子、游艇、海面上的日落。
下面是数据集中的一些图片:

图8:数据集中的示例图像。我们将使用这些图像构建自己的图像搜索引擎。
在本例中,对于我们希望从旅行相册中找到某种景色的相片来说,用这幅数据集作为示例来说非常好。
我们的目标是构建一个个人图像搜索引擎。将假期照片作为数据集,我们希望将这个数据集变成可搜索的,即一个“基于例子”的图像搜索引擎。例如,如果我提交了一幅在河中航行的帆船的照片,图像搜索引擎应该能找到并返回相册中码头和船坞拍摄的照片。
看下面的图,其中有我提交的照片,即一幅在水里的船。得到了假期照片集合中相关的图像。

图9:图像搜索引擎的例子。提交了一幅含有海中船只的图像。返回相关的图像,这些图像都是在海中的船。
为了构建这个系统,将使用一个简单且有效的图像描述符:颜色直方图。
通过将颜色直方图作为我们的图像描述符,可以根据图像的色彩分布提取特征。由于这一点,我们可以对我们的图像搜索引擎做个重要的假设:
假设:如果图像含有相似的色彩分布,那么这两幅图像就认为是相似的。即使图像的内容差别非常大,依然会根据色彩分布而被认为是相近的。
这个假设非常重要,在使用颜色直方图作为图像描述符时,这是个公平且合理的假设。
这里不使用标准的颜色直方图,而是对其进行一些修改,使其更加健壮和强大。
这个图像描述符是HSV颜色空间的3D颜色直方图(色相、饱和度、明度)。一般来说,图像由RGB构成的元组表示。通常将RGB色彩空间想象成一个立方体,如下图所示。
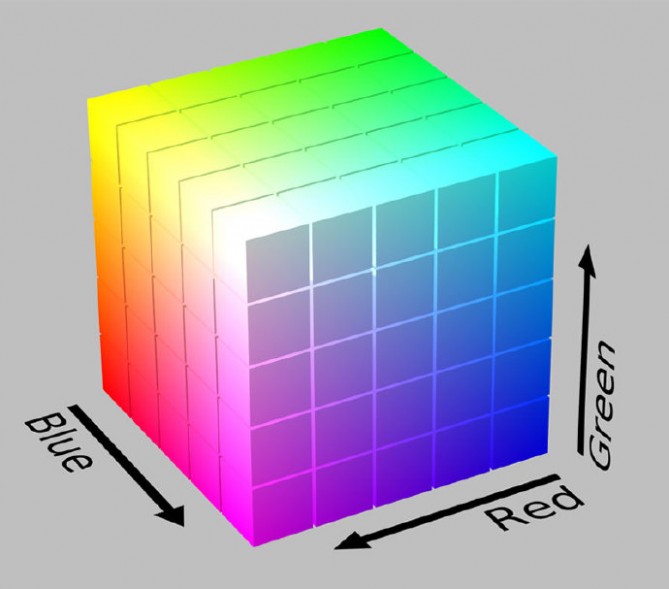
图10:RGB立方体的例子。
然而,虽然RGB值很容易理解,但RGB色彩空间无法模拟人眼接受到的色彩。取而代之,我们使用HSV色彩空间将像素点的映射到圆bin体上。
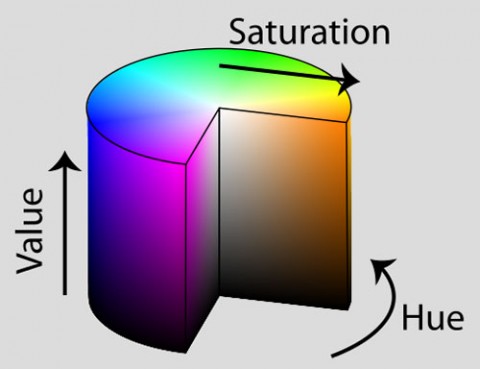
图11:HSV圆bin体的例子。
还有其他颜色空间能够更好的模拟人眼接收的颜色,如CIE L*a*b*和CIE XYZ颜色空间,但作为第一个图像搜索引擎的实现,先简化使用的色彩模型。
现在选定了颜色空间,接着需要定义直方图中bin的数量。直方图用来粗略的表示图像中各强度像素的密度。本质上,直方图会估计底层函数的概率密度。在本例中,P是图像I中像素色彩C出现的概率。
主要注意的是,为直方图选取bin的数目需要不断的权衡。如果选择的bin数目过少,那么直方图含有的数据量就不够,无法区分某些不同颜色分布的图像。反之,如果直方图选取的bin的数目过多,那么其中的组件就过多,导致内容很相近的图片也会判断成不相似。
下面是直方图bin过少的例子。

图12:9个bin直方图的例子。注意其中bin的数量很少,只有少数给定的像素值位列其中。
注意其中只有少数几个bin及相应的像素值。
下面是直方图bin过多的例子。
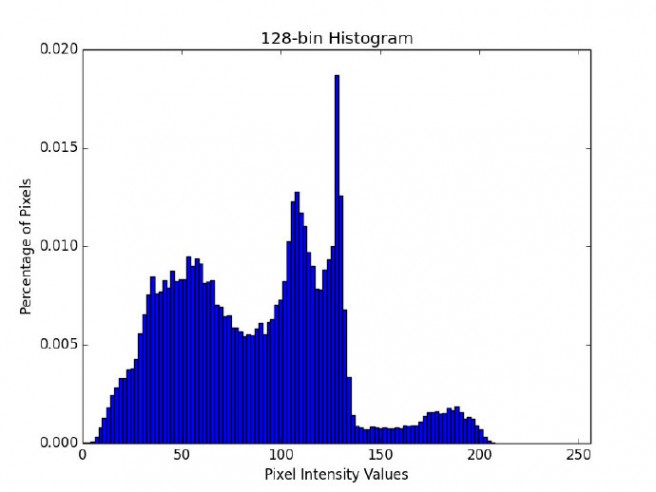
图13:128 bin直方图的例子。注意其中含有许多的柱和相应的像素值。
在上面的的例子中使用了许多bin,bin的数目过多,由于需要直方图中每个“山峰”和“山谷”都需要匹配才能认为图像是“相似的”,所以就失去了“概括”图像的能力。
就我个人而言,我喜欢用迭代、实验性的方式来调整bin的数目。迭代方法一般基于数据集的大小调整。数据集越小,使用的bin的数目就越少。如果数据集非常大,则会使用更多的bin,这样可以让直方图更大,更能区分图像。
一般来说,读者需要为颜色直方图描述符实验bin的个数,具体取决于数据集的大小和数据集中图像之间色彩分布的差异。
对于我们的假期照片图像搜索引擎,将在HSV色彩空间中使用3D颜色直方图,8个bin用于色相通道、12个bin用于饱和度通道、3个bin用于明度通道,总共的特征向量有8 × 12 × 3=288。
这意味着数据集中的每幅图像,无论其像素数目是36 × 36,还是2000 × 1800。最终都会用288个浮点数构成的列表抽象并量化表示。
我认为解释3D直方图最好的方式是用连接词AND。一个3D HSV颜色描述符将查找指定图像中1号bin有多少像素含有色相值,AND有多少像素有饱和度值,AND有多少像素有明度值。计算出符合条件的像素值。虽然需要对每个bin重复这个操作,但可以非常高效的完成这个任务。
很酷,是吧!
理论讲解的够多了,下面来开始编码。
用你最喜欢的编辑器打开一个新文件,命名为colordescriptor.py。加入下面代码:
| 123456789101112131415161718 | # import the necessary packagesimport numpy as npimport cv2class ColorDescriptor:def __init__(self, bins):# store the number of bins for the 3D histogramself.bins = binsdef describe(self, image):# convert the image to the HSV color space and initialize# the features used to quantify the imageimage = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)features = []# grab the dimensions and compute the center of the image(h, w) = image.shape[:2](cX, cY) = (int(w * 0.5), int(h * 0.5)) |
首先导入所需的Python模块。用NumPy进行数值处理,用cv2使用OpenCV的Python绑定。
在第五行定义了ColorDescriptor类。该类用来封装所有用于提取图像中3D HSV颜色直方图的逻辑。
ColorDescriptor的__init__方法只有一个参数——bins,即颜色直方图中bin的数目。
在第10行定义describe方法,用于描述指定的图像。
在describe方法中,将图像从RGB颜色空间(或是BGR颜色空间,OpenCV以NumPy数组的形式反序表示RGB图像)转成HSV颜色空间。接着初始化用于量化图像的特征列表features。
17和18行获取图像的维度,并计算图像中心(x, y)的位置。
现在遇到难点。
这里不计算整个图像的3D HSV颜色直方图,而是计算图像中不同区域的3D HSV颜色直方图。
使用基于区域的直方图,而不是全局直方图的好处是:这样我们可以模拟各个区域的颜色分布。例如看下面的这幅图像:

图14:待搜索的图像。
在这幅图像中,很明显,蓝天在图像的上部,而沙滩在底部。使用全局搜索的话,就无法确定图像中“蓝色”区域和“棕色”沙子区域的位置。而是仅仅知道图像中有多少比例是蓝色,有多少比例是棕色。
为了消除这个问题,可以对图像中的不同区域计算颜色直方图:

图15:将图像分为5个不同区域的例子。
对于我们的图像描述符,将图像分为5个不停的区域:1、左上角;2、右上角;3、右下角;4、左下角;以及图像的中央。
使用这些区域,可以粗略模拟出不同的区域。能够表示出蓝天在左上角和右上角,沙滩在左下角和右下角。图像的中央是沙滩和蓝天的结合处。
下面的代码是创建基于区域的颜色描述符:
| 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950 | # import the necessary packagesimport numpy as npimport cv2class ColorDescriptor:def __init__(self, bins):# store the number of bins for the 3D histogramself.bins = binsdef describe(self, image):# convert the image to the HSV color space and initialize# the features used to quantify the imageimage = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)features = []# grab the dimensions and compute the center of the image(h, w) = image.shape[:2](cX, cY) = (int(w * 0.5), int(h * 0.5))# divide the image into four rectangles/segments (top-left,# top-right, bottom-right, bottom-left)segments = [(0, cX, 0, cY), (cX, w, 0, cY), (cX, w, cY, h),(0, cX, cY, h)]# construct an elliptical mask representing the center of the# image(axesX, axesY) = (int(w * 0.75) / 2, int(h * 0.75) / 2)ellipMask = np.zeros(image.shape[:2], dtype = 'uint8')cv2.ellipse(ellipMask, (cX, cY), (axesX, axesY), 0, 0, 360, 255, -1)# loop over the segmentsfor (startX, endX, startY, endY) in segments:# construct a mask for each corner of the image, subtracting# the elliptical center from itcornerMask = np.zeros(image.shape[:2], dtype = 'uint8')cv2.rectangle(cornerMask, (startX, startY), (endX, endY), 255, -1)cornerMask = cv2.subtract(cornerMask, ellipMask)# extract a color histogram from the image, then update the# feature vectorhist = self.histogram(image, cornerMask)features.extend(hist)# extract a color histogram from the elliptical region and# update the feature vectorhist = self.histogram(image, ellipMask)features.extend(hist)# return the feature vectorreturn features |
22和23行用于分别定义左上、右上、右下、和左下区域。
这里,我们需要构建一个椭圆用来表示图像的中央区域。在代码的27行,定义一个长短轴分别为图像长宽75%的椭圆。
接着初始化一个空白图像(将图像填充0,表示黑色的背景),该图像与需要描述的图像大小相同,见28行。
最后,在29行使用cv2.ellipse函数绘制实际的椭圆。该函数需要8个不同的参数:
需要绘制椭圆的图像。这里使用了下面会介绍的“掩模”的概念。两个元素的元组,用来表示图像的中心坐标。两个元组的元组,表示椭圆的两个轴。在这里,椭圆的长短轴长度为图像长宽的75%。椭圆的旋转角度。在本例中,椭圆无需旋转,所以值为0。椭圆的起始角。椭圆的终止角。看上一个参数,这意味着绘制的是完整的椭圆。椭圆的颜色,255表示的绘制的是白色椭圆。椭圆边框的大小。传递正数比会以相应的像素数目绘制椭圆边框。负数表示椭圆是填充模式。在35行为每个角的掩模分配内存,在36行为图像的每个角绘制白色矩形,接着在37行将矩形减去中间的椭圆。
如果将这个过程用图像动态表示,看上去应该是这样的:

图16:为图像中每个需要提取特征的区域构建掩模。
如这个动画所示,我们独立检测每块区域,在迭代中移除每个矩形与图像中间的椭圆重叠的部分。
读者也许会奇怪,“我们不是要提取图像的颜色直方图吗?为什么要做这些掩模的事情?”
问得好!
原因是因为我们需要告诉OpenCV直方图函数我们要提取的颜色直方图的区域。
记住,我们的目标是分开描述图像的每个区域。表述不同区域最高效的方法是使用掩模。对于图像中某个点(x, y),只有掩模中该点位白色(255)时,该像素点才会用于计算直方图。如果该像素点对应的位置在掩模中是黑色(0),将会被忽略。
通过下图可以更加深刻的了解这个概念。

图17:对图像使用掩模。注意左图中只有右图掩模中对应的区域为白色才会显示。
可以看到,只有掩模的区域才会用于直方图的计算中。
很合理,是吧。
所以现在在41行针对每个区域都调用直方图方法。第一个参数是需要提取特征的图像,第二个参数是掩模区域,这样来提取颜色直方图。
histogram方法会返回当前区域的颜色直方图表示,我们将其添加到特征列表中。
46和47行提取图像中间(椭圆)区域的颜色直方图并更新features列表。
最后,在50行像调用函数返回特征向量。
现在来快速浏览下实际的histogram方法:
| 12345678910 | def histogram(self, image, mask):# extract a 3D color histogram from the masked region of the# image, using the supplied number of bins per channel; then# normalize the histogramhist = cv2.calcHist([image], [0, 1, 2], mask, self.bins,[0, 180, 0, 256, 0, 256])hist = cv2.normalize(hist).flatten()# return the histogramreturn hist. |
这里的histogram方法需要两个参数,第一个是需要描述的图像,第二个是mask,描述需要描述的图像区域。
在5和6行,通过调用cv2.calcHist计算图像掩模区域的直方图,使用构造器中的bin数目作为参数。
在7行对直方图归一化。这意味着如果我们计算两幅相同的图像,其中一幅比另一幅大50%,直方图会是相同的。对直方图进行归一化非常重要,这样每个直方图表示的就是图像中每个bin的所占的比例,而不是每个bin的个数。同样,归一化能保证不同尺寸但内容近似的图像也会在比较函数中认为是相似的。
最后,在10行向调用函数返回归一化后的3D HSV颜色直方图。
现在有了定义好的图像描述符,进入第二步,对数据集中的每幅图像提取特征(如颜色直方图)。提取特征并将其持久保存起来的过程一般称为“索引化”。
继续来看对假期照片数据集进行索引化的代码。创建一个新文件,命名为index.py,添加索引化所需的代码:
| 12345678910111213141516 | # import the necessary packagesfrom pyimagesearch.colordescriptor import ColorDescriptorimport argparseimport globimport cv2# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument('-d', '--dataset', required = True,help = 'Path to the directory that contains the images to be indexed')ap.add_argument('-i', '--index', required = True,help = 'Path to where the computed index will be stored')args = vars(ap.parse_args())# initialize the color descriptorcd = ColorDescriptor((8, 12, 3)) |
首先导入所需的模块。注意第一步中的ColorDescriptor类,这里将其放入pyimagesearch模块,以便更好的组织代码。
还需要argparse模块来处理命令行参数、glob来获取图像的文件路径,以及cv2来使用OpenCV的接口。
7-12行用来处理命令行指令。这里需要两个指令,–dataset,表示假期相册的路径。–index,表示输出的CSV文件含有图像文件名和对应的特征。
最后,在16行初始化ColorDescriptor,8 bin拥有色相、12 bin用于饱和度、3 bin用于明度。
现在所有内容都初始化了,可以从数据集提取特征了:
| 12345678910111213141516171819 | # open the output index file for writingoutput = open(args['index'], 'w')# use glob to grab the image paths and loop over themfor imagePath in glob.glob(args['dataset'] + '/*.png'):# extract the image ID (i.e. the unique filename) from the image# path and load the image itselfimageID = imagePath[imagePath.rfind('/') + 1:]image = cv2.imread(imagePath)# describe the imagefeatures = cd.describe(image)# write the features to filefeatures = [str(f) for f in features]output.write('%s,%sn' % (imageID, ','.join(features)))# close the index fileoutput.close() |
在2行代开输出文件,在5行遍历数据集中的所有图像。
对于每幅图像,可以提取一个imageID,即图像的文件名。对于这个作为示例的搜索引擎,我们假定每个文件名都是唯一的,也可以针对每幅图像生产一个UUID。在9行将从磁盘上读取图像。
现在图像载入内存了,在12行对图像使用图像描述符并提取特征。ColorDescriptor的describe方法返回由浮点数构成的列表,用来量化并表示图像。
这个数字列表,或者说特征向量,含有第一步中图像的5个区域的描述。每个区域由一个直方图表示,含有8 × 12 × 3 = 288项。5个区域总共有5 × 288 = 1440维度。。。因此每个图像使用1440个数字量化并表示。
15和16行简单的将图像的文件名和管理的特征向量写入文件。
为了索引化我们的相册数据集,打开一个命令行输入下面的命令:
| 1 | $ python index.py --dataset dataset --index index.csv |
这个脚本运行的很快,完成后将会获得一个名为index.csv的新文件。
使用你最喜欢的文本编辑器打开并查看该文件。
可以看到在.csv文件的每一行,第一项是文件名,第二项是一个数字列表。这个数字列表就是用来表示并量化图像的特征向量。
对index文件运行wc命令,可以看到已经成功对数据集中805幅图像索引化了:
| 12 | $ wc -l index.csv805 index.csv |
现在已经从数据集提取了特征了,接下来需要一个方法来比较这些特征,获取相似度。这就是第三步的内容,创建一个类来定义两幅图像的相似矩阵。
创建一个新文件,命名为searcher.py,让我们在这里做点神奇的事情:
| 123456789101112 | # import the necessary packagesimport numpy as npimport csvclass Searcher:def __init__(self, indexPath):# store our index pathself.indexPath = indexPathdef search(self, queryFeatures, limit = 10):# initialize our dictionary of resultsresults = {} |
首先先导入NumPy用于数值计算,csv用于方便的处理index.csv文件。
在第5行定义Searcher类。Searcher类的构造器只需一个参数,indexPath,用于表示index.csv文件在磁盘上的路径。
要实际执行搜索,需要在第10行调用search方法。该方法需要两个参数,queryFeatures是提取自待搜索图像(如向CBIR系统提交并请求返回相似图像的图像),和返回图像的数目的最大值。
最后,在12行初始化results字典。在这里,字典有很用的用途,每个图像有唯一的imageID,可以作为字典的键,而相似度作为字典的值。
好了,现在将注意力放在这里。这里是发生神奇的地方:
| 1234567891011121314151617181920212223242526272829 | # open the index file for readingwith open(self.indexPath) as f:# initialize the CSV readerreader = csv.reader(f)# loop over the rows in the indexfor row in reader:# parse out the image ID and features, then compute the# chi-squared distance between the features in our index# and our query featuresfeatures = [float(x) for x in row[1:]]d = self.chi2_distance(features, queryFeatures)# now that we have the distance between the two feature# vectors, we can udpate the results dictionary -- the# key is the current image ID in the index and the# value is the distance we just computed, representing# how 'similar' the image in the index is to our queryresults[row[0]] = d# close the readerf.close()# sort our results, so that the smaller distances (i.e. the# more relevant images are at the front of the list)results = sorted([(v, k) for (k, v) in results.items()])# return our (limited) resultsreturn results[:limit] |
在1行打开index.csv文件,在3行获取CSV读取器的句柄,接着在6行循环读取index.csv文件的每一行。
对于每一行,提取出索引化后的图像的颜色直方图,用11行的chi2_distance函数将其与待搜索的图像特征进行比较,该函数在下面介绍。
在32行使用唯一的图像文件名作为键,用与待查找图像的与索引后的图像的相似读作为值来更新results字典。
最后,将results字典根据相似读升序排序。
卡方相似度为零的图片表示完全相同。相似度数值越高,表示两幅图像差别越大。
说到卡方相似读,看下面的源码:
| 1234567 | def chi2_distance(self, histA, histB, eps = 1e-10):# compute the chi-squared distanced = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps)for (a, b) in zip(histA, histB)])# return the chi-squared distancereturn d |
chi2_distance函数需要两个参数,即用来进行比较的两个直方图。可选的eps值用来预防除零错误。
这个函数的名称来自皮尔森的卡方测试统计,用来比较离散概率分布。
由于比较的是颜色直方图,根据概率分布的定义,卡方函数是个完美的选择。
一般来说,直方图两端的值的差别并不重要,可以使用权重对其进行处理,卡方距离函数就是这么做的。
还能跟的上吗?我保证,最后一步是最简单的,仅仅需要将前面的各部分组合在一起。
如果我告诉你,执行搜索是最简单的一步,你信吗?实际上,只需一个驱动程序导入前面定义的所有的模块,将其依次组合成具有完整功能的CBIR系统。
所以新建最后一个文件,命名为search.py,这样我们的例子就能完成了:
| 123456789101112131415161718 | # import the necessary packagesfrom pyimagesearch.colordescriptor import ColorDescriptorfrom pyimagesearch.searcher import Searcherimport argparseimport cv2# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument('-i', '--index', required = True,help = 'Path to where the computed index will be stored')ap.add_argument('-q', '--query', required = True,help = 'Path to the query image')ap.add_argument('-r', '--result-path', required = True,help = 'Path to the result path')args = vars(ap.parse_args())# initialize the image descriptorcd = ColorDescriptor((8, 12, 3)) |
首先导入所需的包,导入第一步的ColorDescriptor来提取待查找图像的特征;导入第三步定义的Searcher类,用于执行执行实际的搜索。
argparse和cv2模块一直会导入。
在8-15行处理命令行参数。我们需要用一个–index来表示index.csv文件的位置。
还需要–query来表示带搜索图像的存储路径。该图像将与数据集中的每幅图像进行比较。目标是找到数据集中欧给你与待搜索图像相似的图像。
想象一下,使用Google搜索并输入“Python OpenCV tutorials”,会希望获得与Python和OpenCV相关的信息。
与之相同,如果针对相册构建一个图像搜索引擎,提交了一副关于云、大海上的帆船的图像,希望通过图像搜索引擎获得相似的图像。
接着需要一个–result-path,用来表示相册数据集的路径。通过这个命令可以选择不同的数据集,向用户显示他们所需要的最终结果。
最后,在18行使用图像描述符提取相同的参数,就如同在索引化那一步做的一样。如果我们是为了比较图像的相似度(事实也正是如此),就无需改变数据集中颜色直方图的bin的数目。
直接将第三步中使用的直方图bin的数目作为参数在第四步使用。
这样会保证图像的描述是连续且可比较的。
现在到了进行真正比较的时候:
| 1234567891011121314151617 | # load the query image and describe itquery = cv2.imread(args['query'])features = cd.describe(query)# perform the searchsearcher = Searcher(args['index'])results = searcher.search(features)# display the querycv2.imshow('Query', query)# loop over the resultsfor (score, resultID) in results:# load the result image and display itresult = cv2.imread(args['result_path'] + '/' + resultID)cv2.imshow('Result', result)cv2.waitKey(0) |
在2行从磁盘读取待搜索图像,在3行提取该图像的特征。
在6和7行使用提取到的特征进行搜索,返回经过排序后的结果列表。
到此,所需做的就是将结果显示给用户。
在9行显示出待搜索的图像。接着在13-17行遍历搜索结果,将相应的图像显示在屏幕上。
所有这些工作完成后,就可以实际操作了。
继续阅读,看最终效果如何。
打开终端,切换到代码所在的目录,执行下面的命令:
| 1 | $ python search.py --index index.csv --query queries/108100.png --result-path dataset |

图18:在相册中搜索含有埃及金字塔的图像。
第一幅图像是待搜索的埃及金字塔。我们的目标是在相册中找到相似的图像。可以看到,在相册中找到了去金字塔游玩拍摄的照片。
我们还游览的埃及其他地方,所以用其他照片搜索试试:
| 1 | $ python search.py --index index.csv --query queries/115100.png --result-path dataset |

图19:使用搜索引起搜索埃及其他地方的图片,注意图中蓝天的位置。
注意我们的搜索图像中,上半部分是蓝天。中间和下半部分是褐色的建筑和土地。
可以肯定,图像搜索引擎会返回上半部分是蓝天,下半部分是棕褐色建筑和沙子的图像。
这是因为我们使用了本文开头介绍的基于区域的颜色直方图描述符。使用这种图像描述符可以粗略的针对每个区域执行,最后的结果中会含有图像每个区域的像素的密度。
旅途的最后一站是海滩,用下面的命令搜索海滩上的图像:
| 1 | $ python search.py --index index.csv --query queries/103300.png --result-path dataset |

图20:使用OpenCV构建CBIR系统来搜索相册。
注意,前3个搜索结果是在相同地点拍摄到的图像。其他图像都含有蓝色的区域。
当然,没有潜水的海滩之旅是不完整的。
| 1 | $ python search.py --index index.csv --query queries/103100.png --result-path dataset |

图21:图像搜索引起再次返回相关的结果。这次是水下冒险。
结果非常棒。前5个结果是同一条鱼,前10幅有9幅是水下探险。
最后,一天的旅途结束了,到了观看夕阳的时候:
| 1 | $ python search.py --index index.csv --query queries/127502.png --result-path dataset |

图22:这个OpenCV图像搜索引起可以查找到相册集中含有夕阳的相片。
搜索结果非常棒,所有的结果都含有夕阳。
这样,你就有了第一个图像搜索引擎:
本文介绍了如何构建一个图像搜索引擎,来查找相册中的图像。
使用颜色直方图对相册中的图像的颜色部分进行分类。接着,使用颜色描述符索引化相册,提取相册中每一副图像的颜色直方图。
使用卡方距离比较图像,这是比较离散概率分布最常见的选择。
接着,实现了提交待搜索图像和返回查找结果的逻辑。
接下来该干什么?
可以看到,使用命令行是与这个图像搜索引擎交互的唯一方式。这样还不是太吸引人
下一篇文章将探索如何将这个图像搜索引擎封装进一个Python网络框架中,让其更易于使用。
代码和数据集总共有约200mb。如果读者想要下载文中用到的代码和图像。请在原文中输入你的邮箱地址,我会给你一个下载代码和数据集的链接。这个链接不仅能下载到代码的zip压缩包,还会收到我送给你的11页关于计算机视觉和图像搜索引擎的资源指南,其中含有文中没有介绍到的一些技术!是不是很不错?别犹豫,赶快在下面输入你的邮箱地址,我会立即给你发送代码的! 在原文填写邮箱(要查看两次邮箱,还得翻墙。不想来回倒腾的童鞋,请戳链接:http://pan.baidu.com/s/1ntsoamP)
小硕一枚,兴趣广泛,关注Python、Go、Java、C++;GUI、Linux、OS和LLVM。(新浪微博:@Sunny2038;CSDN博客。同时寻求工作机会,长三角地区)
查看Daetalus的更多文章 >>
五 : Windows XP优化指南
动手之前,首先要确保以管理员的身份登录操作系统,因为普通用户身份下好些选项是无权使用的。接下来请激活清晰字体(ClearType),ClearType能使桌面的文字看起来更加清晰易读——这对于手提电脑或液晶显示器用户尤其重要,请看下面关闭和打开ClearType(清晰字体)的前后效果对比图:
关闭清晰字体ClearType 打开清晰字体Cleartype61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1