一 : 微软已宣布首次公开预览Linux版本SQL Server
0易信微信QQ空间微博更多今年早些时候,微软宣布将推出Linux版SQL Server 2016。昨天,微软正式加入了Linux基金会。作为白金会员,现在该公司正在寻求进一步加强与社区的关系。为此,它已经宣布在Linux上首次公开预览SQL Server。这个预览版本也已在Windows上发布,它带来性能改进和工具更新。
随着SQL Server的发布,开发人员现在可以在Linux,Windows,Docker或Mac上构建应用程序,并将其部署到本地或云中。用户现在也更容易安装和使用SQL Server。用户可以在Red Hat Enterprise Linux和Ubuntu Linux本机系统上安装Linux版本SQL Server 2016。微软也将推出适用于SUSE Linux Enterprise Server的软件包。
微软还承诺大幅度提升Linux版本SQL Server性能。微软表示,内存中OLTP读取速度最大提升100倍,写入速度最大提升30倍。SQL Server还拥有用于事务处理的多个顶级TPC-E性能和用于数据仓库的顶级TPC-H性能,以及具有适用于领先业务应用程序的顶级性能。
微软最近还展示了每秒运行超过100万次R预测的SQL Server。除此之外,SQL Server还提供了令人难以置信的效率。在Linux工具方面,微软发布了一些SQL Server工具的更新版本以及针对Visual Studio代码的新SQL Server扩展。开发人员可以使用Azure SQL数据库和Azure SQL DW。该公司还在Linux上为SQL Server提供了本地命令行工具。
在今年3月份,微软宣布超过8000家公司已经在第一周内注册尝试Linux版SQL Server,其中包括超过50%的财富500强公司。

二 : SQL Server 2000企业版教程
SQL Server 2000企业版教程
一、硬件和操作系统要求
下表说明安装 Microsoft SQL Server 2000 或 SQL Server 客户端管理工具和库的硬件要求。

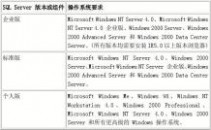
注:SQL Server 2000 的某些功能要求在Microsoft Windows 2000 Server以上的版本才能运行。因此大家安装Windows Server 2000,可以学习和使用到SQL Server 2000的更多功能,以及享受更好的性能
二、详细的安装过程
本文将在Windows 2000 Advanced Server操作系统作为示例,详细介绍安装SQL Server 2000企业版的过程。
将企业版安装光盘插入光驱后,出现以下提示框。请选择 "安装 SQL Server 2000 组件",出现下一个页面后,选择 "安装数据库服务器" 。

图

1
图2
选择 "下一步",然后选择 "本地计算机" 进行安装。
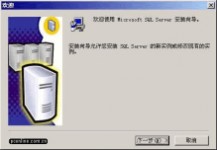
图3
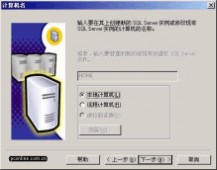
图4
在 "安装选择" 窗口,选择 "创建新的SQL Server实例..."。对于初次安装的用户,应选用这一安装模式,不需要使用 "高级选项" 进行安装。 "高级选项" 中的内容均可在安装完成后进行调整。
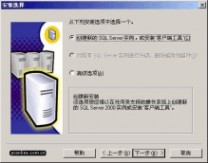
图5
在 "用户信息" 窗口,输入用户信息,并接受软件许可证协议。
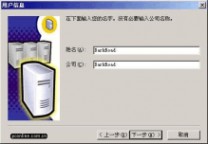
图6
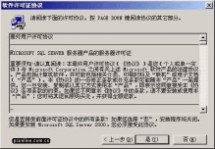
图7
在 "安装定义"窗口,选择 "服务器和客户端工具" 选项进行安装。我们需要将服务器和客户端同时安装,这样在同一台机器上,我们可以完成相关的所有操作,对于我们学习SQL Server很有用处。如果你已经在其它机器上安装了SQL Server,则可以只安装客户端工具,用于对其它机器上SQL Server的存取。
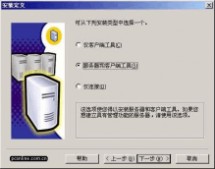
图8
在 "实例名" 窗口,选择 "默认" 的实例名称。这时本SQL Server的名称将和Windows 2000服务器的名称相同。例如笔者的Windows服务器名称是 "Darkroad",则SQL Server的名字也是 "Darkroad"。SQL Server 2000可以在同一台服务器上安装多个实例,也就是你可以重复安装几次。这时您就需要选择不同的实例名称了。建议将实例名限制在 10 个字符之内。实例名会出现在各种 SQL Server 和系统工具的用户界面中,因此,名称越短越容易读取。另外,实例名称不能是 "Default" 或 "MSSQLServer" 以及SQL Server的保留关键字等。
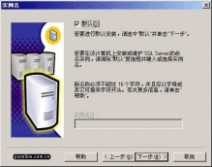
图9
在 "安装类型" 窗口,选择 "典型" 安装选项,并指定 "目的文件夹"。程序和数据文件的默认安装位置都是 "C:\Program Files\Microsoft SQL Server\"。笔者因为C盘是系统区、D盘是应用区,因此选择了D盘。注意,如果您的数据库数据有10万条以上的话,请预留至少1G的存储空间,以应付需求庞大的日志空间和索引空间。
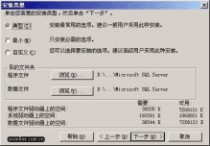
图10
在 "服务账号" 窗口,请选择 "对每个服务使用统一账户..." 的选项。在 "服务设置" 处,选择 "使用本地系统账户"。如果需要 "使用域用户账户" 的话,请将该用户添加至Windows Server的本机管理员组中。
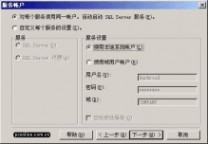
图11
在 "身份验证模式" 窗口,请选择 "混合模式..." 选项,并设置管理员"sa"账号的密码。如果您的目的只是为了学习的话,可以将该密码设置为空,以方便登录。如果是真正的应用系统,则千万需要设置和保管好该密码!如果需要更高的安全性,则可以选择 "Windows身份验证模式" ,windows Server的本地用户和域用户才能使用SQL Server了。
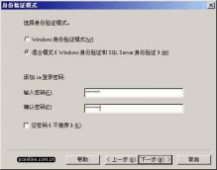
图12
在 "选择许可模式" 窗口,根据您购买的类型和数量输入(0表示没有数量限制)。 "每客户"表示同一时间最多允许的连接数,"处理器许可证"表示该服务器最多能安装多少个CPU。笔者这里选择了 "每客户" 并输入了100作为示例。
图13
然后就是约10分钟左右的安装时间,安装完毕后,出现该界面,并新增了以下的菜单。!

图14
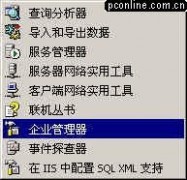
图15
三、SQL SERVER的存储形式
1、物理存储形式:
物理上,一个数据库有一个或多个磁盘上的一个或多个文件组成。这种物理实现只对数据库管理人员是可见的,而对于用户是透明的。
每个数据库在物理上又分为数据和日志文件,这些数据和日志文件存放一个或多个磁盘上。这些文件不与其它文件共享。
1) 数据文件:
SQL Server将一个数据文件中的空间分配给表格和索引,每块有64kb空间,叫做“扩展盘区”。有两种类型的扩展盘区:统一扩展盘区和混合扩展盘区。
每个扩展盘区由页面组成。页面是SQL Server中数据存储的基本单元,每个页面的大小为8kb。通常情况下,每个数据页面上以行的形式存储数据。一行的数据最多达8060字节。数据行上如若有群集索引,则基于群集索引的关键字(如邮政编码等)为顺序组织数据,否则没有特定的顺序。
2) 事务处理日志文件:
事务处理日志文件驻留在与数据文件不同的一个或多个物理文件中,包含一系列日志记录而不是扩展盘区分配的页面。
2、逻辑存储形式:
逻辑上,一个数据库有若干个用户可见的组件组成,如:表格、视图、存储过程等。


四、主要SQL语句介绍
1、概要介绍
SELECT --从数据库表中检索数据行和列
INSERT --向数据库表添加新数据行
DELETE --从数据库表中删除数据行
UPDATE --更新数据库表中的数据
CREATE TABLE --创建一个数据库表
DROP TABLE --从数据库中删除表
ALTER TABLE --修改数据库表结构
CREATE VIEW --创建一个视图
DROP VIEW --从数据库中删除视图
CREATE INDEX --为数据库表创建一个索引
DROP INDEX --从数据库中删除索引
CREATE PROCEDURE --创建一个存储过程
DROP PROCEDURE --从数据库中删除存储过程
CREATE TRIGGER --创建一个触发器
DROP TRIGGER --从数据库中删除触发器
CREATE SCHEMA --向数据库添加一个新模式
DROP SCHEMA --从数据库中删除一个模式
CREATE DOMAIN --创建一个数据值域
ALTER DOMAIN --改变域定义
DROP DOMAIN --从数据库中删除一个域
GRANT --授予用户访问权限
DENY --拒绝用户访问
REVOKE --解除用户访问权限
COMMIT --结束当前事务
ROLLBACK --中止当前事务
SET TRANSACTION --定义当前事务数据访问特征
DECLARE --为查询设定游标
EXPLAN --为查询描述数据访问计划
OPEN --检索查询结果打开一个游标
FETCH --检索一行查询结果
CLOSE --关闭游标
PREPARE --为动态执行准备SQL 语句
EXECUTE --动态地执行SQL 语句
DESCRIBE --描述准备好的查询
2、详细介绍
1. 创建数据库
CREATE DATABASE database_name [WITH LOG IN “pathname”]
database_name:数据库名称。
“pathname”:事务处理日志文件。
创建一database_name.dbs目录,存取权限由GRANT设定,无日志文件就不能使用
2. 等事务语句
BEGIN WORK(可用START DATABASE语句来改变)。
可选定当前数据库的日志文件。
如:select dirpath form systables where tabtype = “L”;
例:create databse customerdb with log in “/usr/john/log/customer.log”;
3. 选择数据库
DATABASE databse-name [EXCLUSIVE]
database_name:数据库名称。
4. 独占状态
EXCLUSIVE:
存取当前目录和DBPATH中指定的目录下的数据库,事务中处理过程中不要使用此语句。 例:dtabase customerdb;
5. 关闭当前数据库
CLOSE DATABASE
database_name:数据库名称。
此语句之后,只有下列语句合法:
CREATE DATABASE; DATABASE; DROP DATABSE; ROLLFORWARD DATABASE;
删除数据库前必须使用此语句。
例:close database;
? DROP DATABASE database_name
删除指定数据库。
database_name:数据库名称。
用户是DBA或所有表的拥有者;删除所有文件,但不包括数据库目录;不允许删除当前数据库(须先关闭当前数据库);事务中处理过程中不能使用此语句,通过ROLLBACK WORK 也不可将数据库恢复。
例:drop databse customerdb;
? CREATE [TEMP] TABLE table-name (column_name datatype [NOT NULL], …)
[IN “pathname”]
创建表或临时表。
table-name :表名称。
column_name:字段名称。
data-type:字段数据类型。
path-name:指定表的存放位置
TEMP用于指定建立临时表;表名要唯一,字段要唯一;有CONNECT权限的用户可建立临时表;创建的表缺省允许CONNECT用户存取,但不可以ALTER。
例:create table user
( c0 serial not null, c1 char (10),
c2 char(2),
c3 smallint,
c4 decimal(6,3),
c5 date
) in “usr/john/customer.dbs/user;
? ALTER TABLE
6. 修改表结构
ALTER TABLE table-name
{ADD (newcol_name newcol_type [BEFORE oldcol_name], …) | DROP (oldcol_name, …) | MODIFY (oldcol_name newcol_type [NOT NULL], … )}, …
table-name:表名称。
newcol_name:新字段名称
newcol_type:新字段类型
oldcol_name:老字段名称
可以使用单个或多个ADD子句、DROP子句、MODIFY子句,但某个字句失败,操作即中止;原字段是NULL,不允许MODIFY为NOT NULL,除非所有NULL字段中均非空,反之可以;ALTER使用者是表的拥有者或拥有DBA权限,或被授权;事务中处理过程中不要使用此语句。
例:alter table user
add ( c6 char(20) before c5);
7. 修改表名
RENAME TABLE oldname TO newname
oldname:原名称。
newname:新名称。
RENAME使用者是表的拥有者或拥有DBA权限,或被授权;事务中处理过程中不要使用此语句。
例:rename user to bbb;
? DROP TABLE table-name
删除表。
table-name:表名称。
删除表意味着删除其中所有数据、各字段上的索引及对表的赋权、视图等;用户不能删除任何系统目录表;语句使用者是表拥有者或拥有DBA权限,事务中处理过程中不要使用此语句。
8.修改字段名
RENAME COLUMN table.oldcolumn, TO newcolumn
table.oldcolumn:表名及原字段名称
newcolumn:新字段名称。
语句使用者是表的拥有者或拥有DBA权限或有ALTER权限的用户,事务中处理过程中不要使用此语句。
例:rename column user.c6 to c7;
9.创建视图
CREATE VIEW view-name column-list
CREATE VIEW view-name column-list AS select_statement [WITH CHECK OPTION] view-name:视图名称。
column-list:字段列表。
select_statement:SELECT语句。
以下语句不使用视图:ALTER TABLE,DROP INDEX,ALTER INDEX,LOCK TABLE,CREATE INDEX, RENAME TABLE;视图将延用基表的字段名,对表达式等虚字段和多表间字段重名必须指明标识其字段名;若对视图中某些字段命名,则所有字段都必须命名;视图中数据类型延用基表中的数据类型,虚字段起诀于表达式;不能使用ORDER BY和UNION子句;对视图中所有的字段要有SELECT权限;事务中处理过程中使用此语句,即使事务回滚,视图也将建立,不能恢复。
例:create view v_user as select * from user where c1 = “B1”;
10. 删除视图
DROP VIEW view-name
view-name:视图名称。
用户可删除自己建立的视图;视图的后代视图也被删除;事务中处理中不要使用此语句。 例:drop view v_user;
11. 创建索引
CREATE INDEX
CREATE [UNIQUE/DISTINCT] [CLUSTER] INDEX index_name ON table_name
([column_name ASC/DESC],…)
index_name:索引名称。
table_name:表名称。
column_name:字段名称。
UNIQUE/DISTINCT:唯一索引。
CLUSTER:使表的物理存放顺序按索引排列。
ASC/DESC:升序或降序,缺省升序。
语句执行时,将表的状态置为EXCLUSIVE;复合索引最多包含8个字段,所有字段长度和不得大于120字节;事务中处理过程中使用此语句,即使事务回滚,索引将建立,不能恢复。
例:create cluster index ix_user on user(c5);
? ALTER INDEX index-name TO [NOT] CLUSTER
修改索引性质。
index-name:索引名称。
TO [NOT] CLUSTER:去掉或加上CLUSTER属性。
语句执行时,将表的状态置为EXCLUSIVE;事务中处理过程中使用此语句,即使事务回滚,索引性质将改变,不能恢复。
例:alter index ix_user to not cluster;
12. 删除索引
DROP INDEX index-name
index-name:索引名称。
语句使用者是索引的拥有者或拥有DBA权限,事务中处理过程中不要使用此语句,否则事务无法恢复。
例:drop index ix_user;
13. 创建同义名
CREATE SYNONYM synonym FOR table-name
synonym:同义名
table-name:表名称
数据库的创建者可以使用同义名;没有赋予同义名权限的用户不能使用同义名;同义名不能和表名相同;事务中处理过程中不要使用此语句。
例:create synonym user_alias for user;
14. 删除同义名
DROP SYNONYM synonym
synonym:同义名
可以删除自己建立的同义名;事务中处理过程中不要使用此语句,否则无法恢复。 例:drop synonym user_alias;
15. 更新数据库的统计数字
UPDATE STATISTICS [FOR TABLE table-name]
table-name:表名称
此语句仅作用于当前数据库;可提高查询效率;只有执行此语句,才改变统计数据。 例:update statistics for table user;
16. 授权命令
GRANT {DBA|RESOURCE|CONNECT} TO {PUBLIC|user-list}
PUBLIC|user-list:全部或指定的用户。
三种权限居且仅居其一,事务处理过程中不要执行GRANT语句。
例:grant resource to pulbic;
GRANT tab-privilege ON table-name TO {PUBLIC|user-list} [WITH GRANT OPTION] 授表级权限。
tab-privilege:表级权限。
table-name:表名称。
PUBLIC|user-list:全部或指定的用户。
[WITH GRANT OPTION]:表示被授权用户有否权限进行二次授权。
用户可以在自己建立表达式或被[WITH GRANT OPTION]准许的表中进行赋权;限定越多的权限优先级越高。
例:grant update(c1,c6) on user to dick with grant option;
附(INFORMIX的权限)
(1) 数据库的权限(控制对数据库的访问以及数据库中表的创建和删除)
DBA权限:全部权利,修改系统表,建立和删除表与索引、增加和恢复表数据,以及授予其他用户数据库权限等;
RESOURCE权限:允许对数据库表中的数据进行存取,建立永久性表以及索引。 CONNECT权限:只允许对数据库表中的数据进行存取,建立和删除视图与临时表。
(2)表级权限(对表的建立、修改、检索和更新等权限)
ALTER:更改权限
DELETE:删除权限
INDEX:索引权限
INSERT:插入权限
SELECT [(cols)]:指定字段或所有字段上的查询权限,不指明字段缺省为所有字段。 UPDATE [(cols)] :指定字段或所有字段上的更新权限,不指明字段缺省为所有字段。 ALL [PRIVILEGES]:以上所有表级权限
REVOKE {DBA|RESOURCE|CONNECT} FROM {PUBLIC|user-list}
收权命令。
PUBLIC|user-list:全部或指定的用户。
三种权限居且仅居其一,事务处理过程中不要执行GRANT语句。
例:revoke resource from john;
REVOKE tab-privilege ON table-name FROM {PUBLIC|user-list}
收表级权限。
tab-privilege:表级权限。
table-name:表名称。
PUBLIC|user-list:全部或指定的用户。
[WITH GRANT OPTION]:表示被授权用户有否权限进行二次授权。
用户只能取消由其本人赋予其他用户的表级存取权限;不能取消自己的权限,对SELECT和UPDATE作取消时,将取消所有表中字段的SELECT 和UPDATE权限。
例;revoke update on user from dick;
17. 记录级加锁和表级加锁或文件加锁
LOCK TABLE table-name IN {SHARE|EXCLUSIVE} MODE
table-name:表名称。
SHARE:允许读表中数据,但不允许作任何修改
EXCLUSIVE:禁止其他任何形式访问表
每次只能对表琐定一次;事务处理过程中,BEGIN WORK后立即执行LOCK TABLE以取代记录级加锁,COMMIT WORK和ROLLBACK WORK语句取消所有对表的加锁;若没有事务处理,锁将保持到用户退出或执行UNLOCK为止。
例:lock table user in exclusive mode;
18. 取消记录级加锁和表级加锁或文件加锁
UNLOCK TABLE table-name
table-name:表名称。
例:unlock user;
19. 改变锁定状态
SET LOCK MODE TO [NOT] WAIT
TO [NOT]:等待解锁,有可能被死锁或不等待并提示错误信息,表示此记录被锁,缺省值。 访问一个EXCLUSIVE状态下的记录,将返回一个错误。
20. 启动事务处理
START DATABSE db_name [WITH LOG IN “pathname”]
“pathname”:事务处理日志文件。
执行该语句前,需要先关闭当前数据库。
例;clost database;
start databse customer with log in “/usr/john/log/customer.log”;
21. 开始事务
BEGIN WORK
例:begin work;
? COMMIT WORK
提交(正常结束)事务。例:commit work;
22.回滚(非正常结束)事务
ROLLBACK WORK
例:rollback work;
23.查询语句
SELECT select_list FROM tab_name|view_name
WHERE condition
GROUP BY column_name
HAVING condition
ORDER BY column_list
INTO TEMP table_name
select_list:选择表或*
tab_name:表名称
view_name:视图名称。
condition:查询条件,可使用BETWEEN、IN、LIKE、IS NULL、LIKE、MATCHES、NOT、 AND、OR、=、!=或<>、>、 >= 、<=、<、ALL、ANY、SOME
column_name:分组字段名称
condition:群聚条件
column_list:排序字段列表,缺省ASC,可指定DSC;排序时,NULL值小于非零值。 table_name:临时表名称
例:略
附(常用函数)
(1)集合函数:
count(*)、
sum(数据项/表达式)、avg(数据项/表达式)、max(数据项/表达式)、min(数据项/表达式) count(distinct 数据项/表达式)、sum(distinct数据项/表达式)、avg(distinct数据项/表达式)
(2)代数函数和三角函数
HEX(数据项/表达式)、ROUND(数据项/表达式)、TRUNC(数据项/表达式)、
TAN(数据项/表达式)、ABS(数据项/表达式)、MOD(被除数,除数)
(3)统计函数
标准差,stdev()、方差,variance()、范围,rang()
(4)时间函数
DAY(日期/时间表达式):返回数字型
MONTH(日期/时间表达式):返回整数
WEEKDAY(日期/时间表达式):0��6,0星期天,1星期一;返回整数
YEAR(日期/时间表达式)、返回整数
DATE(非日期表达式):返回日期型
EXTEND(日期/时间表达式,[第一个至最后一个]):返回指定的整数
MDY(月,日,年):返回日期型
CURRENT:返回日期型
(5)时间函数
ROUND(),四舍五入。如:ROUND(10.95,position)position进行四舍五入的前一位置 TRUNC(),截取。如:TRUNC(10.95,0)position截取的位置
INFORMIX临时表在下列情况下自动取消:
A.退出数据库访问工具(如DBACCESS)
B.SQL通话结束(DISCONNECT)
C.发出取消表语句
D.退出程序时
24.插入数据
INSERT INTO view_name|table_name [(column_list)] VALUES (value_list)
或 INSERT INTO view_name|table_name [(column_list)] select_statement
view_name|table_name:视图名或表名称
column_list:数据项列表。
value_list:值列表
select_statement:查询语句。
例:略
25. 删除语句
DELETE FROM view_name|table_name WHERE search-conditions
view_name|table_name:视图名或表名称
search-conditions;删除条件
例:略
26.更新数据语句
UPDATE view_name|table_name SET column_1 = value_1ist WHERE search_conditions
或UPDATE view_name|table_name SET column_1|* = value_1ist WHERE search_conditions view_name|table_name:表名称或视图表名称
value_1ist:字段值
search_conditions:更新数据的条件
例:略
27.检查索引语句
CHECK TABLE table-name
语句使用者是表的拥有者或拥有DBA权限;不能对systable使用此语句。
例:略
28.修复索引
REPAIR TABLE table-name
语句使用者是表的拥有者或拥有DBA权限;不能对systable使用此语句。
例:略
29.将文本数据栽入表中
LOAD FROM “file-name” INSERT INTO table_name [(column_name[,?])]
例:load form “aa.txt” insert into user;
30.将表中数据卸为文本
UNLOAD TO “pathname”
例:unload to “aa.txt” select * from user;
31.系统信息查询。
INFO TABLES:得到当前数据库上表的名字。
INFO columns FOR table_name:指定表上的字段信息。
INFO INDEXES FOR table_name:指定表上的索引信息。
INFO [ACCESS|PRIVILEGES] FOR table_name:指定表上的存取权限。
INFO STATUS FOR table_name:指定表的状态信息。
例: info tables;
五、常用数据库维护
1、备份数据库
1、打开SQL企业管理器,在控制台根目录中依次点开Microsoft SQL Server
2、SQL Server组-->双击打开你的服务器-->双击打开数据库目录
3、选择你的数据库名称(如论坛数据库Forum)-->然后点上面菜单中的工具-->选择备份数据库
4、备份选项选择完全备份,目的中的备份到如果原来有路径和名称则选中名称点删除,然后点添加,如果原来没有路径和名称则直接选择添加,接着指定路径和文件名,指定后点确定返回备份窗口,接着点确定进行备份
2、还原数据库
1、打开SQL企业管理器,在控制台根目录中依次点开Microsoft SQL Server
2、SQL Server组-->双击打开你的服务器-->点图标栏的新建数据库图标,新建数据库的名字自行取
3、点击新建好的数据库名称(如论坛数据库Forum)-->然后点上面菜单中的工具-->选择恢复数据库
4、在弹出来的窗口中的还原选项中选择从设备-->点选择设备-->点添加-->然后选择你的备份文件名-->添加后点确定返回,这时候设备栏应该出现您刚才选择的数据库备份文件名,备份号默认为1(如果您对同一个文件做过多次备份,可以点击备份号旁边的查看内容,在复选框中选择最新的一次备份后点确定)-->然后点击上方常规旁边的选项按钮
5、在出现的窗口中选择在现有数据库上强制还原,以及在恢复完成状态中选择使数据库可以继续运行但无法还原其它事务日志的选项。在窗口的中间部位的将数据库文件还原为这里要按照你SQL的安装进行设置(也可以指定自己的目录),逻辑文件名不需要改动,移至物理文件名要根据你所恢复的机器情况做改动,如您的SQL数据库装在D:\Program Files\Microsoft SQL Server\MSSQL\Data,那么就按照您恢复机器的目录进行相关改动改动,并且最后的文件名最好改成您当前的数据库名(如原来是bbs_data.mdf,现在的数据库是forum,就改成forum_data.mdf),日志和数据文件都要按照这样的方式做相关的改动(日志的文件名是*_log.ldf结尾的),这里的恢复目录您可以自由设置,前提是该目录必须存在(如您可以指定d:\sqldata\bbs_data.mdf或者d:\sqldata\bbs_log.ldf),否则恢复将报错
6、修改完成后,点击下面的确定进行恢复,这时会出现一个进度条,提示恢复的进度,恢复完成后系统会自动提示成功,如中间提示报错,请记录下相关的错误内容并询问对SQL操作比较熟悉的人员,一般的错误无非是目录错误或者文件名重复或者文件名错误或者空间不够或者数据库正在使用中的错误,数据库正在使用的错误您可以尝试关闭所有关于SQL窗口然后重新打开进行恢复操作,如果还提示正在使用的错误可以将SQL服务停止然后重起看看,至于上述其它的错误一般都能按照错误内容做相应改动后即可恢复
3、收缩数据库
一般情况下,SQL数据库的收缩并不能很大程度上减小数据库大小,其主要作用是收缩日志大小,应当定期进行此操作以免数据库日志过大
1、设置数据库模式为简单模式:打开SQL企业管理器,在控制台根目录中依次点开Microsoft SQL Server-->SQL Server组-->双击打开你的服务器-->双击打开数据库目录-->选择你的数据库名称(如论坛数据库Forum)-->然后点击右键选择属性-->选择选项-->在故障还原的模式中选择“简单”,然后按确定保存
2、在当前数据库上点右键,看所有任务中的收缩数据库,一般里面的默认设置不用调整,直接点确定
3、收缩数据库完成后,建议将您的数据库属性重新设置为标准模式,操作方法同第一点,因为日志在一些异常情况下往往是恢复数据库的重要依据
4、设定每日自动备份数据库
强烈建议有条件的用户进行此操作!
1、打开企业管理器,在控制台根目录中依次点开Microsoft SQL Server-->SQL Server组-->双击打开你的服务器
2、然后点上面菜单中的工具-->选择数据库维护计划器
3、下一步选择要进行自动备份的数据-->下一步更新数据优化信息,这里一般不用做选择-->下一步检查数据完整性,也一般不选择
4、下一步指定数据库维护计划,默认的是1周备份一次,点击更改选择每天备份后点确定
5、下一步指定备份的磁盘目录,选择指定目录,如您可以在D盘新建一个目录如:d:\databak,然后在这里选择使用此目录,如果您的数据库比较多最好选择为每个数据库建立子目录,然后选择删除早于多少天前的备份,一般设定4-7天,这看您的具体备份要求,备份文件扩展名一般都是bak就用默认的
6、下一步指定事务日志备份计划,看您的需要做选择-->下一步要生成的报表,一般不做选择-->下一步维护计划历史记录,最好用默认的选项-->下一步完成
7、完成后系统很可能会提示Sql Server Agent服务未启动,先点确定完成计划设定,然后找到桌面最右边状态栏中的SQL绿色图标,双击点开,在服务中选择Sql Server Agent,然后点击运行箭头,选上下方的当启动OS时自动启动服务
8、这个时候数据库计划已经成功的运行了,他将按照您上面的设置进行自动备份
三 : SQL Server 2000删除实战演习(1)
我们今天是要和大家一起讨论的是SQL Server 2000删除日志,如果你对SQL Server 2000删除日志的实际操作步骤心存好奇的话,以下的文章将会揭开它的神秘面纱,以下就是具体方案的描述,希望在你今后的学习中会有所帮助。
一. 删除LOG
1:分离数据库 企业管理器->服务器->数据库->右键->分离数据库
2:删除LOG文件
3:附加数据库 企业管理器->服务器->数据库->右键->附加数据库
此法生成新的LOG,大小只有520多K
再将此数据库设置自动收缩
或用代码:
下面的示例分离 testdatabase,然后将 testdatabase 中的一个文件附加到当前服务器。
- EXECsp_detach_db@dbname='testdatabase'
- EXECsp_attach_single_file_db@dbname='testdatabase',
- @physname='c:\ProgramFiles\MicrosoftSQLServer\MSSQL\Data\testdatabase.mdf'
二.清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
再:
企业管理器右键你要压缩的数据库所有任务收缩数据库收缩文件选择日志文件在收缩方式
里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
三.如果想以后不让它增长
企业管理器->服务器->数据库->属性->事务日志->将文件增长限制为2M
自动收缩日志,也可以用下面这条语句
ALTER DATABASE 数据库名
SET AUTO_SHRINK ON
故障还原模型改为简单,用语句是
USE MASTER
GO
ALTER DATABASE 数据库名 SET RECOVERY SIMPLE
GO
-
截断事务日志:
- BACKUPLOG{database_name|@database_name_var}
- {
- [WITH
- {NO_LOG|TRUNCATE_ONLY}]
- }
压缩SQL Server 2000删除日志及数据库文件大小
特别注意
请按步骤进行,未进行前面的步骤,请不要做后面的步骤
否则可能损坏你的数据库.
1.清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
2.截断事务日志:
BACKUP LOG 数据库名 WITH NO_LOG
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
企业管理器右键你要压缩的数据库所有任务收缩数据库收缩文件
选择SQL Server 2000删除日志文件在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,
确定就可以了
选择数据文件在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,
确定就可以了
也可以用SQL语句来完成
收缩数据库
DBCC SHRINKDATABASE(客户资料)
收缩指定数据文件,1是文件号,可以通过这个语句查询到:select * from sysfiles
DBCC SHRINKFILE(1)
4.为了最大化的缩小日志文件(如果是sql 7.0,这步只能在查询分析器中进行)
a.分离数据库:
企业管理器服务器数据库右键分离数据库
b.在我的电脑中删除LOG文件
c.附加数据库:
企业管理器服务器数据库右键附加数据库
此法将生成新的LOG,大小只有500多K
或用代码:
下面的示例分离 testdatabase,然后将 testdatabase 中的一个文件附加到当前服务器。
a.分离
- EXECsp_detach_db@dbname='testdatabase'
b.删除日志文件
c.再附加
- EXECsp_attach_single_file_db@dbname='testdatabase',
- @physname='c:\ProgramFiles\MicrosoftSQLServer\MSSQL\Data\testdatabase.mdf'
5.为了以后能自动收缩,做如下设置:
企业管理器服务器右键数据库属性选项选择"自动收缩"
SQL语句设置方式:
EXEC sp_dboption '数据库名', 'autoshrink', 'TRUE'
6.如果想以后不让它SQL Server 2000删除日志增长得太大
企业管理器服务器右键数据库属性事务日志
将文件增长限制为xM(x是你允许的最大数据文件大小)
SQL语句的设置方式:
alter database 数据库名 modify file(name=逻辑文件名,maxsize=20)
压缩数据库的通用存储过程
压缩日志及数据库文件大小
因为要对数据库进行分离处理
所以存储过程不能创建在被压缩的数据库中
调用示例
exec p_compdb 'test'
use master 注意,此存储过程要建在master数据库中
- go
- ifexists(select*fromdbo.sysobjectswhereid=object_id(N'[dbo].[p_compdb]')and
- OBJECTPROPERTY(id,N'IsProcedure')=1)
- dropprocedure[dbo].[p_compdb]
- GO
- createprocp_compdb
@dbname sysname, 要压缩的数据库名
@bkdatabase bit=1, 因为分离SQL Server 2000删除日志的步骤中,可能会损坏数据库,所以你可以选择是否自动数据库
@bkfname nvarchar(260)='' 备份的文件名,如果不指定,自动备份到默认备份目录,备份文件名为:数
据库名+日期时间
SQL Server 2000删除实战演习(1)_实战演习
as
1.清空日志
- exec('DUMPTRANSACTION['+@dbname+']WITHNO_LOG')
2.截断事务日志:
- exec('BACKUPLOG['+@dbname+']WITHNO_LOG')
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
- exec('DBCCSHRINKDATABASE(['+@dbname+'])')
4.设置自动收缩
- exec('EXECsp_dboption'''+@dbname+''',''autoshrink'',''TRUE''')
后面的步骤有一定危险,你可以可以选择是否应该这些步骤
5.分离数据库
- if@bkdatabase=1
- begin
- ifisnull(@bkfname,'')=''
- set@bkfname=@dbname+'_'+convert(varchar,getdate(),112)
- +replace(convert(varchar,getdate(),108),':','')
select 提示信息='备份数据库到SQL 默认备份目录,备份文件名:'+@bkfname
- exec('backupdatabase['+@dbname+']todisk='''+@bkfname+'''')
- end
进行分离处理
- createtable#t(fnamenvarchar(260),typeint)
- exec('insertinto#tselectfilename,type=status&0x40from['+@dbname+']..sysfiles')
- exec('sp_detach_db'''+@dbname+'''')
删除SQL Server 2000删除日志文件
- declare@fnamenvarchar(260),@svarchar(8000)
- declaretbcursorlocalforselectfnamefrom#twheretype=64
- opentb
- fetchnextfromtbinto@fname
- while@@fetch_status=0
- begin
- set@s='del"'+rtrim(@fname)+'"'
- execmaster..xp_cmdshell@s,no_output
- fetchnextfromtbinto@fname
- end
- closetb
- deallocatetb
附加数据库
- set@s=''
- declaretbcursorlocalforselectfnamefrom#twheretype=0
- opentb
- fetchnextfromtbinto@fname
- while@@fetch_status=0
- begin
- set@s=@s+','''+rtrim(@fname)+''''
- fetchnextfromtbinto@fname
- end
- closetb
- deallocatetb
以上的相关内容就是对SQL Server 2000删除日志的介绍,望你能有所收获。
本文标题:sql server 2000 个人版-微软已宣布首次公开预览Linux版本SQL Server61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1