一 : 特定人语音识别芯片
盛矽电子是专业从事方案与技术服务的提供商。专注于语音识别、智能玩具、儿童电脑、语音芯片等领域。盛矽电子由年轻有为、高学历、有多年工作经验的员工组成,踏实敬业,技术实力雄厚。成功的服务于消费类电子、玩具、礼品、仪器等行业,为客户提供高附加值的产品方案与技术支持。
盛矽电子以技术为先导,把计算机技术,智能技术,自控技术等移植到玩具产品中,使玩具有智能的芯。
您的产品如果选择了盛矽电子的语音识别(注1)产品线,就立即升级为能听懂人命令智能产品,能与人进行交互式对话,提升了产品附价值,为客户创造更多利润。
盛矽电子的高品质语音级、音乐级的放音·录音(自有算法)产品线,硬件资源丰富,质优价廉,可以应用于各种需要语音产品中。
盛矽电子推出提升开发效率的软件虚拟机(注2)的录音放音芯片。芯片集成了专业的语音算法和简单实用的接口平台;Flash存储技术,简单、高效、灵活、便捷、低风险。
盛矽电子在儿童电脑,智能算法方向有着独到的技术优势,俱有先进自主产权算法,已经成功向多家知名厂商提供方案级、机芯级的产品。
盛矽电子重磅推出业界第一款专门为智能玩具设计的可编程玩具操作系统Semroid Toy OptionSystem(盛卓玩具操作系统),独特的开放平台,接口丰富多样,适合玩具种类丰富,用户可以把自己的玩法编程,实现新功能和新玩法,使单纯玩具具备创造力。
盛矽电子甘做您的研发部门,完整的技术研发体系能为客户量身定制个性化产品,为客户创造更大价值。
更多信息请访问:www.semxi.com或电话、E-mail咨询。盛矽电子科技遵循客户为本的服务理念,务实、高效的工作作风,竭诚为您服务!
注1:语音识别,也叫语音辨识,是机器能听懂人语言的技术,被视为本世纪最有挑战性、最具市场前景的应用技术之一。在玩具领域,该技术最具有交互娱乐性。注2:软件虚拟机,技术类似于Java虚拟机,采用软件封装了技术;避免了专业的汇编指令难学的C指令及语音算法、电机控制等知识。
语音识别技术就是让机器通过识别把语音信号转变为命令的技术,也就是语言命令控制,它和人类语言交流一样,作为一种命令交互方式。在PC领域,Microsoft的Word软件就有语音识别技术,但我们的语音识别芯片SR1501与PC相比,具有自己的特点。首先,它是一个完整的语音识别系统,除了识别外还具备语音提示及语音回放等功能。其次,嵌入式语音识别系统具有体积小,可靠性高,功耗低,价格低,易于商品化。嵌入式语音识别系统的特点使得其应用领域十分广泛,不仅可以做玩具、礼品、学习机、消费类产品控制。由于语音识别的特点,不建议使用要求可靠性极高的领域。
嵌入式语音识别系统都采用了模式匹配的原理。录入的语音信号首先经过预处理,包括语音信号的采样、反混叠滤波、语音增强,接下来是特征提取,用以从语音信号波形中提取一组或几组能够描述语音信号特征的参数。特征提取之后的数据一般分为两个步骤,第一步是系统“学习”或“训练”阶段,这一阶段的任务是构建参考模式库,词表中每个词对应一个参考模式,它由这个词重复发音多遍,再经特征提取和某种训练中得到。第二是“识别”或“测试”阶段,按照一定的准则求取待测语音特征参数和语音信息与模式库中相应模板之间的失真测度,最匹配的就是识别结果。
对于嵌入式系统而言,语音识别硬件组成要考虑很多其它因素,首先由于成本的限制,一般使用定点DSP,这意味着算法的复杂度受到限制;其次,对产品化有各种严格的限制,这就需要一个高度集成的硬件DSP,因此最理想的硬件组成是系统级的芯片。
我公司采用的是一个16位结构的微控制器,将MCU、A/D、D/A、RAM、ROM集成在一块芯片上,具有很高的集成度。同时具有较高运算速度的16×16位的乘法语音和内积运算指令,CPU最高可达时钟49MHz,因此在复杂的数字信号处理方面既非常便利又比专用的DSP芯片便宜得多。并具有12位ADC,和12位DAC保证音频精度,配置带自动增益控制(AGC)的麦克风输入方式,为语音处理带来了极大的方便。既具有体积小、集成度高、可靠性好的特点,又具有较强的中断处理能力、高性能的价格比和功能强、效率高的指令系统及低功耗、低电压的特点,所以非常适合用于嵌入式语音识别系统。
以SR1501为核心的嵌入式语音识别系统硬件的电路系统,主要包括麦克风输入电路、ADC、DAC、功放输出电路、键盘电路和各种通信电路等,语音和特征库保存到SPIFlash存储器中。
SR1501特定人识别要经过语音训练后才能识别,将语音训练过程中建立的参考模式库和从待识别语音信号中提取的特征参数都存放在外扩的SPIFlash中,这样就可以保证掉电后重新开机继续识别。语音识别系统软件主程序由语音训练程序、语音识别程序、语音播放程序、中断程序、初始化程序等子程序组成。由于嵌入式平台存储资源少、实时性要求高的特点,因此算法在保证识别效果的前提下要尽可能优化。
软件包括A/D变换、预加重、分帧和加窗、端点检测、特征参数提取、放宽端点限制的DTW算法,最后识别结果输出。
SR1501识别速度快,识别率高,抗干扰能力强,识别率最好可以达到98%以上。体积小,使用灵活,系统价格低廉,可移植性好。目前已成功应用于多类产品中。
二 : 语音识别芯片:语音识别芯片-简介,语音识别芯片-语音识别芯片分类
语音识别_语音识别芯片 -简单介绍
[www.61k.com)语音识别芯片也叫语音识别IC,与传统的语音芯片相比,语音识别芯片最大的特点就是能够语音识别,它能让机器听懂人类的语音,并且可以根据命令执行各种动作,如眨眼睛、动嘴巴(智能娃娃)。除此之外,语音识别芯片还具有高品质、高压缩率录音放音功能,可实现人机对话。
语音识别芯片所涉及的技术包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
 语音识别控制系统结构图
语音识别控制系统结构图语音识别_语音识别芯片 -语音识别芯片分类
按照使用者的限制而言,语音识别芯片可以分为特定人语音识别芯片和非特定人语音识别芯片。
特定人语音识别特定人语音识别芯片是针对指定人的语音识别,其他人的话玩具不识别,须先把使用者的语音参考样本存入当成比对的资料库,即特定人语音识别在使用前必须要进行语音训练,一般按照机器提示训练2遍语音词条就可以使用。
非特定人语音识别非特定人语音识别是不用针对指定的人的识别技术,不分年龄、性别,只要说相同语言即可,应用模式是在产品定型前按照确定的十几个语音交互词条,采集200人左右的声音样本,经过PC算法处理得到交互词条的语音模型和特征数据库,然后烧录到芯片上。应用这种芯片的机器(智能娃娃、电子宠物、儿童电脑)就具有交互功能了。
非特定人语音识别应用有的是基于音素的算法,这种模式下不需要采集很多人的声音样本即可做交互识别,但是缺点是识别率不高,识别性能不稳定。
按照说话方式的连续性,语音识别芯片又可分为非连续语音识别和连续语音识别。
对于非连续语音来说,识别所说的每1个字必须分开辨认,要求说完每个字后都要停顿。
连续语音识别连续语音识别可以一般自然流利的说话方式来进行人性化的语音识别,但由于关系到相连音的问题,很难达到好的辨认效果。
语音识别_语音识别芯片 -基本原理
嵌入式语音识别系统都采用了模式匹配的原理。录入的语音信号首先经过预处理,包括语音信号的采样、反混叠滤波、语音增强,接下来是特征提取,用以从语音信号波形中提取一组或几组能够描述语音信号特征的参数。特征提取之后的数据一般分为2个步骤,第1步是系统“学习”或“训练”阶段,这一阶段的任务是构建参考模式库,词表中每个词对应1个参考模式,它由这个词重复发音多遍,再经特征提取和某种训练中得到。第二是“识别”或“测试”阶段,按照一定的准则求取待测语音特征参数和语音信息与模式库中相应模板之间的失真测度,最匹配的就是识别结果。
语音识别_语音识别芯片 -语音识别系统的结构
1个完整的基于统计的语音识别系统可大致分为三部分:
(1)语音信号预处理与特征提取; (2)声学模型与模式匹配; (3)语言模型与语言处理
选择识别单元是语音识别研究的第1步。语音识别单元有单词(句)、音节和音素3种,具体选择哪1种,由具体的研究任务决定。
单词(句)单元广泛应用于中小词汇语音识别系统,但不宜大词汇系统,原因在于模型库太庞大,训练模型任务繁重,模型匹配算法复杂,难以满足实时性要求。
音节单元多见于汉语语音识别,主要因为汉语是单音节结构的语言,而英语是多音节,并且汉语虽然有大约1300个音节,但若不考虑声调,约有40八个无调音节,数量相对较少。因此,对于中、大词汇量汉语语音识别系统来说,以音节为识别单元基本是可行的。
音素单元以前多见于英语语音识别的研究中,但目前中、大词汇量汉语语音识别系统也在越来越多地采用。原因在于汉语音节仅由声母(包括零声母有二十二个)和韵母(共有二十八个)构成,且声韵母声学特性相差很大。实际应用中常把声母依后续韵母的不同而构成细化声母,这样虽然增加了模型数目,但提高了易混淆音节的区分能力。由于协同发音的影响,音素单元不稳定,所以如何获得稳定的音素单元,还有待研究。 语音识别1个根本的问题是合理的选用特征。特征参数提取的目的是对语音信号进行分析处理,去掉与语音识别无关的冗余信息,获得影响语音识别的重要信息,同时对语音信号进行压缩。在实际应用中,语音信号的压缩率介于10-100之间。语音信号包含了大量各种不同的信息,提取哪些信息,用哪种方式提取,需要综合考虑各方面的因素,如成本,性能,响应时间,计算量等。非特定人语音识别系统一般侧重提取反映语义的特征参数,尽量去除说话人的个人信息;而特定人语音识别系统则希望在提取反映语义的特征参数的同时,尽量也包含说话人的个人信息。
线性预测(LP)分析技术是目前应用广泛的特征参数提取技术,许多成功的应用系统都采用基于LP技术提取的倒谱参数。但线性预测模型是纯数学模型,没有考虑人类听觉系统对语音的处理特点。
Mel参数和基于感知线性预测(PLP)分析提取的感知线性预测倒谱,在一定程度上模拟了人耳对语音的处理特点,应用了人耳听觉感知方面的一些研究成果。实验证明,采用这种技术,语音识别系统的性能有一定提高。从目前使用的情况来看,梅尔刻度式倒频谱参数已逐渐取代原本常用的线性预测编码导出的倒频谱参数,原因是它考虑了人类发声与接收声音的特性,具有更好的鲁棒性(Robustness)。
也有研究者尝试把小波分析技术应用于特征提取,但目前性能难以与上述技术相比,有待进1步研究。
声学模型通常是将获取的语音特征使用训练算法进行训练后产生。在识别时将输入的语音特征同声学模型(模式)进行匹配与比较,得到最佳的识别结果。
声学模型是识别系统的底层模型,并且是语音识别系统中最关键的一部分。声学模型的目的是提供1种有效的方法计算语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。声学模型单元大小(字发音模型、半音节模型或音素模型)对语音训练数据量大小、系统识别率,以及灵活性有较大的影响。必须根据不同语言的特点、识别系统词汇量的大小决定识别单元的大小。
以汉语为例:
汉语按音素的发音特征分类分为辅音、单元音、复元音、复鼻尾音4种,按音节结构分类为声母和韵母。并且由音素构成声母或韵母。有时,将含有声调的韵母称为调母。由单个调母或由声母与调母拼音成为音节。汉语的1个音节就是汉语1个字的音,即音节字。由音节字构成词,最后再由词构成句子。
汉语声母共有二十二个,其中包括零声母,韵母共有3八个。按音素分类,汉语辅音共有二十二个,单元音十三个,复元音十三个,复鼻尾音十六个。
目前常用的声学模型基元为声韵母、音节或词,根据实现目的不同来选取不同的基元。汉语加上语气词共有4十二个音节,包括轻音字,共有128两个有调音节字,所以当在小词汇表孤立词语音识别时常选用词作为基元,在大词汇表语音识别时常采用音节或声韵母建模,而在连续语音识别时,由于协同发音的影响,常采用声韵母建模。
基于统计的语音识别模型常用的就是H美眉模型λ(N,M,π,A,B),涉及到H美眉模型的相关理论包括模型的结构选取、模型的初始化、模型参数的重估以及相应的识别算法等。
语言模型包括由识别语音命令构成的语法网络或由统计方法构成的语言模型,语言处理可以进行语法、语义分析。
语言模型对中、大词汇量的语音识别系统特别重要。当分类发生错误时可以根据语言学模型、语法结构、语义学进行判断纠正,特别是一些同音字则必须通过上下文结构才能确定词义。语言学理论包括语义结构、语法规则、语言的数学描述模型等有关方面。目前比较成功的语言模型通常是采用统计语法的语言模型与基于规则语法结构命令语言模型。语法结构可以限定不同词之间的相互连接关系,减少了识别系统的搜索空间,这有利于提高系统的识别。
语音识别_语音识别芯片 -语音识别系统设计
系统硬件设计对于嵌入式系统而言,语音识别硬件组成要考虑很多其它因素,首先由于成本的限制,一般使用定点DSP,这意味着算法的复杂度受到限制;其次,对产品化有各种严格的限制,这就需要1个高度集成的硬件DSP,因此最理想的硬件组成是系统级的芯片。
一般采用的是1个16位结构的微控制器,将MCU、A/D、D/A、RAM、ROM集成在一块芯片上,具有很高的集成度。同时具有较高运算速度的16×16位的乘法语音和内积运算指令,CPU最高可达时钟49MHz,因此在复杂的数字信号处理方面既非常便利又比专用的DSP芯片便宜得多。并具有12位ADC,和14位DAC保证音频精度,配置带自动增益控制(AGC)的麦克风输入方式,为语音处理带来了极大的方便。既具有体积小、集成度高、可靠性好的特点,又具有较强的中断处理能力、高性能的价格比和功能强、效率高的指令系统及低功耗、低电压的特点,所以非常适合用于嵌入式语音识别系统。
以SR160X为核心的嵌入式语音识别系统硬件的电路系统,主要包括麦克风输入电路、ADC、DAC、功放输出电路、键盘电路和各种通信电路等,语音保存到SPI Flash存储器中。
非特定人语音识别要经过语音训练后才能识别,将语音训练过程中建立的参考模式库和从待识别语音信号中提取的特征参数都存放在外扩的SPI Flash中,这样即可保证掉电后重新开机继续识别。语音识别系统软件主程序由语音训练程序、语音识别程序、语音播放程序、中断程序、初始化程序等子程序组成。由于嵌入式平台存储资源少、实时性要求高的特点,因此算法在保证识别效果的前提下要尽可能优化。
软件包括A/D变换、预加重、分帧和加窗、端点检测、特征参数提取、放宽端点限制的DTW算法,最后识别结果输出。
在应用层软件考虑到用户的实际需求,增加了能快速开发的虚拟软件开发技术,能快速完成产品。
三 : 语音识别芯片介绍

WT7010语音识别芯片
1. WT7010语音识别芯片概述
WT7010语音芯片内建8bit DSP核心,它能提供高分辨率ADC模拟采样和高质量的差分音频输入及麦克风输入,配备数学处理器以精确处理高压缩语音编解码或语音识别。该芯片有NAND接口和SPI总线用于外部存储器,提供2线串口用于连接其它设备或MCU。语音输入方面配备差分放大器用以麦克风输入以及AGC(自动增益控制)以便提供更好的SNR(信噪比)语音信号输入。芯片不单止嵌入前置放大也提供高品质的DAC和AB类扬声器放大器可以驱动输出高品质的声音。
2. WT7010功能特性
(1)内置8bitDSP核心,内部操作频率最高达48MHz(典型值:40MHz);
(2)内置麦克风差分前置放大器,包括AGC功能,16级增益控制功能;
(3)最长可记录10秒语音;
(4)内置8欧姆/0.5瓦电路,可直接驱喇叭或蜂鸣器,拥有16级音量控制,PWM音频输出方式;
(5)低电压复位功能(LVR);
(6)内建看门狗(WDT);
(7)具有24 I/O;
(8)内建有NAND-Flash接口及SPI主从总线接口;
(9)数字部分工作电压:2.4V ~ 3.6V;模拟部分工作电压2.4V~4.5V;
(10)休眠电流 <3.0uA
WT7010语音识别芯片为广州唯创新研发特定语音识别芯片,还有未尽的各项其他功能正在加紧研发中,有需求时可接受定制。
3. 应用举例
在语音ic应用范围上,特定语音识别可以做简短语音识别系统,体现个性化服务,如: ? 语音电子锁;
? 智能家居开关,如WT系列智能语音识别开关;
? 特定报警器、家庭防盗报警器;
? 高级玩具,如鹦鹉学舌、TOM汤姆猫
4. 应用电路示例
(1)特定人语音识别(学习型)
特定人语音识别(学习型),是指预先对说话人进行语音输入,由语音识别芯片进行特征提取,然后进行存储。当语音输入时,语音芯片会将输入的声音特征和参考模块库内的特征进行匹配,匹配成功则输出成功值。
(a)示例电路

(b)操作说明
示例的设计使用WT7010语音识别芯片,外挂SPI-Flash作为数据存储,其中采集模型数量:3个(相当于可识别3个词),模型对应的应答音有3个(相当于至多可3个语音输出)。
语音识别芯片可设计为2种模式:
Play模式(对话模式),平时使用此模式,适用于家里/办公室等比较安静环境,对距离看:20cm-1m保持40-50cm使用效果最佳
Try Me模式(演示模式),适用于商场/展览馆等比较吵杂的环境,对话距离:1cm-10cm,保持1-3cm使用效果最佳。
开机语音播放:欢迎使用特定语音识别系统
采集键:长按“采集”键2秒;系统开始进行指令采集,每一条指令要说两遍 采集完毕自动结束,可采集3个词组,如:
长按“采集”键,系统播放提示音“请在嘀一声后采集模型,请采集两遍模型1”
客户对着麦克风说:“你好”,系统提示“请再采集一次”,客户对着麦克风再说一次:“你好”
系统提示:“请采集两遍模型2”,
客户对着麦克风说:“启动汽车”,系统提示“请再采集一次”,客户对着麦克风再说一次:“启动汽车”
??
系统提示“采集完毕”,这时,系统自动进入识别状态。
当用户说“你好”,系统识别正确的话会回答“声音1” 用户说“启动汽车”,系统识别正确的话会回答“声音2” 复位键:系统重新启动
四 : 语音识别芯片:语音识别芯片-简介,语音识别芯片-语音识别芯片分类
语音识别芯片_语音识别芯片 -简单介绍
[www.61k.com)语音识别芯片也叫语音识别IC,与传统的语音芯片相比,语音识别芯片最大的特点就是能够语音识别,它能让机器听懂人类的语音,并且可以根据命令执行各种动作,如眨眼睛、动嘴巴(智能娃娃)。除此之外,语音识别芯片还具有高品质、高压缩率录音放音功能,可实现人机对话。
语音识别芯片所涉及的技术包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
 语音识别控制系统结构图
语音识别控制系统结构图语音识别芯片_语音识别芯片 -语音识别芯片分类
按照使用者的限制而言,语音识别芯片可以分为特定人语音识别芯片和非特定人语音识别芯片。
特定人语音识别特定人语音识别芯片是针对指定人的语音识别,其他人的话玩具不识别,须先把使用者的语音参考样本存入当成比对的资料库,即特定人语音识别在使用前必须要进行语音训练,一般按照机器提示训练2遍语音词条就可以使用。
非特定人语音识别非特定人语音识别是不用针对指定的人的识别技术,不分年龄、性别,只要说相同语言即可,应用模式是在产品定型前按照确定的十几个语音交互词条,采集200人左右的声音样本,经过PC算法处理得到交互词条的语音模型和特征数据库,然后烧录到芯片上。应用这种芯片的机器(智能娃娃、电子宠物、儿童电脑)就具有交互功能了。
非特定人语音识别应用有的是基于音素的算法,这种模式下不需要采集很多人的声音样本即可做交互识别,但是缺点是识别率不高,识别性能不稳定。
按照说话方式的连续性,语音识别芯片又可分为非连续语音识别和连续语音识别。
对于非连续语音来说,识别所说的每1个字必须分开辨认,要求说完每个字后都要停顿。
连续语音识别连续语音识别可以一般自然流利的说话方式来进行人性化的语音识别,但由于关系到相连音的问题,很难达到好的辨认效果。
语音识别芯片_语音识别芯片 -基本原理
嵌入式语音识别系统都采用了模式匹配的原理。录入的语音信号首先经过预处理,包括语音信号的采样、反混叠滤波、语音增强,接下来是特征提取,用以从语音信号波形中提取一组或几组能够描述语音信号特征的参数。特征提取之后的数据一般分为2个步骤,第1步是系统“学习”或“训练”阶段,这一阶段的任务是构建参考模式库,词表中每个词对应1个参考模式,它由这个词重复发音多遍,再经特征提取和某种训练中得到。第二是“识别”或“测试”阶段,按照一定的准则求取待测语音特征参数和语音信息与模式库中相应模板之间的失真测度,最匹配的就是识别结果。
语音识别芯片_语音识别芯片 -语音识别系统的结构
1个完整的基于统计的语音识别系统可大致分为三部分:
(1)语音信号预处理与特征提取; (2)声学模型与模式匹配; (3)语言模型与语言处理
选择识别单元是语音识别研究的第1步。语音识别单元有单词(句)、音节和音素3种,具体选择哪1种,由具体的研究任务决定。
单词(句)单元广泛应用于中小词汇语音识别系统,但不宜大词汇系统,原因在于模型库太庞大,训练模型任务繁重,模型匹配算法复杂,难以满足实时性要求。
音节单元多见于汉语语音识别,主要因为汉语是单音节结构的语言,而英语是多音节,并且汉语虽然有大约1300个音节,但若不考虑声调,约有40八个无调音节,数量相对较少。因此,对于中、大词汇量汉语语音识别系统来说,以音节为识别单元基本是可行的。
音素单元以前多见于英语语音识别的研究中,但目前中、大词汇量汉语语音识别系统也在越来越多地采用。原因在于汉语音节仅由声母(包括零声母有二十二个)和韵母(共有二十八个)构成,且声韵母声学特性相差很大。实际应用中常把声母依后续韵母的不同而构成细化声母,这样虽然增加了模型数目,但提高了易混淆音节的区分能力。由于协同发音的影响,音素单元不稳定,所以如何获得稳定的音素单元,还有待研究。 语音识别1个根本的问题是合理的选用特征。特征参数提取的目的是对语音信号进行分析处理,去掉与语音识别无关的冗余信息,获得影响语音识别的重要信息,同时对语音信号进行压缩。在实际应用中,语音信号的压缩率介于10-100之间。语音信号包含了大量各种不同的信息,提取哪些信息,用哪种方式提取,需要综合考虑各方面的因素,如成本,性能,响应时间,计算量等。非特定人语音识别系统一般侧重提取反映语义的特征参数,尽量去除说话人的个人信息;而特定人语音识别系统则希望在提取反映语义的特征参数的同时,尽量也包含说话人的个人信息。
线性预测(LP)分析技术是目前应用广泛的特征参数提取技术,许多成功的应用系统都采用基于LP技术提取的倒谱参数。但线性预测模型是纯数学模型,没有考虑人类听觉系统对语音的处理特点。
Mel参数和基于感知线性预测(PLP)分析提取的感知线性预测倒谱,在一定程度上模拟了人耳对语音的处理特点,应用了人耳听觉感知方面的一些研究成果。实验证明,采用这种技术,语音识别系统的性能有一定提高。从目前使用的情况来看,梅尔刻度式倒频谱参数已逐渐取代原本常用的线性预测编码导出的倒频谱参数,原因是它考虑了人类发声与接收声音的特性,具有更好的鲁棒性(Robustness)。
也有研究者尝试把小波分析技术应用于特征提取,但目前性能难以与上述技术相比,有待进1步研究。
声学模型通常是将获取的语音特征使用训练算法进行训练后产生。在识别时将输入的语音特征同声学模型(模式)进行匹配与比较,得到最佳的识别结果。
声学模型是识别系统的底层模型,并且是语音识别系统中最关键的一部分。声学模型的目的是提供1种有效的方法计算语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。声学模型单元大小(字发音模型、半音节模型或音素模型)对语音训练数据量大小、系统识别率,以及灵活性有较大的影响。必须根据不同语言的特点、识别系统词汇量的大小决定识别单元的大小。
以汉语为例:
汉语按音素的发音特征分类分为辅音、单元音、复元音、复鼻尾音4种,按音节结构分类为声母和韵母。并且由音素构成声母或韵母。有时,将含有声调的韵母称为调母。由单个调母或由声母与调母拼音成为音节。汉语的1个音节就是汉语1个字的音,即音节字。由音节字构成词,最后再由词构成句子。
汉语声母共有二十二个,其中包括零声母,韵母共有3八个。按音素分类,汉语辅音共有二十二个,单元音十三个,复元音十三个,复鼻尾音十六个。
目前常用的声学模型基元为声韵母、音节或词,根据实现目的不同来选取不同的基元。汉语加上语气词共有4十二个音节,包括轻音字,共有128两个有调音节字,所以当在小词汇表孤立词语音识别时常选用词作为基元,在大词汇表语音识别时常采用音节或声韵母建模,而在连续语音识别时,由于协同发音的影响,常采用声韵母建模。
基于统计的语音识别模型常用的就是H美眉模型λ(N,M,π,A,B),涉及到H美眉模型的相关理论包括模型的结构选取、模型的初始化、模型参数的重估以及相应的识别算法等。
语言模型包括由识别语音命令构成的语法网络或由统计方法构成的语言模型,语言处理可以进行语法、语义分析。
语言模型对中、大词汇量的语音识别系统特别重要。当分类发生错误时可以根据语言学模型、语法结构、语义学进行判断纠正,特别是一些同音字则必须通过上下文结构才能确定词义。语言学理论包括语义结构、语法规则、语言的数学描述模型等有关方面。目前比较成功的语言模型通常是采用统计语法的语言模型与基于规则语法结构命令语言模型。语法结构可以限定不同词之间的相互连接关系,减少了识别系统的搜索空间,这有利于提高系统的识别。
语音识别芯片_语音识别芯片 -语音识别系统设计
系统硬件设计对于嵌入式系统而言,语音识别硬件组成要考虑很多其它因素,首先由于成本的限制,一般使用定点DSP,这意味着算法的复杂度受到限制;其次,对产品化有各种严格的限制,这就需要1个高度集成的硬件DSP,因此最理想的硬件组成是系统级的芯片。
一般采用的是1个16位结构的微控制器,将MCU、A/D、D/A、RAM、ROM集成在一块芯片上,具有很高的集成度。同时具有较高运算速度的16×16位的乘法语音和内积运算指令,CPU最高可达时钟49MHz,因此在复杂的数字信号处理方面既非常便利又比专用的DSP芯片便宜得多。并具有12位ADC,和14位DAC保证音频精度,配置带自动增益控制(AGC)的麦克风输入方式,为语音处理带来了极大的方便。既具有体积小、集成度高、可靠性好的特点,又具有较强的中断处理能力、高性能的价格比和功能强、效率高的指令系统及低功耗、低电压的特点,所以非常适合用于嵌入式语音识别系统。
以SR160X为核心的嵌入式语音识别系统硬件的电路系统,主要包括麦克风输入电路、ADC、DAC、功放输出电路、键盘电路和各种通信电路等,语音保存到SPI Flash存储器中。
非特定人语音识别要经过语音训练后才能识别,将语音训练过程中建立的参考模式库和从待识别语音信号中提取的特征参数都存放在外扩的SPI Flash中,这样即可保证掉电后重新开机继续识别。语音识别系统软件主程序由语音训练程序、语音识别程序、语音播放程序、中断程序、初始化程序等子程序组成。由于嵌入式平台存储资源少、实时性要求高的特点,因此算法在保证识别效果的前提下要尽可能优化。
软件包括A/D变换、预加重、分帧和加窗、端点检测、特征参数提取、放宽端点限制的DTW算法,最后识别结果输出。
在应用层软件考虑到用户的实际需求,增加了能快速开发的虚拟软件开发技术,能快速完成产品。
五 : 语音识别芯片介绍

WT7010语音识别芯片
1. WT7010语音识别芯片概述
WT7010语音芯片内建8bit DSP核心,它能提供高分辨率ADC模拟采样和高质量的差分音频输入及麦克风输入,配备数学处理器以精确处理高压缩语音编解码或语音识别。[www.61k.com)该芯片有NAND接口和SPI总线用于外部存储器,提供2线串口用于连接其它设备或MCU。语音输入方面配备差分放大器用以麦克风输入以及AGC(自动增益控制)以便提供更好的SNR(信噪比)语音信号输入。芯片不单止嵌入前置放大也提供高品质的DAC和AB类扬声器放大器可以驱动输出高品质的声音。
2. WT7010功能特性
(1)内置8bitDSP核心,内部操作频率最高达48MHz(典型值:40MHz);
(2)内置麦克风差分前置放大器,包括AGC功能,16级增益控制功能;
(3)最长可记录10秒语音;
(4)内置8欧姆/0.5瓦电路,可直接驱喇叭或蜂鸣器,拥有16级音量控制,PWM音频输出方式;
(5)低电压复位功能(LVR);
(6)内建看门狗(WDT);
(7)具有24 I/O;
(8)内建有NAND-Flash接口及SPI主从总线接口;
(9)数字部分工作电压:2.4V ~ 3.6V;模拟部分工作电压2.4V~4.5V;
(10)休眠电流 <3.0uA
WT7010语音识别芯片为广州唯创新研发特定语音识别芯片,还有未尽的各项其他功能正在加紧研发中,有需求时可接受定制。
3. 应用举例
在语音ic应用范围上,特定语音识别可以做简短语音识别系统,体现个性化服务,如: ? 语音电子锁;
? 智能家居开关,如WT系列智能语音识别开关;
? 特定报警器、家庭防盗报警器;
? 高级玩具,如鹦鹉学舌、TOM汤姆猫
4. 应用电路示例
(1)特定人语音识别(学习型)
特定人语音识别(学习型),是指预先对说话人进行语音输入,由语音识别芯片进行特征提取,然后进行存储。当语音输入时,语音芯片会将输入的声音特征和参考模块库内的特征进行匹配,匹配成功则输出成功值。
(a)示例电路
语音识别芯片 语音识别芯片介绍
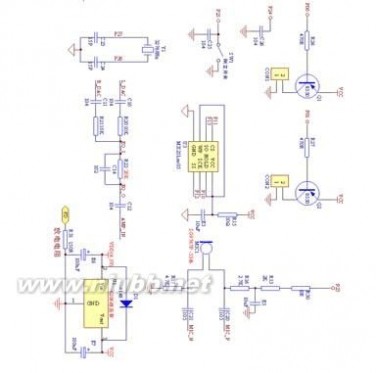
(b)操作说明
示例的设计使用WT7010语音识别芯片,外挂SPI-Flash作为数据存储,其中采集模型数量:3个(相当于可识别3个词),模型对应的应答音有3个(相当于至多可3个语音输出)。[www.61k.com]
语音识别芯片可设计为2种模式:
Play模式(对话模式),平时使用此模式,适用于家里/办公室等比较安静环境,对距离看:20cm-1m保持40-50cm使用效果最佳
Try Me模式(演示模式),适用于商场/展览馆等比较吵杂的环境,对话距离:1cm-10cm,保持1-3cm使用效果最佳。
开机语音播放:欢迎使用特定语音识别系统
采集键:长按“采集”键2秒;系统开始进行指令采集,每一条指令要说两遍 采集完毕自动结束,可采集3个词组,如:
长按“采集”键,系统播放提示音“请在嘀一声后采集模型,请采集两遍模型1”
客户对着麦克风说:“你好”,系统提示“请再采集一次”,客户对着麦克风再说一次:“你好”
系统提示:“请采集两遍模型2”,
客户对着麦克风说:“启动汽车”,系统提示“请再采集一次”,客户对着麦克风再说一次:“启动汽车”
??
系统提示“采集完毕”,这时,系统自动进入识别状态。
语音识别芯片 语音识别芯片介绍
当用户说“你好”,系统识别正确的话会回答“声音1” 用户说“启动汽车”,系统识别正确的话会回答“声音2” 复位键:系统重新启动
本文标题:语音识别芯片-特定人语音识别芯片61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1