一 : VIM查看中文编码文件显示为乱码的解决办法
如果你需要在Linux中操作windows下的文 件,那么你可能会经常遇到文件编码转换的问题。[www.61k.com)Windows中默认的文件格式是GBK(gb2312),而Linux一般都是UTF-8。下面介绍一 下,在Linux中如何查看文件的编码及如何进行对文件进行编码转换。
查看文件编码
在Linux中查看文件编码可以通 过以下几种方式:
1.在Vim中可以直接查看文件编码
:set fileencoding
即可显示文件编码格式。
如果你 只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,那么你可以在
~/.vimrc 文件中添加以下内容:
let &termencoding=&encoding
set fileencodings=utf-8,ucs-bom,gbk,cp936
这样,就可以让vim自动识别文 件编码(可以自动识别UTF-8或者GBK编码的文件),其实就是依照fileencodings提供的编码列表尝试,如果没有找到合适的编码,就用 latin-1(ASCII)编码打开。
文件编码转换
1.在Vim中直接进行转换文件编码,比如将一个文件转 换成utf-8格式
:set fileencoding=utf-8
2. iconv 转换,iconv的命令格式如下:
iconv -f encoding -t encoding inputfile
比如将一个UTF- 8 编码的文件转换成GBK编码
iconv -f GBK -t UTF-8 file1 -o file2
Linux 对一个3G的文本进行编码转换全过程
本过程中涉及到的Linux的命令有:split, iconv, cat
问题:有一个3G 的文本a.txt,编码格式为gbk,现在需要对其进行转换成为utf-8。 难点:iconv的转换是在内存中进行的,因此3G大小的文本,无法 进行直接转换。
思路:先利用split进行文件切分,然后对每一个字文件进行ivonv转换,最后进行cat合并。
1) ll -h a.txt 查看文件的大小,2.9G
乱码查看器 VIM查看中文编码文件显示为乱码的解决办法
2) wc -l a.txt 查看文件的行数,9千200万行
3) split -l 20000000 a.txt chunk 按照每个文件2千万行进行切割,共分成5个文件
4) 进行转换
iconv -f gbk -t utf-8 chunka > chunka_utf8 -c
iconv -f gbk -t utf-8 chunkb > chunkb_utf8 -c
iconv -f gbk -t utf-8 chunkc > chunkc_utf8 -c
iconv -f gbk -t utf-8 chunkd > chunkd_utf8 -c
iconv -f gbk -t utf-8 chunke > chunke_utf8 -c
5) rm chunka chunkb chunkc chunkd chunke 删除原文件
6) cat chunk* > a.txt_utf8 进行合并
至此,工作完成
二、
批 量文件编码转换
本操作有风险,请注意操作前备份文件。[www.61k.com]
1.将原来所有编码为gb2312的*.java文件转换为编码为utf-8 的*.java.new文件
for i in `find . -name "*.java"`; do iconv -f gb2312 -t utf-8 $i -o $i.new; done
2.将*.java.new文件的.new扩展名去除
find . -name "*.new" | sed 's/(.*).new$/mv "&" "1"/' | sh
三、
linux下有 许多方便的小工具来转换编码,
文本内容转换 iconv
文件名转换 convmv
mp3标签转换 python-mutagen
四、
用法: iconv [选项...] [文件...]
转换给定文件的编码。
输 入/输出格式规范:
-f, --from-co
de=名称 原始文本编码
-t, --to-code=名 称 输出编码
信息:
-l, --list 列举所有已知的字符集
输出 控制:
-c 从输出中忽略无效的字符
-o, --output=FILE 输出文件
-s, --silent 关闭警告
--verbose 打印进度信息
-?, --help 给出该系统求助列表
--usage 给出简要的用法信息
-V, --version 打印程序版本号
乱码查看器 VIM查看中文编码文件显示为乱码的解决办法
五、
find default -type d -exec mkdir -p utf/{} ;
find default -type f -exec iconv -f GBK -t UTF-8 {} -o utf/{} ;
这两行命令将default目录下的文件由GBK编码转换为UTF-8编码,目录结构 不变,转码后的文件保存在utf/default目录下。[www.61k.com]
六、
Linux下文件名编码批量转换convmv
由于FC将字 符编码统一成了UTF8,原来在gb18030下建立的ext3分区中的文件和目录,一挂载到FC上就显示成乱码。google遍整个互联网,说对于目录 名和文件名,有一个叫convmv的软件可以对其进行自动转换。
今日下载了convmv,摸索了一套使用方法如下:
convmv -f code1 -t code2 -r
code1:分区原来使用的字符集编码。支持gb2312、gbk、 big5,不支持gb18030和big5-hkscs。 code2:预转换到的字符集编码。对于FC,这里填写utf8
-r 参数:转换子目录。
dir:要转换的目录,当前目录用./表示。
回车执行,这个时候convmv会显示执行的结果,但不会真正对文件进 行修改。并提示使用--replace参数进行修改。
七、
批量转换文件的编码
for i in `find ./ -name *.htm` ; do echo $i;iconv -f gb18030 -t utf8 $i -o /tmp/iconv.tmp;mv /tmp/iconv.tmp $i; done
find -name “*.htm“
-exec iconv -f gb2312 -t utf8 ‘{}‘ -o /tmp/iconv.tmp ;
-exec mv /tmp/iconv.tmp ‘{}‘ ;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
修改你的.vimrc文件,让其支持 gb2312就行,会自动识别的。
可以参考我的设置
代码:
"设定文件编码类型,彻底解决中文编码问题
let &termencoding=&encoding
set fileencodings=utf-8,gbk,ucs-bom,cp936
乱码查看器 VIM查看中文编码文件显示为乱码的解决办法
--------------------------------------------------------------------------------
oldniu
按照karron的方法解决了终端中vi看中文字问题。[www.61k.com)谢谢
略微查了一下.vimrc中添加内容的含意,这篇文章有相关解释。
http://blog.dawnh.net/comment.php?type=trackback&entry_id=59
内容如下:
vim中编辑不同编码的文件时需要注意的一些地方
此文讲解的是vim编辑多字节编码文档(中文)所要了解的一些基础知识,注意其没有涉及gvim,纯指字符终端下的vim。
[vim编码方面的基础知识]
1,存在3个变量:
encoding----该选项使用于缓冲的文本(你正在编辑的文件),寄存器,Vim 脚本文件等等。你可以把 'encoding' 选项当作是对 Vim 内部运行机制的设定。
fileencoding----该选项是vim写入文件时采用的编码类型。
termencoding----该选项代表输出到客户终端(Term)采用的编码类型。
2,此3个变量的默认值:
encoding----与系统当前locale相同,所以编辑文件的时候要考虑当前locale,否则要设置的东西就比较多了。
fileencoding----vim打开文件时自动辨认其编码,fileencoding就为辨认的值。为空则保存文件时采用encoding的编码,如果没有修改encoding,那值就是系统当前locale了。 termencoding----默认空值,也就是输出到终端不进行编码转换。
由此可见,编辑不同编码文件需要注意的地方不仅仅是这3个变量,还有系统当前locale和、文件本身编码以及自动编码识别、客户运行vim的终端所使用的编码类型3个关键点,这3个关键点影响着3个变量的设定。
如果有人问:为什么我用vim打开中文文档的时候出现乱码?
答案是不确定的,原因上面已经讲了,不搞清楚这3个关键点和这3个变量的设定值,出现乱码是正常的,倒是不出现乱码那反倒是凑巧的。
再来看一下常见情况下这三个关键点的值以及在这种情况下这3个变量的值:
乱码查看器 VIM查看中文编码文件显示为乱码的解决办法
1.locale----目前大部分Linux系统已经将utf-8作为默认 locale了,不过也有可能不是,例如有些系统使用中文locale zh_CN.GB18030。[www.61k.com)在locale为utf-8的情况下,启动vim后encoding将会设置为utf-8,这是兼容性最好的方式,因为内部 处理使用utf-8的话,无论外部存储编码为何都可以进行无缺损转换。locale决定了vim内部处理数据的编码,也就是encoding。
2.文件的编码以及自动编码识别----这方面牵扯到各种编码的规则,就不一一细讲了。但需要明白的是,文件编码类型并不是保存在文件内的,也就是说没有 任何描述性的字段来记录文档是何种编码类型的。因此我们在编辑文档的时候,要么必须知道这文档保存时是以什么编码保存的,要么通过另外的一些手段来断定编 码类型,这另外的手段,就是通过某些编码的码表特征来断定,例如每个字符占用的字节数,每个字符的ascii值是否都大于某个字段来断定这个文件属于何种 编码。这种方式vim也使用了,这就是vim的自动编码识别机制了。但这种机制由于编码各式各样,不可能每种编码都有显著的特征来辨别,所以是不可能 100%准确的。对于我们GB2312编码,由于其中文是使用了2个acsii值高于127的字符组成汉字字符的,因此不可能把gb2312编码的文件与 latin1编码区分开来,因此自动识别编码的机制对于gb2312是不成功的,它只会将文件辨识为latin1编码。此问题同样出现在gbk,big5 上等。因此我们在编辑此类文档时,需要手工设定encoding和fileencoding。如果文档编码为utf-8时,一般vim都能自动识别正确的 编码。
3.客户运行vim的终端所使用的编码类型----同第二条一样,这也是一个比较 难以断定的关键点。第二个关键点决定着从文件读取内容和写入内容到文件时使用的编码,而此关键点则决定vim输出内容到终端时使用的编码,如果此编码类型 和终端认为它收到的数据的编码类型不同,则又会产生乱码问题。在 linux本地X环境下,一般终端都认为其接收的数据的编码类型和系统locale类型相符,因此不需关心此方面是否存在问题。但如果牵涉到远程终端,例 如ssh登录服务器,则问题就有可能出现了。例如从1台locale为GB2310的系统(称作客户机)ssh到locale为utf-8的系统(称作服 务器)并开启vim编辑文档,在不加任何改动的情况下,服务器返回的数据为utf-8的,但客户机认为服务器返回的数据是gb2312的,按照 gb2312来解释数据,则肯定就是乱码了,这时就需要设置termencoding为gb2312来解决这个问题。此问题更多出现在我们的 windows desktop机远程ssh登录服务器的情况下,这里牵扯到不同系统的编码转换问题。所以又与windows本身以及ssh客户端有很大相关性。在 windows下存在两种编码类型的软件,一种是本身就为unicode编码方式编写的软件,一种是ansi软件,也就是程序处理数据直接采用字节流,不 关心编码。前一种程序可以在任何语言的windows上正确显示多国语言,而后一种则编写在何种语言的系统上则只能在何种语言的系统上显示正确的文字。对 于这两种类型的程序,我们需要区别对待。以ssh客户端为例,我们使用的putty是unicode软件,而secure CRT则是ansi 软件。对于前者,我们要正确处理中文,只要保证vim输出到终端的编码为utf-8即可,就是termencoding=utf-8。但对于后者,一方面 我们要确认我们的windows系统默认代码页为cp936(中文windows默认值),另一方面要确认vim设置的termencoding= cp936。
乱码查看器 VIM查看中文编码文件显示为乱码的解决办法
最后来看看处理中文文档最典型的几种情况和设置方式:
1.系统locale是utf-8(很多linux系统默认的locale形 式),编辑的文档是GB2312或GBK形式的(Windows记事本默认保存形式,大部分编辑器也默认保存为这个形式,所以最常见),终端类型utf- 8(也就是假定客户端是putty类的unicode软件)
则vim打开文档后,encoding=utf-8(locale决定的),fileencoding=latin1(自动编码判断机制不准导致的),termencoding=空(默认无需转换term编码),显示文件为乱码。(www.61k.com]
解决方案1:首先要修正fileencoding为cp936或者euc-cn(二者一样的,只不过叫法不同),注意修正的方法不是:set fileencoding=cp936,这只是将文件保存为cp936,正确的方法是重新以cp936的编码方式加载文件为:edit ++enc=cp936,可以简写为:e ++enc=cp936。 解决方案2:临时改变vim运行的locale环境,方法是以LANG=zh_CN vim abc.txt的方式来启动vim,则此时encoding=euc-cn(locale决定的),fileencoding=空(此locale下文件 编码自动判别功能不启用,所以fileencoding为文件本身编码方式不变,也就是euc-cn),termencoding=空(默认值,为空则等 于encoding)此时还是乱码的,因为我们的ssh终端认为接受的数据为utf-8,但vim发送数据为euc-cn,所以还是不对。此时再用命令: set termencoding=utf-8将终端数据输出为utf-8,则显示正常。
2.情况与1基本相同,只是使用的ssh软件为secure CRT类ansi类软件。
vim打开文档后,encoding=utf-8(locale决定的),fileencoding=latin1(自动编码判断机制不准导致的),termencoding=空(默认无需转换term编码),显示文件为乱码。
解决方案1:首先要保证运行secure CRT的windows机器的默认代码页为CP936,这一点中文windows已经是默认设置了。其他的与上面方案1相同,只是要增加一步,:set termencoding=cp936
解决方案2:与上面方案2类似,不过最后一步修改termencoding省略即可,在此情况下需要的修改最少,只要以locale为zh_CN开启 vim,则encoding=euc-cn,fileencoding和termencoding都为空即为encoding的值,是最理想的一种情况。
二 : 国外空间出现乱码的几种解决办法
国外空间出现乱码的几种解决办法
好不容易找到了一个免费的空间,可是把网页放上去一看一些乱码,是不是很上火呢?不过看了这篇文章之后就不用上火了,我们有解决办法! 在数据提取页面的第一行代码换成如下代码即可: <% @language=vbscript codepage=936%> 1.若是HTML文件(.htm .html): 在<head></head>中加上<meta http-equiv="Content-Type" content="text/html; charset=gb2312"> 2.若是PHP/cgi文件(.php .php3 .php4): 在每个PHP文件第一行加上<?header("content-Type: text/html; charset=gb2312"; ?>
3.若是asp文件(.asp .jsp): 下面言归正传,说说asp源文件在国外服务器上中文问题的解决办法:
1.首先,把您的asp源文件放在 IIS 里进行全面测试,调用每一项功能,确认它完全能够使用,并正确显示中文,并打开 *.mdb 数据库文件查看中文显示是否正常。[www.61k.com]全部通过后,做好备份文件,即可执行第二步。
2.如果,您根本不懂 asp 的话,最简单的方法是: 打开 所有 *.asp 文件,并在第一行插入 <%@ codepage="936" %>,
例外情况: ①,如果第一行是以 <%@ LANGUAGE="VBs cript" %> 开头, 则把第一行改为:<%@ codepage="936" LANGUAGE="VBs cript" %>
②,如果第一行是以 <html> 或 <s cript LANGUAGE="javas cript">开头,则不加入。
3.第二步完成后,再用 IIS 对每一项功能进行测试,如显示 �conn.asp line 1, 即为错误信息,意思是: conn.asp 源文件第一行有错,那就把 <%@ codepage="936" %> 删除即可,一些例外错误,请到http://search.microsoft.com/default.asp ;;这里,输入错误信息查询即可,全部功能测试可行后,即可上传至国外服务器上,进行测试。
4.方法还是:调用每一项功能,全部能正确使用并能显示中文后,再下传*.mdb 文件(非常重要),打开,确认能正确显示中文,大功告成。
另外在外国服务器上用ACESS2000的中文显示方法不用转化数据库ACESS2000,只需在ASP第一行加入<%@ codepage=1256 %>
怎么解决外国空间中文显示出问题的问题 非程序生成的文字可以显示。但程序生成的文字就只有E文可以显示了。中文全是?号,这是数据库乱码引起的。
方法一: 使用 Microsoft Access 2000 打开数据库,选择工具菜单>数据库实用工具>转换数据库>到早期 Access 数据库版本。OK!
方法二:
后来订阅了微软的新闻组,在微软的新闻组dotnet.framework.aspplus.general中发现有讨论这 个问题的文章,方法为添加<%@ CODEPAGE = "936" %>到每一页的开头,有点类似于jsp中的 <%@ page contentType="text/html;charset=gb2312"%> 赶紧测试了一下,果然OK!!!
例子如下面所示: <%@ CODEPAGE = "936" %> <%@ Import Namespace="System.Data" %> <%@ Import Namespace="System.Data.ADO" %> <%@ Import Namespace="System.Globalization" %> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <
qq空间乱码 国外空间出现乱码的几种解决办法
/head>
方法三:
添加一个config.web文件到 web目录下, 建立一个文件config.web,内容如下,放在WEB目录下 <configuration> <globalization requestencoding="utf-8" responseencoding="utf-8" /> </configuration>
61阅读提醒您本文地址:
三 : CMD中文乱码不能显示中文的两种解决办法
就是这种,不能输入中文,也不能显示中文,所有的中文都会显示成问号“???????”相当头疼。看看下图这种你就知道什么是头疼了。想知道解决方法吗?

方法一:
1、右键单击CMD标题栏选“默认值”,然后在弹出的窗口里选择默认代码页为936,点确定,然后关掉CMD窗口。如下图所示:
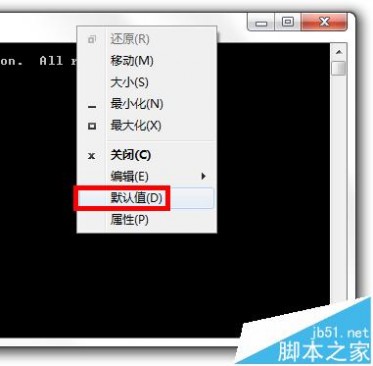

方法二:
1、首先打开注册表:开始菜单,输入regedit,就可以找到注册表了

2、按照下图中找到HKEY_CURRENT_USERConsole,把CodePage项的值改成936,如上图所示。如果在HKEY_CURRENT_USERConsole里面找不到CodePage项,你可以找找HKEY_CURRENT_USERConsole%SystemRoot%_System32_cmd.exe看有没有CodePage项,有的话,改,改成936(十六进制3a8)点确定,关掉注册表。这一次再启动CMD就能看到中文了。
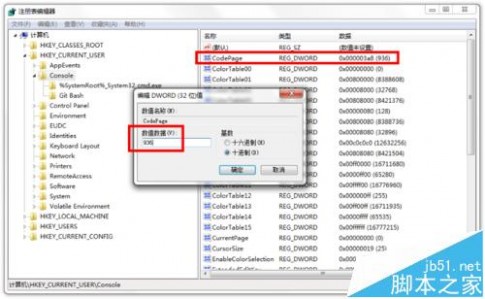
相关知识:
十六进制"000003a8"或十进制"936",表示“936 (ANSI/OEM - 简体中文 GBK)”
十六进制"000001b5"或十进制"437",表示“437 (OEM - 美国)”
四 : 串口显示乱码的原因有哪些?有关串口乱码的问题的解决办法
在通信波特率为 38400 时,通信正常,arm 板上解受到的数据(ascII码)显示正常。但是当波特率为 115200 时,解受到的数据就出现乱码的现象!
用ARM2103 给电脑发送信息,用串口高度精灵看,一直接收的都是错误码。
波特率 换了好几档 比如9600 4800 2400 1200(我用的晶振是 11M多点的那个) 等都试过 都是乱码 区别是一个乱码来得快 一个乱码来得慢 串口线 23 脚短接能正常的自收自发 下载到单片机的程序也没啥问题。
真的不知道,原因出现在哪里!
1.USB转串口的问题
解决方法:我曾用一个12块钱的那种U转串,出现过乱码,换一个好的就没事了
2.波特率不同步的问题
解决方法:两边设置的波特率的一样,会导致这样的问题
3.在通信波特率为 38400 时,通信正常,arm 板上解受到的数据(ascII码)显示正常。
但是当波特率为 115200 时,解受到的数据就出现乱码的现象!
解决方法:暂无
4.用ARM2103 给电脑发送信息,用串口高度精灵看,一直接收的都是错误码
解决方法: 我用的44b0曾经出现过显示乱码的问题,在超级终端上显示的;
后来才发现是在boot汇编程序里设置了主频为60M;但是在串口初始化时用的是40M,在c语言程序里忘记重新设定主频了
呵呵,改了之后就好了
不知道你的是不是这样的
==========================================================================================================================
我的目前的问题:就是乱码,波特率一样了!看看是不是显示的问题:

果真是这个原因,下面就有的放矢……
本文标题:vcf乱码解决办法-VIM查看中文编码文件显示为乱码的解决办法61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1