一 : 消息称阿里700万美元收购移动数据统计平台
新浪科技讯 3月23日上午消息,有消息人士爆料称,阿里巴巴7000万美元收购了一家移动开发者数据统计平台,不少分析认为收购对象很有可能是移动开发服务平台友盟。阿里巴巴则表示不对市场传言做评论。
昨日“小道消息”账号爆料称,阿里巴巴收购国内某移动开发者统计服务平台,收购价格是7000万美元,并且收购之后将会纳入一淘体系。
该消息引发市场猜测,大家纷纷将目光投向友盟。资料显示,友盟2010年5月推出首款产品友盟统计,为中国开发者提供本地化、免费、跨平台的移动应用统计分析。2010年11月获得创新工场天使投资,2011年7月完成A轮融资,投资方为经纬投资,融资规模1000万元。
目前各大互联网公司都在抢占移动入口,阿里巴巴也不例外,在阿里巴巴董事局主席马云“平台、金融、数据”战略的指点下,收购移动开发者统计服务公司并不意外,而这也被看做是为阿里在移动端电商和广告的布局做伏笔。
阿里巴巴并未对此事进行回应,则表示不对外界传言做评论。友盟也暂未对此事进行回应。(林明)
二 : 当当网发力数字阅读:计划做自出版平台
新浪科技讯 6月24日上午消息,据消息人士透露,当当网正在发力数字阅读市场,不仅成立原创事业部,还计划做“自出版”平台。
不久前当当网与童话大王郑渊洁签约,在是当当首次绕过出版社直接签约作者,意味着其希望加大原创数字内容的扶持力度。
据内部人士透露,除了推动直签作家真略,当当还在网络文学领域招兵买马成立原创事业部,目前事业部成员包括幻剑书盟、博易创为、梦工厂等班底。
豆瓣上一位人气网络写手透露,当当网的目标可能是要做一个“自出版”平台,希望扶持网络文学里的草根作家。
当当网在数字图书领域的对手,亚马逊中国正在通过Kindle推动数字阅读市场,虽然当当网也曾推出过电子书产品“都看”。与亚马逊硬件推数字书阅读不同,当当网除了开发了“都看”阅读器,还施行“买纸书送电子书”的政策,以讨好深度阅读者培养数字书阅读习惯。
在业内人士看来,当当网此举也是比拼硬件更好的抢深度用户的方式,毕竟手机阅读才是现在和未来的数字书阅读主流,很多读者并不愿意为阅读数字书增加一个阅读终端。
当当网CEO李国庆在公开场合不止一次强调,电子书短期内不会替代纸书。当当网内部人士表示,用硬件推动数字书阅读市场并不是一件最紧迫的事,关键还是在版权。
“数字书一战惨烈程度将不亚于纸书,原创资源、纸书数字版权以及作家资源、深度阅读人群等等都将是战场,靠硬件铺路可能是把事情想简单了。”上述人士称。
一组未公开的数据是:1.当当网读书客户端“当当读书”的月活跃用户以每月30%速度在增长,以此计算,读书客户端的年用户增长将达到23倍;2.“当当读书”用户以深度阅读者为主,用户每日平均的阅读时长超过30分钟。
这也是当当布局数字阅读的重要原因。不过当当内部人士表示,在目前阶段,当当网没有打算在数字版权领域赚钱,主要还是想拿更多畅销的版权资源。
当当网副总裁姚丹骞数日前参加一个电商论坛时透露,在获取版权资源后,当当网将通过图书出版激活电商文化产业,涉足影视、手游文化产业。(林明)
三 : 链家网大数据平台枢纽——工具链
声明:本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》。
作者:吕毅,链家网平台架构师。目前负责链家网大数据平台,之前曾负责链家网基础服务平台建设。
责编:郭芮,关注大数据领域,寻求报道或投稿请联系guorui@csdn.net。
链家网于2015年成立大数据部门,开始构建基于Hadoop的技术体系,初期大数据部门以运营数据报表需求、公司核心指标需求为主。随着2015年链家网发力线上业务,toB与toC业务齐头并进,数据需求量激增的情况也随之在2016年突显,数据量增至PB级。我们开始思考如何改变现状,如何高效支撑未来可预见的众多数据需求。
基于ROLAP技术的报表平台
链家网大数据部门成立之初,面对着零散的数据需求,最早期的办法是配置定时任务跑脚本,将结果通过邮件方式发送给需求方。2015年期间,随着运营数据需求的增加、希望查阅数据的人员增多,邮件的方式不方便人员间信息传递,并且查找历史数据也不方便,在技术上也因数据相关人太多导致邮件发送阻塞。因此,考虑到运营数据需求、公司核心指标需求相对固定,并且维度可枚举,特在2015年基于ROLAP技术方案,搭建了早期的报表系统。
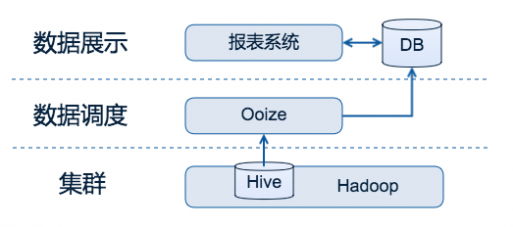
图1 链家网早期的报表系统
早期的报表系统,由数据开发工程师提交数据任务,通过配置Oozie定时任务,定时的基于Hive数据做ETL过程,将报表系统所需的数据推入关系型数据库(MySQL)中。该系统从接收需求到报表系统里看到数据,需要比较长的一段时间过程,涵盖过程如下:
沟通需求,由数据开发工程师理解数据需求; 对接数据,将数据源对接入HDFS; 构造数据,将数据加工处理到Hive中,逐层由STG到ODG,再到DW层; 数据任务,数据开发工程师根据需求方需求、DW层数据,编写基于Oozie的调度任务; 发布任务,将Oozie调度任务发布到线上,定时执行,数据运行结果将被推送到MySQL; 数据展示,由自研的报表系统,根据需求方展示需求,添加维度筛选能力,开发一些对结果数据的再加工程序,部署上线。
流程过程较长,角色间传递信息较多,前后依赖太强,都是制约当时报表系统快速产出数据的根本问题。该系统在之后的迭代中,通过增加选取MySQL数据、自助勾选维度,实现了自助报表系统,命名为“地动仪”并服务至今。然而,流程长、传递信息多、依赖强的问题依旧没有根本解决,对于逐渐增多的数据分析需求,更不能及时响应。
地动仪在一定程度上解决了邮件方式的弊端,提供Web界面化的查询,支持历史查询和多人使用。但对于非订制化需求、数据探索需求、数据分析需求支持的力度并不好。我们开始规划更好的数据分析平台服务。
链家网大数据平台的诞生
大数据工作划分,通常分为大数据应用、大数据平台两大部分。常见的大数据应用形态有数据挖掘、数据分析、个性化推荐、数据报表等,大数据应用形式相对更多样,可以根据业务不同而有具体的大数据应用产品。大数据平台,在一家公司中则应相对统一,以方便做好公司统一的数据接入规范、统一的数据管理机制、统一的数据处理能力等,做好数据管控。
因此,在对历史大数据架构进行梳理后,链家网将原有大数据部门工作细化,将大数据应用交由业务线团队或其他技术团队承担,便于业务线开展多样化的数据工作,同时将大数据部门聚焦于构建公司统一的大数据平台,负责公司内各部门数据相关需求的统一规划与实现,建设公司统一的数据仓库与数据服务。至此,链家网大数据平台团队诞生,我们开始着手建立平台,支持好未来公司内对数据使用上的各类需求。
在2016年中期,通过梳理各部门数据需求,将数据需求分类为:数据探索需求、报表需求、数据分析需求、数据API需求这四类。为满足这些数据需求,我们相应规划了下面这些数据产品:
AdHoc系统:解决数据探索性需求,基于SQL查询,查询速度要求高; 地动仪:解决报表需求,承接较固化报表需求、公司级报表需求; BI产品:解决数据分析需求,支持多维查询,支持数据分析中常用的下钻、上卷等功能; 数据API:解决数据API需求,大数据API统一出口,支持各部门的格式化数据获取。
结合数据产品层面的规划,大数据平台在技术工作上做了重新规划,技术工作上划分出了四个部分:平台服务、数据管理、工具链与集群。其中平台服务包含报表系统、BI系统与大数据API;大数据工具链包括OLAP引擎、即席查询AdHoc系统、调度系统三部分;大数据集群层面除集群性能、稳定性工作外,还包括集群安全、集群资源隔离两部分;贯穿服务、工具链、集群三层的数据管理部分,更加关注数据治理,内含元数据管理、指标管理、数据权限管理三大数据管理工作。技术工作划分情况如图2:
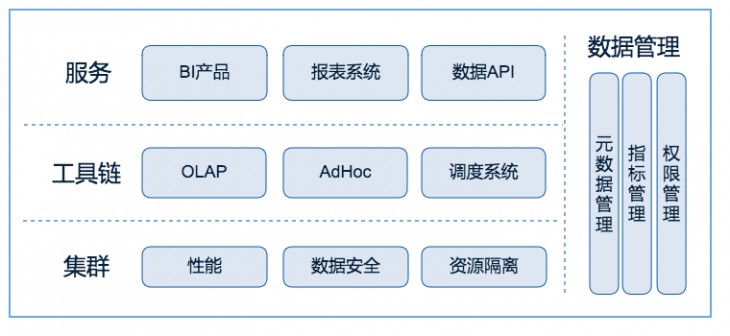
图2 链家网大数据平台
大数据平台的建设过程,是由下而上逐步完成的。首先要有Hadoop集群,在有HDFS与Hive后,才能开展数据接入工作,才能基于集群建设工具链;当工具链部分的OLAP引擎构建好,才有上层BI、报表系统和数据API,只有AdHoc能力构建好,才能提供基于SQL的数据探索平台,工具链中特别需要建设好调度系统,才能在实现好数据ETL任务的同时,管控数据流向与数据关系。最后则是服务层面的建设,重心在于迎合需求的同时,服务做得更加易用。数据管理系统会穿插于整个大数据平台中。
大数据平台中衔接服务与集群的枢纽——工具链,正是整个平台能力的传送带,它肩负着将大数据能力输送到上层服务层的重任,也承担着上层多项服务被使用时的数据能力支持。
建设大数据平台枢纽——工具链
大数据平台内部工作,完全可以简单划分为集群与服务两部分,为何要在它们之间构建一层工具链层呢?由图1可以看到,原大数据架构中,因产品层面单一,数据从收集入HDFS后,数据流向单一,均由Oozie调度任务从Hive获取数据,并向上推送。考虑到平台服务层面的多个产品形态,数据流向也需扩展才能满足产品所需能力,而数据流的管理与集群工作强制规划在一起,太过生硬。故全新开辟一层工具链层,通过借助集群能力,通过或使用开源或自研,来扩展数据转换与输出的能力,提供更多种的数据流形式,以满足上层数据服务需求。
对于工具链层面的设计,我们按照数据流向设计了下图中的工具链结构:

图3 大数据工具链数据流向规划
数据探索类需求
数据探索类需求,即数据查询需求,若都基于Hive采用MapReduce运算,速度上会大大影响用户的使用体验,然而即席查询AdHoc技术方面,Facebook开源的基于内存计算的Presto进入了我们的视野,考虑到Presto与Hive均为Facebook开源技术,在SQL兼容性方面通用性更强,特对Hive、Presto、Spark在SQL on Hadoop方面进行测试对比:
数据样本:2000万行数据集、7000万行数据集;
SQL样例:简单SQL(select count)、复杂SQL(线上真实SQL);
机器资源:
Hive:3台机器;
Spark:4个节点;
Presto:3个节点,每节点最大内存4G。
通过多次测试结果显示,在处理速度方面,Presto < Spark SQL < Hive,大部分情况下,Presto时间开销上远少于Hive SQL,速度优势稍微好于Spark SQL。考虑到公司内探索性数据查询需求由人发起,数量可控,Presto技术选型完全满足我们对响应速度的要求。故采用Presto引擎搭建AdHoc平台,AdHoc的Web界面我们通过自研,除基础的数据查询功能外,实现了数据导出、转发、生成报表等功能,其中生成报表功能与调度系统打通,将数据探索工作成果进一步延伸,由AdHoc发起的调度任务,则是使用MapReduce离线运算。关于Presto UI部分,Airbnb开源的Airpal界面简洁清晰,也是不错的选择。
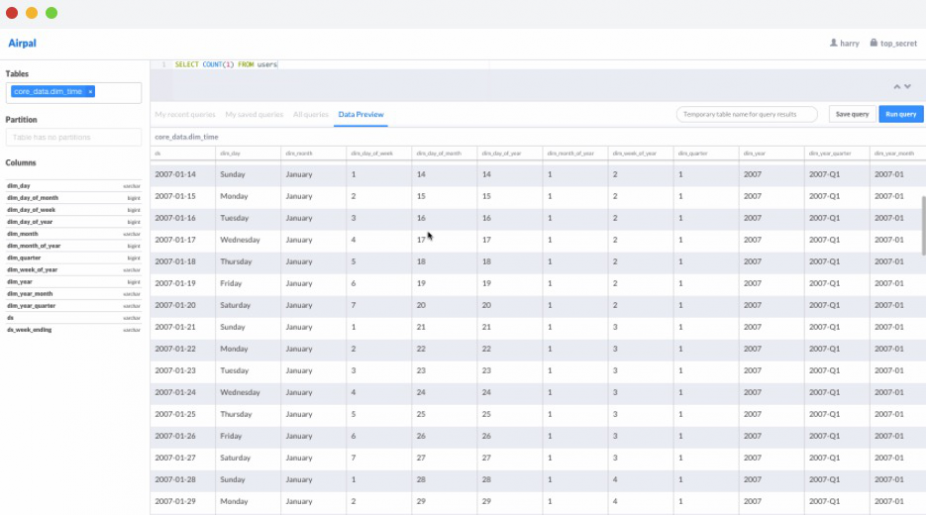
图4 Airbnb开源的基于Presto的UI界面
数据分析类需求
数据分析性需求按照工作方式细分,还可以分为非技术人员使用Web工具分析数据、技术型人员直连Hadoop集群提交分析任务两种类型。前者更多是运营、研究院、产品线数据PM等角色使用,后者则是做数据挖掘、推荐的工程师们在使用,对于工程师们,我们内网开放集群运算能力,供工程师们提交任务,通过集群中的资源隔离保障大家的任务高效运行。工具链中,则更关注前者的分析类场景,如何方便地满足。
非技术人员的数据分析需求,相对于比较固话的数据报表型需求,指标、维度的组合上希望灵活性更高,并且有着下钻、上卷分析数据的需求,更多维的查询数据。因为分析工作一般是连续查询数据,所以对于查询速度也有一定的期望。
鉴于此,我们考虑通过预置数据的方式,通过空间换时间,来解决查询速度问题。对于多维查询需求,我们考虑通过构建多维Cube方案解决。这正是MOLAP解决数据查询问题的方式,而MOLAP方案的有限技术选型中,我们更看好Apache Kylin项目。
Apache Kylin项目的一些特性,匹配我们的数据需求以及我们当时的现状。数据需求已经梳理清晰,要快、要多维查询,Kylin项目对于已创建了Cube并构建好数据的数据集上,提供亚秒级的快速查询。并且Kylin还提供工具方便构建Cube、提供API方便对接上游BI产品。另一方面我们当时的现状是,海量数据库方面我们拥有稳定且调优过的HBase集群,这恰巧是Apache Kylin所依赖的数据库选型。综合这些情况,我们通过调研Kylin系统自身能力、Kylin与Sarku的对接情况,以及有Apache Kylin研发团队成员现场交流,逐步启动了基于Kylin的MOLAP引擎构建。预计不久我们将以Kylin为基础,为BI产品、数据API两项数据平台服务提供数据查询能力,以满足公司内的多维数据分析需求。
通过MOLAP建设,与原有地动仪ROLAP相辅相成,面向公司内有数据分析诉求的同事,提供更全面的数据分析平台。
调度系统
调度系统,是大数据工具链的核心环节,乃至是大数据平台化的基础。数据ETL任务完全基于任务调度在有计划地执行,数据任务的关系、数据血缘也需要基于调度系统的能力来自动化构建。
在链家网大数据平台建设之初,最先对原有的Oozie调度系统进行调研分析,发现Oozie与Hadoop集群绑定太过紧密,任务间的状态传递必须依赖HDFS中的文件状态来传递任务状态,这导致一些数据任务需要我们用Hack的手段处理,例如我们的任务是定时“先将Hive数据导到MySQL,再运行一个远程服务器脚本对MySQL统计数据,再将脚本统计的结果发送到xxx@lianjia.com邮箱”,这样的需求,整个过程没有产生HDFS文件的必要,但在使用Oozie时,我们不得不在每一步执行完后在HDFS中创建文件以便传递信息。
我们已经可预见未来数据任务需求会有所增加,随之而来的数据任务种类也将会扩充,若不做调度系统上的改变,大数据平台的数据任务能力,将会受限于Oozie的使用场景,这与平台设计理念不符,工具应当更好的支持平台建设,而非阻碍平台发展。所以在那时,我们决定自研大数据调度系统,在参考了行业内一些调度系统解决方案的同时,我们梳理了现有的任务种类与可能的未来需求,逐步排期的实现调度系统必须的两大环节:调度环节、执行环节,并且抽象的设计了他们之间的传输协议,为未来扩展新型执行单元提供了可能。
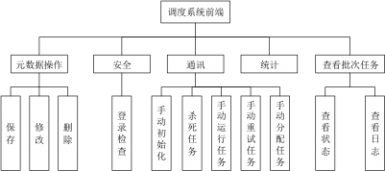
图5 调度系统前端功能
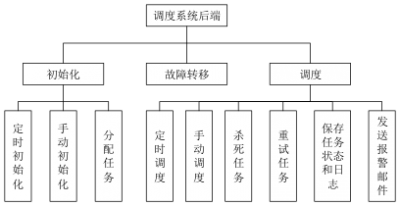
图6 调度系统后端能力
工具链作为数据驱动纽带,工具化的为上层平台服务提供各类能力,上层平台服务包装大数据平台能力,开放给用户使用。围绕着工具链的建设,大数据平台较改造前的数据加工模式,提供了更丰富的上层数据服务。通过Apache Kylin技术构建MOLAP引擎,与原有的ROLAP引擎相辅相成,搭配基于Presto的AdHoc服务,提供了一站式的快速数据查询、分析平台,并且提供了统一的大数据API,为公司各业务线、数据分析团队、数据应用方提供高可用稳定的数据格式化出口。随着调度系统的逐渐成熟,工具链层面的建设逐渐完善,平台化的大数据服务,整体较从前有全面的改善。链家网的大数据工作逐渐从报表阶段,步入了平台化自助服务的阶段。
技术挑战
当然,在建设大数据工具链的过程中,依然还有不少技术问题需要攻坚。例如Presto中还未完全兼容Hive SQL语法,需要涉及到Presto SQL解析器部分的调整工作,又例如Kylin如何能够根据指标系统中的指标自动构建Cube,需要考虑打通指标系统与Kylin系统,或通过自动化的程序来避免数据开发人员的重复操作。工具链中的技术挑战还有不少,但我们清晰的发展路线,让我们有坚定的信心去逐个攻克,也欢迎有志之士加入,一同建设链家网大数据平台。
大数据平台的规划
目前大数据工具链的技术问题,在陆续解决的同时,我们的平台服务、集群、数据管理相关的工作也都在紧锣密鼓的进行中。整体大数据平台长线的一些工作,也在逐渐规划着,例如自动化构建数据血缘、调度系统中任务DAG实时关系图、MOLAP与ROLAP的融合、数据API的全自助服务等技术问题。相信未来半年到一年的大数据平台发展过程中,在将平台服务包装的更为优秀的同时,将会积累更多实用的技术沉淀,促成公司、团队、个人共同成长与进步。
在建设链家网大数据平台期间,我们与百度、美团、滴滴和Kyligence有着良好的沟通交流,他们在大数据平台上的沉淀与经验在平台设计规划阶段,对我们的帮助很大,我们也将会在建设链家网大数据平台的同时,通过技术分享的方式与行业内大数据相关的朋友分享交流,帮助营造行业内大数据领域共同进步的良好氛围。
订阅2017年程序员(含iOS、Android及印刷版)请访问 http://dingyue.programmer.com.cn

【订阅咨询】QQ:2251809102 电话:010-64351436

想了解更多大数据相关资讯?立即扫码关注吧。

61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1