一 : 怎样分析百度蜘蛛来过自己的网站
最近,菜菜经常没事的时候就喜欢到各大论坛,去瞧瞧,去看看。为什么?原因很简单,我去其他的论坛上回答问题做外链呀,好让百度蜘蛛通过外链爬到我的网站上抓取我的网页呀,但是这几天,菜菜发现一个问题,在网上兼职赚钱创业的朋友都应该有一个网站吧,就是很多站长,我估计哈 ,可能都是新手,基本上问的问题都是关于百度什么时候才会收录自己的网页,说道这点,大家可以去我这篇文章看下,关于新手前期做网站的心态的,对新手是有帮助的。再或者百度蜘蛛是否来过我的网站,怎么才知道百度蜘蛛来过我的网站呢?我们只需要查询网站日记,去好好的分析网站日记就可以了。
百度蜘蛛是个摸不着性子的东西,最近听说百度在做大的调整,导致很多网站的排名情况,外链数量变动很大呀,老站长就没什么了饿,可是对于新站长来说。心里就一阵一阵的怕了。也不知道百度这次的调整要什么时候才能稳定呀。
其实百度蜘蛛是有规律可循的,它一般都是一周一小变,一月一大变那种,对于新手来说,只要把心态调整好,是没有问题的【关于心态的文章请参考;“新人学习SEO的心态变化】,下面就具体讲讲百度蜘蛛的小细节了,知道了这些就知道了 百度蜘蛛到你网站上具体来做什么。
百度蜘蛛大概分为三类:
我们最常见的就是:220.181.108.*这一段了!这段IP注意负责抓取网站的更新,和增加网站的权重的作用。
其次就是:123.125.71*。这段IP注意负责一些权重比较低的网站文章抓取情况,和文章原创度的情况,一般会在48小时内抓取你的网页,但是也会在48小时内删除你的资料。这也是许多新手站长奇怪的是为什么我的网站收录不到很久就没有排名的原因。一定要请大家注意,这个IP出现在网站日记的话一定要小心!
最后一个,也是大家不愿意看到的一个IP:123.125.68*。这段IP我们一般叫做黑武士,他如果来到你的网站的话,你的网站基本就会被降权或者被K掉,情况好的只会抓取你一次,如果网站大量出现这样的百度蜘蛛的话,你的网站就准备被K掉吧,也说明了百度发现你做了很多不好的事情。这个IP事许多老站长都不愿意看到的IP。
百度蜘蛛的三大类的基本工作情况:
前面我们说道最常见的就是220.181.108.*。内容已经解释过了就不在解释了,主要的蜘蛛【220.181.108.86】它抓取的网页权重是最大的,如果说这个蜘蛛在你的网页上返回正常的话,说明你的网站问题不大,如何抓取的时候返回数据库有其他的数值的话,说明网站问题就很大了,一定要注意。
快照蜘蛛:顾名思义就是说专门给你网页拍照的蜘蛛。IP结尾的75的就是快照蜘蛛,它来到你网站越多越好,为什么?不解释了。
IP结尾的89的蜘蛛,我们称为高权重的蜘蛛,但是它的权重没有IP86结尾的高,但是权重也是非常不错的。
接下来就是:94,97,80,83,z这些蜘蛛都是高权重的蜘蛛,它们的权重是依此递减的。剩下来的就是普通的蜘蛛了,它们会抓取新的网站的内容,返回数据库的值有200的话,一般情况下,会在24到40小时至内会被放出的。如果现实304的话,就说明此网站有待考察。
123.125.71*
这段IP有两个功能!
一,检查更新情况,一般这种情况的蜘蛛权重都比较低,它们一般只会检查网站的首页的更新情况。
二,文章的原创度的多少,此原理来自半发现象,怎么说呢,一般情况下被一个低权重的百度蜘蛛抓取过的网页的,它会再在抓取网页,如果发现相同的地方,会在48小时内删除的,并且还会降权的。
很多朋友都真正地很少的知道百度蜘蛛的工作原理是怎么回事的,通过菜菜的这篇文章,相信大家会对百度蜘蛛有个全新的认识,并不是说百度蜘蛛到你的网站上就是好事,这一定要注意!!!!
二 : 关于百度蜘蛛ip分类
作为1个网站SEO优化新网站的站长,要时刻留意网站的百度蛛蛛的爬行,留意它的到访规律。下面分析一下百度蛛蛛IP分类及返回值三 : 百度蜘蛛是抓取网站和提高抓取频率的技巧分享
做SEO的小伙伴对百度搜索引擎和蜘蛛是情有独钟啊,因为目前百度是国内PC端和移动端搜索引擎的老大,seo的小伙伴当然是希望百度蜘蛛能够更多的抓取网站,只有抓取的页面多了,才有可能获得更好的收录、排名和流量。
下面就先和各位分享一下百度蜘蛛是如何从最原始的策略制定到抓取的。
一、百度蜘蛛抓取规则
1、对网站抓取的友好性
百度蜘蛛在抓取互联网上的信息时为了更多、更准确的获取信息,会制定一个规则最大限度的利用带宽和一切资源获取信息,同时也会仅最大限度降低对所抓取网站的压力。
2、识别url重定向
互联网信息数据量很庞大,涉及众多的链接,但是在这个过程中可能会因为各种原因页面链接进行重定向,在这个过程中就要求百度蜘蛛对url重定向进行识别。
3、百度蜘蛛抓取优先级合理使用
由于互联网信息量十分庞大,在这种情况下是无法使用一种策略规定哪些内容是要优先抓取的,这时候就要建立多种优先抓取策略,目前的策略主要有:深度优先、宽度优先、PR优先、反链优先,在我接触这么长时间里,PR优先是经常遇到的。
4、无法抓取数据的获取
在互联网中可能会出现各种问题导致百度蜘蛛无法抓取信息,在这种情况下百度开通了手动提交数据。
5、对作弊信息的抓取
在抓取页面的时候经常会遇到低质量页面、买卖链接等问题,百度出台了绿萝、石榴等算法进行过滤,据说内部还有一些其他方法进行判断,这些方法没有对外透露。
上面介绍的是百度设计的一些抓取策略,内部有更多的策略咱们是不得而知的。
二、百度蜘蛛抓取过程中涉及的协议
1、http协议:超文本传输协议
2、https协议:目前百度已经全网实现https,这种协议更加安全。
3、robots协议:这个文件是百度蜘蛛访问的第一个文件,它会告诉百度蜘蛛,哪个页面可以抓取,哪个不可以抓取。
三、如何提高百度蜘蛛抓取频次
百度蜘蛛会根据一定的规则对网站进行抓取,但是也没法做到一视同仁,以下内容会对百度蜘蛛抓取频次起重要影响。
1、网站权重:权重越高的网站百度蜘蛛会更频繁和深度抓取
2、网站更新频率:更新的频率越高,百度蜘蛛来的就会越多
3、网站内容质量:网站内容原创多、质量高、能解决用户问题的,百度会提高抓取频次。
4、导入链接:链接是页面的入口,高质量的链接可以更好的引导百度蜘蛛进入和爬取。
5、页面深度:页面在首页是否有入口,在首页有入口能更好的被抓取和收录。
6、抓取频次决定着网站有多少页面会被建库收录,这么重要的内容站长该去哪里进行了解和修改,可以到百度站长平台抓取频次功能进行了解,如下图:
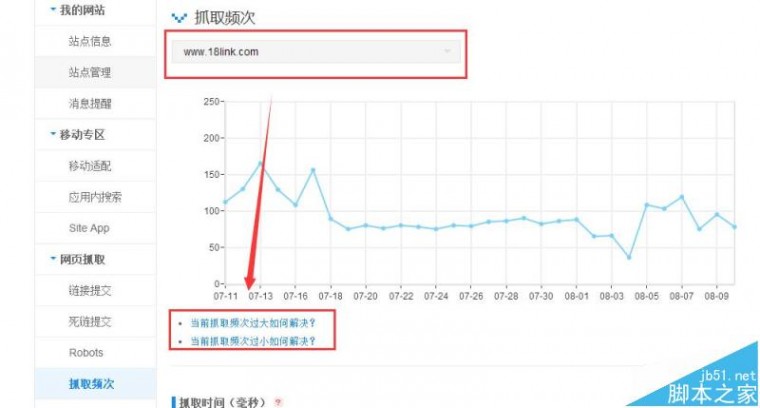
四、什么情况下会造成百度蜘蛛抓取失败等异常情况
有一些网站的网页内容优质、用户访问正常,但是百度蜘蛛无法抓取,不但会损失流量和用户还会被百度认为网站不友好,造成网站降权、评分下降、导入网站流量减少等问题。
小编在这里简单介绍一下造成百度蜘蛛抓取一场的原因:
1、服务器连接异常:出现异常有两种情况,一是网站不稳定,造成百度蜘蛛无法抓取,二是百度蜘蛛一直无法连接到服务器,这时候您就要仔细检查了。
2、网络运营商异常:目前国内网络运营商分电信和联通,如果百度蜘蛛通过其中一种无法访问您的网站,还是赶快联系网络运营商解决问题吧。
3、无法解析IP造成dns异常:当百度蜘蛛无法解析您网站IP时就会出现dns异常,可以使用WHOIS查询自己网站IP是否能被解析,如果不能需要联系域名注册商解决。
4、IP封禁:IP封禁就是限制该IP,只有在特定情况下才会进行此操作,所以如果希望网站百度蜘蛛正常访问您的网站最好不要进行此操作。
5、死链:表示页面无效,无法提供有效的信息,这个时候可以通过百度站长平台提交死链。
通过以上信息可以大概了解百度蜘蛛爬去原理,收录是网站流量的保证,而百度蜘蛛抓取则是收录的保证,所以网站只有符合百度蜘蛛的爬去规则才能获得更好的排名、流量。
四 : 简单的分析一下百度蜘蛛的日常工作习性
搜索引擎用来爬行和访问页面的程序被称为蜘蛛工,也称为机器人(bot)。搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序把收到的代 码存入原始页面数据库。搜索引擎为了提高爬行和抓取速度,都使用多个蜘蛛并发分布爬行。61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1