一 : SQL Server 2008:开辟崭新数据平台
和以往微软开发的工具一样,版本越高其功能也就越为强大,即将发布的SQL Server 2008也是如此。SQL Server 2008是微软数据平台愿景中的一个主要部分,旨在满足目前和将来管理和使用数据的需求。
SQL Server 2008引入了用于提高开发人员、架构师和管理员的能力和效率的新功能。不仅改进了包括Transact-SQL语句、数据类型和管理功能,还添加了许多新特性,比如数据集成功能,分析服务,报告服务,以及Office集成等等,但或许它最为吸引人的地方在于引入了商业智能。
SQL Server 2008是一个集数据仓储、分析和生成报表功能为一身的可扩展的数据平台,提供给终端用户可以用来访问和分析商业信息的强大的和直觉工具,使用户能够:
◆ 统一企业中所有数据的存储和访问。
◆建立和管理复杂的商业智能解决方案。
◆ 扩大用户的商业智能解决方案的范围,使其可以用于所有雇员。
SQL Server 2008并不是一款高不可攀的工具,通过与Office的深度集成,它为所有人提供了可用的商业智能,使公司里所有层级的雇员都可以用他们可以理解和习惯的方式,通过易用和功能强大的工具看到和帮助改变商业执行。
此外,我们可以看到SQL Server 2008新的特性如下面所示:
| 组成 | 描述 |
| SQL Server数据库引擎 | 为大型数据提供了一个可扩展的高性能的数据存储引擎。这为将企业的商业数据合并到一个用于分析和生成报表的中央数据仓库中提供了理想的选择。 |
| SQL Server数据库引擎 | 是一个用于提取、转换和加载(ETL)操作的全面的平台,使得能够对你的数据仓库进行操作和与其同步,数据仓库里的数据是从你的企业中的商业应用所使用的孤立数据源获得的。 |
| SQL Server分析服务 | 提供了用于联机分析处理(Online Analytical Processing,OLAP)的分析引擎,包括在多维度的商业量值聚集和关键绩效指标(KPI),和使用特定的算法来辨别模式、趋势和与商业数据的关联的数据挖掘解决方案。 |
| SQL Server报表服务 | 是一个广泛的报表解决方案,使得很容易在企业内外创建、发布和发送详细的商业报表。 |
SQL Server 2008对用户的所有数据进行整合和管理:使用SQL Server 2008企业级的数据仓库平台可以高效的操纵用户的所有数据,并对其进行统一管理存储。
合并用于最优的报表和分析的数据:对用户所有的数据进行操作,使用SQL Server 2008采用任何用户希望的方式与关系数据和非关系数据进行交互,包括使用户有效的存储、管理和分析无结构的数据——像文档和图片——的新的数据类型。
提高数据仓库性能:更快的将数据整合到数据仓库中,提高大型分区表的管理能力和性能,使用户更有效的管理不断增长的数据和用户的空间。
给所有用户提供一个全面的平台:使用可视化的向导和新颖的工具在一个单独的环境中建立ETL、OLAP和报表解决方案,这个环境是设计用来提高开发人员的生产力和加速对新的分析和报表能力的利用。
提高开发人员的生产力:使用SQL Server 商业智能开发套件提供的丰富的可视化开发环境,来开发、测试和维护强大、可靠和可扩展的数据整合、报表制作和分析解决方案。通过自动提示潜在问题来实现最佳的分析应用。
降低管理费用:SQL Server 2008给数据库管理员提供了一个单独的统一管理工具,它可以提供所有SQL Server技术的集成管理,通过扩展SQL Server工具提高了生产力、灵活性和可管理性。
保护企业可扩展性:用户可以利用SQL Server 2008报表服务(SQL Server 2008 Reporting Services)高度可扩展的平台来有效的设计、管理和生成各种规模和各种复杂度的报表,并将这些报表在正确的时间提供给公司内正确的用户。通过使用SQL Server 2008分析服务提供的可视化cube设计工具和扩大了涵盖范围的设计工具建立强大的高性能解决方案,使用户的商业智能进入下一阶段,使用户的分析架构的开发工作流程化。
使每一个用户都具有全面的洞察力:通过一个用于与Office协作的最佳的、可扩展的、开放的和内嵌的架构使每个人都拥有了丰富的用户经验。
使终端用户具有了制作能力,并扩展了报表方法:通过利用新的Tablix报表设计结合静态和动态的行,以此来制作各种规模和各种复杂度的报表并提高灵活性,Tablix报表设计使得以前很难或不可能设计得了的数据录制环境成为可能。提高终端用户的经验,并利用新的强大的数据可视化工具将复杂的信息转化为丰富的、图形化的和更容易理解的媒体文件。
通过熟悉的工具扩大商业洞察力:可以直接将报表制作成Excel和Word格式。这可以很容易的生成易理解的预测分析提供给广大的用户,使终端用户可以直接在熟悉的Excel环境中利用分析服务极其可靠的数据挖掘规则。
通过以上SQL Server 2008的新特性以及其功能不难看出SQL Server 2008是一个可信任的、高效的、智能的数据平台。SQL Server 2008不仅提供给公司可依靠的技术和能力用于接受管理数据和给用户发送全面的洞察的挑战,在关键领域方面还具有显著的优势,它推出了许多新的特性和关键的改进,使得它成为至今为止的最强大和最全面的SQL Server版本。
二 : sql server 2000数据库备份文件还原成sql server 2005 /2008
前几天需要把公司远程桌面上的一个数据库还原到本地。(www.61k.com)服务器上的是mssql 2000,手动还原到本地sql2008 出错。于是搜索并解决了以下问题。
在sql server 2005 /2008中直接右击数据库选还原数据库。

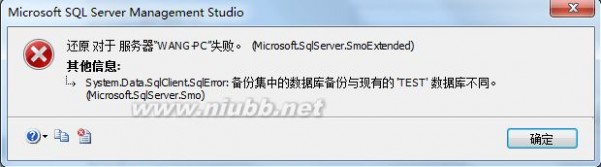
详细错误信息附图如下:
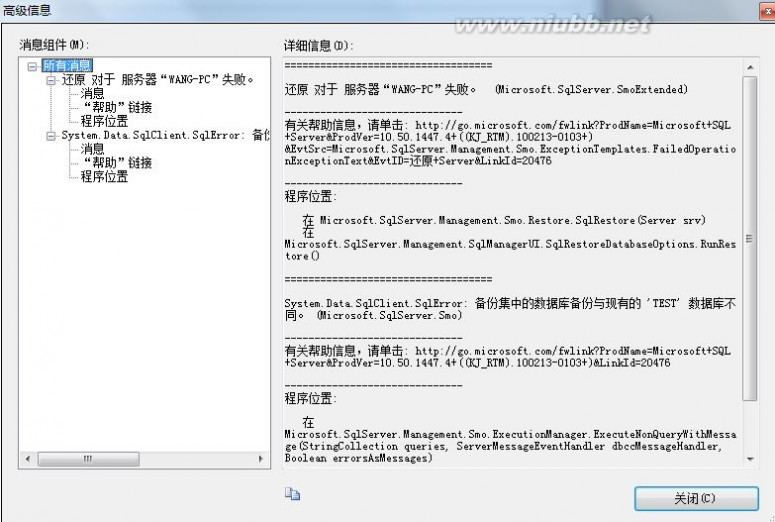
1、删除上述操作中新建的数据库或还原时要起的数据库名称相同的数据库名称,结合上图如删除已存在的'test'数据库;
2、右击“数据库”选择“还原数据库”;

3、在出现的窗口中输入目标数据库,如输入db_test,并选择“源设备”,点击浏览按钮;
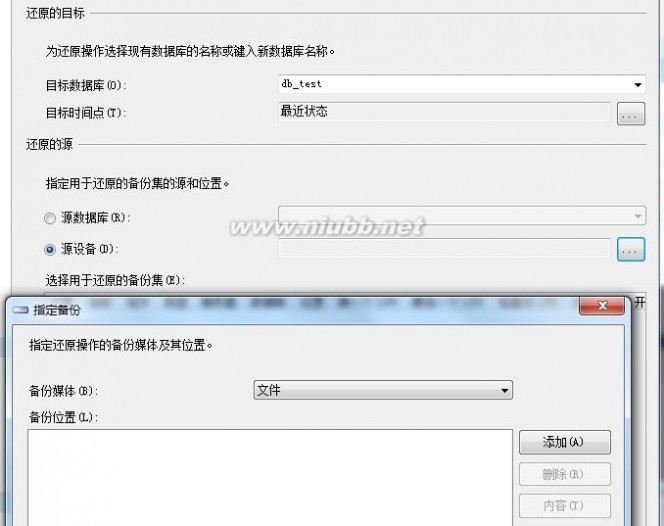
4、单击“添加”按钮,选择Sql Server 2000的备份文件,点击“确定”按钮到初始窗口,勾选文件前“还原”列的复选框;
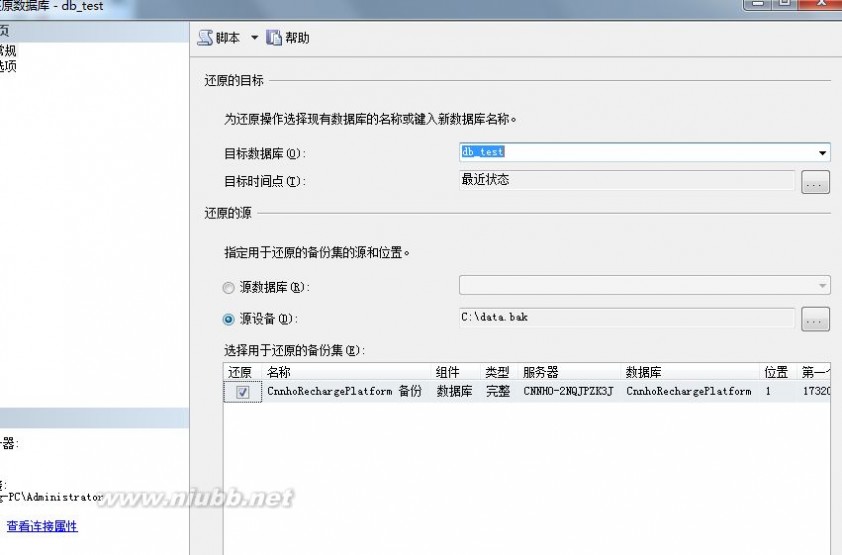
5、点击“确定”按钮,数据库还原成功。
【关键所在】
由上述内容不难看出来,使用Sql Server 2000的数据库备份文件还原Sql Server 2000的数据库和还原Sql Server 2005/2008的数据库时,其关键所在就是在Sql 2000时是必须新建数据库并对其还原,而在Sql 2005时是必须不能新建数据库才能对其还原。另外一个区别就是Sql 2000时是要新建的数据库名称与原库名称相同,而Sql 2005时输入的数据库名称可以是任意的一个名称,不必与原库名称相同。
注意:
如果经过上面的方法还是不可以的话 可能就是数据库备份的数据问题了
三 : 数据库开发规范(SQL SERVER篇) 2012年最新版
第一章命名规范
1.命名标志法
使用下面的三种大写标识符约定。(www.61k.com)
Pascal大小写
将标识符的首字母和后面连接的每个单词的首字母都大写。可以对三字符或更多字符的标识符使用 Pascal 大小写。例如:
BackColor
Camel大小写
标识符的首字母小写,而每个后面连接的单词的首字母都大写。例如:
backColor
大写
标识符中的所有字母都大写。仅对于由两个或者更少字母组成的标识符使用该约定。例如:
System.IO
System.Web.UI
可能还必须大写标识符以维持与现有非托管符号方案的兼容性,在该方案中所有大写字母经常用于枚举和常数值。一般情况下,在使用它们的程序集之外这些字符应当是不可见的。
2.数据库命名
数据库名要求全部使用Pascal命名法
例如:
MFC
MFC53
DataController
3.数据库月份库、数据表日分库命名规则
<DatabaseName><Month>
<TableName><Day>
DatabaseName按数据库命名要求命名
TableName按数据表命名规则命名
Month, Day要求中间无任何连接符
例如
MFCLOG200301
MFC_log_ClientCheckin20030109
4.分段数据库分库命名规则
<DatabaseName><Segment>
DatabaseName按数据库命名要求命名
Segment是分段的编号,要求长度一致并且3位或者以上
例如 NIDCHyper021
5.分段分日期数据库分库命名规则
<DatabaseName><Segment><Day>
DatabaseName按数据库命名要求命名
Segment是分段的编号,要求长度一致并且3位或者以上
Day要求中间无任何连接符
例如
GatheredLog00120110227
MassLog00320110227
6.表的命名
<SystemName>_<TableType>_<Name>
SystemName为表所属的系统名,此处要求采用Pascal命名法
TableType为数据表的类别,此处要求全部使用小写,在我们的库中有如下几种数据表类型:
tb----------数据表,
stat--------统计表,
dict--------字典表,
sys--------系统信息表,
re----------关系表,
log---------日志表
Name为数据库表的名称,此处要求使用Pascal命名法
例如:
MFC_tb_Unit 场所信息表
MFC_stat_UnitDailyStatus 场所状态日统计表
MFC_re_UserArea 用户地区关系表
MFC_log_Customer 顾客日志表
MFC_dict_Sex 性别字典表
7.字段命名
字段命名统一使用Pascal标志法,单词中间不用下划线。应尽量使用简短而又能说明字段实际意义的词组组合,为保证不与系统字段重复,应尽量至少使用两个单词。同样含义的字段应尽量使用已有字段的物理名。
例如:
CertificateCode 证件号
CertificateType 证件类别
AlertClassName 报警类别名
8.存储过程命名
[<SystemName>]<FunctionModule>_<TableName>_<FunctionName>
SystemName是系统名,此处要求使用Pascal命名法,对于跨系统使用的存储过程要求此段,其他非跨系统的存储过程不要求。
FunctionModule为功能模块名,此处要求使用Pascal标志法
TableName为数据库已有表名,命名规则同上面的表命名要求
FunctionName为存储过程的功能说明,此处要求使用Pascal标志法。
常用的功能有:
GetList 取多条记录
GetModel 去单条记录
GetListByCondition 根据Condition条件取单条记录
Add 插入或修改单条记录
Delete 删除记录
Insert 插入单条记录
BatchInsert 批量插入多条记录
BatchUpdate 批量更新多条记录
Update 更新单条记录
例如:
Communication_MFC_re_UnitStatus_GetList
DataAnalysis_NIDC_tb_PersonGroup_Delete
DataAnalysis_MFC_tb_CrimeOnEsc_Add
9.触发器命名,
TR_<TableName>[_<Operation>]
如果只是针对单个操作类型的触发器,则要求说明操作类型:
例如:
TR_MFC_tb_Argot
TR_MFC_tb_Argot_Insert
10.索引命名
IX_<TableName>_<ColumnName>
例如:
IX_MFC_log_Customer_EndTime
11.主键
PK_<TableName>。
TableName同表命名规则
例如
PK_MFC_Log_Customer
12.外键
FK_<TableName1>_<TableName2>
例如:
FK_MFC_log_Customer_MFC_tb_Unit
13.缺省值
DF_<TableName>_<ColumnName>
例如:
DF_MFC_log_Customer_UserName
14.视图的命名用Pascal标志法,和表一致;
<SystemName>_view_<Name>
视图的命名除中间用’view’链接以外与表一致
例如:
MFC_view_Strategy
15.函数的命名
采用存储过程同样的命名规则
16.其他数据库对象命名规则
其他数据库对象,比如约定、队列、服务、路由等采用表名相同的命名法。
17.其他数据库可编程性对象命名
其他数据库可编程性对象采用存储过程相同的命名法。
18.数据库保留字
不要使用数据库保留字,给数据对象命名;
19.禁止使用空格
在数据库对象命名时,禁止使用空格。
第二章常用数据类型
下面是我们再数据库设计中常用的几种数据类型:
数据类型 | 类型 | 描 述 |
int | 整型 | int 数据类型可以存储从- 231(-2147483648)到231(2147483 647)之间的整数。存储到数据库的几乎所有数值型的数据都可以用这种数据类型。这种数据类型在数据库里占用4个字节 |
bigint | 整型 | 从-2^63(-9223372036854775808)到2^63-1(9223372036854775807)的整型数据。这种数据类型在数据库里占用8 字节空间 |
numeric | 精确数值型 | numeric数据类型与decimal 型相同(要求在存储过程或其他语句中必须表名数据长度及精度) |
datetime | 日期时间型 | datetime数据类型用来表示日期和时间。这种数据类型存储从1753年1月1日到9999年12月3 1日间所有的日期和时间数据, 精确到三百分之一秒或3.33毫秒 |
cursor | 特殊数据型 | cursor 数据类型是一种特殊的数据类型,它包含一个对游标的引用。这种数据类型用在存储过程中,而且创建表时不能用 |
Uniqueidentifier | 特殊数据型 | Uniqueidentifier数据类型用来存储一个全局唯一标识符,即GUID。GUID确实是全局唯一的。这个数几乎没有机会在另一个系统中被重建。可以使用NEWID 函数或转换一个字符串为唯一标识符来初始化具有唯一标识符的列 |
char | 字符型 | char数据类型用来存储指定长度的定长非统一编码型的数据。当定义一列为此类型时,你必须指定列长。当你总能知道要存储的数据的长度时,此数据类型很有用。例如,当你按邮政编码加4个字符格式来存储数据时,你知道总要用到10个字符。此数据类型的列宽最大为8000 个字符 |
varchar | 字符型 | varchar数据类型,同char类型一样,用来存储非统一编码型字符数据。与char 型不一样,此数据类型为变长。当定义一列为该数据类型时,你要指定该列的最大长度。 它与char数据类型最大的区别是,存储的长度不是列长,而是数据的长度 |
nvarchar | 统一编码字符型 | nvarchar 数据类型用作变长的统一编码字符型数据。此数据类型能存储4000种字符,使用的字节空间增加了一倍 |
Nvarchar(max) | 统一编码字符型 | 最多为230–1(1?073?741?823)Unicode字符,占用2×字符数+2字节的空间 |
Varchar(max) | 字符型 | 最多为231–1(2?147?483?647)字符,一般用来定义XML的入参,每字符1字节+2字节额外开销 |
varbinary(max) | 二进制数据类型 | 可变长度二进制数据。 n 的取值范围为 1 至 8,000。 max 指示最大存储大小是 2^31-1 个字节。 存储大小为所输入数据的实际长度 + 2 个字节。 |
第三章数据库设计规范
1.三范式
数据库设计中应尽可能遵守三范式。所谓三范式即:
2.适当的冗余
但是完全按照规范化设计的系统几乎是不可能的,除非系统特别的小,在规范化设计后,有计划地加入冗余是必要的。冗余可以是冗余数据库、冗余表或者冗余字段,不同粒度的冗余可以起到不同的作用。冗余可以是为了编程方便而增加,也可以是为了性能的提高而增加。从性能角度来说,冗余数据库可以分散数据库压力,冗余表可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
比如一些日志表的历史统计信息,我们可以通过作业定期在数据库负载较小的凌晨8点对数据日志数据进行统计,并建立冗余的统计表记录下来。
3.主键
主键是必要的,SQL SERVER的主键同时是一个唯一索引,而且在实际应用中,我们往往选择最小的键组合作为主键,所以主键往往适合作为表的聚集索引。聚集索引对查询的影响是比较大的,这个在下面索引的叙述。在有多个键的表,主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前面。
4.索引
索引分为聚集索引和非聚集索引。
每个数据表只能建立一个聚集索引,聚集索引决定了数据在表中的物理顺序,同时非聚集索引依赖聚集索引存在。每一个非聚集索引B树的页节点都存有对应的聚集索引键。因此聚集索引和非聚集索引的选择应该遵守如下规范:
1) 应尽量选择符合唯一约束的字段建立聚集索引
2) 尽量选择占用空间较小的字段建立聚集索引,一般要求聚集索引小于900字节
3) 根据数据量决定哪些表需要增加索引,数据量小的可以只有主键。同时对数据量比较大的表(>1000行)应结合数据表的使用情况建立非聚集索引以提高数据库查询的反应效率。但是过多的非聚集索引也会影响数据表记录的插入及更新速度,一般要求非聚集索引的个数不超过两位数。因此应该针对各数据表的实际情况设计索引。
4) 若某列的值大部分是a,少数是别的值(如b,c,d…),且经常以该列的其它值(如b,c,d…)为查询条件,可以考虑对(如b,c,d…)建立筛选索引。
5) 把经常一起出现的字段组合在一起,组成组合索引,组合索引的字段顺序与主键一样,也需要把最常用的字段放在前面,把重复率低的字段放在前面,同一索引中的组成列最好不要超过3列。
6) 根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段。
7) 若表主要用来查询,则可按需要建立索引,若对表操作主要是UPDATE,则尽可能少建索引。
5.主键与聚集索引的关系
在数据库设计中,我们经常容易混淆主键和聚集索引的关系。因为如果我们建立主键的时候没有特别说明,SQL SERVER会默认在主键上建立聚集索引。同时由于聚集索引同时也是唯一索引,而且主键一般为较小的键。所以我们经常将主键作为聚集索引。但是这并不表示主键和聚集索引等同。
第四章存储过程编写规范
统一和规范的代码书写风格对保证软件的开发质量、提高团队的开发效率以及将来的维护及其扩展都至关重要。
1.注释
为了增强可读性及美观性,在存储过程头部和存储过程中间应尽量按照如下演示的存储过程做好注释。
USE [MFC_HOTEL] GO /*------------------------------------ -- 用途:根据用户ID查询辖区场所统计 -- 项目名称: -- 说明:这里对存储过程进行详细说明 -- 时间:2012-09-24 -- 编写者: *** -------------------------------------- -- 修改记录: -- 编号 修改时间 修改人 修改原因 修改标注 -- 001 2012-10-11 *** 这里说明修改原因 001 ------------------------------------ 测试语句 EXEC Web_UnitMange_MFC_tb_Unit_GetTreeList @LocationStatus=2 */ CREATE PROCEDURE [dbo].[Web_UnitMange_MFC_tb_Unit_GetTreeList] ( @GuildIDXML VARCHAR(MAX)=NULL, @LocationStatus INT=0 --0-全部;1-已标注;2-未标注 ) AS BEGIN --存储过程应尽量保持这种缩进风格,增强美观性和可读性 SET NOCOUNT ON --每个存储过程中关闭统计 --这里介绍每个代码块的功能,增强代码可读性 IF ISNULL(@GuildIDXML,'')<>'' BEGIN EXEC sp_xml_preparedocument @Handle OUTPUT, @GuildIDXML /*SELECT GuildID INTO #TempGuildID 修改前的代码段注释保留*/ INSERT INTO #TempGuildID --001 这里标注相应修改的位置 SELECT GuildID FROM OPENXML(@Handle, N'/ROOT/ROW') WITH (GuildID int) EXEC sp_xml_removedocument @Handle END END |
2.书写规范
数据库服务器端的触发器和存储过程是一类特殊的文本,为方便开发和维护,提高代码的易读性和可维护性。规范建议按照分级缩进格式编写该文本。
1) 编写存储过程时应遵守以下缩进规则,如下示例
IF 1<>1 BEGIN --每个IF条件后的程序块缩进 SELECT U.[GuildID] --各字段尽量对其 ,U.[UnitCode] --每个查询字段要写明表别名或表名 ,U.[UnitID] ,U.[AreaCode] FROM [MFC_HOTEL].[dbo].[MFC_tb_Unit] U WITH(NOLOCK) INNER JOIN MFC_HOTEL.dbo.MFC_tb_Area A WITH(NOLOCK) ON U.AreaCode = A.AreaCode --JOIN条件缩进增强层次感 WHERE A.IsActive=0 --FROM,JOIN,WHERE对齐 END ELSE RETURN
2) 不要使用SELECT * 需要哪些字段,查询哪些字段, 尽可能少的返回结果集行的数量。
3) 在多表关联时,列名前需要加上别名(或表名),表名前加Owner(dbo)。如果涉及到跨数据库,就需要加上数据库名称。
例如:AdventureWorks.dbo.Contact;存储过程也一样;
4) SQL保留字要大写
对SQL的保留字,都需要大写。
例如:SELECT,UPDATE,INSERT,WHERE,INNER JOIN,AND,OR等。
5) 过多使用GOTO语句会使得代码可读性降低
6) 查询列表和条件中的字段全部需要指定所属的表,可以使用表名别名简化。表名别名要简短,但意义要尽量明确,避免使用A、B、C等过于简单的别名。通常,使用大写的表名作为别名,使用 AS 关键字指定表或字段的别名。
3.性能相关
1) Where子句尽量避免使用函数;
2) 避免在ORDER BY子句中使用表达式;
3) 限制在GROUP BY子句中使用表达式;
4) 慎用游标;
5) 避免隐式类型转换,例如字符型一定要用’’,数字型一定不要使用’’;
6) 查询语句一定要有范围的限定,避免全表扫描操作;
7) 慎用DISTINCT关键字;
8) 慎用OR关键字,可以用UNION ALL替代;
9) 除非必要,尽量用UNION ALL而非UNION
10) 使用EXISTS(SELECT 1)替count(*)来判断是否存在记录;
11) SET NOCOUNT ON 语句
把 SET NOCOUNT ON 语句放到存储过程和触发器中,作为第一句执行语句。例如:
CREATE PROCEDURE [dbo].[UP_GetOrgChildren] AS BEGIN SET NOCOUNT ON ...... 关闭数据库提示输出。
4.尽量使用索引
1) IN/OR子句使用
IN、OR、NOT IN 应尽量避免使用,这可能会导致SQL SERVER不使用索引而选择全表扫描,可以索引查找的,可以正常使用。
2) !=或<>操作符子句使用
!=或<>操作符应尽量避免使用,可以用索引查找的,可以正常使用。
3) 不要对索引字段进行运算
例如: SELECT ID FROM T WHERE NUM/2=100 应改为: SELECT ID FROM T WHERE NUM=100*2 SELECT ID FROM T WHERE NUM/2=NUM1 如果NUM有索引应改为: SELECT ID FROM T WHERE NUM=NUM1*2
如果NUM1有索引则不应该改。
4) 不要对索引字段进行格式转换
日期字段的例子: WHERE CONVERT(VARCHAR(10),日期字段,120)='2008-08-15' 应该改为 WHERE 日期字段>='2008-08-15' AND 日期字段<'2008-08-16'
5) 不要对索引字段使用函数
日期查询的例子: WHERE LEFT(NAME, 3)='ABC' 或者 WHERE SUBSTRING(NAME,1, 3)='ABC' 应改为: WHERE NAME LIKE 'ABC%' 日期查询的例子: WHERE DATEDIFF(DAY, 日期,'2005-11-30')=0 应改为:WHERE 日期>='2005-11-30' AND 日期<'2005-12-1' WHERE DATEDIFF(DAY, 日期,'2005-11-30')>0 应改为:WHERE 日期<'2005-11-30' WHERE DATEDIFF(DAY, 日期,'2005-11-30')>=0 应改为:WHERE 日期<'2005-12-01' WHERE DATEDIFF(DAY, 日期,'2005-11-30')<0 应改为:WHERE 日期>='2005-12-01' WHERE DATEDIFF(DAY, 日期,'2005-11-30')<=0 应改为:WHERE 日期>='2005-11-30'
6) 不要对索引字段进行多字段连接
例如: WHERE FAME+'.'+LNAME='H.Y' 应改为: WHERE FNAME='H' AND LNAME='Y'
7) Like的使用
对索引列避免使用like ‘%xx’, 应该使用like ‘xx%’。设计数据结构时就应该考虑这个问题,不要出现必须要采用like ‘%xx’才能满足业务需要的情形。
5.事务和锁
事务是数据库应用中和重要的工具,它有原子性、一致性、隔离性、持久性这四个属性,很多操作我们都需要利用事务来保证数据的正确性。在使用事务中我们需要做到尽量避免死锁、尽量减少阻塞。具体以下方面需要特别注意:
1) 使用NOLOCK提示查询优化器
在繁忙的系统中,对改善并发问题,是个不错的选择;
2) 在存储过程,触发器,以及SQL 簇中,尽可能按照相同的循序来访问相关的表。这样可以减少死锁的机会;
3) 事务尽可能短
4) 在事务中涉及到数据修改量,尽可能小,提高事务中每个语句的效率,利用索引和其他方法提高每个语句的效率可以有效地减少整个事务的执行时间。
5) 事务操作过程不应该有交互,因为交互等待的时候,事务并未结束,可能锁定了很多资源。
6) 尽可能低的设置锁,以及隔离的级别。
7) 尽量不要指定锁类型和索引,SQL SERVER允许我们自己指定语句使用的锁类型和索引,但是一般情况下,SQL SERVER优化器选择的锁类型和索引是在当前数据量和查询条件下是最优的,我们指定的可能只是在目前情况下更有,但是数据量和数据分布在将来是会变化的。
6.其他注意事项
1) 在相关表存在的数据库下创建存储过程和函数
2) 有设置默认值限制的字段不允许设置为可以为空
3) 合理对大表进行分区
4) 视图嵌套使用不能超过3层
5) 对数据量比较大的日志表,应按日期,ID段分库分表
7.注意临时表和表变量的用法
在复杂系统中,临时表和表变量很难避免,关于临时表和表变量的用法,需要注意:
1) 如果语句很复杂,连接太多,可以考虑用临时表和表变量分步完成。
2) 如果需要多次用到一个大表的同一部分数据,考虑用临时表和表变量暂存这部分数据。
3) 如果需要综合多个表的数据,形成一个结果,可以考虑用临时表和表变量分步汇总这多个表的数据。
4) 其他情况下,应该控制临时表和表变量的使用。
5) 关于临时表和表变量的选择,很多说法是表变量在内存,速度快,应该首选表变量,但是在实际使用中发现,这个选择主要考虑需要放在临时表的数据量,在数据量较多的情况下,临时表的速度反而更快。
6) 临时表使用CREATE TABLE + INSERT INTO的方式
8.注意子查询的用法
子查询是一个SELECT查询,它嵌套在SELECT、INSERT、UPDATE、DELETE 语句或其它子查询中。任何允许使用表达式的地方都可以使用子查询。子查询可以使我们的编程灵活多样,可以用来实现一些特殊的功能。但是在性能上,往往一个不合适的子查询用法会形成一个性能瓶颈。如果子查询的条件中使用了其外层的表的字段,这种子查询就叫做相关子查询。相关子查询可以用IN、NOT IN、EXISTS、NOT EXISTS引入。
关于相关子查询,应该注意:
1) NOT IN、NOT EXISTS的相关子查询可以改用LEFT JOIN代替写法。
例如:
SELECT BEA.[AddressID] ,BEA.[AddressTypeID] FROM [AdventureWorks2012].[Person].[BusinessEntityAddress] BEA WITH(NOLOCK) WHERE BusinessEntityID NOT IN (SELECT BusinessEntityID FROM [AdventureWorks2012].[Person].[BusinessEntity] WITH(NOLOCK))
可以改写成
SELECT BEA.[AddressID] ,BEA.[AddressTypeID] FROM [AdventureWorks2012].[Person].[BusinessEntityAddress] BEA WITH(NOLOCK) LEFT JOIN [AdventureWorks2012].[Person].[BusinessEntity] BE WITH(NOLOCK) ON BEA.BusinessEntityID = BE.BusinessEntityID WHERE BE.BusinessEntityID IS NULL
2) 如果保证子查询没有重复 ,IN、EXISTS的相关子查询可以用INNER JOIN 代替。
SELECT BEA.[AddressID] ,BEA.[AddressTypeID] FROM [AdventureWorks2012].[Person].[BusinessEntityAddress] BEA WITH(NOLOCK) WHERE BusinessEntityID IN (SELECT BusinessEntityID FROM [AdventureWorks2012].[Person].[BusinessEntity] WITH(NOLOCK))
可以改写成:
SELECT BEA.[AddressID] ,BEA.[AddressTypeID] FROM [AdventureWorks2012].[Person].[BusinessEntityAddress] BEA WITH(NOLOCK) INNER JOIN [AdventureWorks2012].[Person].[BusinessEntity] BE WITH(NOLOCK) ON BEA.BusinessEntityID = BE.BusinessEntityID
3) 不要用COUNT(*)的子查询判断是否存在记录,最好用LEFT JOIN或者EXISTS
SELECT BEA.[AddressID] ,BEA.[AddressTypeID] FROM [AdventureWorks2012].[Person].[BusinessEntityAddress] BEA WITH(NOLOCK) WHERE (SELECT COUNT(*) FROM [AdventureWorks2012].[Person].[BusinessEntity] WITH(NOLOCK))=0
可以改写成:
SELECT BEA.[AddressID] ,BEA.[AddressTypeID] FROM [AdventureWorks2012].[Person].[BusinessEntityAddress] BEA WITH(NOLOCK) LEFT JOIN [AdventureWorks2012].[Person].[BusinessEntity] BE WITH(NOLOCK) ON BEA.BusinessEntityID = BE.BusinessEntityID WHERE BE.BusinessEntityID IS NULL
9.常用写法
9.1. XML解析
CREATE TABLE #Temp ( FieldName nvarchar(50), FieldValue nvarchar(256), Memo nvarchar(100) ) DECLARE @docHandle int EXEC sp_xml_preparedocument @docHandle OUTPUT, @Xml INSERT INTO #Temp(FieldName,FieldValue,Memo) SELECT FieldName, FieldValue, Memo FROM OPENXML(@docHandle, N'/ROOT/ROW') WITH ( FieldName nvarchar(50), FieldValue nvarchar(256), Memo nvarchar(100) ) EXEC sp_xml_removedocument @docHandle
9.2. 检查表是否有数据
IF EXISTS(SELECT 1 FROM #Temp)
9.3. 检查变量是否为空或为’’
IF ISNULL(@Input,'')<>''
9.4. 动态SQL
--不带输出参数值的写法 DECLARE @SQL NVARCHAR(MAX),@Input INT SET @Input=1 SET @SQL=N' SELECT UnitCode FROM dbo.MFC_tb_Unit WITH(NOLOCK) WHERE UnitID='+CONVERT(NVARCHAR(8),@Input) EXEC(@SQL) --带输出参数值的写法 DECLARE @SQL NVARCHAR(MAX),@Input INT,@Output NVARCHAR(20) SET @Input=1 SET @SQL=N' SELECT @Output=UnitCode FROM dbo.MFC_tb_Unit WITH(NOLOCK) WHERE UnitID=@Input ' EXEC sp_executesql @SQL,N'@Input INT,@Output NVARCHAR(20) OUTPUT',@Input,@Output OUTPUT PRINT @Output
9.5. 建表
CREATE TABLE [dbo].[NB_re_RoleDepartment]( [RoleID] [int] NOT NULL, [DepartmentID] [int] NOT NULL, CONSTRAINT [PK_NB_RE_ROLEDEPARTMENT] PRIMARY KEY CLUSTERED ( [RoleID] ASC, [DepartmentID] ASC )WITH (IGNORE_DUP_KEY = OFF,DATA_COMPRESSION = PAGE) ON [PRIMARY] ) ON [PRIMARY] 这其中DATA_COMPRESSION = PAGE页压缩选项在SQL SERVER2008或之后的版本才能使用
9.6. 建索引
CREATE NONCLUSTERED INDEX [IX_MFC_tb_Process_UserID] ON [dbo].[MFC_tb_Process] ([UserID] DESC)WITH (DATA_COMPRESSION = PAGE) ON [PRIMARY] 这其中DATA_COMPRESSION = PAGE页压缩选项在SQL SERVER2008或之后的版本才能使用
9.7. 建用户
--创建数据库用户sdfsa IF NOT EXISTS (SELECT * FROM sys.server_principals WHERE name = N'sdfsa') CREATE LOGIN [sdfsa] WITH PASSWORD=N'123214', DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[简体中文], CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF GO EXEC sys.sp_addsrvrolemember @loginame = N'sdfsa', @rolename = N'sysadmin' GO
9.8. 建全文索引
BEGIN TRY -- 屏蔽全文错误 --建全文索引目录 IF NOT EXISTS(SELECT name FROM sys.fulltext_catalogs WHERE name = 'ChatQQ20121018') -- 全文目录不存在 AND EXISTS (SELECT 1 FROM sys.tables WHERE name = 'NIR_log_ChatQQ20121018') -- 表存在 BEGIN CREATE FULLTEXT CATALOG ChatQQ20121018 WITH ACCENT_SENSITIVITY = ON AUTHORIZATION [dbo] END; --建全文索引 IF NOT EXISTS(SELECT 1 FROM sys.fulltext_indexes WHERE object_id = object_id('NIR_log_ChatQQ20121018')) -- 全文索引不存在 AND EXISTS (SELECT 1 FROM sys.tables WHERE name = 'NIR_log_ChatQQ20121018') -- 表存在 AND EXISTS (SELECT 1 FROM sys.fulltext_catalogs WHERE name = 'ChatQQ20121018') -- 全文目录存在 BEGIN CREATE FULLTEXT INDEX ON NIR_log_ChatQQ20121018([Content]) KEY INDEX PK_NIR_log_ChatQQ20121018 ON ChatQQ20121018 END END TRY BEGIN CATCH END CATCH SQL SERVER 2008及以后全文索引目录是一个虚拟的概念,不需要制定PATH9.9. 建链接服务器
-- 增加链接服务器 exec sp_addlinkedserver 'MFC208', ' ', 'SQLOLEDB ', '192.168.1.27' --MFC208是链接服务器的数据库逻辑名(别名) -- 增加链接服务器关联登录用户 exec sp_addlinkedsrvlogin 'MFC208 ', 'false ',null, 'asdf', '654561' --MFC208是链接服务器关联到远程的用户asdf,密码是654561
9.10. SERVICE BROKER
USE MFC GO --建立消息类型 CREATE MESSAGE TYPE [XMLMessageType] VALIDATION = WELL_FORMED_XML GO --建立约定 CREATE CONTRACT [XMLMessageContract] ([XMLMessageType] SENT BY INITIATOR) GO --建立队列 CREATE QUEUE [dbo].[Queue_Argot] WITH STATUS = ON , RETENTION = OFF ON [PRIMARY] GO --建立服务 CREATE SERVICE [Service_Argot] ON QUEUE [dbo].[Queue_Argot] ([XMLMessageContract]) GO --建立表删除新增触发器,并发送消息到队列 CREATE TRIGGER [dbo].[TR_MFC_tb_Argot] ON [dbo].[MFC_tb_Argot] FOR INSERT,DELETE AS BEGIN IF @@ROWCOUNT=0 RETURN SET NOCOUNT ON -- 将要发送的数据生成xml 数据 DECLARE @message xml IF EXISTS ( SELECT 1 FROM INSERTED ) BEGIN SET @message = ( SELECT Operation = 'INSERTED' ,ArgotName AS KeyWordID FROM INSERTED FOR XML RAW('ROW') , ROOT('ROOT') ) END IF EXISTS ( SELECT 1 FROM DELETED ) BEGIN SET @message = ( SELECT Operation = 'DELETED' ,ArgotName AS KeyWordID FROM DELETED FOR XML RAW('ROW') , ROOT('ROOT') ) END DECLARE @handle uniqueidentifier BEGIN DIALOG CONVERSATION @handle FROM SERVICE [Service_Argot] TO SERVICE N'Service_Argot' ON CONTRACT XMLMessageContract WITH ENCRYPTION = OFF; SEND ON CONVERSATION @handle MESSAGE TYPE XMLMessageType(@message); -- 消息发出即可, 不需要回复, 因此发出后即可结束会话 --END CONVERSATION @handle END9.11. 分区
--创建分区函数 IF NOT EXISTS (SELECT 1 FROM sys.partition_functions WHERE name = N'MFCPartitionFunction') CREATE PARTITION FUNCTION [MFCPartitionFunction](bigint) AS RANGE FOR VALUES (-7378697629483820647, -5534023222112865486, -3689348814741910325, -1844674407370955164, -3, 1844674407370955158, 3689348814741910319, 5534023222112865480, 7378697629483820641, 8378697629483820641) GO --创建分区方案 IF NOT EXISTS (SELECT 1 FROM sys.partition_schemes WHERE name = N'MFCPartitionScheme') CREATE PARTITION SCHEME [MFCPartitionScheme] AS PARTITION [MFCPartitionFunction] TO ([2005P1], [2005P2], [2005P3], [2005P4], [2005P5], [2005P6], [2005P7], [2005P8], [2005P9], [2005P10], [PRIMARY]) GO IF NOT EXISTS (SELECT 1 FROM sys.partition_schemes WHERE name = N'MFCPartitionSchemeInd') CREATE PARTITION SCHEME [MFCPartitionSchemeInd] AS PARTITION [MFCPartitionFunction] TO ([PRIMARY], [2005P10], [2005P9], [2005P8], [2005P7], [2005P6], [2005P5], [2005P4], [2005P3], [2005P2], [2005P1]) GO
四 : 你所不知道的SQL Server数据库启动过程,以及启动不起来的各种问题的分
目前SQL Server数据库作为微软一款优秀的RDBMS,其本身启动的时候是很少出问题的,我们在平时用的时候,很少关注起启动过程,或者很少了解其底层运行过程,大部分的过程只关注其内部的表、存储过程、视图、函数等一系列应用方式,而当有一天它运行的正常的时候突然启动不起来了,这时候就束手无策了,能做的或许只能是重装、配置、还原等,但这一个过程其实是一个非常耗时的过程,尤其当我们面对是庞大的生产库的时候,可能在这火烧眉毛的时刻,是不允许你再重搭建一套环境的。[www.61k.com)
所以作为一个合格的数据库使用者,我们要了解其启动、运行过程的事情,一旦发生问题,我们也能及时定位,迅速解决。
闲言少叙,我们进入本篇的正题。
SQL Server本身就是一个Windows服务,每一个实例对应的就是一个sqlserver.exe进程。这是一个可执行的文件,默认就放在SQL Server的安装目录下,当我们启动的时候,就是直接调用这个文件,然后启动这个服务。
第一部分、SQL Server实例启动的方法和启动所发生的问题
SQL Server实例分为下面几种启动方法:
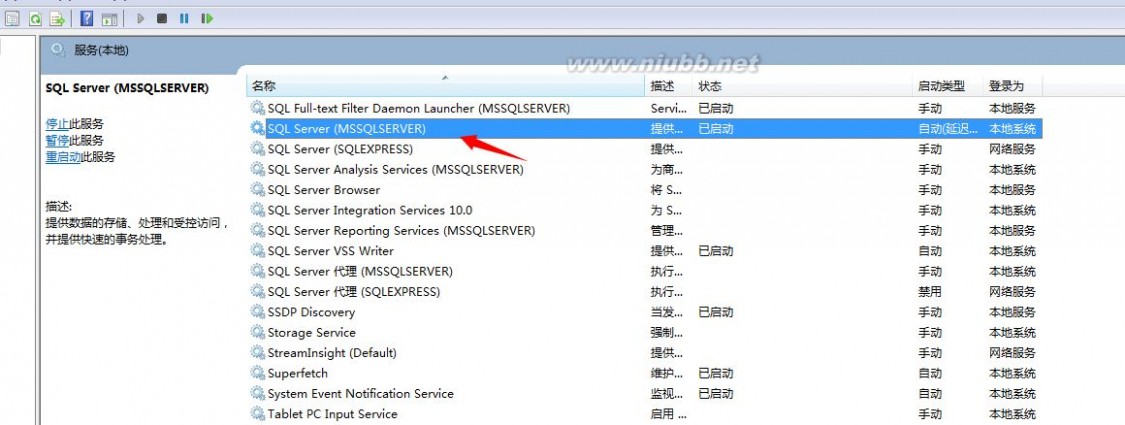
(1)在Windows服务控制台里手动启动,或者自动启动(默认),这个也是最常用的方式
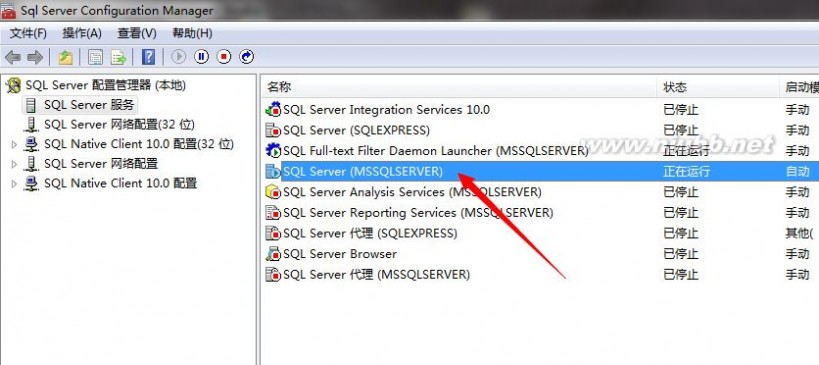
(2)第二种方式是SQL Server本身自己提供的启动方式,我们这里可以手动启动
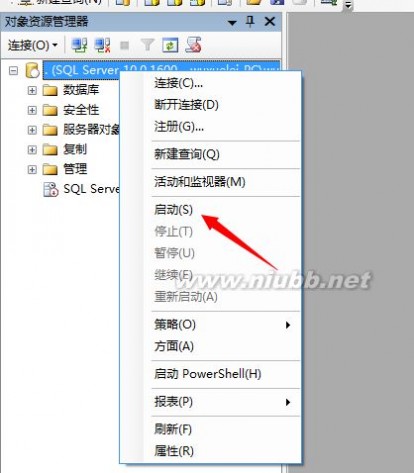
(3)在SQL Server的SSMS里面手动启动它,这个方式一般大部分利用这种方式进行手动重启
(4)通过Windows命令窗口,用'net start'命令手动启动,这种方法也可以用

以上这几种方式都可以启动SQL Sever,并且都会在SQL 日志信息中有所记录。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第二部分、SQL Server实例启动的详细过程以及所发生的问题项
第一步、检查注册表项
当一个sqlserver.exe文件开始启动的时候,首先要干的第一件事就是先检查它的配置信息存放于注册表的值项
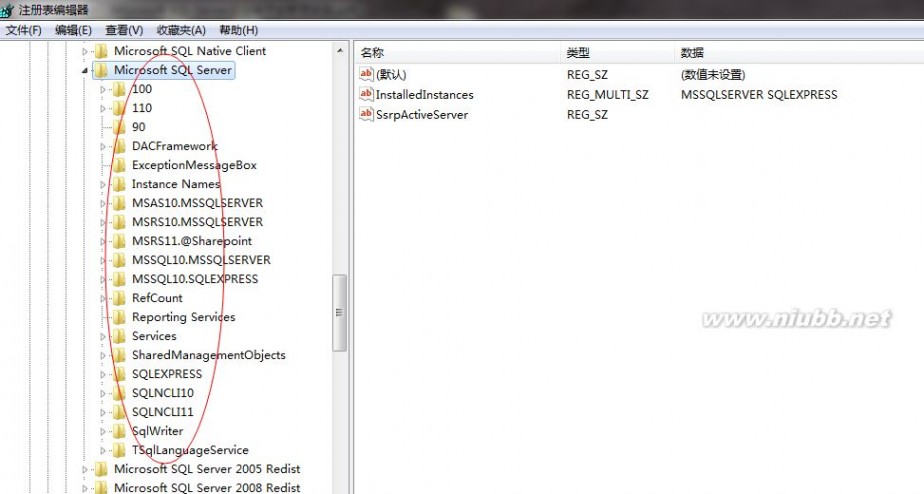
比较重要的几个键值有下面几个:
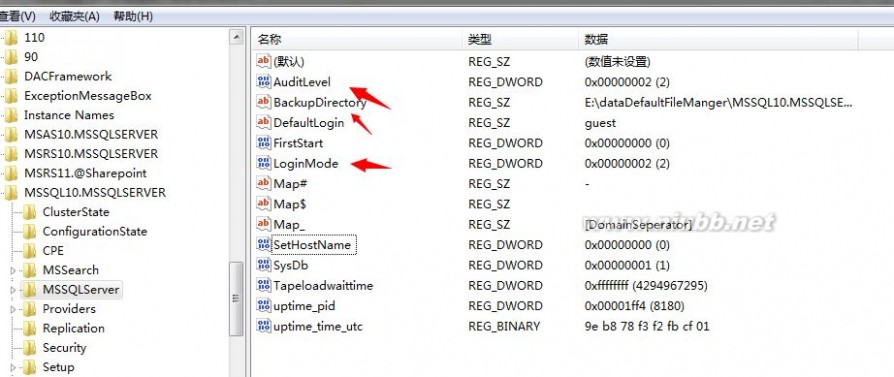
这里的
AuditLevel:其实就是SQL 如何记录用户登录记录;
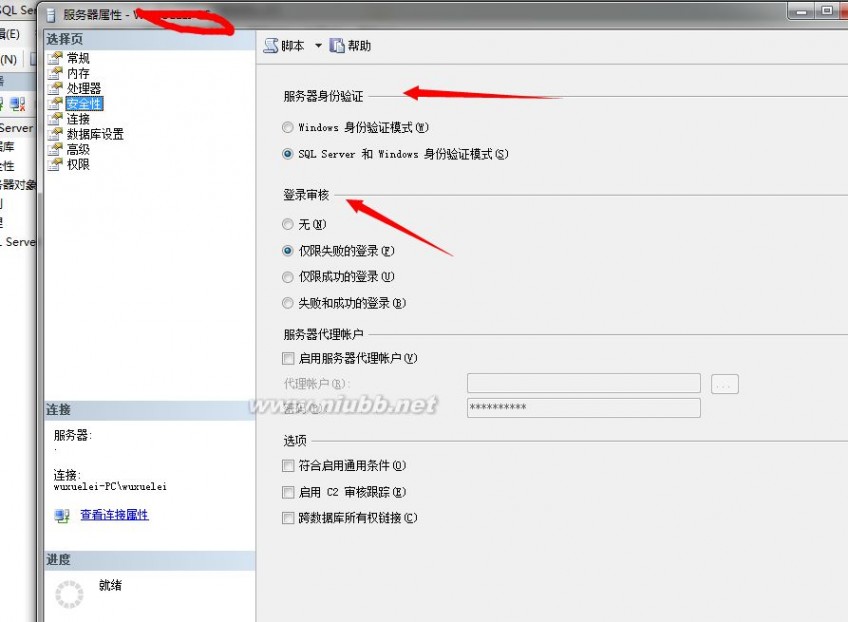
LoginMode:是SQL Server服务器身份验证方式等;
BackupDirectory:默认的备份路径等信息;
关于注册表信息简要了解即可,不建议做任何修改,当然这些值的信息默认在SQL Server中都能设置:
在不修改注册表的情况下,一般这一步的启动顺序一般不会出现问题,当然出现问题了也通常没有办法解决,大部分的解决方式只有重装了。
但这一步骤,通常出现以下两个个问题通常是可以解决的:
<1>启动账号权限问题
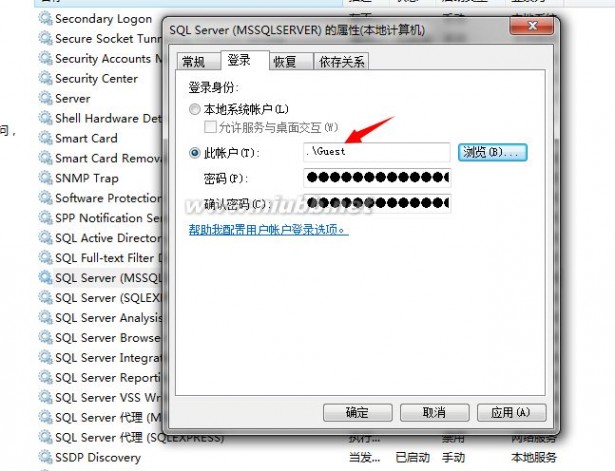
如果我们启动SQL Server的进程使用的账号连读注册表的权限都没有,那这个服务是怎么也启动不了的,通常这时候连SQL 的错误日志都没有能力生成出来。
这时候我们该如何发现呢,虽然这时候它没有能力创建SQL 的错误日志,但是它在Windows层面留下了痕迹,我们来看:
我将服务启动账号设置成gust来宾账号,来启动该服务
这时候会产生以下错误信息:
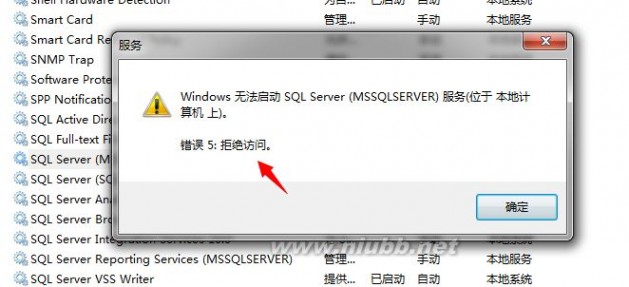
在Windows的日志信息里也会产生一条错误日志记录:
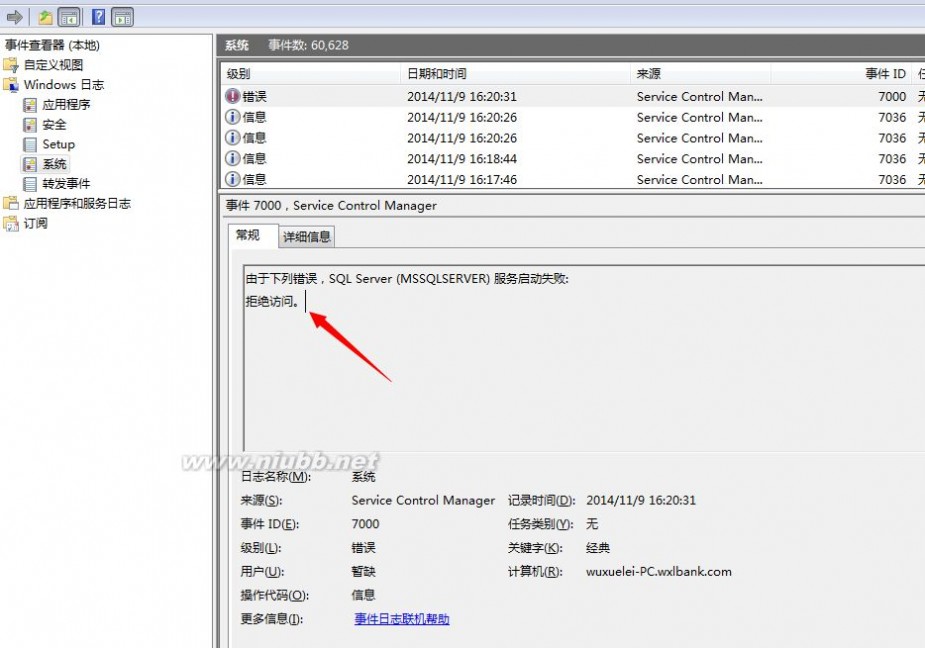
这里的拒绝访问指的就是拒绝访问注册表信息了。
解决方法:
此问题的解决方式就很简单了,只需要将当然的用户提权到SQL Server服务的启动账号就行了,提权的方式也很简单,只需要添加到SQL的本地用户的启动服务组就可以了。

当然,也可以直接换一个更高级别的用户登录。一般默认都用的超级管理员账户。
<2>访问日志和文件夹出现问题
默认在SQL Server启动的时候会创建一个启动日志文件,记录所有正确的日志信息,当然也包括错误的日志信息,如果这时候找不到这个日志信息的路径,或者已经存在一个日志,但是日志被锁定了(某些NB的杀毒软件擅长干这个),这时候这个服务也是启动不了的,同样也创建不出SQL Server的日志文件,这时候我们还得借助于Windows平台本身,来解决。
SQL Server启动的创建的日志文件路径,同样存在于注册表项里,我们来看这个参数: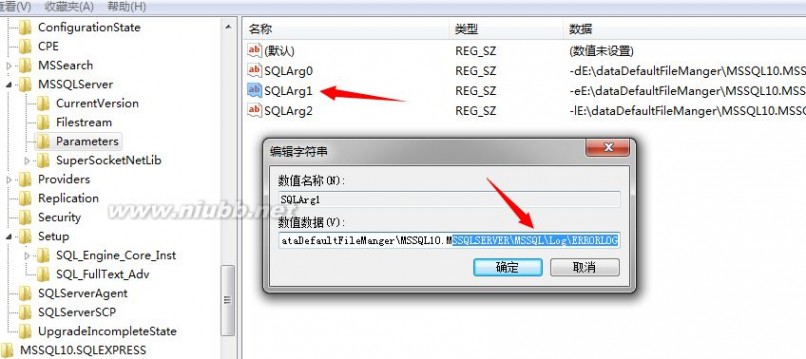
这里我们故意改成一个错误的路径,来启动下看看:
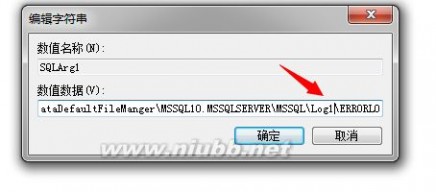
会产生以下错误

系统的错误日志信息
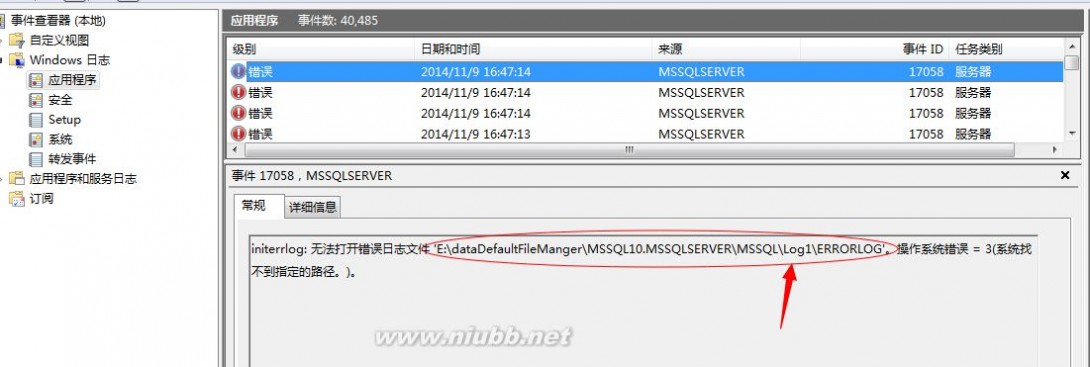
错误说明的很清楚。
解决方法:
这个问题解决起来也很简单,只需要检查好该路径,确保路径下的文件正确就可以。
不过有一点需要注意,当SQL Server还没启动起来的时候,有部分错误信息日志需要检查Windows平台下的系统日志。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第二步、检查系统配置环境,包括硬盘、内存与CPU等
当我们进行完第一步的时候,SQL Server已经读取完注册表信息,完成了它的errorlog文件的创建,然后开始进行第二步的进行,这一步骤所有的信息就会按照顺序依次记录到errorlog文件中,我们可以通过查看该文件来详细跟踪这一步骤的进行,根据上一步的注册表信息,我们先来手动清空下这个日志,然后重启一下SQL Server服务,查看下这个日志记录
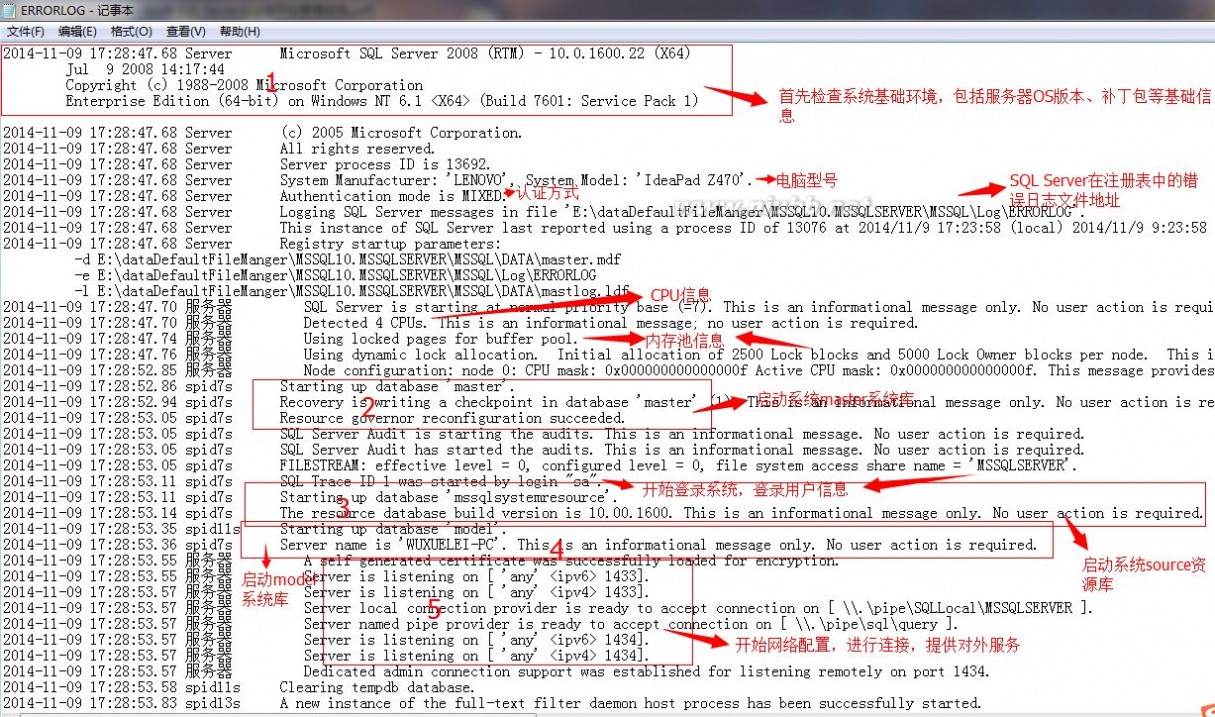
我们简单大致分了以下几大步骤:
一、首先检查系统的软件环境,包括OS版本、电脑信号、内存、硬盘、注册表基础配置项是否正确等
二、启动系统数据库master
三、开始利用服务用户登录系统、启动系统资源数据库、检查数据库版本信息等
四、启动系统数据库model
五、开始网络配置进行连接,对外提供服务,使用的默认的1433端口
我们接着分析下面的日志:
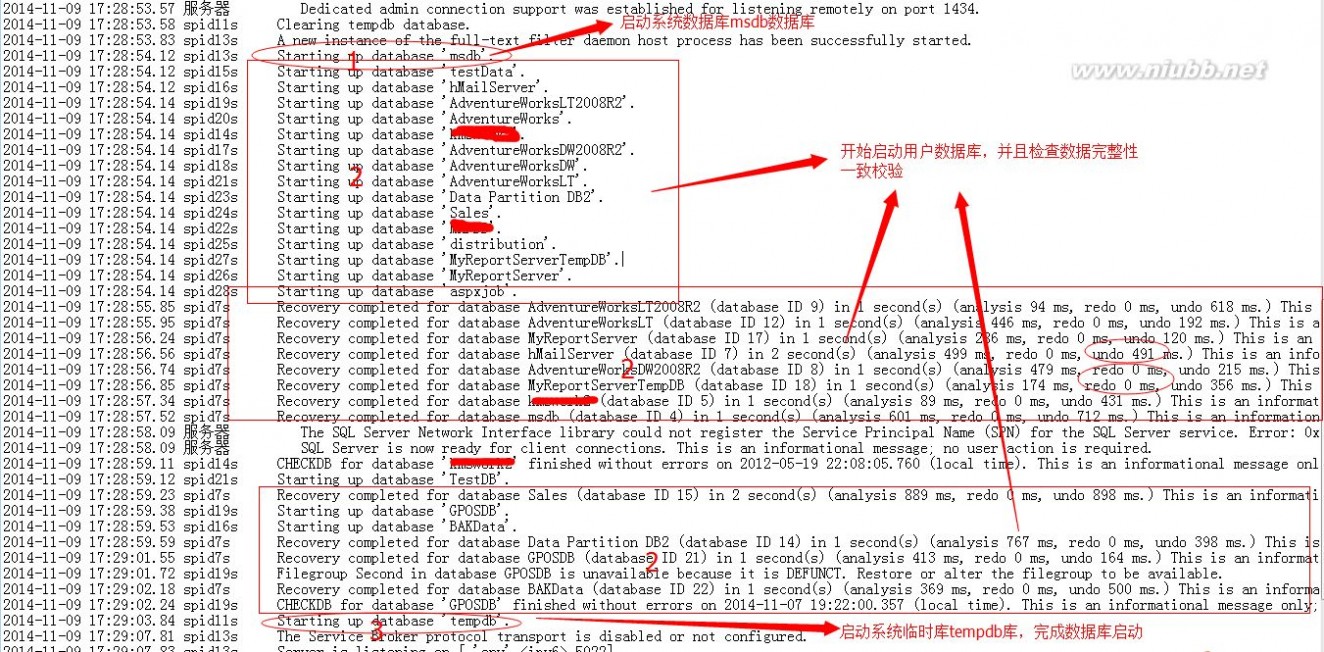
六、其实完成上面的第五步之后,也就开始启动msdb系统数据库
七、这时候开始真正的启动用户数据库,并且完整各个库的完整性校验,并且在启动用户数据库之前,先将系统库的tempdb进行清空
八、在搭建完成之后,才开始启系统的另外一个数据库tempdb
上面的整个SQL Server系统启动的过程产生了详细的日志记录,我们下面会依次按照该步骤进行详细的进行逐步分析。
在检查系统软硬件环境的过程中,基本不会发生什么致命错误。比较常见的问题就是内存配置问题,其实在上面的日志记录中有一句特别重要,它反映的就是SQL Server利用内存的情况,我们来看:

这句话的意思是将所有的数据页锁定到内存中,作为大部分数据库而言,内存就是生命线,SQL Server同样也是,如果系统(64bit中)没有内存压力的情况下,才能将数据页正常的锁定到内存中,如果内存压力过大,系统内存是不允许将数据页也加入到内存中,而这样导致的问题就是SQL Server严重的性能问题。
很多用户希望限制SQL Server内存使用,并且有些客户机将它限制到服务都不能启动的情况,这时候在SQL Server的日志中是这样展现的,我们来看:


可以看到,该错误的原因还是挺清楚的,修复该错误的解决方法也很简单,将内存配置调大就可以。
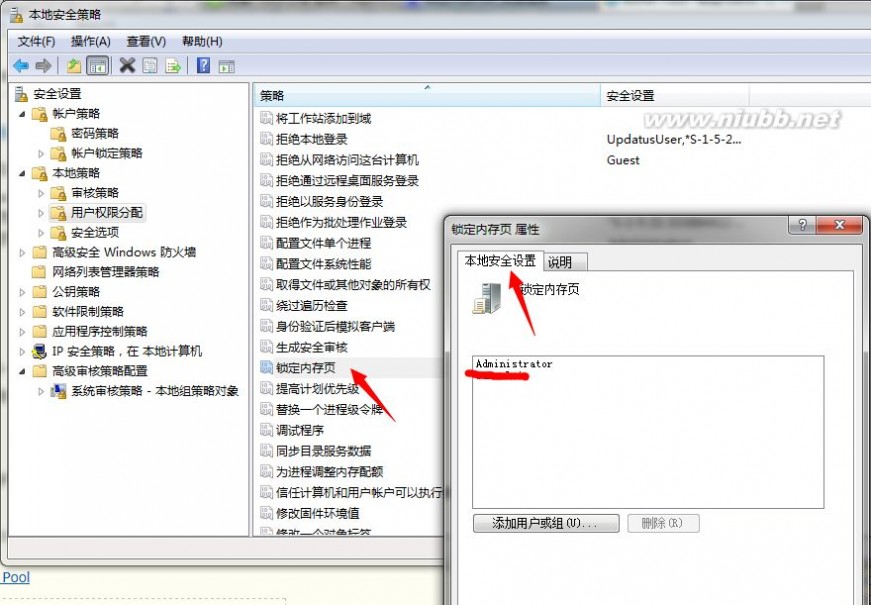
跟内存有关的还有一种特殊的情况,就是SQL Server的启动账号在服务器上没有Lock page in memory的权限,如果没有这个权限,在明细日志中查看不到上面的日志记录,该问题的解决方法也很简单,只需要将需要权限加上就可,加权限的方式如下:
经过上面的步骤基本,完成数据的软硬件检测过程。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第三步、启动系统数据库master
master数据库是SQL Server系统启动过程中的第一个系统库,是非常关键的数据库。如果这个库不能被正常打开,则SQL Server就不能正常启动。
和其它数据库一样,master数据库也分为数据文件和日志文件,启动的过程是依次打开,然后做恢复动作,如果这个过程没问题的话,在Errorlog日志文件中,我们会看到如下的这句话:

如果这个过程出现了任何问题,SQL Server的启动过程都会被中断,启动过程失败。
而这个过程发生的错误,无非就集中以下几种情况,我们来分析一下:
<1>在指定的路径找不到master数据的数据文件或日志文件
关于这个SQL Server的最主要的系统数据库的路径,它是以注册表形式存在的,在一下注册表项,可以看到
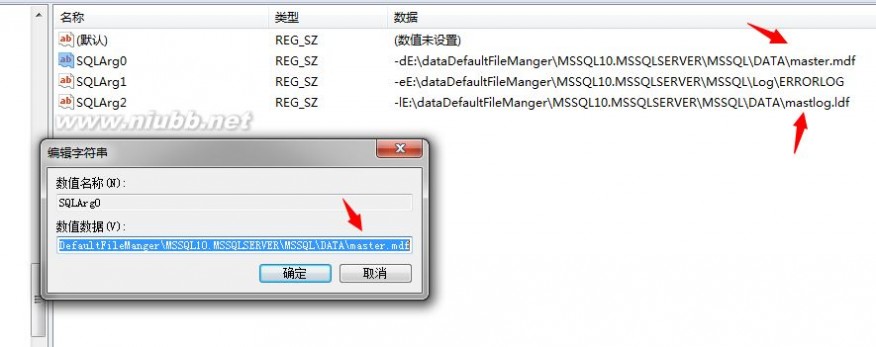
如果在该路径下找不到这个系统数据库的话,服务是启动不了的,并且会产生相应的错误日志信息,我们来模拟下,关掉服务,将这两个文件移除走,然后启动看一下:
首先,该服务是启动失败的
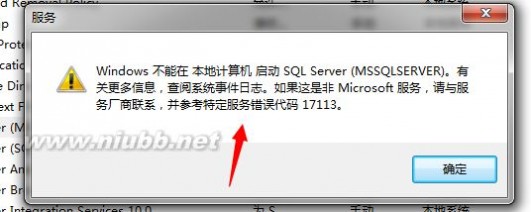
我们来看一下系统日志
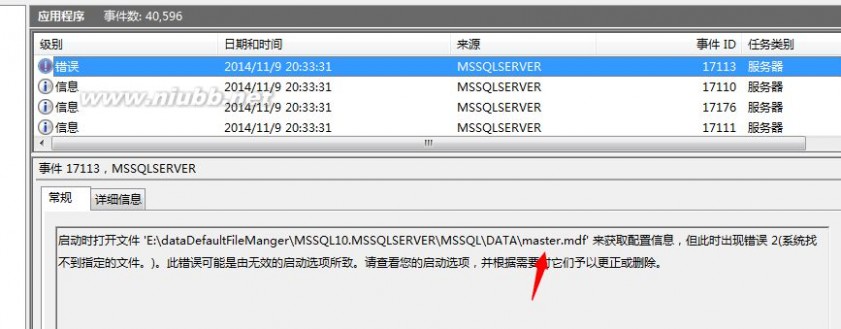
看Errorlog的日志信息

可以看到,该问题提示错误信息还是挺详细的。我们来看第二种情况
<2>文件找到了,但是没有权限访问,或者不能以排他的方式打开该文件(默认的是独占锁进行文件打开的)
此种情况也是有可能产生的,比如某些NB的杀毒软件就可以干这个事,让你的系统库无法访问,这样同样也是启动不了的,我们这样来看,提示的错误的信息有哪些:

来看Errorlog的错误记录:

<3>文件找到了,访问权限也有,但是文件有问题,就是说是数据库损坏了
这个问题也经常出现,比如磁盘坏掉了,恢复后发现文件有问题,不能正常打开,这种问题我们来看错误信息:

日志中的信息

关于master系统库的启动过程,基本就是上面的三种错误,关于这三种问题,我们该如何解决呢?
解决方法:首先如果根据错误日志定位出问题的性质,如果是前两种问题其实是挺好解决的,比如文件没找到、权限项不对等,这些问题相应的去解决就可以,最棘手的就是第三种情况,出现这种情况最理想的情况是master数据库进行了备份,通过备份文件进行恢复就可以,一切就可以正常,当然通过暴力的停掉服务,拷贝文件进去也可以解决。
最揪心的就是这个库就没备份,那该如何解决呢?这种方式的解决就得借助SQL Server的安装程序,进行重建master数据了,但是这种方式重建的master数据库会导致以前的SQL Server的设定全部清空掉。
清空的信息包括:所有的账户信息(意味着需要重建)、msdb中的所有job信息等(也需要重建)、用户数据库信息(必须全部重新附加attch上)
而这一系列过程如果是一个生产库,可能会是一个非常大的工作量!
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第四步、启动系统资源数据库,并检查数据版本信息
资源数据库是SQL Server2005中引入的逻辑数据库,在实例下是看不到的,但是有它的物理文件,主数据库默认名称为:mssqlsystemresource.mdf、日志名称为:mssqlsystemresource.ldf
如果该数据库启动的过程中也出现了问题,那SQL Server也不能正常启动。
这个系统数据库比较特别,它是一个只读数据库,完全由SQL Server自己维护,用户是不能更改的,所以我们只要保证它的是数据库文件和日志完好就可以,不需要对它进行任何的跟踪和维护。
当然如果非要看这个数据库,可以通过单用户的DAC方式进行连接。
所以这个数据库在一般情况下不会发生意外,基本上是能正常启动,不过特殊情况下,不能启动的情况就以下两种:
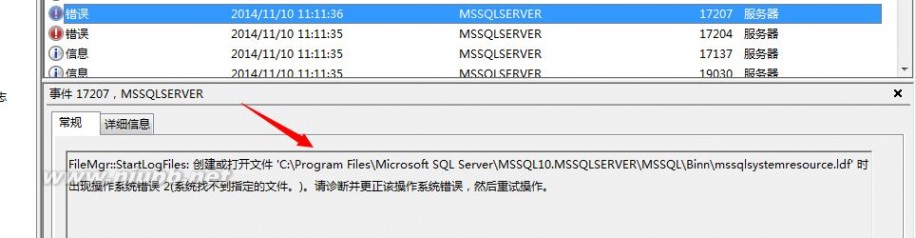
<1>数据库文件不存在,无法访问,或者文件坏掉了
其实它的报的错误信息,类似于上面的master数据库,我来截个图,看一下:
这个是errorlog记录的错误信息

在windows层面也有它自己的错误日志信息:
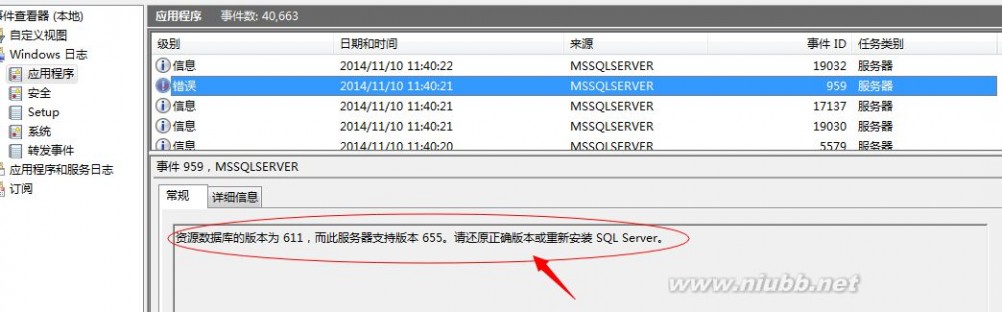
<2>资源数据库的版本和SQL Server的版本不一致
这个有可能是人为的更改了这个资源数据库,导致现有的资源数据库文件和数据库版本不一致,这样的话也会导致错误的形成

windwos平台也记录下了该错误的信息,看下面的图片:
解决方法:
关于资源库的这两个问题解决方法,非常的简单。只要找到和这台服务器上的SQL Server的版本一致的数据库,拷贝过来就行。
当然最好的预防措施是:每当安装完SQL Server或者打完补丁之后,就及时的备份这个两个文件,放在安全的地方,用的时候拷贝过来就行,备份是数据库管理员的天职
当然有时候在紧急的情况下,找不到相同版本的数据库,理论上这个库是只读的,所以不会发生任何改变,我们随便找一台机器,安装一下同版本数据库,然后拷贝过来就行,当然一定注意的是这里面是相同版本。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第五步、启动系统数据库model
model系统数据库同样也是SQL Server启动过程中用到的一个非常关键的数据库,如果这个库损坏,SQL Server启动也会失败,关于model数据不能启动的原因基本和master的类似,同样也是两种:1、数据库文件早不到或者不能访问;2、数据库文件能访问但是是损坏的文件。
诊断此种问题的方式也和上面的两种方式一样,查看启动过程产生的errorlog文件或者windows系统日志,这里我们就不重现该问题了。
我们只给出此种问题的解决方法:
1、如果该库我们已经做过备份,那最直接也是最有效的解决方式就是直接还原,这里的还原方式可能和普通库的还原方式不一样,因为SQL Server实例还没有启动,我们恢复过程采取以下过程:
a.用参数启动SQL Server,在命令提示行中执行以下命令,这样的话SQL Server启动就会跳过model数据库恢复这一步
net start MSSQLSERVER /f /m /T3608
b.现在恢复model数据库,打开SSMS,直接输入
RESTORE DATABASE model FROM DISK ='G:\data\model.bak' WITH MOVE 'modeldev' TO 'E:\dataDefaultFileManger\MSSQL10.MSSQLSERVER\MSSQL\DATA\model.mdf' MOVE 'modellog' TO 'E:\dataDefaultFileManger\MSSQL10.MSSQLSERVER\MSSQL\DATA\model.ldf' ,replace
c.恢复成功后,直接重启SQL Server既可以。
2、将SQL Server关闭,然后直接采取暴力的方式将model数据文件拷贝回来就可以,这种方式简单有效,但是非常规操作
3、还有一种方式是利用setup安装文件,重建该数据库,过程缓慢,稍显复杂,很不推荐。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第六步、开始网络配置进行连接,对外提供服务,使用的默认的1433端口
当上面的几个重要的系统库都已经启动完成之后,下一步就是开始检查网络环境,进行网络服务的配置,对外进行提供服务了,一般来讲,在SQL Server中利用的网络启动协议有三种:Shared Memory、Named Pope和TCP/IP,其实在日常我们最常用的就是TCP/IP这种方式了,并且默认开启的是1433端口。
我们来看一下正常启动过程中,该部分的详细日志:

这里面的Shared Memory是专供本地连接通过LPC(Local Procedure Call)技术向SQL Server做的连接。它不走网络层,所以他是速度最快的连接方式。正常启动后会显示上面的正常日志。
Named Pipe方式正常启动,也会显示出上面的日志。可以看到。
这其中我们最常用的TCP/IP这种方式,也正常的启动了,并且指定了两种访问方式,ipv4/ipv6,然后后面加上了1433端口号。
在这个过程中最常出现的问题就是,1433端口被其它程序占用,这样就导致TCP/IP协议无法正常启动,这样我们会看到如下日志信息

并且在windows 系统日志中也会有记录

解决方法:
其实这里出现的问题还是挺好解决的,只需要找到占用这个端口的应用程序,采取措施让它把这个端口给让出来就可以。
当然出现这些问题就意味着客户端已经无法通过TCP/IP这种远程连接的方式进行连接访问了。
这时候一般管理员可以采用SQL Server给其提供的“专用管理员连接”(DAC)进行连接,这种方式我们以后再介绍。
当然,在SQL Server启动的过程中,一般出现这种网络问题,或者协议不能成功加载,SQL Server会报出错误信息,但是一般情况下是不会影响SQL Server的正常启动的。受影响的可能只是出问题的那种协议功能。
我们只需要根据日志,定位问题,然后解决掉,重新启动就可以了。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第七步、开始启动msdb系统数据库
关于msdb这个系统数据库,它是被安排在系统库中接近最后一个了,除了用户数据库和临时库tempdb之外,当启动过程中已经进行到这一步的时候,其实我们的实例就已经启动起来了,并且能够连接。
我们知道msdb这个库中主要的存储的信息是应用各个库的备份信息,各种job的历史跑批信息等,其实诸多的都是来自于用户数据库所产生的一些客观数据。
我们来看一下这个库出现了问题会产生什么现象:
我将这个库文件移除走,然后重新启动服务,启动过程中没有报任何错误,并且能够顺利启动,我们用SSMS直接连接过去,也可以正常连接

但是当我们点击开数据的时候,其实是看不到任何用户数据库的,并且会产生一个错误提示:
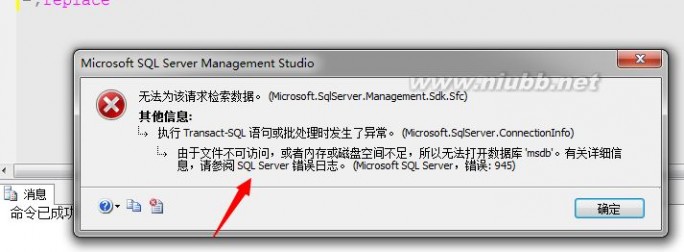
看来是不能使用的,我们来查看一下错误日志:

虽然这个库的重要性比起master之类的库重要性要稍显差一些,但是缺少了它我们的SQL Server虽然能启动,但是依然不能使用。
解决方法:
要解决这个问题其实方式就很多种了,因为到此我们的SQL Server实例已经能够正常启动了,我们可以采取:
1、利用备份还原该库,参考文章前面的方式(推荐)
2、关掉服务,利用暴力的拷贝文件的方式进行恢复,简单有效,非常规操作
3、找台相同的环境,找到相同的文件,直接拷贝过来使用
4、利用安装文件进行恢复(不推荐)
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
第八步、启动用户数据库,并且完整各个库的完整性校验,并且在启动用户数据库之前,先将系统库的tempdb进行清空
本步骤所遇到的问题层出不穷,各种样式,我打算再重新组织一篇文章,专门列举,此篇就不介绍了。
但有一点需要记住:在这一步之前SQL Server会将tempdb这个系统库清空掉,也就是说,每次的重启操作,系统都会将tempdb清空,然后重建,这一步一般不会发生异常,成功之后会出现以下日志信息:

第九步、开始重建系统的另外一个数据库tempdb
tempdb这个库比较特殊,每次重启的时候都是重新创建的,SQL Server会根据master数据库里的记录的信息以model数据库为版本进行创建。所以只要我们保证model数据库没有问题,然后硬盘没有问题,tempdb的数据库文件就应该没有问题。
关于temdb这个库的所有配置信息是存储于master的数据库中的,里面的内容信息是存储于model系统库中的
这样就带来了一个问题,有时候我们的master的库是从别的机器下面备份下来的,所以它里面会记录这个tempdb这个库在原来机器上的路径,这样在启动创建的时候就会报错。
所以我们需要执行以下命令更改这个库路径
a、用参数启动SQL Server
net start MSSQLSERVER /f /m /T3608
b.修改数据文件和日志文件路径
ALTER DATABASE tempdb MODIFY FILE(NAME=tempdev,FILENAME='C:\right path....\temdb.mdf'); go ALTER DATABASE tempdb MODIFY FILE(NAME=tempdev,FILENAME='C:\right path....\temdblog.ldf'); go
c.正常启动数据库既可以
还有一种情况,就是创建该文件的时候,提供的硬盘空间不足,或者权限不够,我们也是根据上面的方式,修改到一个正确的路径,并且确保权限正确。
也可以更改temp文件的大小,默认是4M,代码如下:
ALTER DATABASE tempdb MODIFY FILE(NAME=tempdev,SIZE=100MB); go ALTER DATABASE tempdb MODIFY FILE(NAME=tempdev,SIZE=100MB); go
至此,如果上面的整个过程都没出问题的话,一个正常的SQL Server就可以启动成功的。
结语
本篇文章到此结束了.....此篇耗时三天.....为了尽可能的呈现出所有的问题现象,我对本地的SQL Server进行了多种无情的蹂躏、各种的摧残,力求能够重显各种不同的应用场景问题现象,然后尽可能的找到合适的解决方案,当然还有很多的情况没有展现出来,后续遇到,会一一补充进来,当然有遇到不能解决的,也可以留言,我们一起分析解决。
关于用户数据库启动过程,这个过程是一个问题较易发生的步骤,神马质疑、恢复中、不可用等等现象,我后续的文章中列举分析。
已经补充出该篇的关联篇:
你所不知道的SQL Server数据库启动过程(用户数据库加载过程的疑难杂症)
如果您看了本篇博客,觉得对您有所收获,请不要吝啬您的“推荐”。
本文标题:sql server数据库-SQL Server 2008:开辟崭新数据平台61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1