一 : 内容存储公司Pocket获B轮500万美元融资
网易科技讯 7月19日消息,据国外媒体报道,互联网内容存储公司 Pocket在B轮融资中获得500万美元风险投资,领投者为Foundation Capital,Baseline Ventures和谷歌旗下的Google Ventures均参与了融资。三家风投此前曾在A轮为Pocket融资250万美元。
报道称,Pocket打算利用新投资将“save for later”体验带到更多的平台和设备,同时扩展团队,为开发商和内容合作伙伴改善服务。
Pocket允许用户在网络上保存内容,并在任何时间、任何设备上读取,从另一个意义上讲,实现了时间转移、空间转移。该公司于2007年创立,截止2011年,一直都是创办者独立研发产品。
2012年4月份,该公司以名称Pocket重新发布服务,反映了它对媒体服务的支持以及以移动设备为目标的定位。除了以网页浏览为基础的版本,Pocket同样开发了适用于安卓系统和iOS系统的应用。而且它通过API融合进350家第三方应用程序和服务,其中包括Flipboard、Twitter 和Zite。
Pocket声称用户每天保存的内容数量接近100万,包括杂志文章,YouTube视频、食物配方等等。
二 : 内存管理以及内存管理单元简介(MMU)
MMU简介
1. 概念
MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路,同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权。
? 虚拟地址映射为物理地址
? 内存访问授权
另一个概念:内存管理,是指软件运行时对计算机内存资源的分配和使用的技术。其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源。
2. 术语
虚拟地址空间——又称逻辑地址空间,CPU看到的使用的地址空间。32位CPU可以使用0~0xFFFFFFFF(4G)的地址空间。
物理地址空间——实际的内存空间,例如一个256M的内存,实际地址空间也就是0~0x0FFFFFFF(256M)。
VA——virtual address,虚拟地址
PA——physical address,物理地址
3. 背景
? 内存有限
? 内存保护
? 内存碎片
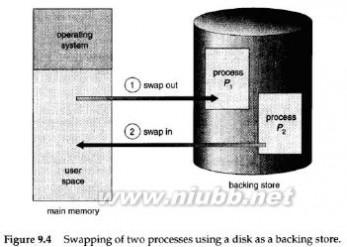
1)内存有限——交换
程序很大,而内存不够一次装入太大的程序。
在磁盘中分配虚拟内存。进程在内存中执行,可以暂时从内存中交换(swap)出去到备份存储上,当需要时再调回到内存中。
2)内存保护

不同进程使用不同的物理地址空间,必须防止不同进程使用同一块内存产生冲突。
内存保护最基本的思路是操作系统为不同进程分配不同的地址空间。可以是逻辑地址,也可以是实际物理地址。(但如果是实际物理地址,操作系统还要负责实际物理地址的分配调度,任务过重,因此设计MMU减轻操作系统负担,负责逻辑地址到物理地址的映射。)
3)内存碎片
最初操作系统的内存是连续分配的,即进程A需要某一大小的内存空间,如200KB,操作系统就需要找出一块至少200KB的连续内存空间给进程A。随着系统的运行,进程终止时它将释放内存,该内存可以被操作系统分配给输入队列里的其他等待内存资源的进程。
可以想象,随着进程内存的分配和释放,最初的一大块连续内存空间被分成许多小片段,即使总的可用空间足够,但不再连续,因此产生内存碎片。
一个办法是不再对内存空间进行连续分配。这样只要有物理内存就可以为进程进行分配。而实际上,不进行连续分配只是相对的,因为完全这样做的代价太大。现实中,往往定出一个最小的内存单元,内存分配是这最小单元的组合,单元内的地址是连续的,但各个单元不一定连续。这样的内存小单元有页和段。
当然,分段和分页也会产生碎片,但理论上每个碎片的大小不超过内存单元的大小。
另外,操作系统分配给进程的逻辑地址就可以是连续的,通过MMU的映射,就可以充分利用不连续的物理内存。
4. MMU原理
? 分页
? 页表查找(映射)
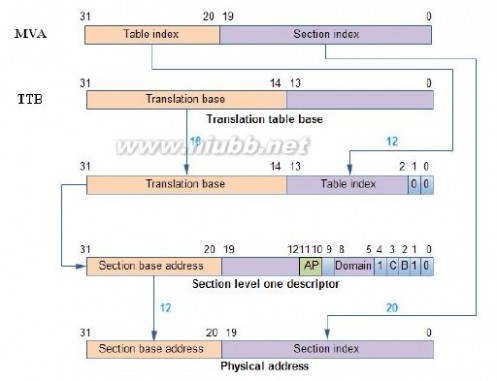
以S3C2440的MMU为例,(ARM920T内核,三星产)
MVA——modified virtual address, 变换后的虚拟地址。一般是在虚拟地址上再标记上进程号。
4.1 分页机制
虚拟地址最终需要转换为物理地址才能读写实际的数据,通过将虚拟地址空
间和物理空间划分为同样大小的空间(段或页),然后两个空间建立映射关系。
在虚拟地址空间上划分的空间单元称为页(page,较大的则称为段section)。在物理地址空间上划分的同样大小的空间单元称为页帧(page frame,或叫页框)。 Linux上地址空间单元大小为4k。
由于虚拟地址空间远大于物理地址,可能多块虚拟地址空间映射到同一块物理地址空间,或者有些虚拟地址空间没有映射到具体的物理地址空间上去(使用到时再映射)。
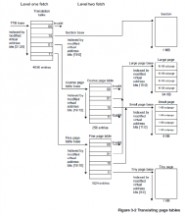
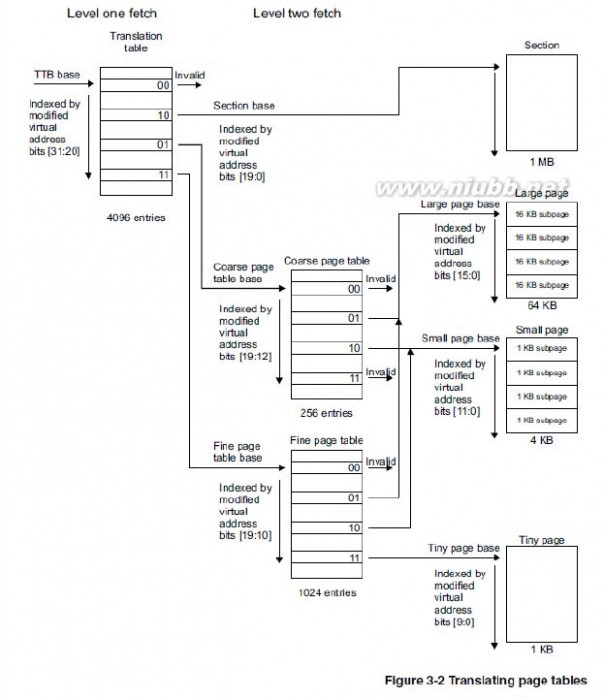
S3C2440最多会用到两级页表,以段(Section,1M)的方式进行转换时只用到一级页表,以页(Page)的方式进行转换时用到两级页表。
页的大小有3种:大页(64KB),小页(4KB),极小页(1KB)。
MVA,32位。
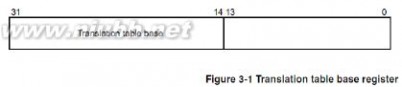
TTB base代表一级页表的地址将它写入协处理器CP15的寄存器C2(称为页表基址寄存器)即可。一级页表的地址使用[31:14]存储页表基址,[13:0]为0。

三 : 内存管理以及内存管理单元简介(MMU)
MMU简介
1. 概念
MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路,同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权。[www.61k.com)
? 虚拟地址映射为物理地址
? 内存访问授权
另一个概念:内存管理,是指软件运行时对计算机内存资源的分配和使用的技术。其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源。
2. 术语
虚拟地址空间——又称逻辑地址空间,CPU看到的使用的地址空间。32位CPU可以使用0~0xFFFFFFFF(4G)的地址空间。
物理地址空间——实际的内存空间,例如一个256M的内存,实际地址空间也就是0~0x0FFFFFFF(256M)。
VA——virtual address,虚拟地址
PA——physical address,物理地址
3. 背景
? 内存有限
? 内存保护
? 内存碎片
1)内存有限——交换
程序很大,而内存不够一次装入太大的程序。
在磁盘中分配虚拟内存。进程在内存中执行,可以暂时从内存中交换(swap)出去到备份存储上,当需要时再调回到内存中。
2)内存保护
i386是什么 内存管理以及内存管理单元简介(MMU)
不同进程使用不同的物理地址空间,必须防止不同进程使用同一块内存产生冲突。(www.61k.com)
内存保护最基本的思路是操作系统为不同进程分配不同的地址空间。可以是逻辑地址,也可以是实际物理地址。(但如果是实际物理地址,操作系统还要负责实际物理地址的分配调度,任务过重,因此设计MMU减轻操作系统负担,负责逻辑地址到物理地址的映射。)
3)内存碎片
最初操作系统的内存是连续分配的,即进程A需要某一大小的内存空间,如200KB,操作系统就需要找出一块至少200KB的连续内存空间给进程A。随着系统的运行,进程终止时它将释放内存,该内存可以被操作系统分配给输入队列里的其他等待内存资源的进程。
可以想象,随着进程内存的分配和释放,最初的一大块连续内存空间被分成许多小片段,即使总的可用空间足够,但不再连续,因此产生内存碎片。
一个办法是不再对内存空间进行连续分配。这样只要有物理内存就可以为进程进行分配。而实际上,不进行连续分配只是相对的,因为完全这样做的代价太大。现实中,往往定出一个最小的内存单元,内存分配是这最小单元的组合,单元内的地址是连续的,但各个单元不一定连续。这样的内存小单元有页和段。
当然,分段和分页也会产生碎片,但理论上每个碎片的大小不超过内存单元的大小。
另外,操作系统分配给进程的逻辑地址就可以是连续的,通过MMU的映射,就可以充分利用不连续的物理内存。
4. MMU原理
? 分页
? 页表查找(映射)
以S3C2440的MMU为例,(ARM920T内核,三星产)
MVA——modified virtual address, 变换后的虚拟地址。一般是在虚拟地址上再标记上进程号。
4.1 分页机制
虚拟地址最终需要转换为物理地址才能读写实际的数据,通过将虚拟地址空
间和物理空间划分为同样大小的空间(段或页),然后两个空间建立映射关系。
在虚拟地址空间上划分的空间单元称为页(page,较大的则称为段section)。在物理地址空间上划分的同样大小的空间单元称为页帧(page frame,或叫页框)。 Linux上地址空间单元大小为4k。
由于虚拟地址空间远大于物理地址,可能多块虚拟地址空间映射到同一块物理地址空间,或者有些虚拟地址空间没有映射到具体的物理地址空间上去(使用到时再映射)。
S3C2440最多会用到两级页表,以段(Section,1M)的方式进行转换时只用到一级页表,以页(Page)的方式进行转换时用到两级页表。
页的大小有3种:大页(64KB),小页(4KB),极小页(1KB)。
i386是什么 内存管理以及内存管理单元简介(MMU)
MVA,32位。[www.61k.com]
TTB base代表一级页表的地址将它写入协处理器CP15的寄存器C2(称为页表基址寄存器)即可。一级页表的地址使用[31:14]存储页表基址,[13:0]为0。
i386是什么 内存管理以及内存管理单元简介(MMU)
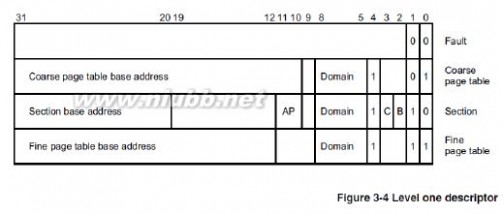
一级页表使用4096个描述符来表示4GB空间,每个描述符对应1MB的虚拟地址,存储它对应的1MB物理空间的起始地址,或者存储下一级页表的地址。(www.61k.com) 每个描述符占4个字节,格式如下:
使用MVA[31:20]来索引一级页表(20-31一共12位,2^12=4096,所以是4096个描述符)。
4.2 转换机制
①页表基址寄存器位[31:14]和MVA[31:20]组成一个低两位为0的32位地址,MMU利用这个地址找到段描述符。
②取出段描述符的位[31:20](段基址,section base address),它和MVA[19:0]组成一个32位的物理地址(这就是MVA对应的PA)
4.3 TLB
从MVA到PA的转换需要访问多次内存,大大降低了CPU的性能,有没有办法改进呢?
i386是什么 内存管理以及内存管理单元简介(MMU)
程序执行过程中,用到的指令和数据的地址往往集中在一个很小的范围内,其中的地址、数据经常使用,这是程序访问的局部性。[www.61k.com]
由此,通过使用一个高速、容量相对较小的存储器来存储近期用到的页表条目(段、大页、小页、极小页描述符),避免每次地址转换都到主存中查找,这样就大幅提高性能。这个存储器用来帮助快速地进行地址转换,成为转译查找缓存(Translation Lookaside Buffers, TLB)
当CPU发出一个虚拟地址时,MMU首先访问TLB。如果TLB中含有能转换这个虚拟地址的描述符,则直接利用此描述符进行地址转换和权限检查,否则MMU访问页表找到描述符后再进行地址转换和权限检查,并将这个描述符填入TLB中,下次再使用这个虚拟地址时就直接使用TLB用的描述符。
若转换成功,则称为"命中"。Linux系统中,目前的"命中"率高达 90%以上,使分页机制带来的性能损失降低到了可接收的程度。若在TLB中进行查表转换失败,则退缩为一般的地址变换,概率小于10%。
5. Linux内存管理
补充概念
逻辑地址
线性地址
物理地址
5.1 逻辑地址转线性地址
i386是什么 内存管理以及内存管理单元简介(MMU)
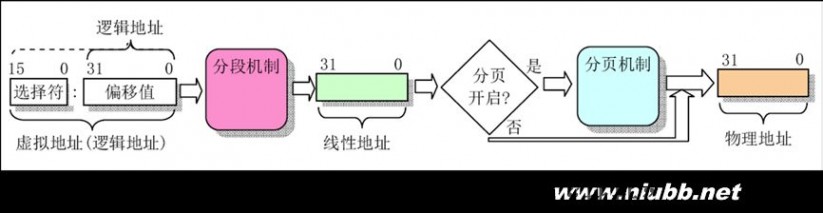
在x86保护模式下,段的信息(段基线性地址、长度、权限等)即段描述符占8个字节,段信息无法直接存放在段寄存器中(段寄存器只有2字节)。(www.61k.com)Intel的设计是段描述符集中存放在GDT或LDT中,而段寄存器存放的是段描述符在GDT或LDT内的索引值(index)。
Linux中逻辑地址等于线性地址。为什么这么说呢?因为Linux所有的段(用户代码段、用户数据段、内核代码段、内核数据段)的线性地址都是
从 0x00000000 开始,长度4G,这样 线性地址=逻辑地址+ 0x00000000,也就是说逻辑地址等于线性地址了。
Linux主要以分页的方式实现内存管理。
5.2 线性地址转物理地址
在保护模式下,控制寄存器CR0的最高位PG位控制着分页管理机制是否生效,如果PG=1,分页机制生效,需通过页表查找才能把线性地址转换物理地址。如果PG=0,则分页机制无效,线性地址就直接做为物理地址。
i386是什么 内存管理以及内存管理单元简介(MMU)
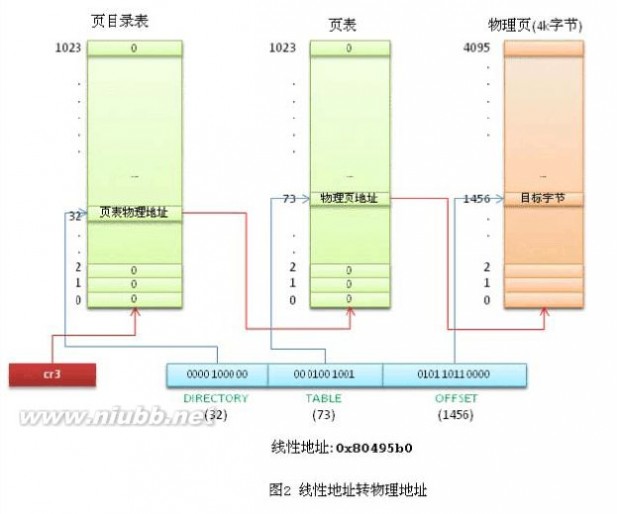
分页的基本原理是把内存划分成大小固定的若干单元,每个单元称为一页(page),每页包含4k字节的地址空间。[www.61k.com)这样每一页的起始地址都是4k字节对齐的。为了能转换成物理地址,我们需要给CPU提供当前任务的线性地址转物理地址的查找表,即页表(page table)。注意,为了实现每个任务的平坦的虚拟内存,每个任务都有自己的页目录表和页表。
为了节约页表占用的内存空间,x86将线性地址通过页目录表和页表两级查找转换成物理地址。
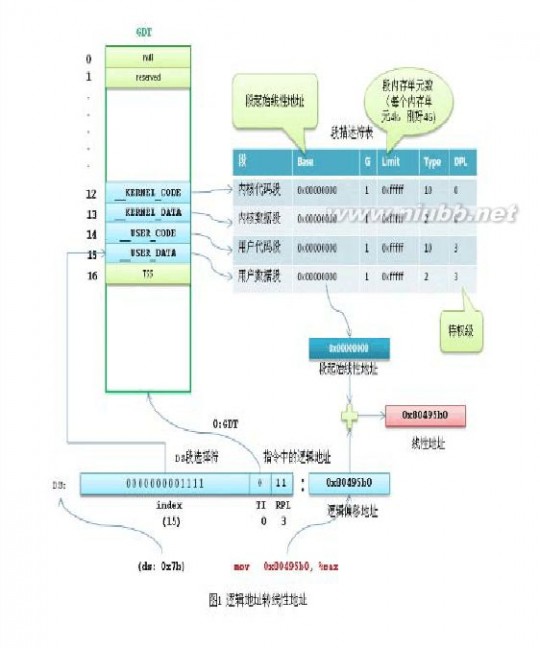
32位的线性地址被分成3个部分:
最高10位 Directory 页目录表偏移量,中间10位 Table是页表偏移量,最低12位Offset是物理页内的字节偏移量。
页目录表的大小为4k(刚好是一个页的大小),包含1024项,每个项4字节(32位),项目里存储的内容就是页表的物理地址。如果页目录表中的页表尚未分配,则物理地址填0。
页表的大小也是4k,同样包含1024项,每个项4字节,内容为最终物理页的物理内存起始地址。
每个活动的任务,必须要先分配给它一个页目录表,并把页目录表的物理地址存入cr3寄存器。页表可以提前分配好,也可以在用到的时候再分配。
还是以 mov 0x80495b0, %eax 中的地址为例分析一下线性地址转物理地址的过程。
i386是什么 内存管理以及内存管理单元简介(MMU)
假设要转换的线性地址就是0x80495b0。(www.61k.com]转换的过程是由CPU自动完成的(应该是通过MMU),Linux所要做的就是准备好转换所需的页目录表和页表(假设已经准备好,给页目录表和页表分配物理内存的过程很复杂,后面再分析)。 内核先将当前任务的页目录表的物理地址填入cr3寄存器。
线性地址 0x80495b0 转换成二进制后是 0000 1000 0000 0100 1001 0101 1011 0000,最高10位0000 1000 00的十进制是32,CPU查看页目录表第32项,里面存放的是页表的物理地址。线性地址中间10位00 0100 1001 的十进制是73,页表的第73项存储的是最终物理页的物理起始地址。物理页基地址加上线性地址中最低12位的偏移量,CPU就找到了线性地址最终对应的物理内存单元。 我们知道Linux中用户进程线性地址能寻址的范围是0~3G,那么是不是需要提前先把这3G虚拟内存的页表都建立好呢?一般情况下,物理内存是远远小于3G的,加上同时有很多进程都在运行,根本无法给每个进程提前建立3G的线性地址页表。Linux利用CPU的一个机制解决了这个问题。进程创建后我们可以给页目录表的表项值都填0,CPU在查找页表时,如果表项的内容为0,则会引发一个缺页异常,进程暂停执行,Linux内核这时候可以通过一系列复杂的算法给分配一个物理页,并把物理页的地址填入表项中,进程再恢复执行。当然进程在这个过程中是被蒙蔽的,它自己的感觉还是正常访问到了物理内存。
5.3 物理内存管理(页管理)
Linux内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数个4k(在i386体系结构中)大小的页,从而分配和回收内存的基本单位便是内存页了。利用分页管理有助于灵活分配内存地址,因为分配时不必要求必须有大块的连续内存,系统可以东一页、西一页的凑出所需要的内存供进程使用。虽然如此,但是实际上系统使用内存时还是倾向于分配连续的内存块,因为分配连续内存时,页表不需要更改,因此能降低TLB的刷新率(频繁刷新会在很大程度上降低访问速度)。
内核分配物理页面时为了尽量减少不连续情况,采用了“伙伴”关系(Buddy 算法)来管理空闲页面。
设置了一个mem_map[]数组管理内存页面page,其在系统初始化时由
free_area_init()函数创建。数组元素是一个个page结构体,每个page结构体对应一个物理页面

i386是什么 内存管理以及内存管理单元简介(MMU)
typedef struct page {
struct page *next;
struct page *prev;
struct inode *inode;
unsigned long offset;
struct page *next_hash;
atomic_t count;
unsigned flags;
unsigned dirty,age;
struct wait_queue *wait;
struct buffer_head * buffers;
unsigned long swap_unlock_entry;
unsigned long map_nr;
} mem_map_t;
把内存中所有页面按照2n划分,其中n=0~5,每个内存空间按1个页面、2个页面、4个页面、8个页面、16个页面、32个页面进行六次划分。(www.61k.com]划分后形成了大小不等的存储块,称为页面块,简称页块。包含1个页面的页块称为1页块,包含2个页面的称为2页块,依此类推。每种页块按前后顺序两两结合成一对Buddy“伙伴”。系统按照Buddy关系把具有相同大小的空闲页面块组成页块组,即1页块组、2页块组……32页块组。每个页块组用一个双向循环链表进行管理,共有6个链表,分别为1、2、4、8、16、32页块链表,分别挂到free_area[] 数组上。
位图数组
标记内存页面使用情况,第0组每一位表示单个页面使用情况,1表示使用,0表示空闲,第2组每一位表示比邻的两个页面的使用情况,依次类推。
? 当一对Buddy的两个页面块中有一个是空闲的,而另一个全部或部分被
占用时,该位置1。
? 两个页面块都是空闲,或都被全部或部分占用时, 对应位置0。
i386是什么 内存管理以及内存管理单元简介(MMU)
内存分配和释放过程
内存分配时,系统按照Buddy算法,根据请求的页面数在free_area[]对应的空闲页块组中搜索。[www.61k.com)
若请求页面数不是2的整数次幂,则按照稍大于请求数的2的整数次幂的值搜索相应的页面块组。
当相应页块组中没有可使用的空闲页面块时就查询更大一些的页块组,在找到可用的空闲页面块后,分配所需页面。
当某一空闲页面块被分配后,若仍有剩余的空闲页面,则根据剩余页面的大小把它们加入到相应页块组中。
内存页面释放时,系统将其做为空闲页面看待。
检查是否存在与这些页面相邻的其它空闲页块,若存在,则合为一个连续的空闲区按Buddy算法重新分组。
i386是什么 内存管理以及内存管理单元简介(MMU)
buddy算法有效利用了物理内存的页面空间,并且为进程提供连续的地址空间。[www.61k.com)
slab算法简介
采用buddy算法解决了外碎片问题,这种方法适合大块内存请求,不适合小内存区请求。如:几十个或者几百个字节。Linux2.0采用传统内存分区算法,按几何分布提供内存区大小,内存区以2的幂次方为单位。虽然减少了内碎片,但没有显著提高系统效率。
Linux2.4采用了slab分配器算法,该算法比传统的分配器算法有更好性能和内存利用率,最早在solaris2.4上使用。
Linux 所使用的 slab 分配器的基础是 Jeff Bonwick 为 SunOS 操作系统首次引入的一种算法。Jeff 的分配器是围绕对象缓存进行的。在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。Jeff 发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。例如,如果内存被分配给了一个互斥锁,那么只需在为互斥锁首次分配内存时执行一次互斥锁初始化函数(mutex_init)即可。后续的内存分配不需要执行这个初始化函数,因为从上次释放和调用析构之后,它已经处于所需的状态中了。
Linux slab 分配器使用了这种思想和其他一些思想来构建一个在空间和时间上都具有高效性的内存分配器。
Slab分配器思想
i386是什么 内存管理以及内存管理单元简介(MMU)
1)小对象的申请和释放通过slab分配器来管理。[www.61k.com]
2)slab分配器有一组高速缓存,每个高速缓存保存同一种对象类型,如i节点缓存、PCB缓存等。
3)内核从它们各自的缓存种分配和释放对象。
4)每种对象的缓存区由一连串slab构成,每个slab由一个或者多个连续的物理页面组成。这些页面种包含了已分配的缓存对象,也包含了空闲对象。
图 1 给出了 slab 结构的高层组织结构。在最高层是 cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个
kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
图 1. slab 分配器的主要结构
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在 3 种 slab:
slabs_full
完全分配的 slab
slabs_partial
部分分配的 slab
slabs_empty
空 slab,或者没有对象被分配
注意 slabs_empty 列表中的 slab 是进行回收(reaping)的主要备选对象。正是通过此过程,slab 所使用的内存被返回给操作系统供其他用户使用。
slab 列表中的每个 slab 都是一个连续的内存块(一个或多个连续页),它们被划分成一个个对象。这些对象是从特定缓存中进行分配和释放的基本元素。注意 slab 是 slab 分配器进行操作的最小分配单位,因此如果需要对 slab 进行扩展,这也就是所扩展的最小值。通常来说,每个 slab 被分配为多个对象。
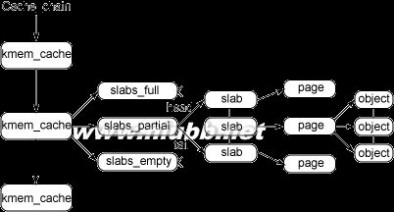
i386是什么 内存管理以及内存管理单元简介(MMU)
由于对象是从 slab 中进行分配和释放的,因此单个 slab 可以在 slab 列表之间进行移动。[www.61k.com)例如,当一个 slab 中的所有对象都被使用完时,就从 slabs_partial 列表中移动到 slabs_full 列表中。当一个 slab 完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到 slabs_partial 列表中。当所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_empty 列表中。
slab 背后的动机
与传统的内存管理模式相比, slab 缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。slab 分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复进行初始化。最后,slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
内存管理摘要
内存管理的目标是提供一种方法,为实现各种目的而在各个用户之间实现内存共享。内存管理方法应该实现以下两个功能:
最小化管理内存所需的时间
? 最大化用于一般应用的可用内存(最小化管理开销) ?
一种使用少量内存进行管理的算法,但是要花费更多时间来管理可用内存。也可以开发一个算法来有效地管理内存,但却要使用更多的内存。最终,特定应用程序的需求将促使对这种权衡作出选择。
每个内存管理器都使用了一种基于堆的分配策略。在这种方法中,大块内存(称为 堆)用来为用户定义的目的提供内存。当用户需要一块内存时,就请求给自己分配一定大小的内存。堆管理器会查看可用内存的情况(使用特定算法)并返回一块内存。搜索过程中使用的一些算法有 first-fit(在堆中搜索到的第一个满足请求的内存块 )和 best-fit(使用堆中满足请求的最合适的内存块)。当用户使用完内存后,就将内存返回给堆。
这种基于堆的分配策略的根本问题是碎片(fragmentation)。当内存块被分配后,它们会以不同的顺序在不同的时间返回。这样会在堆中留下一些洞,需要花一些时间才能有效地管理空闲内存。这种算法通常具有较高的内存使用效率(分配需要的内存),但是却需要花费更多时间来对堆进行管理。
另外一种方法称为 buddy memory allocation,是一种更快的内存分配技术,它将内存划分为 2 的幂次方个分区,并使用 best-fit 方法来分配内存请求。
i386是什么 内存管理以及内存管理单元简介(MMU)
当用户释放内存时,就会检查 buddy 块,查看其相邻的内存块是否也已经被释放。(www.61k.com]如果是的话,将合并内存块以最小化内存碎片。这个算法的时间效率更高,但是由于使用 best-fit 方法的缘故,会产生内存浪费。
四 : 内容存储公司Pocket获得B轮500万美元融资
7月19日消息,据国外媒体报道,互联网内容存储公司 Pocket在B轮融资中获得500万美元风险投资,领投者为Foundation Capital,Baseline Ventures和谷歌旗下的Google Ventures均参与了融资。三家风投此前曾在A轮为Pocket融资250万美元。
报道称,Pocket打算利用新投资将“save for later”体验带到更多的平台和设备,同时扩展团队,为开发商和内容合作伙伴改善服务。
Pocket允许用户在网络上保存内容,并在任何时间、任何设备上读取,从另一个意义上讲,实现了时间转移、空间转移。该公司于2007年创立,截止2011年,一直都是创办者独立研发产品。
2012年4月份,该公司以名称Pocket重新发布服务,反映了它对媒体服务的支持以及以移动设备为目标的定位。除了以网页浏览为基础的版本,Pocket同样开发了适用于安卓系统和iOS系统的应用。而且它通过API融合进350家第三方应用程序和服务,其中包括Flipboard、Twitter 和Zite。
Pocket声称用户每天保存的内容数量接近100万,包括杂志文章,YouTube视频、食物配方等等。
五 : 内存管理单元MMU(memory management unit)

内存管理单元MMU(memory management unit)的主要功能是虚拟地址(virtual memory addresses)到物理地址(physical addresses)的转换。除此之外,它还可以实现内存保护(memory protection)、缓存控制(cache control)、总线仲裁(bus arbitration)以及存储体切换(bank switching)。
(www.61k.com)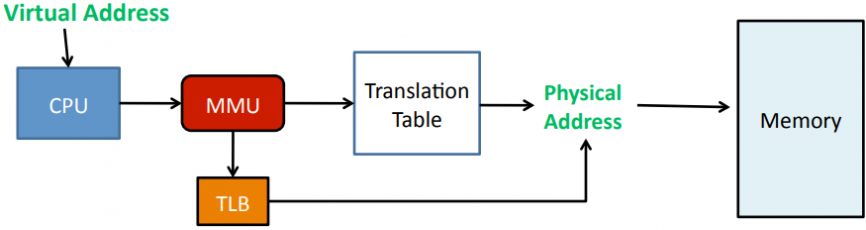
CPU将要请求的虚拟地址传给MMU,然后MMU先在高速缓存TLB(Translation Lookaside Buffer)查找转换关系,如果找到了相应的物理地址则直接访问;如果找不到则在地址转换表(Translation Table)里查找计算。
现代的内存管理单元是以页的方式来分区虚拟地址空间(the range of addresses used by the processor)的。页的大小是2的n次方,通常为几KB。所以虚拟地址就被分为了两个部分:virtual page number和offset。
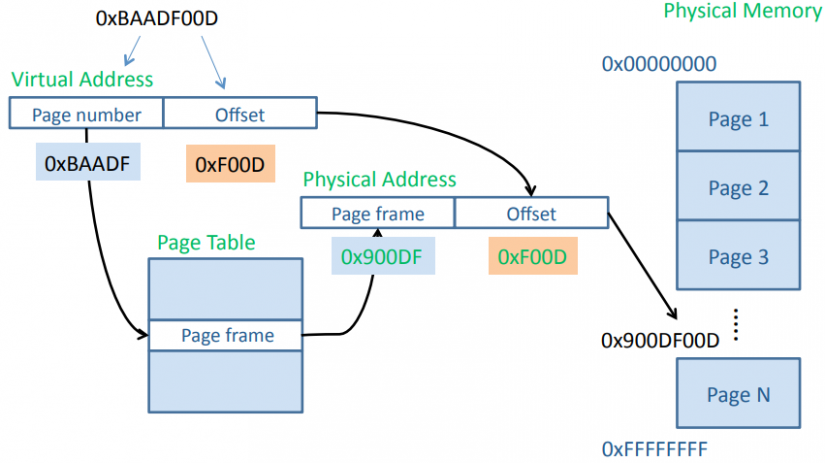
上面从虚拟页号在页表里找到的存放物理页表号的条目就是页表项(PTE)。PTE一般占1个字长,里面不仅包含了physical page number,还包含了重写标志位(dirty bit)、访问控制位(accessed bit)、允许读写的进程类型(user/supervisor mode《犇_嫑》)、是否可以被cached以及映射类型(PTE最后两位)。
映射方式
映射方式有两种,段映射和页映射。段映射只用到一级页表,页映射用到一级页表和二级页表。映射粒度
段映射的映射粒度有两种,1M section和16M supersection;页映射的映射粒度有4K small page、64K large page和过时的1K tiny page。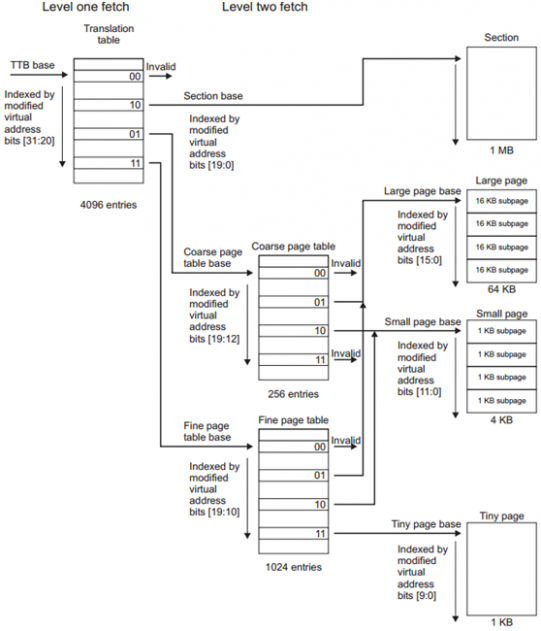
1. Memory Management Unit
2. Translating Addresses
3. 映射方式
本文永久更新链接地址:
 本文标题:内存存储单元-内容存储公司Pocket获B轮500万美元融资
本文标题:内存存储单元-内容存储公司Pocket获B轮500万美元融资 61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1