一 : 大数据分析平台Apache Kylin的部署(Cube构建使用)
前言
Apache Kylin是一个开源的分布式分析引擎,最初由eBay开发贡献至开源社区。它提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持大规模数据,能够处理TB乃至PB级别的分析任务,能够在亚秒级查询巨大的Hive表,并支持高并发。
Kylin的理论基础:空间换时间。
Kylin从数据仓库中最常用的Hive中读取源数据,使用 MapReduce作为Cube构建的引擎,并把预计算结果保存在HBase中,对外暴露Rest API/JDBC/ODBC的查询接口。
部署Kylin
(一)下载安装
写这篇博客时,最新版为2.0.0 beta版,最新的正式版为1.6.0,所以我使用的1.6.0。
可以直接下载源码包编译安装,也可以根据自己的hadoop环境版本下载对应的二进制安装包。
Apache Kylin v1.6.0正式发布

我使用的是HDP2.4.2,Hbase版本是1.1.2。直接下载的是二进制包安装。
$ cd /opt
$ wget http://ftp.tc.edu.tw/pub/Apache/kylin/apache-kylin-1.6.0/apache-kylin-1.6.0-hbase1.x-bin.tar.gz
$ tar xf apache-kylin-1.6.0-hbase1.x-bin.tar.gz
$ vim /etc/profile
export KYLIN_HOME=/opt/apache-kylin-1.6.0-hbase1.x-bin
$ source /etc/profile
(二)环境检查
$cd /opt/apache-kylin-1.6.0-hbase1.x-bin
$./bin/check-env.sh
KYLIN_HOME is set to /opt/apache-kylin-1.6.0-hbase1.x-binmkdir: Permission denied: user=root, access=WRITE, inode="/kylin":hdfs:hdfs:drwxr-xr-xfailed to create /kylin, Please make sure the user has right to access /kylin
#提示使用hdfs用户
#check-env.sh脚本执行的是检查本地hive,hbase,hadoop等环境情况。
#并会在hdfs中创建一个kylin的工作目录。
$ su hdfs
$ ./bin/check-env.sh
KYLIN_HOME is set to /opt/apache-kylin-1.6.0-hbase1.x-bin
$ hadoop fs -ls / #多了一个/kylin的目录drwxr-xr-x - hdfs hdfs 0 2017-01-19 10:08 /kylin
(三)启动
$ chown hdfs.hadoop /opt/apache-kylin-1.6.0-hbase1.x-bin
$ ./bin/kylin.sh start
A new Kylin instance is started by hdfs, stop it using "kylin.sh stop"Please visit
You can check the log at /opt/apache-kylin-1.6.0-hbase1.x-bin/logs/kylin.log
(四)进入页面
http://localhost:7070/kylin
user:ADMIN passwd:KYLIN
使用Kylin
(一)添加新的项目
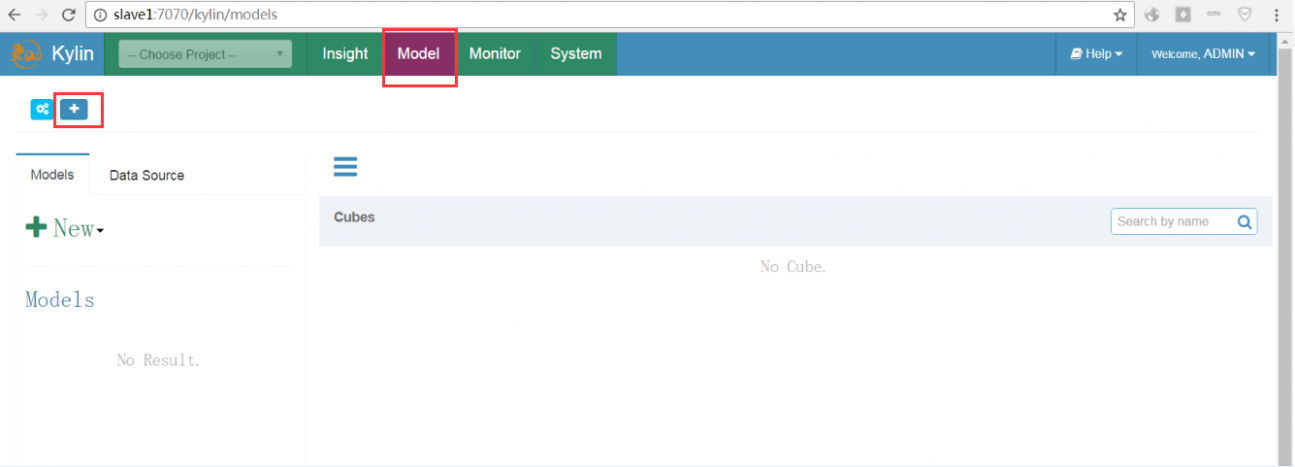
给项目起一个名字,添加项目描述。
给项目添加数据源(加载hive数据表)
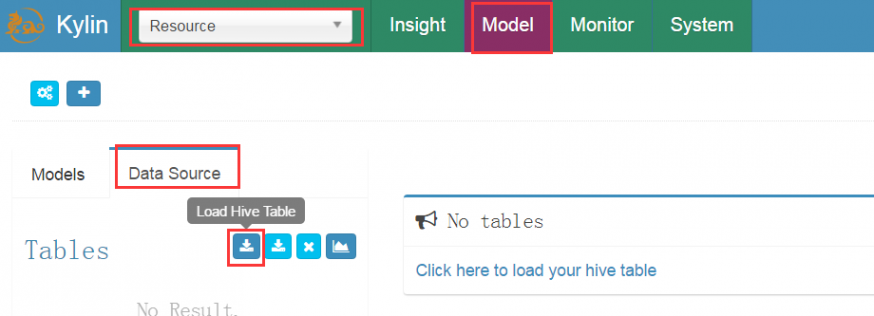
在数据源的页面,可以手动填写hive表名
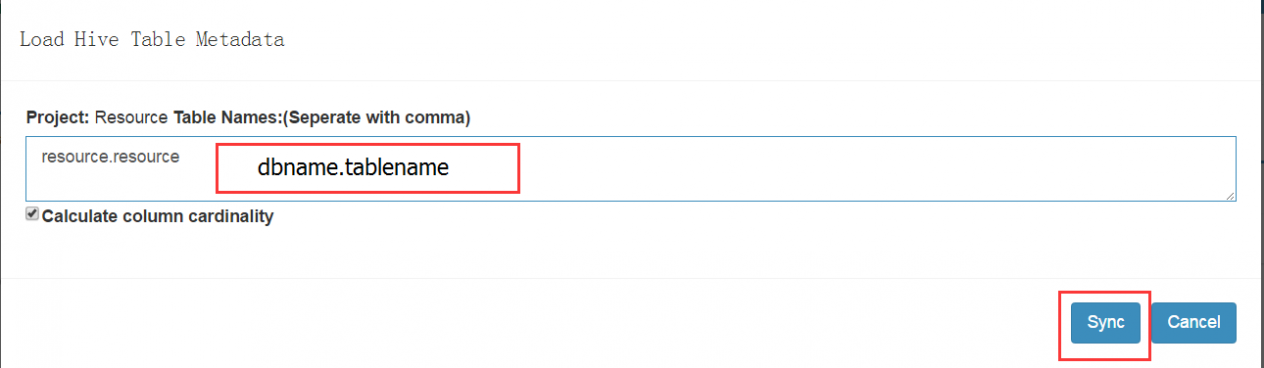
成功加载了resource表的数据

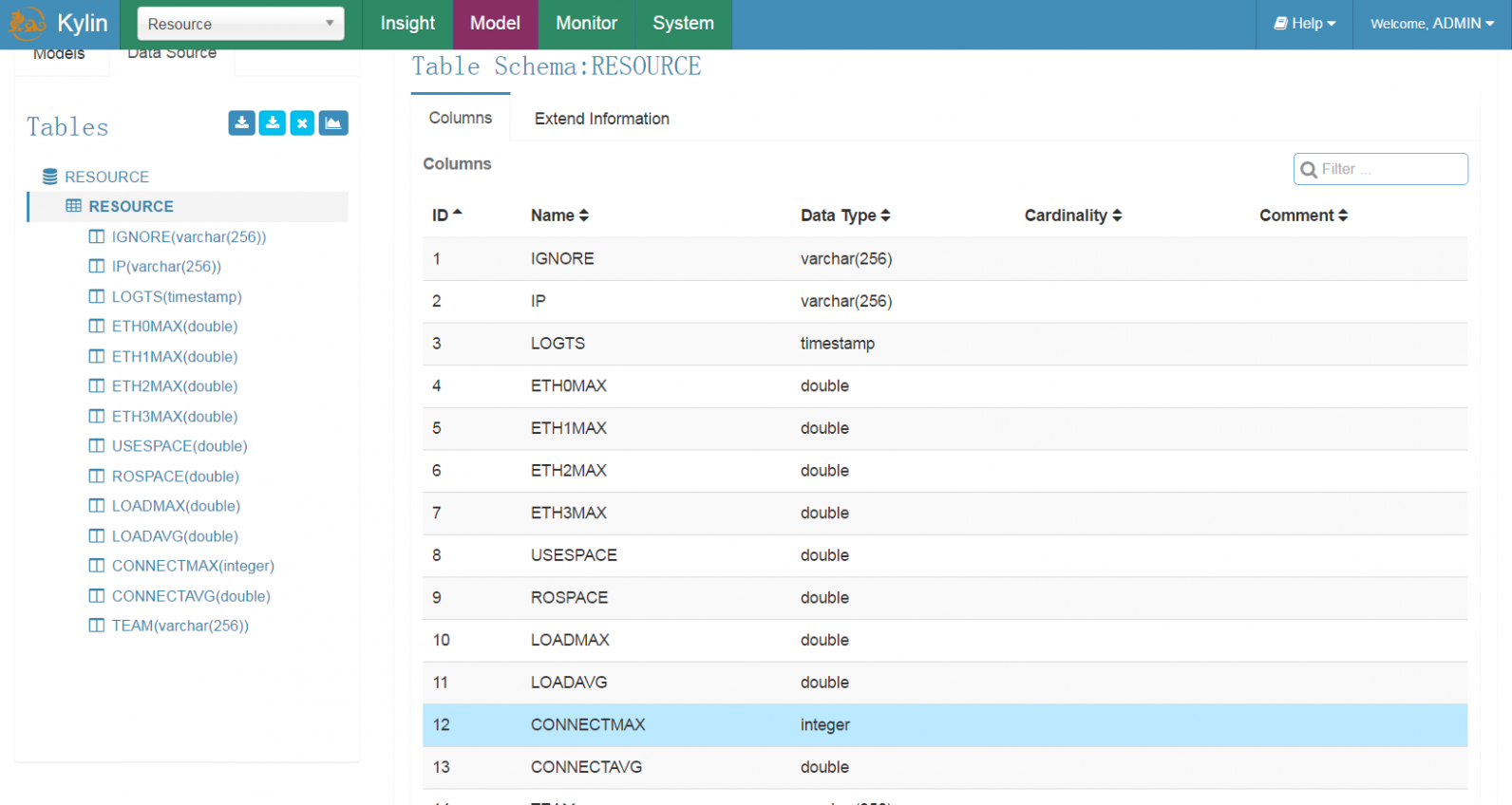
这时就可以看到对应表的字段属性。
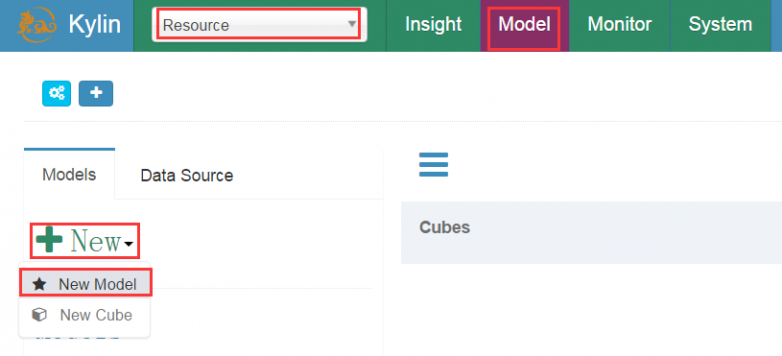
(二)创建model(模型)
新建model
编辑model名字和描述
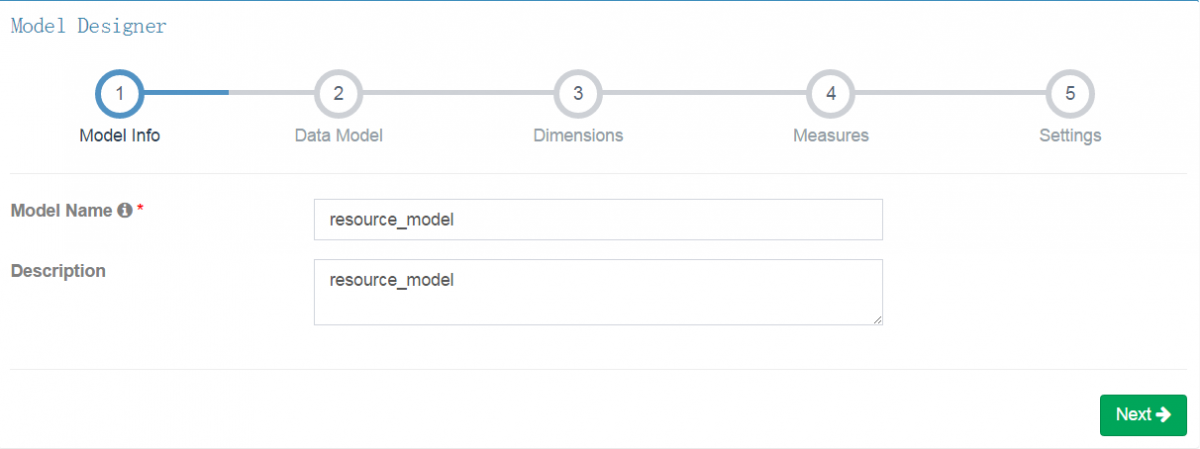
选择数据表

接下来选择维度和度量,这是构建预计算模型cube中最为重要的两个属性。
度量: 度量是具体考察的聚合数量值,例如:销售数量、销售金额、人均购买量。计算机一点描述就是在SQL中就是聚合函数。
例如:select cate,count(1),sum(num) from fact_table where date>’2016****’ group by cate;
count(1)、sum(num)是度量
维度: 维度是观察数据的角度。例如:销售日期、销售地点。计算机一点的描述就是在SQL中就是where、group by里的字段
例如:select cate,count(1),sum(num) from fact_table where date>’2016****’ group by cate;
date、cate是维度
选择要分析的维度字段
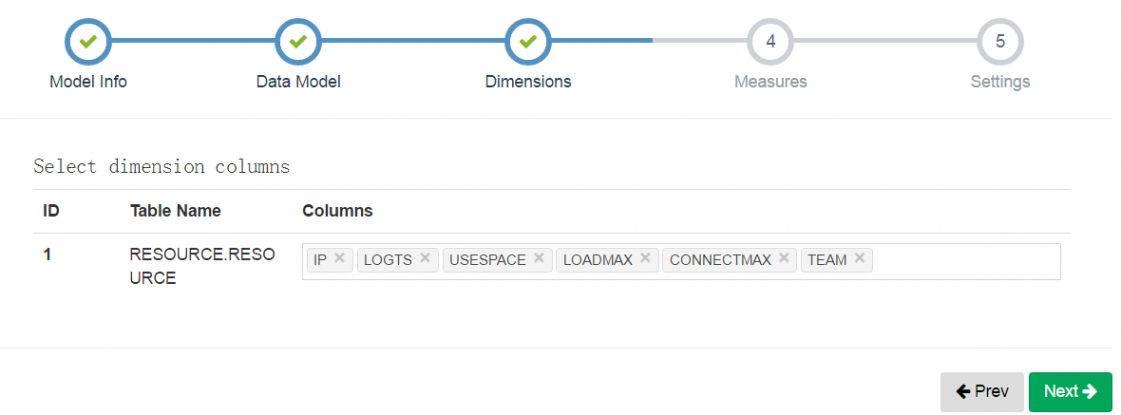
选择要分析的度量字段
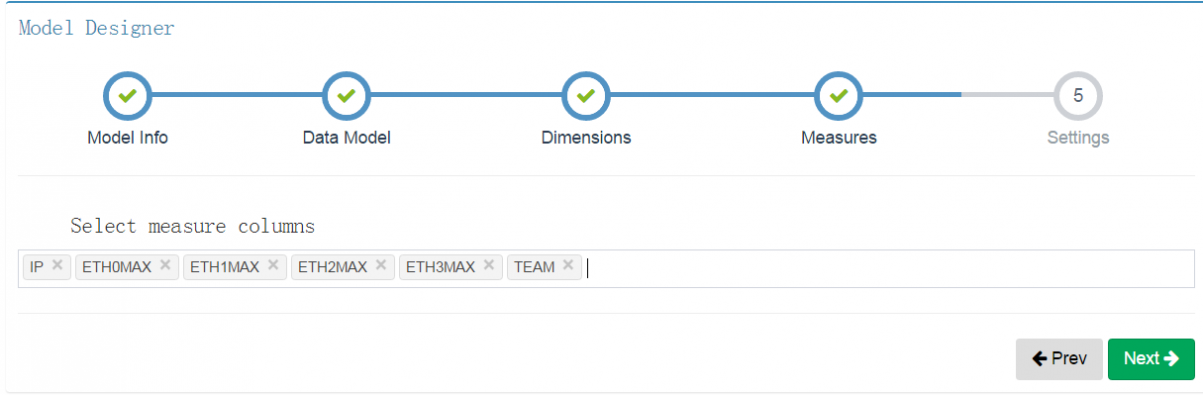
设置表中的时间字段
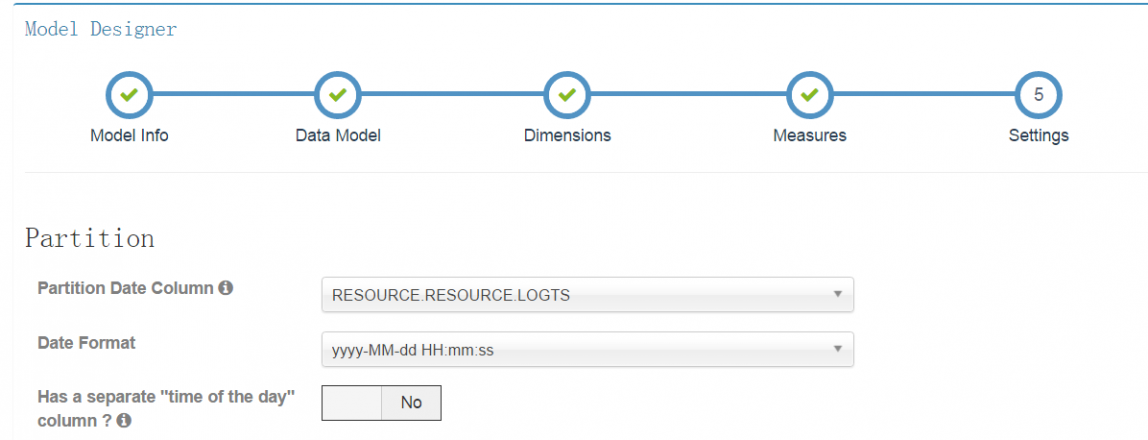
(三)创建cube(立方体)
Cube构建需要依赖前面创建的model。选择model,设置cube名。
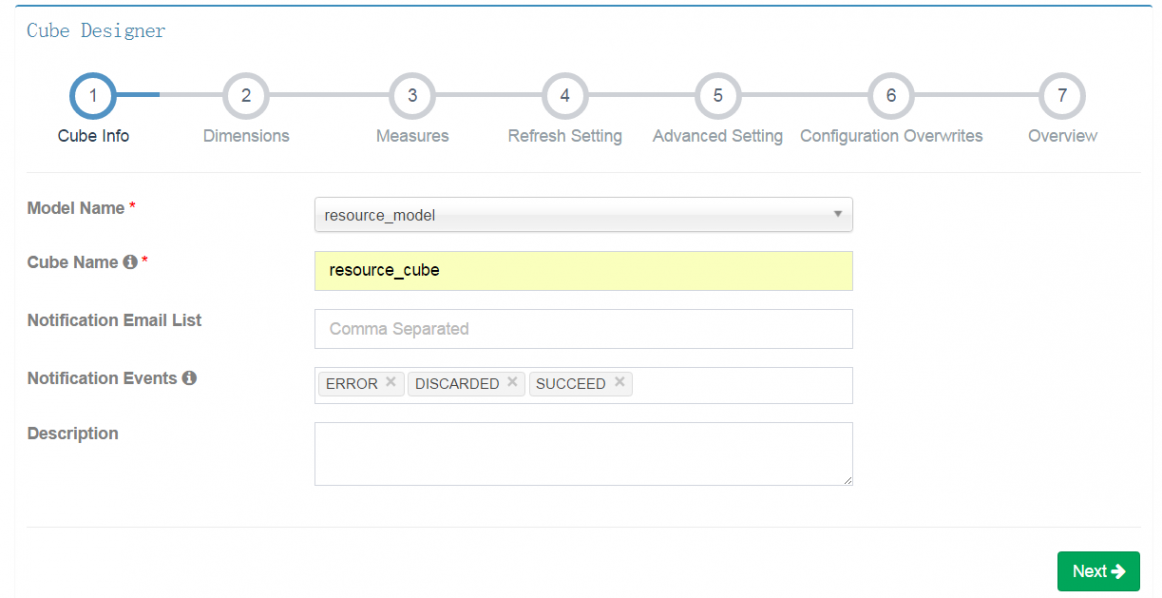
从上面model设置的维度字段中选择你需要分析的字段。
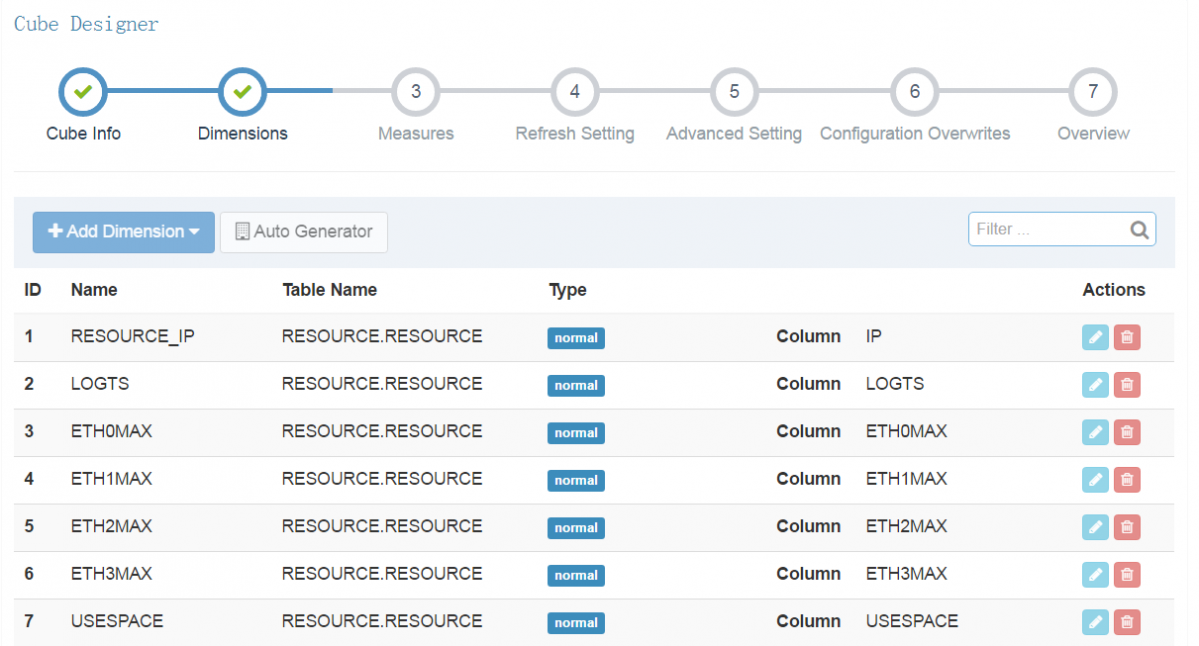
选择度量。
第一个_COUNT_是默认要计算的。
第二个COUNT_DISTINCT,可以去重计算得到有多少个IP地址,即通常的UV。
(COUNT_DISTINCT计算时是有精确度选择的,计算越精准需要的时间就越长)
第三个TOP_N,是用来计算排名的。
第四个MAX,是用来计算最大值的
还有其他的MIN,SUM等各种计算表达式。

后面的几个基本上就没有什么要设置的了,直接Next了,最后保存cube就好了。
(四)构建cube
创建好cube之后,我们只是得到了一个计算模型。需要将数据按照我们设定的模型去计算,才能得到相应的结果。
下面开始构建cube,在Action中选择Build

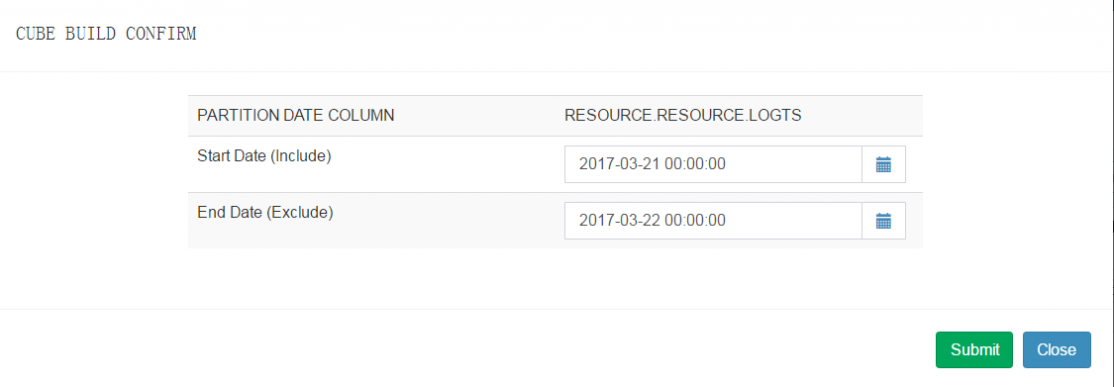
选择要构建的时间范围(如果数据是持续写入hive表,那么可以使用cube持续构建)


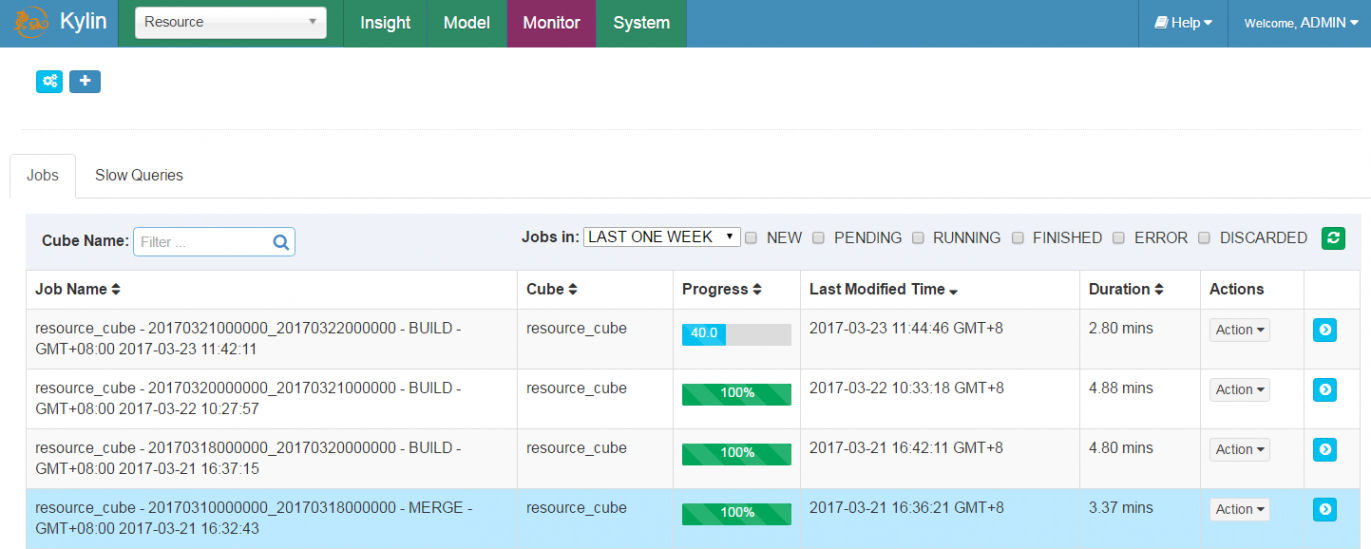
进入Monitor中查看正在构建的Cube,和历史构建的cube
(五)查询
cube构建成功后,数据就已经计算过,并将计算结果存储到了Hbase。那么这时候我们可以使用SQL在kylin中进行查询。
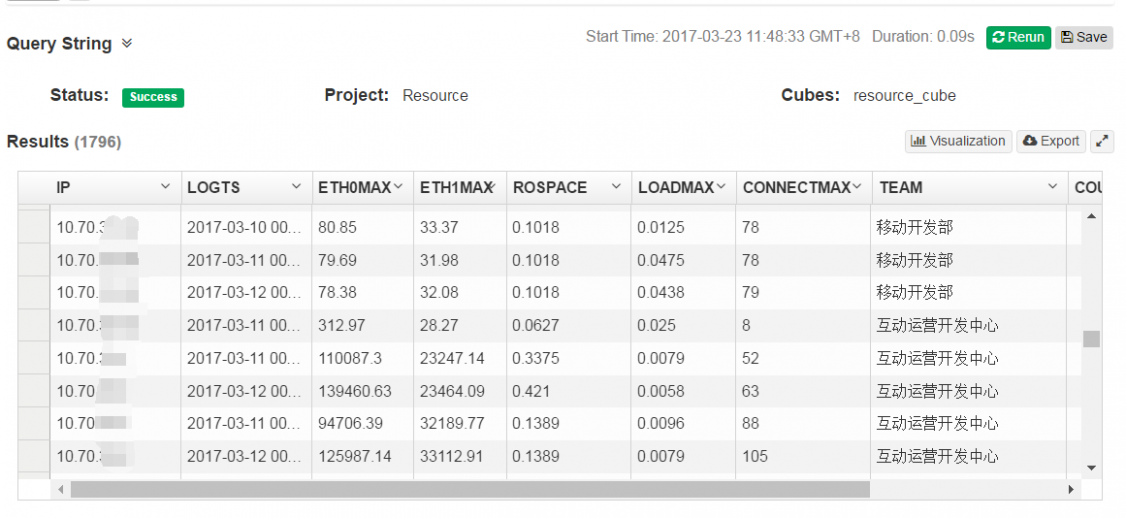
比较一下在kylin中查询和直接在hive中查询的速度。
执行一个group by order by的查询。
SQL:select ip, max(loadmax) as loadmax,max(connectmax) as connectmax, max(eth0max) as eth0max, max(eth1max) as eth1max ,max(rospace) as rospace,max(team) as team from resource group by ip order by loadmax asc ;
在Kylin预计算之后,这条查询只用了0.11s

直接在hive中进行计算时间是30.05s
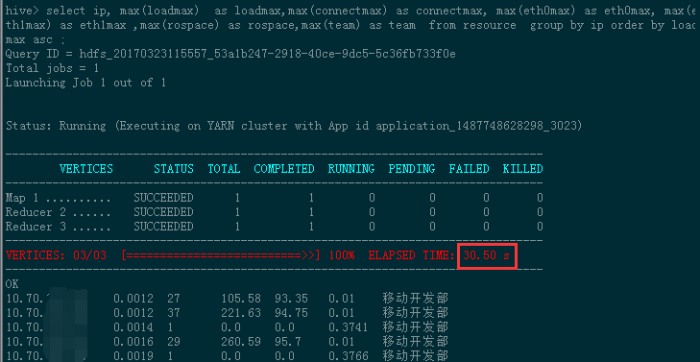
时间相差270倍!!!
(六)样例数据
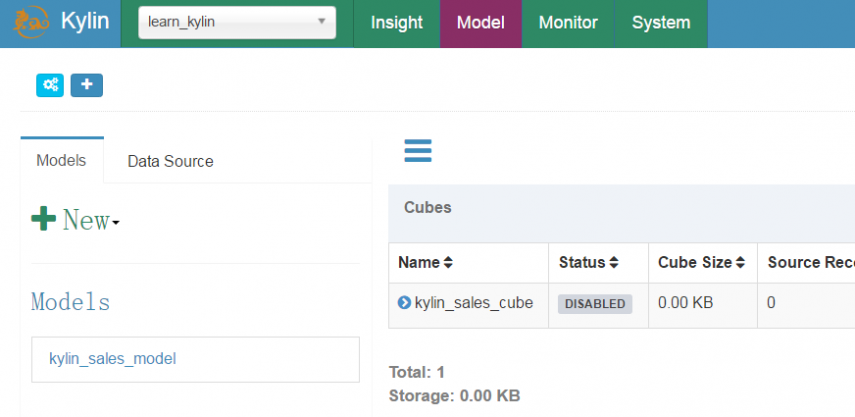
#kylin自带一个样例,包含1w条数据的样本
$ ./bin/sample.sh
Sample cube is created successfully in project 'learn_kylin'.
Restart Kylin server or reload the metadata from web UI to see the change.
$ ./bin/kylin.sh stop
stopping Kylin:15334
$ ./bin/kylin.sh start
可以在Kylin中看到learn_kylin这个项目。并且有创建好的model和cube,可以供参考和学习。
本文永久更新链接地址:
二 : 爱吧创始人:用大数据做婚恋平台

“爱吧”创始人石庆年资料图
对于一个39岁的外企人,我发现我以后发展的瓶颈太多,好像碰到天花板了,我觉得事业上好像也就这样了,但是自己心里又不太甘心,觉得还要挑战一下,还要做些什么,拥有属于自己的东西,所以就出来创业了。(www.61k.com]
我以前在外企做的是2B生意,经常出差,我就想创业以后找一个不用出差的,可以不用东跑西颠的事做。想了想就在2C的生意里面选,但选来选去发现难度很大:做游戏,我不喜欢;做平台,我们人手不够;做电商,钱不够而且不懂物流;总之那时候我把自己知道的项目全都在纸上罗列出来,最后发现移动婚恋这块可以做。
我以前工作是飞机制造,经常处理数据,对信息处理并不陌生,我之前的经验是很有用的。还有一点,我们创业时候钱不多,需要一个资金回流快的项目,我们烧不起钱,婚恋这块可以收到钱,可以保证我们创业能持续下去,就这样我们开始做“爱吧”这款应用。
绝处逢生
仔细算来,“爱吧”死了好几次了,但每次又绝处逢生。2011年一开始做的是PC端产品,是微博里面的一个应用,但微博后来和别的应用合作推出了一款婚恋产品。(我们)没办法只能退出微博,把20多个人的团队裁到了只剩几个人。这是团队经历的第一次大调整。
调整完,我们掉头做移动互联网,重写代码,重建我们的商业模式。做着做着,好不容易有点起色了,但是又一次大危机来了:2012年过年那会,初二到初九,我还清楚的记得,我们放在云服务器里面的“爱吧”的数据意外丢失了,要知道,那可是我们所有200万用户的数据,丢了的话我们的劳动就等于白费了,这对于“爱吧”来说就是晴天霹雳。团队那会过年的心情都没有,心情非常沮丧。但我没放弃,抱着试一试的心态,我亲自跑到上海,一路上,心里一直打鼓,到底能不能搞回数据。最后协调半天,把原始数据给拿回来了,心里的一颗石头才算落了地。说真的,那时候放弃做“爱吧”,确实是个好借口。
我们的产品是什么?
1.老乡汇:这是我们软件里的一个功能,因为不同的地方会有不同的文化,用户一开始注册的时候就会填籍贯,填完了我们会在“老乡会”里推送和用户家乡近的对象。文化相似的男女更容易成为一对,而且逢年过节回家的时候还能互相照应。
2.车子房子认证:现在人们结婚还是很“现实”的,择偶观也重视这个方面,人们普遍还是追求安全感。我们在用户备注里有这方面的认证,比如一个人拥有(北京)朝阳88平的房子,一辆奥迪SL的车都会显示出来。最后证明这个认证非常能得到用户的认可,有车有房的用户更容易收到邀请和约会,他们是真正要结婚的,这个功能能帮助他们直奔主题。
3.企业会员:像很多外企每年也会由单位组织相亲会,比如IBM、惠普等,但是他们开完了以后发现效果并不是特别好,没什么人在这种相亲会上能完成婚姻大事,原因多种多样。我们干脆把这些优质用户拉进来让我们平台,他们可选择的范围扩大了,IT男就有可能认识女教师,女医生有可能认识一个外企高管。
我们怎么挣钱?
1、线上收费
这是传统的会员VIP收费。最大的特点是,我们有“委托红娘”服务收费:如果一个人用我们的产品给异性私信,但没有得到回应,又对这名异性特别感兴趣,用户可以联系我们,我们人工和对方取得联络,我们从中收一定的费用。
还有一种线上收费就是用户在上面成功发起约会我们收取一定费用,以发私信的方式主动求约对方收一定的“邮票费”。
2、高端服务收费
爱情猎头:很多人没有时间寻找自己的另一半,“爱吧”专门为这样的人服务,像猎头一样去找符合用户需求的异性。
和婚介所合作:婚介所并不过时,它满足人们线下见面的需求,不光这样,婚介所里也有很多人是真正想结婚的,而且对于上年纪的人来说可能不太接受得了移动互联网,我们和他们合作把中高端的人群资源调出来放到我们的平台上,帮助他们征婚,这个模式也能挣到一些钱。
3、向企业收费
我们前面说到,我们和很多企事业单位合作,把想结婚的员工资料放在我们平台上。这个模式里面我们对员工是免费的,但是会对企事业单位和机构收取费用。这些机构通常有着自己这样那样的特殊要求,我们另外收取一部分费用。
61阅读提醒您本文地址:
三 : 浅谈站长如何根据后台数据进行内容的构建
对于每一个站长来说,为访客和搜索引擎蜘蛛提供新鲜的高质量的内容是每天的工作之一,如果一个站点长期没有在内容上更新的话,访客和搜索引擎最终都会流失。对于内容的更新,我们是不是只要每天更新几篇就没事了呢?这样的成效有多少?笔者认为只是为了更新而更新的是得不到好的效果的。我们在更新内容的时候还要充分的利用现有的数据,即后台的流量数据来进行内容的构建,才能达到最好的效果。那么笔者将就如何利用后台数据进行内容构建分享自己的心得。
一:通过分析站点后台数据的PV值构建内容
PV只是一个站长们判断用户的友好体验度的直观的渠道之一,因为如果我们的站点PV值越高的话,那么我们可以说访客在站点上的停留时间就表明越长,同时也可以从侧面反映出站点的用户友好体验度高。试想一下,如果用户不喜欢你的站点,何来更加深入的访问。对此,站长们在更新内容的时,同时也要先分析站点的PV值。具体如下图笔者的站点所示:
图一:站点PV值
图二:受访页面的点击率及跳出率
在上面笔者站点后台的两个数据中,我们可以看出,在站点的首页访问量是最大的,而这也是正常的情况,而我们分析的时候要也要将首页排除掉。在内页的数据中,我们可以发现如果页面的访问次数和停留时间长的页面往往是访客比较喜欢的页面,而我们在更新站点内容的时候,自然而然要率先考虑这些页面的内容,因为作为内容的构建,我们要跟着访客的喜好走。这对于提高站点的友好体验度,增加站点的粘度有很好的促进作用。
二:从独立访客数据进行分析
一般来说,根据站点的后台数据中用户访问的时间段我们可以看出,在一天的流量中访问量最大的时间段出现在早上九点至中午的十一点这一段时间内,如下图所示,那么我们就可以根据这一数据对站点的内容更新时间做出安排,我们可以选择在用户访问量最大的这一个时间段内进行内容的更新,特别是对于资讯类站点来说,可以让访客及时的看到最新鲜的内容。同时,我们还需要注意,并不是说这个时间段流量较大就将所有的内容更新在这一个时间段内完成,我么也要在其他的时间段内进行定量的内容更新,合理的照顾到每一个时间段内访问的用户。
对于内容的更新,我们应该更加的谨慎,因为内容使我们呈献给我们的访客和搜索引擎蜘蛛我们站点的价值。所以,根据后台数据合理的处理好每一个内容建设的细节是每一个站长必具备的一项技能。本文由skf轴承http://www.skf-bearing.net/ 手写原创,转载请保留出处。
四 : 传Facebook将在台湾建数据中心 占地约2万平米
【搜狐IT消息】11月8日消息,据报道,Facebook将在台湾建立亚洲最大云数据中心,地点选在中科。
在美国,Facebook在北卡罗来纳州已拥有大型数据中心。台湾数据中心将占地两万平米,相当于180个篮球场大小。至于采购,软件和硬件将分开,Facebook负责采购软件,而硬件则直接向代工厂采购,避开了品牌商。
在硬盘采购上纬创夺标可能性最大,技嘉、广达积极争取,明年元月可能出最终方案。
中科方面对Facebook建亚洲最大云数据中心一事“没听说”;Facebook台湾广告代理商圣洋科技,也以“不清楚”响应,但相关消息已在电子代工厂传开。之前Google也选定在台湾设立云中心。
业界分析,云服务器平均毛利率超过20%,对目前毛利率仅剩3%至4%的代工厂而言,可谓肥单,若能直接出货给终端客户,毛利率更佳,将带动纬创、技嘉等大厂的获利起飞。
纬创与Facebook已有合作,纬创负责供应Facebook美国北卡罗来纳州数据中心的服务器,预计12月出货,Facebook这次来台投资,纬创夺标呼声大,将成最大赢家;技嘉则期望借由此机会首度吃到一线大厂的云订单。 纬创不愿对于客户状况置评。据了解,为响应Facebook等大型客户的云采购案,纬创内部已成立新事业部专门负责产品设计与出货等细节。
技嘉表示,先前已与Google合作过数字机顶盒,近日也听闻到Facebook在台投资案,将会积极争取订单。
五 : 爱钱帮以大数据为支点构建生态圈
随着互联网技术的不断发展,大数据的应用开始冲击着各行各业,其中包括传统行业,零售业以及互联网金融服务业,与此同时,大数据也在改变着我们的日常生活,通过简单和基于云端数据服务,我们更能追踪自己的行为和习惯,目前中国拥有将近14亿人口,是大数据潜在的市场之一,据统计,中国有将近6亿网民,这也就代表中国将有更好的了解客户并且提供个性化的体验。
爱钱帮作为国内知名互联网金融在去年基础完善的大数据风控系统下,今年力求以大数据为支点构建更完善的生态圈,爱钱帮CEO王吉涛表示,在去年,其实我们有一个非常的感受就是,我们基于这套大数据的风控系统,搭建模型已经越来越成型,很多数据源我们不可得的,在今年,我们都变得触手可及。这种数据源的开发以及可获得性,让我们在抵押类的资产和供应链的资产,可以尝试一些这种基于消费场景的消费金融概念。有像我们现在做的以车、以房或者库存作为抵押的硬抵押,但是消费场景、真实、分散,我们通过对个人的这种数据,从数据的角度对个人进行评估和授信。让这个领域的创新变得有很大的空间。
由此可见,大数据在互联网金融发展中发挥着不可忽视的作用,生活中不再需要银行卡和钱包,平台和渠道的发展融合延伸深化了金融的意义,大数据也正在以一种新的方式塑造一个全新的的金融思维模式,爱钱帮作为行业的创新发展的企业代表,在勇往直前的道路上也在不断地与时俱进。
据了解,爱钱帮所做的信贷包括贷款前,贷款中,贷款后。以前会花很多的时间做敬职调查,现在通过大数据的方式解决的。信贷前审查后,就会提高贷款的效率,贷款中进行监管,采用银行资金存管+第三方担保+独立风控的业务模式,与受地方金融局监管的实力雄厚的融资性担保机构合作,为投资人提供年化收益率8%—14%的优质安全的理财产品,由合作担保机构全额本息担保,全面保障用户的资金安全。
本文标题:如何构建大数据平台-大数据分析平台Apache Kylin的部署(Cube构建使用)61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1