ICT技术发展到今天,面临这样一种矛盾:一方面,人工智能、5G、HPC、边缘计算等新业务逐渐落地实用,对算力性能提出极高要求;另一方面,摩尔定律逐渐失效,通用计算越来越不能满足这些业务的算力需求。
在这样的背景下,算力的发展重心正在从传统的冯·诺依曼架构为代表的通用计算向以域专有架构(DomainSpecific Architecture)为代表的异构计算转移。
域专有架构主要有以下几个特点:一是它由许多简单单元组成。不同于以往通用计算的CPU单核单带或者是多核的组成,域专有架构通常有多个DIE,每个DIE专用于执行一种功能。第二个特性就是更少的数据移动。为了达到这一特性,从硬件设计层面,就会优化计算单元跟存储单元之间的物理位置以及访问协议设置。第三,能效比更高的专用硬件。针对特定的业务场景采用专用硬件,很好地提供能效比。第四,新的指令集或像MindSpore这类的新编程范式。
在域专有架构下,越来越多的GPU、FPGA、ASIC、SoC等异构计算硬件被使用,但在云计算普遍普及的产业背景下,如何才能更好地管理这些异构计算设备,使之更好地释放算力呢?
异构计算相关的开源项目,正在帮助我们解决这个问题。
在华为开发者大会2020(Cloud)期间,OpenStack Cyborg项目发起人、华为计算产品线开源生态部主任工程师黄之鹏,通过对最新开源项目的解读,带来了异构计算的最新发展趋势。
OpenStack的Cyborg异构硬件加速框架
如果市场上每出现一种硬件,就去增加一种专用支持,就会形成“烟囱式”管理,这种方法虽然也能胜任商业交付,但是因为过于来碎片化,会为日后的发展埋下隐患。
为此,开源管理平台OpenStack早在2017年异构计算刚刚开始发展时,就提出了Cyborg项目,面向GPU、FPGA、AI处理器等不同异构计算硬件和软件加速资源,提供具有标准API的通用管理框架。
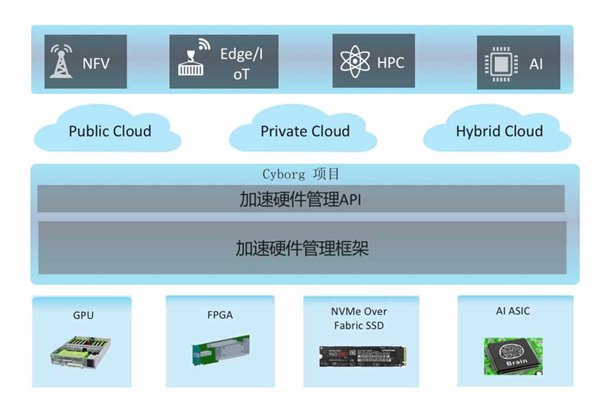
Cyborg的主要功能包括硬件资源的发现、资源上报、资源的管理,Cyborg还能完成FPGA编程等特殊硬件的特殊功能或配置。
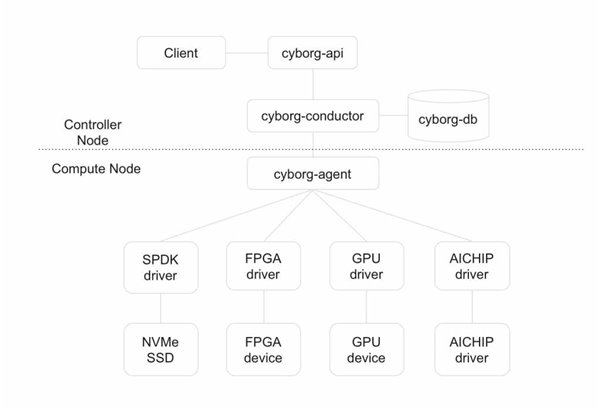
Cyborg已经交付了至少4~5个版本,采用OpenStack组件中常用的架构设计,分为控制层和计算节点层,以分离管理面与数据面,并在管理面设计了统一的API。
Cyborg-api、Cyborg-conductor、Cyborg-agent是Cyborg的3个主要服务,Cyborg-api主要用于提供API接口,Cyborg-conductor主要用来缓冲和路由api与agent数据库的操作,Cyborg-agent主要用来对接各种异构计算硬件,Cyborg-client主要调用cyborg-api,最终对用户提供命令行。
Cyborg项目自2017年9月成为OpenStack社区官方项目后,生态进展迅速,已成长为加速设备管理的事实标准,服务于NFV、HPC、边缘计算、AI/DL等多个场景。
开源是催生开发者生态非常重要的一环,至今Cyborg已经吸引了来自Intel、联想、ARM、Redhat、科大讯飞、中移动、银联等公司或机构的开发者参与。
Cyborg的技术实现
在通用计算主导的云计算时代,通过虚拟化、容器化,实现了物理资源池的资源复用,进而以多租户的方式开放出去,形成公有云服务或私有云服务。
在异构计算时代,为了实现虚拟化和容器化,同样需要异构资源的分层抽象,所以Cyborg项目定义了一套面向异构计算设备的抽象设备模型:
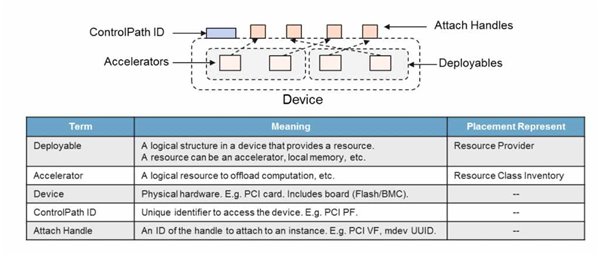
第一层是Device,对应物理意义上的卡,如各类加速卡;
在Device的层级之上,是PF(PhysicalFunction),比如FPGA上会有多个区域(Region),每一个区域可能就是一个PF;
在PF之上,可以抽象出VF(VirtualFunction),很多异构硬件支持在PF的基础上进一步提供VF的能力。
下面以两个例子来说明Cyborg的技术实现。
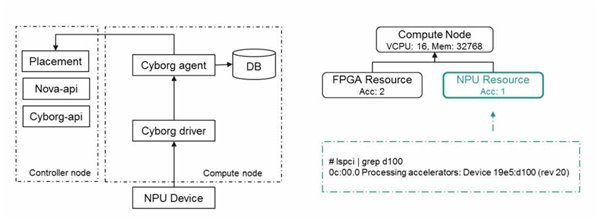
设备发现:在一个有2个FPGA资源、1个的NPU资源的计算节点上,通过PCIE上电的设备,信息被CyborgDriver上报到Compute计算节点的Agent上面,Agent主要做两个动作,一是写入到DB,另外一个是写入到Placement,Placement是OpenStack近几个版本才出现的新组件,起到计数器的作用,会统计所有的计算存储网络以及异构资源的总数量,以便在Schedule调度的时候实现全局视图。
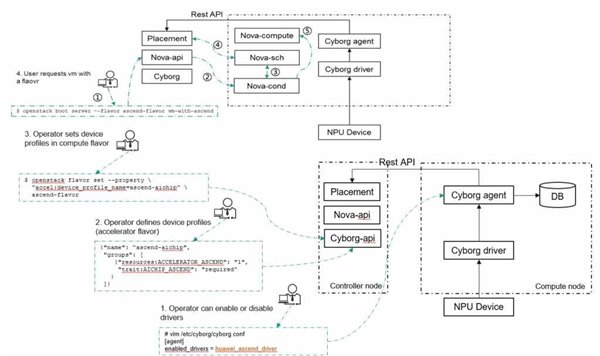
Nova-Cyborg交互:Nova是OpenStack里非常重要的管理组件,这里来看一下Cyborg怎样和Nova实现交互。
第1步,管理员或运营者(Operator)把要使用的硬件的驱动配置进Cyborg的Config中。
第2步,定义一个DeviceProfiles,和OpenStack的通用资源定义一样,通过Flavor描述资源的规格。
第3步,管理员把设定的DeviceProfiles关联到Flavor上面。
管理员通过CyborgApi完成了这些工作之后,用户就可以去申请这个实例了。
用户使用OpenStack的命令行或者按钮申请一个Flavor,Flavor会加上Device Profiles的描述,之后启动调度器去Placement查询,如果有符合用户请求的资源,云平台就可以返回用户所需要的实例了。
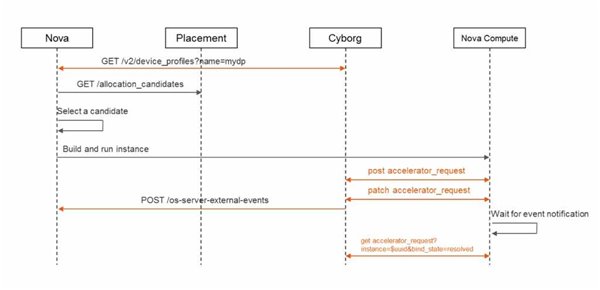
通过组件间的调用关系图示,可以看到Nova和Cyborg之间的DeviceProfiles的设置、Nova和Placement关于Allocation之间的交互,以及当创建实例时的Post accelerator request等,整体的工作流比较清晰,而且尽可能复用了OpenStack的Nova的工作机制,实现对异构资源的管理。
Kubernetes以及其他社区的异构计算开源项目
Kubernetes(K8s)社区是谷歌开源出来的容器管理平台,K8s同样存在异构计算的支持的问题。因为K8s出现的比较晚,对GPU这类异构设备的支持排在很高的优先级,很快就实现了DevicePlug Interface(DPI)的机制。
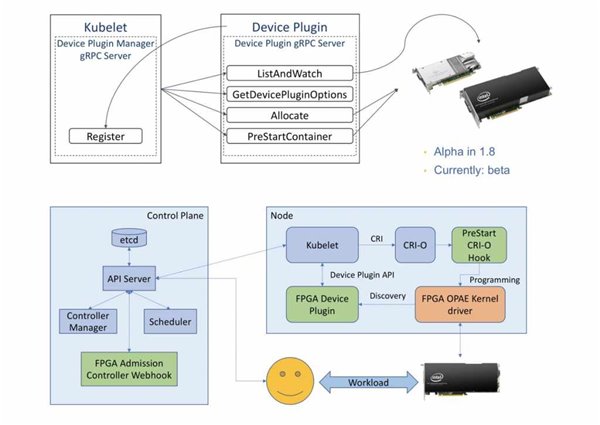
在K8s社区,通过英伟达等公司开发者的努力,已经有一套比较稳定的异构计算管理方法,可以实现K8s集群管理GPU等硬件处理AI任务,或者实现有限的HPC任务。
但DPI本质上还是一个“烟囱式”的解决方案,每种设备都需要一个适配的operator+一个适配的DPI插件,比如做FPGA的方案,还需要做很大的改动才能实现端到端的打通。而NVDIA也为GPU开发了专门的operator。
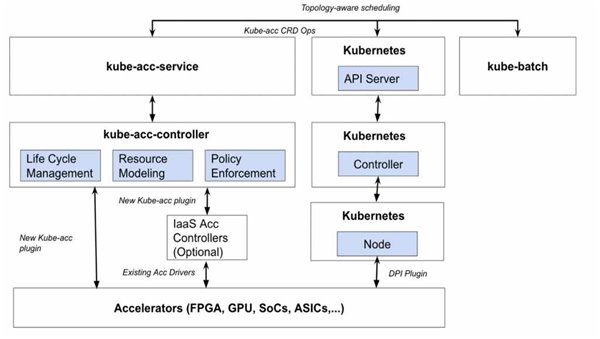
为此,K8s社区也已经提出了一个类似于Cyborg的异构计算项目Kube-acc,希望在K8s上借助优秀的CRD机制,扩展标准的API接口,实现面向不同异构计算硬件的通用管理。
此外,关于异构计算的开源项目社区还有:TornadoVM项目、RISC-V社区、OCP社区(OpenSystem Firmware)、OCP社区(Open Acceleration Infra)等。
其中TornadoVM项目致力于实现Java在异构计算硬件的运行。和华为开源全场景AI计算框架MindSpore一样,都是基于源码的编译优化(Sourceto Source),需要逐层迭代、逐层打开、逐层替换的编译过程。
致力于整合的开放异构计算框架
现在的异构计算、开源生态面临一个巨大的困难,就是应用层面、管理层面和物理设备层面的开发者未能实现互相交谈,整个计算的生态面还没有建立起来,造成很多产业割裂的“烟囱”问题。

为此,正在推动一个新的开源项目:开放异构计算框架(OpenHeterogeneous Computing Framework),希望把上游社区的异构计算的项目,根据场景做端到端的整合。
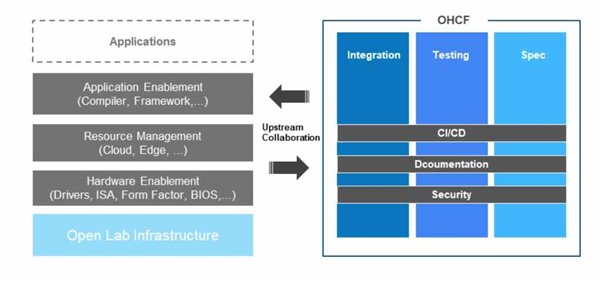
目前已经开展了对已有上游异构计算相关开源项目的集成、测试以及标准文档的撰写工作。
展望未来,5G、AI、云计算、大数据、IoT等技术推动的万物互联时代即将到来。IDC预测数据显示,到2023年全球各种类物联网终端数量将达352亿个,海量连接产生的数据量达175ZB。
随着数字化进程的推进,算力需求将越来越大,数据中心将逐步演变为计算中心,算力将成为新的生产力。在多种数据类型和场景驱动下,异构计算将获得快速发展,异构计算的最新发展趋势值得每一个有志未来的开发者关注。
版权声明:本文内容由网友上传(或整理自网络),原作者已无法考证,版权归原作者所有。61k阅读网免费发布仅供学习参考,其观点不代表本站立场。
本文标题:异构计算,如何让开源有更开放的生态?61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1