一 : Tagg:基于脸部识别的照片分享应用

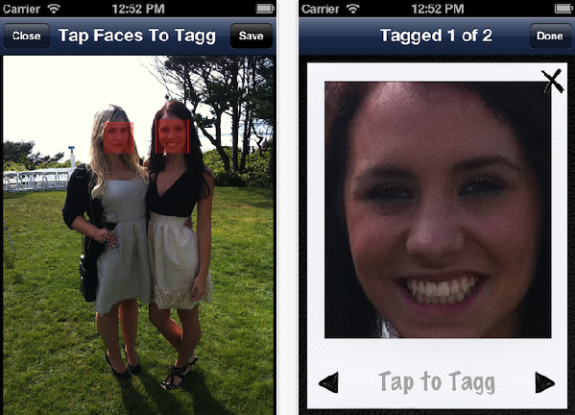
Tagg是一款利用离线脸部识别技术来检测照片人物的iPhone应用。通过该应用,用户可以对照片进行标记,将照片上传至Facebook,或在Twitter上发布。
Tagg使用十分简单。首先,通过地址簿在手机、Facebook或Twitter上添加人物条目,然后对挑选出的照片进行标记。Tagg可以自动 识别照片上的人脸,并用红色方框标出,点击方框便可开始标记。如果想用人名作为标记,无需滚动长长的联系人列表一一查找,只需打字输入,Tagg会从事先 添加的人物条目中自动过滤。或者,还可以使用iPhone的语音功能输入标记名。标记完成后,就可以在将照片在Facebook上分享,或在 Twitter上发布了。整个操作过程十分简单。
整体来说,Tagg各方面的性能都不错,但也仍存在一些小bug。与无需标记就可以自动进行人脸识别的竞争对手AutoTagger相比,Tagg不具备明显优势。当然,AutoTagger的准确性和稳定性也不是很理想。
与其他通过广告盈利的免费应用不同,Tagg售价99美分,可在iTunes购买。目前,Tagg虽然还不尽完美,但随着越来越多的bug得到修复,Tagg将会是一款很不错的应用。
Via TC
(sarah_long 供雷锋网专稿,转载请注明!)
二 : 59基于MATLAB的车牌识别系统研究(课设参考文献)
基于MATLAB的车牌识别系统研究
摘 要
近几年,车牌识别系统作为智能交通的一个重要方向越来越受到重视。车牌识别系统可以应用于停车场管理系统、高速公路超速管理系统、城市十字路口的“电子警察”、小区车辆管理系统等各个领域,对国家的安全发展有很大的作用。虽然目前已有一些车牌识别系统相关产品出现,但是对其算法的研究发展从没有停止,仍有许多学者在做着进一步的研究改进。
本文首先对车牌识别系统的现状和已有的技术进行了深入的研究,在研究的基础上开发出一个基于MATLAB的车牌识别系统。确定了整体设计方案,其中软件部分包括车牌定位、车牌字符切分及车牌字符识别三个模块。车牌定位模块中提出了基于小波变换的车牌边缘提取的算法,以及车牌二次定位的算法,提高了系统在光照条件较差的情况下的定位准确率,该算法对于各种底色的车牌具有良好的适应性;车牌的二值化采用了改进的Otus算法,重新划分了其两维直方图的区域,改进后的算法大大减少了运行时间,对于各种类型的车牌都能达到较好的二值化效果;针对BP神经网络字符识别算法,采用有动量的梯度下降法训练网络,减小了神经网络学习过程的振荡趋势,使得BP网络能够较快的达到收敛,完成车牌字符的识别。对模板匹配算法和BP网络算法进行对比,证明了BP网络算法要优于模板匹配算法。
根据上述算法搭建了一个测试平台。整个测试平台的软件部分采用MATLAB的M语言编写。通过测试平台,对353幅卡口汽车照片进行车牌识别,测试系统的性能。测试结果表明,本课题设计的车牌识别系统可有效地实现车牌识别,为今后的产品化奠定了很好的技术基础。
关键词: 车牌识别,小波变换,Otsu算法,模板匹配,BP网络,MATLAB
I
RESEARCH ON PLATE LICENSE
RECOGNITION SYSTEM BASED ON MATLAB
ABSTRACT
In recent years, the development of intelligent transportation has become more and more important. As an important aspect in intelligent transportation, plate license recognition system has taken more and more attention. The plate license recognition system can be applied to public parking, highway speeding management system, crossing road, district vehicle management system, and so on. Although now there are already some exsiting plate lecense recognition systems, the research and development of arithmetic have never stopped, and there are still many scholars who are doing further research and improvement.
Firstly, the paper gives a deep research on the status and technique of the plate license recognition system. On the basis of research, a solution of plate license recognition system is proposed, and the paper focused on the software part. The whole system concludes three modules. They are plate location, plate character segmentation, and plate character recognition. In the plate location module, the paper puts forward an arithmetic of plate edge recognition by wavelet decomposition, and an arithmetic of locating twice, which improve the accuracy in bad light condition, and are fit for plates with different grounding. An improved Otsu arithmetic is used in the process of binaryzating, which reduces the running time, and can achieve good effect for different kinds of plate. In character recognition part, with the momentum of the gradient descent method, the BP neural network can fast convergence.Compared the BP neural network with template matching arithmetic, which improves that the BP neural network are better than the template matching arithmetic.
II
Then, a test platform has been built with MATLAB, for the test of the system. Through the test of 353 monitoring car photographs, the results shows that the system can effectively meets the requirement, and lay a good foundation of technology for productization.
KEY WORDS: plate license recognition, wavelet transform, Otsu, template matching, BP neural network, MATLAB
III
图目录
图1 车牌识别系统····································································································1 图2 自选号牌车牌示例·····························································································3 图3 车辆牌照识别系统结构图···············································································10 图4 系统流程图······································································································13 图5 车牌定位的过程······························································································15 图6(a)原始汽车图像 (b)灰度图···································································16 图7 灰度变换的对比曲线·······················································································17 图8(a)灰度图 (b)灰度变换后的图像···························································17 图9(a)灰度图 (b)中值滤波后的图像···························································18 图10 小波分解树[10]································································································21 图11 小波变换的Mallat算法················································································23 图12 二维小波变换的Mallat算法········································································24 图13 车辆灰度图····································································································25 图14 X=214数据线的灰度图··················································································25 图15 用HAAR小波进行五层分解········································································26 图16 车牌图像的小波分解·····················································································27 图17小波分解提取边缘··························································································27 图18 开闭运算后的图像·························································································28 图19 车牌区域标记································································································29 图20 初步提取的车牌····························································································29 图22 平滑后的水平差分累加投影图·····································································31 图23 水平定位后的图像·························································································31 图24 平滑后的垂直差分累加投影图·····································································32 图25 精确定位后的车牌·························································································32 图26 车牌定位算法································································································33 图27 车牌字符切分流程·························································································35 图28 二维Otsu算法阈值求解示意图···································································38 图29 改进的Otsu算法阈值求解示意图·······························································40
VII
图30 改进的Otsu算法二值化实验·······································································41 图31 图像空间········································································································42 图32 Hough空间·····································································································42 图33 利用Hough变换查找倾斜角度····································································43 图34 车牌二值子图及其水平投影·········································································44 图35 坐标变换示意图····························································································46 图36 两种校正算法的比较·····················································································47 图37 字符投影图····································································································48 图38 字符切分后的效果图·····················································································49 图39 车牌字符切分算法·························································································50 图40 加权后模板与原模板·····················································································54 图41 特征提取········································································································54 图42 模板匹配字符识别流程图·············································································56 图43 BP神经网络结构示意图················································································58 图44 三层BP网络示意图······················································································58 图45 BP网络的应用过程························································································60 图46 BP算法流程···································································································63 图47 车牌识别测试系统流程·················································································65 图48 车牌识别测试系统界面·················································································67 图49 测试系统文件菜单·························································································68 图50 测试系统视频设备菜单·················································································68 图51 测试系统识别参数设置菜单·········································································69 图52 测试系统系统设置菜单·················································································70 图53 测试分析(1)······························································································71 图54 测试分析(2)······························································································72 图55 测试分析(3)······························································································73 图56 测试分析(4)······························································································73 图57 测试分析(5)······························································································74 图58 测试分析(6)······························································································75 图59 测试分析(7)······························································································76
VIII
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
上海交通大学硕士学位论文 表目录
表目录
表1 字符识别方法结果分析···················································································64 表2 车牌识别结果分析···························································································76
IX
3
1 绪论
1.1 研究背景
1990年,美国智能交通学会CITS America提出了智能交通系统(ITS)的概念。目前,智能交通系统已经在世界上经济发达国家的一些城市及高速公路系统中得到了广泛应用。我国在该领域的研究起步较晚,但随着全球范围智能交通技术研究的兴起及奥运会的成功举办,智能交通在我国也逐渐进入了应用阶段,相应的,我国也加快了对智能交通技术研究的步伐,智能交通技术的研究现已进入快速发展期。
车牌识别系统作为数字摄像、计算机信息管理、图像分割和图形识别技术在智能交通领域的应用,是智能交通管理系统中重要的组成部分。车牌识别技术可应用于道路交通监控、交通事故现场勘察、交通违章自动记录、高速公路超速管理系统、小区智能化管理等方面[1],为智能交通管理提供了高效、实用的手段。
目前世界各国都在进行适用于本国汽车牌照的自动识别研究,美、日、韩等国已有相关系统(基于传感器)问世。引进这些系统费用比较高、而且由于各国车牌和实际的交通环境不同,引进的系统往往无法满足我国城市的需求,而国内市场上虽然已有产品投入使用,但是在后续处理时很大程度上仍然需要人工识别,所以对车牌识别技术的研究依然是目前高科技领域的热门课题之一。车牌识别系统的成功设计、开发和应用具有相当大的社会效益、经济效益和学术意义。
基于图像处理的车牌识别系统一般包括以下五个部分:
图1 车牌识别系统
Figure 1 Flow chart of license plate recognition system
1
在实际应用中,车牌识别系统必须快速、准确、鲁棒地识别出车牌。因此,在车牌识别过程中,车辆的检测、图像的采集、车牌的识别等都是重要的环节,其中关键的技术有:
1)车辆牌照区域定位技术,即给出图像中车牌所在位置。
2)车辆牌照字符切分技术,即对定位后的车牌区域中的字符进行切分和归一化处理,其中车牌的二值化和倾斜校正对于字符的切分和识别都是非常重要的。
3)车辆牌照字符识别技术,即将切分后的字符识别出来。
车牌识别是一个很复杂的图像处理和模式识别问题,研究时存在很多难点,主要在于:
1)获取的车牌图像质量不高。车牌图像往往含有大量复杂的背景信息,遮盖了有用信息。很多时候受到照明条件、天气条件、及运动失真的影响,会出现图像模糊、清晰度不高、目标区域过小、色彩失真等现象,影响了车牌的定位。
2)车牌悬挂位置不唯一。在汽车的各个位置都可能出现车牌,而且不能保证车牌的水平悬挂,甚至有的车牌出现了扭曲。
3)牌照多样性。其他国家的汽车牌照格式,如尺寸大小,牌照上字符的排列等,通常只有一种。而我国则根据不同车型、用途,规定了多种牌照格式,例如分为军车、警车、普通车等。
4)我国标准车牌照是由汉字、英文字母和阿拉伯数字组成的,汉字的识别与字母和数字的识别有很大的不同,增加了识别的难度。
5)国外许多国家汽车牌照的底色和字符颜色通常只有对比度较强的两种颜色,例如韩国,其车牌底色为红色,车牌上的字符为白色;而我国汽车牌照仅底色就有蓝、黄、白、黑等多种颜色,字符颜色也有黑、红、白等若干种颜色。
6)由于环境、道路或人为因素造成汽车牌照污染严重,这种情况下国外发达国家不允许上路,而在我国仍可上路行驶。使得车牌的对比度降低,特征不是很明显,即使在定位准确的情况下,字符的识别也会受到很大影响。
目前在国内存在多种牌照格式,且存在以上种种困难和特殊性,加大了我国车
2
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
牌自动识别的难度,使得中国车辆牌照识别远远难于国外的车辆牌照识别。因而如何提高识别率和识别处理的实时性及实用性成了一个紧要的任务。图2为我国目前使用的一个自选号牌车牌样本,上面标明了车牌样式规定。
图2 自选号牌车牌示例
Figure 2 Examples of self-selected plate
1.2 车牌识别系统现状
1.2.1 国内外车辆牌照识别技术现状
目前,国内外有大量关于车牌识别方面的研究报道。国外在这方面的研究工作开展较早。在上世纪70年代,英国就在实验室中完成了“实时车牌检测系统”的广域检测和开发。同时代,诞生了面向被盗车辆的第一个实时自动车牌监测系统。发展到今日,国外对车牌检测的研究已经取得了一些令人瞩目的成就,如Yuntao Cui[2]提出了一种车牌识别系统,在车牌定位以后,利用马尔科夫场对车牌特征进行提取和二值化,对样本的识别达到了较高的识别率。Eun Ryung等[3]利用图像中的颜色分量,对车辆牌照进行定位识别,其中提到了三种方法:①以Hough变换为基础的边缘检测定位识别;②以灰度值变换为基础的识别算法;③以HLS彩色模式为基础的车牌识别系统,识别率分别为81.25%、85%、91.25%。日本对车牌图像的获取也做了大量的研究,并为系统产业化做了大量工作。Luis[4]开发的系统应用于
3
公路收费站,全天识别率达到了90%以上,即使在天气不好的情况下也达到了70%。国外对车牌识别的研究起步早,总体来讲其技术已比较领先,同时由于他们车牌种类单一,规范程度较高,易于定位识别,目前,已经实现了产品化,并在实际的交通系统中得到了广泛的应用。由于中国车牌的格式与国外有较大差异,所以国外关于识别率的报道只具有参考价值,其在中国的应用效果可能没有在其国内的应用效果好,但其识别系统中采用的很多算法具有很好的借鉴意义。
从车牌识别系统进入中国以来,国内有大量的学者在从事这方面的研究,提出了很多新颖快速的算法。中国科学院自动化所的刘智勇等[5]开发的系统在一个样本量为3180的样本集中,车牌定位准确率为99.42%,切分准确率为94.52%,这套系统后来应用于汉王公司的车牌识别系统,取得了不错的效果。南京大学的熊军等[6]提出了基于字符纹理特征的定位算法,准确率达95%。华中科技大学的陈振学等[7]学者提出了一种新的车牌图像字符分割与识别算法,使用一维循环清零法,通过对垂直投影图进行一次扫描,有效的清除了杂点和间隔符,正确分割率达到了96.8%。浙江大学的张引、潘云鹤等[8]提出了彩色边缘算子ColorPrewitt和彩色边缘检测与区域生长相结合的牌照定位算法ColorLP,算法简单,且全面作用在颜色空间的三个分量上,检测出的牌照区域易于与背景剥离。但是计算量和存储量都比较大,难以满足实时性的要求。此外,当车辆区域的颜色和附近颜色相近时,定位失误率会增加。国内还有许多学者都在进行这方面的研究,并且取得了大量的研究成果。
1.2.2 车牌识别技术的应用情况
车辆牌照自动识别技术是智能交通系统的一个重要组成部分,它在交通管理、监控中有着广泛的应用。车辆牌照识别系统技术能够从一幅车辆图像中准确定位出车牌图像,经过字符切分和识别后实现车辆牌照的自动识别,从而为以上应用提供信息和基础功能。
目前车牌识别系统主要应用于以下领域:
1)停车场管理系统。利用车牌识别技术对出入车辆的号牌进行识别和匹配,
4
与停车卡结合实现自动计时、计费的车辆收费管理系统。
2)高速公路超速自动化管理系统。以车牌自动识别技术为基础,与其他高科技手段结合,对高速公路交通流状况进行自动监测、自动布控,从而降低交通事故的复发生率,确保交通顺畅。
3)公路布控。采用车牌识别技术实现对重点车辆的自动识别,快速报警,既可以有效查找被盗车辆,同时又为公安、检察机关提供了对犯罪嫌疑人的交通工具进行远程跟踪与监查的技术手段。
4)城市十字交通路口的“电子警察”。可以对违章车辆进行责任追究,也可以辅助进行交通流量统计,交通监测和疏导。
5)小区车辆管理系统。社区保安系统将出入社区的车辆通过车牌识别技术进行记录,将结果与内部车辆列表对比可以实现防盗监管。
目前,市场上已出现了一些可应用的汽车牌照自动识别系统。如CPRS-1型汽车牌照识别系统是在国家“863”计划课题与国防图像目标识别课题相结合的研究基础上研制成功的,实现了识别汽车牌照中的数字、字母和汉字以及汽车牌照的底色(白、黑、蓝、黄四种)的功能,可以全天候工作。另一种型号GW-PR-9902T的牌照识别器系统产品,采用新型的数字图像处理和识别技术,基于嵌入式工控机/DSP和专用硬件电路,利用定向反射和自然光相结合的识别原理,实时地完成复杂情况下的汽车牌照的定位、分割以及识别。此类产品都已应用于高速公路的收费监控系统。总体上说,虽然汽车牌照识别系统在国内还未形成一个成熟的产业,但是随着我国国民经济的迅速发展,机动车辆规模及流量大幅度增加,高速公路和城市交通管理现代化水平的提高势在必行,迫切需要高科技的智能交通系统来充实和加强交通管理水平。车牌识别技术在智能交通系统中占有重要位置,车牌识别技术的推广普及,必将对加强高速公路、城市道路管理,减少交通事故、车辆被盗案件的发生,保障社会稳定等方面产生重大而深远的影响。
1.2.3 车牌识别技术的发展趋势
5
车牌识别技术作为智能交通系统中的关键技术,在各国学者的共同努力下,已经得到了长足的发展,并且已经得到了不同程度的实际应用,但目前还存在着种种不足。
对于未来车牌识别产品的技术发展趋势,汉王科技智能交通部总经理乔炬认为。首先,由于市场需求不同,对识别产品的需求也有差异,因此就要求研发针对不同细分市场的车牌识别产品。其次,随着算法的不断改进,基于视频触发技术的车牌识别产品将得到大范围的应用,但是视频触发技术取代外触发装置尚需时日。第三,现在的车牌识别系统设备过多,系统集成难度大,系统稳定性差,系统维护是一个让人头疼的问题。随着技术不断进步,以往多个设备实现的功能可能由一个设备实现。
目前,车牌识别技术和产品性能进入实用阶段的时间还不是很长,随着人工智能以及自动识别技术的进步,未来的技术发展空间还会非常大。例如,核心算法继续发展,识别率和识别速度进一步改善,图像处理中对模糊图像预处理能力增强,画质改善技术的提高等等。
1.3 本课题的研究内容
本文就车辆牌照自动识别技术进行了一系列的研究工作,在研究国内外各种典型的车牌识别方法的基础上,努力学习和创新,结合中国车牌的特点,对适合中国车牌的识别系统进行了研究。
在课题研究中作者的主要研究内容有:
1)在广泛查阅国内外车牌识别系统算法的基础上,以MATLAB的Image Acquisition Toolbox、Image Processing Toolbox以及Neural Network Toolbox工具箱为骨架,以M语言为主要编程语言,部分模块结合C语言开发了一套车牌识别系统,实现了车牌识别系统中车牌的定位、车牌字符的切分、以及车牌字符的识别的功能。
6
2)车牌边缘提取效果的好坏对于车牌能否准确定位有很大影响。已有的车牌系统大多采用传统边缘检测算子对车牌边缘进行提取,在光线不好或者图像比较模糊时效果并不是很理想。在对数字图像进行处理时,离散小波变换往往是首选的数学工具。考虑到小波变换在图像处理中有着良好的特性,而且小波变换对于噪点有着良好的抑制作用,同时分解后的高频部分的垂直分量和低频部分的水平分量非常有助于图像的细节信息的获取,本文借助MATLAB的wavemenu对小波变换进行了细致的研究和分析,采用了多分辨率分析的Mallat快速小波算法对小波变换进行了两次分解,并对小波变换在车牌边缘提取中的应用进行了研究。测试结果显示利用小波变换提取的车牌边缘特征明显,在此基础上进行形态学处理后车牌定位的准确性和鲁棒性都比较好。
3)车牌识别系统主要由车牌定位、车牌字符切分以及车牌字符识别三个部分组成。本文依次对这三个组成部分中涉及到的算法进行了研究和优化。
车牌定位中首先对车牌进行了预处理,即灰度化处理,灰度拉伸,应用中值滤波算法进行了降噪处理。之后采用了小波变换的算法提取车牌边缘,进行形态学处理后,根据车牌先验知识进行初步定位,再用投影法进行二次定位提取出了车牌。
在车牌字符切分部分主要进行了二值化、车牌倾斜校正以及字符切分的算法研究。二值化选取了改进的全局阈值Otsu算法。然后通过对Hough变换和投影特征法的对比,选取了投影特征法和坐标变换算法进行了车牌校正。根据车牌垂直投影图显现出的多个集中峰群的特点,进行了车牌字符切分。
在最后部分,对主流的模板匹配字符识别和BP神经网络字符识别的算法分别进行了研究与改进。最后将两种算法进行了对比分析,可以看出,改进的BP网络的算法特性要远优于模板匹配算法,更适于系统的实际应用。
4)本文依次完成了车牌定位、车牌字符切分以及车牌字符识别等组件的开发。采用M语言建立了测试平台,并对353张卡口图片进行了测试,对实验结果进行了分析。
5)根据实验结果分析系统仍然存在的缺陷与不足,给出结论,提出展望。
7
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
1.4 本文的创新点
本文的创新点主要体现在以下四个方面:
1)提出了基于小波变换的车牌边缘提取的算法,和车牌二次定位的算法。根据车牌部分垂直方向的特征比其他部分明显的特点,采用了Mallat小波快速算法对小波变换进行了两次分解,提取出高频部分的垂直分量,进行形态学处理后可以看到车牌部分的特征非常明显,其他干扰特征则已弱化。然后根据车牌先验知识进行初步定位,去除伪车牌,最后根据投影进行精确定位,提高了光线较差情况下车牌的定位准确率。
2)对二值化过程中采用的Otsu算法进行了改进,重新划分其两维直方图的区域,由二维降到一维,提高了运算速度。
3)针对模板匹配字符识别算法中的特征提取,提出了将字符按照九宫格的方式划分,然后在每一区域分别进行特征提取的算法,提高了识别准确率。
4)针对BP神经网络字符识别算法,采用有动量的梯度下降法来训练网络,即按照某一时刻的负梯度方向修正网络权值,同时加入动量因子,修正负梯度方向的值,使得整个网络能够更快更好地收敛,提高了字符识别的运算速度和准确率。
1.5 论文结构
本文组织结构共分为7个章节:
第1章为绪论,主要介绍车牌识别研究的背景和现状,包括国内外技术的发展现状和一些较好的算法、车牌识别技术的应用情况以及发展趋势等。
第2章对车牌系统的总体设计进行了介绍。车牌的总体设计包括硬件设计、软件设计以及测试平台的搭建。本文侧重进行了软件设计和测试平台的搭建,依次完成了车牌定位、车牌字符切分、车牌字符识别三个组件的设计,并搭建了测试平台。
第3章主要研究车牌定位。在详细阐述小波变换理论的基础上,结合wavemenu工具箱对小波变换进行了详细分析,提出采用小波变换分解后的垂直分量进行边缘
8
提取的算法,结合形态学处理,采用初步定位去除伪车牌和精确定位相结合的算法,实现车牌的准确定位。
第4章是关于车牌字符切分的研究,这里主要针对二值化、倾斜校正、字符切分进行了研究。对二值化中采用的Otsu算法进行改进,重新划分二维直方图的区域,改进后的算法运行时间短、二值化效果好。
第5章研究车牌字符识别的问题,对模板匹配和神经网络的方案进行研究、改进和试验。对模板匹配法中的特征提取采用新的划分方式进行划分,分别提取特征,提高了识别准确率。对BP网络采用有动量的梯度下降法训练网络,改进后的网络可以快速收敛。最后通过实验得出结论,改进的神经网络算法在准确性、实时性和鲁棒性方面都要优于改进的模板匹配法。
第6章根据前三章研究的算法采用M语言设计了车牌识别系统的测试平台,对353张卡口图片进行测试,并对测试结果进行分析,验证改进算法的实际效果,并分析了系统的优缺点。
第7章对全文进行总结。提出了本研究课题中存在的有待改善的一些问题,指出系统可以改进的方向和对未来工作的展望。
9
2 系统总体设计
2.1 车牌识别系统总体设计
一个完整的车辆牌照识别系统是一个复杂的系统,应该包括图像采集、图像预处理、车牌定位、字符切分、字符识别以及图像编码、数码传输与更新等步骤,基本可以分为硬件部分和软件部分,硬件部分主要完成车辆图像的摄取采集,软件部分主要完成对采集到的车辆图像进行车辆牌照定位、车牌字符切分与车牌字符识别等工作,这部分工作最为复杂,最后对识别结果进行数据传送和存储,将处理后的识别信息交给管理系统进行管理。整个系统的核心是软件部分的工作,能否通过牌照对车辆进行有效管理,很大程度上取决于软件部分识别车牌的准确性。一个车牌识别系统的基本结构如图3所示:
图3 车辆牌照识别系统结构图
Figure 3 The structure of the License Plate Recognition System
2.2 系统硬件设计
一个车牌识别系统的基本硬件配置由摄像机、主控机、采集卡和照明装置组成。例如在停车场管理系统中,系统硬件主要包括车辆传感探测器、高性能工控计算机、
10
高分辨率CCD摄像机、高放大倍数镜头、CCD自动亮度控制器和视频采集卡等。
首先是探测车辆的接近、通过和停留等。常用的有光探测器、微波雷达通过型探测器、测速雷达探测器、声探测器、红外探测器、电磁感应探测器和压敏探测器等。我国停车场应用较多的是红外探测器和电磁感应环探测器。设置在停车场入口和出口的两对红外发射和接收设备进行车辆检测。利用编码调制信号,增强抗干扰的能力,具有较强的可靠性。前端工控机利用红外线探测到车辆经过的信号时,控制图像采集卡抓拍图像,并对抓拍的汽车图像进行牌照识别,同时控制摄像机光圈的大小,以适应外界环境不同的光照条件。然后将识别出的牌照信息储存到服务器中,当车辆离开时,同样的进行牌照识别,将其与前面输入的牌照信息进行对比,计算出停车时间,然后计费。
本课题主要侧重算法的研究,主要工作是设计软件,对已摄取到的卡口车辆照片实现车牌识别。
2.3 系统软件设计
硬件设备采集到图片后首先要考虑图像的存储格式。目前比较常用的图像格式有*.BMP、*.JPG、*.GIF、*.PCX等,本课题采集到的图片是*.JPG的格式。
软件系统的编写大多采用VC或者MATLAB语言,本课题选用了MATLAB语言。MATLAB具有以下优点:
1)MATLAB编程效率高,使用方便。MATLAB以矩阵作为基本语言要素大大提高了数值计算的编程效率。MATLAB本身拥有丰富的函数库,并具有结构化的流程控制语句和运算符,用户在使用过程中能够方便自如地应用。其图像处理工具箱更是大大扩展了MATLAB解决图像处理问题的能力,其他还有诸如用于神经网络和小波的工具箱等,对于算法的分析都有着很大的帮助。
2)MATLAB扩充能力强,交互性好,移植性和开放性较好。MATLAB的库函数同用户文件在形式上是一样的,用户可以根据自己的需求方便地建立与扩充新的
11
库函数,扩充其功能。MATLAB可在Windows系列、UNIX、Linux、VMS 6.1、PowerMac平台上使用,且所有的核心文件和工具箱文件都是公开的,用户可以修改源文件构成新的工具箱,从而可以扩充很多新的功能,利于算法的研究和改进。
3) 较强的图形控制和处理功能,自带的API使得用户可以方便地在MATLAB与C、C++等其他程序设计语言之间建立数据通信。
本文设计的系统采用MATLAB搭建车辆牌照识别系统,具有非常明显的优势:
1)可以直接使用MATLAB的Image Acquisition Toolbox、Image Processing Toolbox以及Neural Network Toolbox作为骨架来搭建整个系统。
2)使用MATLAB的图形用户界面技术(GUI)编写牌照识别系统面板,可以达到与牌照定位切分程序及字符识别程序的无缝连接。
3)使用专业工具箱,使得研究人员不必过于关心程序的细节问题,可以将主要的精力放在算法的研究、设计方面,极大地减少了工作量,为算法的研究改进提供了先决条件。
整个软件系统是一个具有车牌识别功能的图像分析和处理软件。首先将采集到的汽车图像进行灰度化、灰度拉伸和滤波处理,以降低噪点、增加车牌部分的对比度。然后,通过对预处理后的图像进行小波变换分解提取图像边缘,并进行形态学处理,这时,车牌的轮廓已经非常清晰,并且可以和非车牌区域明显区分开来了,接着,根据车牌的特点进行车牌初步定位,对车牌区域和伪车牌区域进行筛选后,采用投影法进行车牌二次定位,提取出车牌图像。将提取出的车牌图像进行二值化处理,根据投影图的特点查找倾斜的角度,采用坐标变换的方法进行车牌倾斜校正,并利用其垂直投影图中字符显示出的峰群的特点进行字符切分。最后利用改进的BP网络完成了整个车牌字符的识别。整个系统的设计主要采用了M语言,部分采用了C语言开发。最后搭建了一个测试平台,将上述三个部分进行了系统化,对系统的性能进行了测试和分析。
本文软件开发环境为Microsoft Windows XP;软件开发工具为Matlab 7.1;测试用图片来源为卡口车辆照片,像素大小为768×288,共353张。整个软件系统的设
12
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
计流程图如图4所示。
图4 系统流程图
Figure 4 The workflow of the system
13
2.4 本章小结
本章主要介绍了车牌识别系统的总体设计方案。首先,简单介绍了车牌识别系统的组成部分,包括硬件部分和软件部分。硬件部分主要完成车辆图像的摄取,获取高质量的含有牌照的图像,受条件限制,关于硬件的研究本文未展开具体工作。软件部分在整个系统中占有很重要的地位,而且软件的优化和升级能在很大程度上弥补硬件的不足,因此是本文研究的重点,软件研究主要是设计车牌识别系统的主体,包括基于小波变换的车牌定位模块、基于Otsu算法的车牌字符切分模块以及基于改进的BP神经网络算法的车牌字符识别模块。在确定总体设计方案后,后面将对每一模块依次进行介绍。
14
3 车牌定位
在确定系统总体设计方案后,首先介绍基于小波变换的车牌定位算法。车牌定位是车牌识别系统完成图像采集后对图像进行处理的第一步,它的好坏直接关系到整个系统识别率的高低,并且对识别速度有很大的影响。车牌不能准确定位意味着后面的识别过程都是无效的。
车牌定位是指车牌部分的图像从整个图像中切分出来的过程,一般包括图像预处理、车牌搜索、车牌定位三个部分。
图5 车牌定位的过程
Figure 5 The process of plate location
3.1 车辆图像预处理
利用摄像头拍摄到的车辆图像往往存在很多噪点,因此在进行识别前要进行车辆图像的预处理。车辆图像的预处理是指对采集到的车辆图像进行灰度化和去噪处理,以使车辆图像尤其是牌照区域的图像的质量得到改善,同时保留和增强车牌中纹理和颜色的信息,去除可能影响牌照区域纹理和颜色信息的噪点,为牌照定位提供方便。
3.1.1 图像灰度化
灰度图是指只包含亮度信息,不包含色彩信息的图像,例如平时看到的亮度连续变化的黑白照片就是一幅灰度图。灰度化处理就是将一幅彩色图像转化为灰度图
15
像的过程。彩色图像分为R、G、B三个分量,分别显示出红、绿、蓝等各种颜色,灰度化就是使彩色的R、G、B分量相等的过程。灰度值大的像素点比较亮(像素值最大为255,为白色),反之比较暗(像素值最小为0,是黑色)。
图像灰度化的算法主要有以下3种:
1)最大值法:使转化后R、G、B的值等于转化前3个值中最大的一个,即: R=G=B=max(R,G,B)………………………………(3.1) 这种方法转换的灰度图亮度很高。
2)平均值法:使转化后R、G、B的值为转化前R、G、B的平均值
R=G=B=(R+G+B)/3………………………………(3.2)
这种方法产生的灰度图像比较柔和。
3)加权平均值法:按照一定的权值,对R、G、B的值加权平均,即:
R=G=B=(ωRR+ωGG+ωBB)/3………………………(3.3)
其中,ωR、ωG、ωB分别为R、G、B的权值。ωR、ωG、ωB取不同的值,将
形成不同的灰度图像。由于人眼对绿色最为敏感,红色次之,对蓝色的敏感性最低,因此使ωG>ωR>ωB将得到较易识别的灰度图像。一般情况下,当ωR=0.299、
ωG=0.587、ωB=0.114时,得到的灰度图像效果最好。
本课题使用加权平均值法处理车辆图像,得到的灰度图效果如图6所示。
图6(a)原始汽车图像 (b)灰度图
Figure 6 (a)Original Image (b) Grayscale Image
3.1.2 灰度拉伸
对车辆图像进行灰度化处理之后,车牌部分和非车牌部分图像的对比度并不是
16
很高,此时如果直接进行边缘提取,由于车牌界限较为模糊,难以提取出车牌边缘,因而难以准确定位车牌。为了增强牌照部位图像和其他部位图像的对比度,使其明暗鲜明,有利于提高识别率,需要将车辆图像进行灰度拉伸。.
所谓灰度拉伸,是指根据灰度直方图的分布有选择地对灰度区间进行分段拉伸以增强对比度。如图7所示。它将输入图像中某点(x,y)的灰度f(x,y),通过映射函数T,映射成输出图像中的灰度g(x,y),即:
g(x,y)=T[f(x,y)]………………………(3.4)
图7 灰度变换的对比曲线
Figure 7 Intensity transformation curve
假定原图像f(x,y)的灰度范围为[s1,s2] 希望变换后图像f(x,y)的灰度范围扩展至[t1,t2],可采用下述线性变换来实现。
g(x,y)=[(t2?t1)/(s2?s1)]f(x,y)+t1…………(3.5)
图8(a)灰度图 (b)灰度变换后的图像
Figure 8 (a)Grayscale Image (b) Intensity Transformation Image
车辆图像进行灰度拉伸前后的效果对比如图8所示,从图中可以看出,灰度拉
17
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
伸后,对比度明显增强,车牌区域更加明显。
3.1.3 图像平滑
车牌图像往往存在一些孤立的噪点。在汽车牌照图像处理初期,若不能有效抑制或者去除这些噪点,将影响车牌定位的准确性或者造成无法定位。通常采用图像平滑的方法去除噪点。
图像平滑包括空域滤波和频域滤波。其中空域滤波中采用平滑滤波器的中值滤波去除噪点的效果最好。中值滤波的主要原理是:首先确定一个以某个像素为中心点的邻域,一般为方形邻域;然后将Fjk邻域中的各个像素的灰度值进行排序,取
其中间值作为中心点像素灰度的新值,这里的邻域通常被称为窗口;当窗口在图像中上下左右进行移动后,利用中值滤波算法可以很好地对图像进行平滑处理。
在二维形式下,一般取某种形式的二维窗口,将窗口内的像素排序,生成单调二维数据序列{Fjk}。二维中值滤波G(i,j)=Mid{Fij},其中Mid{?}表示取窗口中值。
在实际应用中,窗口的尺寸一般先选3再选5,逐渐增大,直到滤波效果满意为止。本文选择的窗口尺寸为3。滤波效果如图9所示。
图9(a)灰度图 (b)中值滤波后的图像
Figure 9(a)Grayscale Image (b) Filtering Image
3.2 基于小波变换的车牌边缘提取
车牌定位的边缘提取主要是利用小波变换的算法进行研究的,因此首先介绍一下小波变换的理论。小波变换是在Fourier分析的基础上发展起来的一门时频分析方法,提供了一种自适应时域和频域同时局部化的分析方法,通过自动调节时频窗
18
口大小和位置来适应分析局部信号的要求。因为其可调节性,因而能够聚焦到信号时频段上的任意细节。小波变换的这一优良性质使其在图像处理领域得到了广泛的应用,可以用于图像边缘检测、平滑去噪及图像压缩等。下面首先对小波理论作简单的介绍。
3.2.1 小波变换的定义
首先介绍小波变换的定义[9] :
若函数ψ(x)∈L2(R)满足:
?(ω)Cψ=∫ω<∞…………………………(3.6) Rω
令 2
ψa,b(x)=aψ(
则函数f(x)∈L2的小波变换定义为: ?12x?b…………………………(3.7) a
Wf(a,b)=<f,ψa,b>=a
相应的反变换公式为: ?12∫Rf(x)ψ(x?b)dx………(3.8) a
f(x)=Cψ∫∫2Wf(a,b)ψa,b(x)Rdadb…………………(3.9) 2a
?(ω)是ψ(ω)的傅里叶变换。 在式(3.6)中,ψ
在式(3.8)中,由于a,b是连续变量,因此称之为连续小波变换(continuous wavelet transform,CWT)。式(3.6)也叫小波的容许条件(Admissibility condition)。
从小波变换的定义,可以看出小波变换具有以下特点[10]:
1)多分辨率。小波变换可看作是时域窗口自适应变化的加窗Fourier变换,随a值的减小,ψa,b(t)的时窗宽度减小,时间分辨率高,ψa,b(t)的频谱向高频方向移动,相当于对高频信号作分辨率较高的分析,即用高频小波作细致观察,可用于对短时高频成分进行准确定位;当a 值增大,ψa,b(t)时窗宽度增大,时间分辨率低,
19
因而频窗宽度减小,频率分辨率高,ψa,b(t)的频谱向低频移动,相当于用低频小波
作整体观察,用于对低频缓变信号进行准确的趋势分析,小波变换可以由粗及细地逐步观察信号。
2)小波变换可以看成由基本频率特性为ψ(x)的带通滤波器在不同尺度a下对信号做滤波。由傅里叶变换的尺度特性可知这组滤波器具有品质因数恒定,即相对带宽(带宽与中心频率之比)恒定的特点。其中,a越大频率越低。
3)适当地选择基小波,使ψ(t)在时域L上为有限支撑,ψ(ω)在频域上也比较集中,就可以使Wf在时域、频域都具有表征信号局部特征的能力,因此有利于检测信号的瞬态或奇异点。
从这些特征可以看出,小波变换作为“数学显微镜”对信号分析有着极大的优势。
3.2.2 多分辨率分析与Mallat小波快速分解算法
多分辨率分析(Multiresolution Analysis,简称MRA)是S.Mallat和Y.Meyer在1986年提出来的。在L2(R)空间的规范正交基的基础上,对函数在具体的正交小波基上的投影进行分析,将L2(R)按分辨率为{2?j}分解为一串嵌套子空间序列{Vj},再通过正交补的塔式分解,将L2(R)分解成一串正交小波子空间序列{Vj}。
设{Vj;j∈Z}是空间L2(R)中的一系列闭子空间,如果满足:
1)单调性:…?Vj-1?Vj?Vj+1?
j→∞… +∞2)渐进完全性:∩Vj={0};limVj=closure(∪Vj)=L2(R)
j∈Zj=?∞
3)二进伸缩相关性:f(t)∈Vj?(2t)∈Vj+1
4)平移不变性:f(t)∈Vj?f(t?k)∈Vj
5)Riesz基存在性:存在φ(t)∈V0,使得{φ(t?k)}k∈Z构成V0的Riesz基。
则称{Vj}j∈Z为L2(R)的一个多分辨率分析。其中,?(t)称为多分辨分析的尺度
20
函数或父函数。
关于多分辨率分析,可用一个三层分解进行说明,其小波分解树如图10所示。其中,S表示原始信号占据的总频带空间,cA1,cD1表示由S第一级分解成的两个
子空间:低频空间和高频空间。然后再将低频空间cA1分解成两个子空间cA2和cD2,以此类推。
图10 小波分解树[10]
Figure 10 Wavelet Decomposition Tree
从图中可以看出,多分辨分析只是对低频部分进行进一步的分解,不考虑高频部分,分解关系式为:S=cA3+cD3+cD2+cD1。
1988年Mallat根据小波的多分辨特性,将此之前的所有正交小波基的构造法统一起来,提出了小波变换分解与重构的快速算法,称为Mallat算法[11]。下面以一维Mallat小波算法为例解释Mallat算法的原理。
设{Vj}j∈Z为L2(R)的多分辨率逼近[11],根据多分辨率理论有
??Vj⊕Wj=Vj?1 Wj∈Vj?1………………………(3.10) ?VV∈?j?1?j
?(x)为尺度函数,令?j(x)=2?j?(2?jx),则Vj的规范正交基可以表示为:
?j,n=2j/2?j(2?jx?n)n∈Z……………………(3.11)
ψ(x)为小波函数,令ψj(x)=2jψ(2?jx),则Wj的规范正交基可以表示为:
ψj,n=2j/2ψj(2jx?n)n∈Z……………………(3.12)
21
j/2?j??2?(2x)∈Vj∈Vj?1且 ?j/2…………………… (3.13) j??2ψ(2x)∈Vj∈Vj?1
根据式(3.13),可以用Vj?1空间的规范正交基表示Vj空间的基函数,即
2?j/2?j(x?2jn)=∑2j/2?j(x?2jn),2j?1/2?j?1(x?2j?1k)i2?(j?1)/2?j?1(x?2j?1k)
k
…………………………………………(3.14)
令j=1,则有
hk=21/2?1(x?2n),?0(x?k)……………………(3.15)
可以证明,对任意j,上式均成立,因此
2j/2?j(x?2jn)=∑hk?2ni2j?1/2?j?1(x?2j?1k)…………(3.16)
k
将?j(x)=2?j?(2?jx)代入上式,可以得到:
2?j/2?(2?jx?n)=∑hk?2ni2?j?1/2?(2?(j?1)x?k)………(3.17)
k
hk?2n=2?j/2?1(2?jx?n),2?j?1/2?(2?(j?1)x?k)…………(3.18)
2j/2ψj(x?2jn)=∑gk?2ni2?j?1/2?j?1(x?2?(j?1)k)………(3.19)
k
2?j/2ψ(2?jx?n)=∑gk?2ni2?j?1/2?(2?(j?1)x?k)………(3.20)
k
gk?2n=2?j/2ψ(2?jx?n),2?j?1/2?(2?(j?1)x?k)………(3.21)
根据式(3.10),有
2?j/2?(2x?n)=j
k=?∞∑∞2j/2?(2?ju?n),2?(j?1)/2?(2?(j?1)u?k)i2(j+1)/2?(2?(j?1)x?k)
……………………………………………(3.22)
2?j/2ψ(2x?n)=?j
k=?∞∑∞2j/2ψ(2?ju?n),2(j+1)/2?(2?(j?1)u?k)i2?(j?1)/2?(2?(j?1)x?k)
22
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
……………………………………………(3.23)
将式(3.18)和(3.21)定义的hk?2n和gk?2n代入式(3.22)和(3.23),有
22
?j/2
?(2x?n)=
?j
?j
k=?∞
?j/2
∑h
∞
∞
k?2n
i2?(j?1)/2?(2?(j?1)x?k)………(3.24) i2?(j?1)/2?(2?(j?1)x?k)………(3.25)
ψ(2x?n)=
k=?∞
∑g
k?2n
因此,由式(3.24)可得
f(u),2
?j/2
?(2u?n)=
?j
n=?∞
∑h
j
n
∞
k?2n
f(u),2?(j?1)/2?(2?(j?1)u?k)…(3.26)
即
a=
k=?∞
∑h
∞
j?1
k?2nk
a………………………(3.27)
由式(3.25)可得
f(u),2
?j/2
ψ(2u?n)=
?j
n=?∞
∑
jn
∞
gk?2nf(u),2?(j?1)/2?(2?(j?1)u?k)…(3.28)
即
d=
k=?∞
∑g
∞
∞
j?1
k?2nk
a………………………(3.29)
令n=h?n,n=g?n,则式(3.27)与式(3.29)变为
a=d=
jnjn
k=?∞∞
∑2n?k
akj?1………………………(3.30) akj?1………………………(3.31)
k=?∞
∑2n?k
式(3.30)和(3.31)就是一维小波变换的Mallat算法。其过程如图11所示。
图11 小波变换的Mallat算法
Figure 11 The Mallat Arithmetic of Wavelet Decomposition
23
其中,↓2表示1/2抽样,即从akj?1到akj和dkj,样点数减少一半。二维图像的Mallat小波变换与此类似,如图12所示。
Aj+1
Hj+1
Aj
Vj+1
Dj+1
图12 二维小波变换的Mallat算法
Figure 12 The Mallat Arithmetic of Two-dimension Wavelet Decomposition
其中,和表示低通和高通滤波器。2↓1表示列抽样,保留所有的偶数行。1↓2表示行抽样,保留所有偶数列。
输入图像经过小波变换分解后得到四个分量,分别为平滑分量Aj+1、水平分量Hj+1、垂直分量Vj+1和对角线分量Dj+1。其中水平分量Hj+1表示水平方向的低频分
量和垂直方向的高频分量,垂直分量Vj+1表示水平方向的高频分量和垂直方向的低频分量,对角线分量Dj+1表示水平方向的高频分量和垂直方向的高频分量。
3.2.3 基于小波变换的车牌边缘提取
边缘主要存在于目标与目标、目标与背景、区域与区域(包括不同色彩)之间,边缘检测主要是精确定位边缘和抑制噪点,其基本思想是首先利用边缘增强算子,突出图像中的局部边缘,然后定义像素的“边缘强度”,通过设置门限的方法提取边缘点集[12]。
常用的传统边缘检测算子有Robert算子、Sobel算子、Prewitt算子、Laplacian算子和Canny算子。但是传统的边缘检测算法存在很多问题。例如边缘检测时噪点的影响会通过检测算子被扩散,传统边缘检测算子的门限值的选取是主观的,其值对最后的检测结果有很大的影响等[13]。由于用传统的边缘检测算子检测到的边缘信息中含有很多无用的干扰信息,所以要想从复杂的背景和种种的干扰中准确的定位
24
出车牌区域是比较困难的。
由于传统边缘检测算法无法满足不同光照条件下的车牌定位的需要,本课题采取了基于小波变换提取边缘的算法。
由于在牌照区域内,纹理结构中纵向边缘比较多。因此,考虑利用小波的多分辨率的思想将待识别的图像进行Mallat小波变换,将车辆图像分解为包含图像基本信息的低频部分和包含图像细节信息的高频部分。根据车牌的先验知识可知,车牌区域垂直边缘比水平边缘丰富,而汽车前面的排气格栅等干扰信息往往是水平边缘更为丰富,因此车牌区域应该包含在图像的高频部分中。经实验,进行两层的小波变换分解即可满足要求。下面是一个关于车牌区域图像的实验。
图13 车辆灰度图
Figure 13 Grayscale Image of The Car
图13是一幅768x288的灰度图,取X=214(车牌中间区域)的一条数据线:
S(k),k∈(1:768),使用MATLAB 7.1的小波分析工具箱进行分析。图15是通过HAAR小波进行5层小波分解得到的结果。
图14 X=214数据线的灰度图
Figure 14 Grayscale Image of X=214 of the car
25
图15 用HAAR小波进行五层分解 Figure 15 Wavelet Decompresion with Haar
从图14可以看出号牌区的纹理有着非常明显的特点,它是一个密集的高频纹理区。而非车牌区则是一个低频区。在图15中,d为细节信号,a为相似信号。从图15中可以看出,在前三层分解中,号牌区的细节信号特征非常明显,可以较容易的分离出来,而第四层和第五层的细节信号中非车牌区域的干扰越来越严重,同时相似信号中号牌区和非号牌区的区别并不是很明显。因此选择两层分解的小波细节信号进行车牌定位。
从上面的实验分析可以看出,经过Mallat分解后的小波图像,可以很好的反映原图像在不同尺度、不同方向上的模糊分量和细节分量。通过对车牌图像进行小波分解,发现小波分解后的细节分量可以较好的体现出车牌位置的信息,特别是水平方向低频、垂直方向高频细节分量有助于车牌的准确定位。
图16是对图13中汽车图像进行小波分解得到的图像。从图中可以看出,经过小波分解后的图像噪点已大大减小,车牌的纹理也比较明显。其中,水平分量夹杂了汽车前面的排气格栅等干扰信号的信息,容易对车牌的定位造成很大的干扰。垂
26
直分量的效果较好。对角线分量在去除干扰信息时,也去除了部分车牌信息,对后续车牌定位有较大影响。所以本课题采取提取车牌图像小波分解垂直分量的算法。
图16 车牌图像的小波分解
Figure 16 Wavelet Decompression of the Car
图17是利用车牌图像小波分解的垂直分量进行边缘提取的图像,从图中可以看出,车牌部分的纹理特征比较明显,车前格栅等干扰均已除去,噪点干扰大大减小,而且只需对高频图像进行检测,即1/4的图像进行检测,运行时间大大缩短。
图17小波分解提取边缘
Figure 17 Edge Extraction with Wavelet Decompression
3.3 车牌初步定位 3.3.1 结构元素的选取
小波变换提取的车牌边缘很明显,但是车牌边缘并不是连续的,不利于根据其特征进行进一步的判断。因此,需要对其进行形态学的处理,使其成为一个连通的整体,便于后续定位。
27
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
在进行形态学处理时,首先采用imclearborder函数对提取后的车牌边缘进行连通处理,删除和图像边界相连的细小的对象,使得相邻的区域可以连成一个整体。然后进行数学形态学的腐蚀和膨胀运算,从而使车牌区域的垂直边缘连接成一个整体,同时和周围的干扰区域分离,成为一个独立的区域。水平结构元素可以是形如
[1…1]的滑动窗口,结构元素的大小取决于车牌图像的大小,一般取所有车牌图像大小的统计均值。相应的代码如下:
a1=imclearborder(a1,8); %8连通
st=ones(1,14); %选取的结构元素
bg1=imclose(a1,st); %闭运算
bg3=imopen(bg1,st); %开运算
bg2=imopen(bg3,[1 1 1 1 1 1 1]');
首先进行闭运算,使得水平相邻的边缘连接成为连通区域,由于车牌长度比较长,所以选取的结构元素为[1 1 1 1 1 1 1 1 1 1 1 1 1 1]。然后再进一步在垂直边缘上进行两次开运算,两次结构元素的选取是由实验的结果得到的。在采用这两个结构元素进行开运算后使得车牌区域与其它背景区域分开,成为独立的连通域。处理后的图像如图18所示。从图中可以看出。车牌区域已经非常明显,和其他区域有明显的区别。
图18 开闭运算后的图像
Figure 18 Image after open and close operation
3.3.2 提取候选区域
由于前面开闭运算中有可能将部分车牌腐蚀掉,造成定位错误或者车牌缺失,所以先进行车牌的初步提取,去除伪车牌,然后结合车牌的纹理特征进行准确提取。
28
提取候选区域的步骤是:首先对经过开闭运算处理的图像进行区域提取,并计算区域特征参数,然后根据车牌的先验知识对区域特征参数进行比较,提取车牌区域。本课题选择使用车牌的宽高范围和比例关系对车牌进行初步定位。
对车牌的区域提取可以利用regionprops函数,对图像每个区域进行标记,然后计算每个区域图像特征参数:区域中心位置、最小包含矩形,面积。最后计算出包含所标记区域的最小矩形的宽和高。
提取车牌区域特征的代码为:
[L,num] = bwlabel(bg2,8); %区域标记
Feastats=regionprops(L,'all'); %区域特征提取
Area=[Feastats.Area];
BoundingBox=[Feastats.BoundingBox];
RGB = label2rgb(L, 'spring', 'k', 'shuffle');
width=BoundingBox((l-1)*4+3); %计算包含标记区域的最小区域的宽 height=BoundingBox((l-1)*4+4); %计算包含标记区域的最小区域的高
图19 车牌区域标记
Figure 19 Area Designation
2007年实施的车牌标准规定,车前车牌长440mm,宽140mm。其比例为440/140≈3.15。根据图像像素的大小,这里选取筛选条件为宽在50到150之间,高在20到50之间,同时宽高比例应大于0.45,就可以比较准确的得到车牌的大致位置。初步提取的车牌图像如图20所示。
图20 初步提取的车牌
Figure 20 Plate Coarse-location
29
3.4 车牌精确定位
在车牌初步定位之后,伪车牌已经去除,得到了车牌区域,接着采用投影法进行车牌的精确定位。在所有的汽车牌照识别定位算法中,利用投影法进行牌照区域与背景的分割,是一种常用的方法,也是一种非常实用的方法。现有的车牌定位算法,包括利用车牌纹理特征进行定位的算法、利用图像信息差进行定位的算法、以及利用车牌颜色特征进行定位的算法等各种算法,在完成特征计算之后,都采用了投影的方法进行车牌切分。
通过车牌二值图像可以看出,二值化后的图像,其车牌区域在水平方向的灰度面积值具有明显频繁的跳变,在垂直方向上的投影则显示出明显的峰-谷-峰的特性,并且有多个峰值出现,组成了峰群。车牌部分的峰值往往比非车牌部分的峰值要大很多。根据车牌的峰谷特点,可以对初步定位后的车牌进行精确定位。其步骤包括车牌的横向定位、车牌的纵向定位。
3.4.1 车牌水平方向的定位算法
通过对车辆牌照灰度图图13的分析可以看出车辆牌照具有以下特点:车辆牌照字符和背景的灰度对比值较大,同时对应于车牌区域的水平灰度变化比较频繁。因此考虑使用在靠近水平方向的一阶差分运算,来突出灰度变化频率频繁的区域。
对前面初步提取后得到的图像f(i,j)进行水平一阶差分得到g(i,j),即:
g(i,j)=f(i,j)?f(i,j+1)……………………(3.32)
其中,i=1,2,3,…,m;m为图像的高度;
j=1,2,3,…,n;n为图像的宽度。
将差分后的图像g(i,j)的灰度值沿水平方向累加后做投影得到T(i),投影图如图21所示。其中
T(i)=∑g(i,j)………………………………(3.33)
j=1n
30
图21 水平差分累加投影图
Figure 21 Map of horizontal projection
由于图像存在一些毛刺,还不够平滑,不利于车牌的精确定位,因此首先对投影值进行平滑处理。在算法的实现上,采用均值法来进行平滑。其公式为:
T(i)=(T(i?1)+T(i)+T(i+1))/3…………………(3.34)
图22 平滑后的水平差分累加投影图
Figure 22 Map of smooth horizontal projection
平滑后的投影图如图22所示。在经过初步定位处理后,车牌上下边界往往没有干扰信息,而且车牌的上下边框由于是水平的,在边缘提取的时候已经被除去。因此,在查找上下边缘时可以从上到下搜索,找到第一个不为零的点,然后从下往上搜索,找到第一个不为零的点,这两点之间即为车牌的上下边界。对车辆牌照上下边界定位的效果图如图23所示。
图23 水平定位后的图像
Figure 23 Image after horizontal positioning
在水平定位后,将车牌上下两条边界之间的距离计算出来就是字符的高度。
31
3.4.2 车牌垂直方向的定位算法
车牌垂直方向的定位算法和车牌水平方向的定位算法类似,首先对车牌垂直方向进行差分运算,将差分得到的结果用均值法进行平滑,平滑后的投影图如图24所示。
图24 平滑后的垂直差分累加投影图
Figure 24 Map of smooth vertical projection
从图中可以看出,对于垂直方向的投影,车牌区域的差分投影不是一个单峰,而是一群多峰,这些多峰的峰值比车牌以外区域的峰值要高出很多。选取最大峰值的0.6做为阈值,找出第一个和最后一个高出此阈值的峰值。将第一个峰左边波谷点以外的部分切除,将最后一个峰右边波谷点以外部分切除,即得到了车牌图像。
在除去两边的非车牌区域后,由于车牌垂直部分可能包含垂直的牌照边框,所以,得到的车牌图像中可能包含牌照边框。为了便于后续的字符切分,这里要去除车牌左右边框。先根据预先设定的阈值查找并记录每一个字符的上升点,及每一个字符的下降点。计算前一个下降点到后一个上升点之间的距离就是两个字符之间的谷宽度。计算相邻两个字符的上升点的差值,减去它们之间的谷宽度,就可以得到每一个字符的宽度。用max函数找出最大字符宽度,记为maxcol,去除宽度小于maxcol/3的波峰,即可去除垂直的车牌边框,得到精确的车牌图像。
精确定位后的车牌图像如图25所示。
图25 精确定位后的车牌
Figure 25 Plate after accurate positioning
32
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
从图中可以看出,车牌上下左右边框均已除去,便于后续的车牌字符切分。
3.5 本章小结
本章主要介绍了车牌识别的第一步——车牌定位的算法。算法的软件流程图如图26所示:
图26 车牌定位算法
Figure 26 Plate Localization Arithmetic
本课题选择使用灰度图进行车牌定位。首先,对车牌进行预处理,包括灰度化、灰度拉伸和图像平滑。经过预处理的车牌图像,车牌区域比较明显,车牌区域和非
33
车牌区域对比度较高。预处理后,采用了基于小波变换的车牌边缘提取算法。通过对车辆图像进行Mallat小波快速分解算法(采用Haar小波),可知小波变换分解后的图像垂直分量中含有能够较好地体现车牌位置的信息。而且,只需要对垂直分量进行检测,也就是说只需要扫描1/4幅图像即可完成车牌边缘提取,运算时间大大减小,有助于后续步骤对车牌的快速准确定位。
经过小波变换分解后的高频子图像,车牌的纹理已清晰可见,噪点也明显减小,搜索范围大大缩小。之后,利用形态学的方法对车牌区域进行处理,并结合车牌的先验知识去除伪车牌,找出真正的车牌区域。对真正的车牌区域进行水平投影和垂直投影就可以得到车牌的位置坐标,切分出车牌,实现车牌的精确定位。
车牌准确切分出来后,下一步研究对车牌的字符进行切分的算法。
34
4 车牌字符切分
4.1 车牌字符切分综述
在车辆牌照准确定位后,本章主要是对车辆牌照识别中的字符切分算法进行研究,依次研究了二值化、倾斜校正和字符切分三个算法。车牌字符切分的流程框图如图27所示。
图27 车牌字符切分流程
Figure 27 Flow chart of Plate characters segmentation
4.2 车牌二值化
图像中对象物的形状特征的主要信息,常常可以从二值图像中得到。二值图像与灰度图像相比,信息量大大减少,因而处理二值图像的速度快,成本低,实用价值高。因此,在车牌字符切分前,首先对图像进行二值化处理。
4.2.1 图像二值化的基本原理
图像的二值化处理就是将图像上的点的灰度值置为0或255,这样处理后整个图像呈现明显的黑白效果,即将256个亮度等级的灰度图经过合适的阈值选取,而获得的二值化图像仍然可以反映图像整体和局部特征。
二值化处理后的图像,其集合性质只与像素值为0或255的点的位置有关,不再涉及像素的其他级值,处理过程简单,且数据的处理和压缩量小。为了得到理想的二值图像,一般采用封闭、连通的边界定义不交叠的区域。所有灰度大于或等于
35
阀值的像素被判定为属于特定物体,其灰度值为255,否则,灰度值为0,表示背景或者其他的物体区域。如果某图像在内部有均匀一致的灰度值,并且处在一个具有其他等级灰度值的均匀背景下,利用阀值法就能得到较好的切分效果。如果物体同背景的差别难以用不同的灰度值表现(比如纹理不同),可以把这些差别特征转换为灰度的差别,然后利用阀值法来切分该图像。动态调节阀值来实现图像的二值化可动态地观察其切分图像的具体结果。
4.2.2 Otsu算法
Trier与A.K.Jain[18]研究了已有的文本图像二值化方法,总结出一些典型的二值化方法,包括Bernsen算法、Chow与Kanekos算法、Bikbil算法、Trier与Taxt算法等局部自适应算法和Otsu算法、Kapur算法、Kittler Illingworth算法、Abutaleb算法等全局阈值算法。其中Otsu算法适应性和效率比较好。
Otsu算法[22],即最大类间方差法,是由日本人大津首先提出来的,又称为大津阈值分割法,是在判断分析最小二乘法原理的基础上推导得到的。按照图像的灰度特性,将图像分成背景和目标两部分。背景和目标之间的类间方差越大,说明构成图像的两部分的差别越大,部分目标错分为背景或部分背景错分为目标都会导致两部分差别变小。因此,使类间方差最大的分割意味着错分概率最小。
Otsu的基本思想是利用一幅图像的灰度直方图,依据类间距离极大准则来确定区域分割门限。该方法的基本原理如下:
设图像有L个灰度级,灰度值是i的像素数为ni,则总的像素数是N=∑ni,
i=0L?1
各灰度值出现的概率为pi=ni/N,显然pi≥0且∑pi=1。设以灰度t为门限将图
i=0L?1
,灰度级为t+1~L?1像分割成两个区域:灰度级为1~t的像素区域为A(背景类)
的像素区域为B(目标类)。A、B出现的概率分别为:
pA=∑pi…………………………………(4.1)
i=0t
36
L?1
pB=
A和B两类的灰度均值分别为 i=t+1∑p
ti=1?pA…………………………(4.2) ωA=∑ipipA……………………………(4.3)
i=0
ωB=
图像总的灰度均值为: i=t+1∑ipL?1ipB……………………………(4.4)
ω0=pAωA+pBωB=∑ipi……………………(4.5)
i=0L?1
由此可以得到A、B两区域的类间方差为:
σ2=pA(ωA?ω0)2+pB(ωB?ω0)2…………………(4.6)
显然,pA、pB、ωA、ωB、ω0、σ2都是关于灰度级t的函数。
为了得到最优分割阈值,Otsu把两类的类间方差做为判别准则,认为使得σ2值最大的t′即为所求的最佳阈值:
t′=ArgMax[pA(ωA?ω0)2+pB(ωB?ω0)2]……………(4.7) 0≤t≤L?1
因为方差是灰度分布均匀性的一种度量,方差越大,说明构成图像的两部分差别越大,将部分目标错判为背景或是部分背景错判为目标都会导致两部分差别变小。因此,使类间方差最大意味着错分概率最小,这就是Otsu准则。
Otsu算法还存在着许多缺点,如运行时间长(要对图像的每一级灰度进行计算),而且Otsu方法的判别准则函数可能呈双峰,此时,Otsu算法可能会把背景错分为字符,导致无法识别。针对这些缺点,在对车牌图像进行二值化时对Otsu算法进行了改进。
4.2.3 改进的Otsu算法
在实际的应用中,干扰因素会造成一维灰度直方图不一定存在明显的波峰和波谷,此时一维Otsu算法就太不适合。但如直接采用二维的Otsu算法,效率又太低。
37
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
因此本课题采用改进的二维Otsu算法,通过改变二维直方图上的区域划分,将二维阈值转换为一维阈值进行计算,既可以克服一维Otsu适应性差的问题,也提高了二维自适应阈值算法的计算速度。
二维Otsu算法的原理是将图像像素按照灰度分为(C0,C1),C0和C1分别包含灰度等级在{0,1,…,t}及{t+1,t+2,…,L-1}内的像素,分别对应于背景和目标物体。
在图像每个像素点计算其邻域平均灰度值,则邻域平均图像的灰度等级也为L。这就构成了图像像素点的灰度值和它的邻域平均灰度值的二元组,记为(i,j)。设
(i,j)出现的频率为f(i,j),则其二维联合概率密度为:
pij=fij/M……………………………(4.8)
其中,i=0,1,2,…,L-1,j=0,1,2,…,L-1,且∑∑pij=1。
i=0j=0
L?1L?1
g(x,yL?
)
图28 二维Otsu算法阈值求解示意图
Figure 28 The arithmetic of two dimentional Otsu threshold
如图28所示,对任意给定的一个阈值(s,t),可以将图像分割成4个区域,分别为:Ⅰ、Ⅱ、Ⅲ、Ⅳ。其中对角线上的区域Ⅰ和Ⅲ分别对应图像的背景C0与目标物体C1(假设目标物体的灰度高于背景物体)。远离对角线上的区域Ⅱ和Ⅳ则对应图像的噪点和边缘。
假设背景对应的概率为p0,目标对应的概率为p1,则:
p0=∑∑pij…………………………(4.9)
i=0j=0s
t
p1=
i=s+1j=t+1
∑∑p
L?1L?1
ij
………………………(4.10)
38
此时C0和C1对应的灰度均值矢量为:
μ0=(μ0i,μ0j)=(∑ip(i
T
i=0
s
C0
),∑jp(j
j=0
t
C1
))T…………(4.11)
μ1=(μ1i,μ1j)=(∑ip(i
T
i=s+1
L?1
C0),
j=t+1
∑
L?1
jp(j
T
…………(4.12) ))C1
图像总的灰度均值矢量为:
μT=(μTi,μTj)=(∑∑ipij,∑∑jpij)………………(4.13)
i=0j=0
i=0j=0
L?1L?1L?1L?1
定义离散度矩阵:
S(s,t)=∑pk[(μk?μT)(μk?μT)T]………………(4.14)
k=01
以离散度矩阵的迹做为离散度测度,得到
tr(S(s,t))=∑pk[(μki?μTi)2+(μkj?μTj)2]……………(4.15)
k=01
当选取最大值时其对应的二值化阈值就是最优阈值,即最优二值化阈值(s′,t′)满足:
tr(S(s′,t′))=max(tr(S(s,t)))……………………(4.16)
其中,0≤s,t≤L?1。
在二维Otsu算法中,需要对每个s,t的组合计算一个离散度矩阵的迹,然后取离散度矩阵的迹最大时的s,t为分割阈值。在原始算法中,需要s和t的双重循环,而每次计算离散矩阵的迹,需要对st+(L?s)(L?t)个点做累加运算,总累加次数为:
A=∑∑[st+(L?s)(L?t)]……………………(4.17)
s=0t=0L?1L?1
其中当L=256时,A=2147416446,这需要经过一个较长时间的循环。 为了解决二维Otsu二值化算法计算量大,运行时间长的问题,考虑将二维直仅计算与对角线平行的f=g+N和f=g?N两条线段方图按图29的方式[23]分块,
之间的点,将之外的点都视为概率为0的点。这时,只要N足够大,就可以将所有概率不为0的点都包括进来。
39
g(x,yL?t1,L?1)
g+N
,y)
012
图29 改进的Otsu算法阈值求解示意图 Figure 29 The improved arithmetic of Otsu threshold
设二值化阈值为(s,t),以通过点(s,t)且与对角线垂直的直线l进行分割。该直线左面的点对应于背景物体,即C0,右面的点对应于目标物体,即C1。
直线l的方程为:
l=s+t?g………………………………(4.18)
则当l≥s+t?g时,属于C1;当l<s+t?g时,属于C0。由于分类准则只与s+t有关,因此可以将s+t整体做为一个阈值,从而将二维阈值转换为一维阈值进行计算。
由于判决标准取决于s+t,而非单独的s、t,因此仅需进行2L次循环,每次循环仅需N2+2N(L?N)=N(2L?N)个点做累加运算。设N=kL,则总累加次数为:
A′=2(2k?k2)L3……………………………(4.19
)
当L=256,且
N=40时,可以将所有的非零概率点都计算在内,此时
A′=966560=0.45%A。可见其计算时间大大提高。
下面是对部分图像采用改进的Otsu算法进行二值化的结果。
(a)
(b)
40
(c)
图30 改进的Otsu算法二值化实验
Figure 30 Experiments of improved binary Otsu arithmetic
图30所选车牌图片都是在光照不均的情况下摄取的,其中图(a)是在曝光过度的情况下摄取的,图(b)是在曝光不足的情况下摄取的,图(c)中黄底黑字的车牌对比度比较差,但是从二值化图像效果来看,基本可以满足后续车牌切分和识别的要求。
4.3 倾斜校正
虽然标准的车牌字符应为水平依次排列,但是由于放置不当或车身前进方向与图像采集设备不在同一条直线上等原因,会造成图像中的车牌倾斜、扭曲。因为一个倾斜的数字或字母的识别和一个很正的数字或字母的识别是有很大差别的,所以车牌定位之后要进行倾斜校正。一般情况下,倾斜校正有两步,第一步是找出倾斜的角度;第二部是进行坐标变换,得到校正后的图像。
4.3.1 倾斜角度的计算
目前常用的计算倾斜角度的方法有两种,一种是Hough变换来找出倾斜的角度,一种是利用投影的方法来找出倾斜的角度。另外还有Radon变换方法等,这里主要介绍前面两种方法。
1)Hough变换
Hough变换[24](Hough Transform,HT)作为一种预处理算法,是由Paul Hough
在1962年提出的一种检测和定位直线或者解析曲线的方法,目前是直线检测的重要工具。这种方法针对有噪图像有很好的稳定性和鲁棒性,可以并行实现。
Hough变换提取直线法是一种变换域直线提取法,它把直线上的点的坐标变换
成过点的直线的系数域,利用了共线和直线相交的关系,使直线的提取问题转化为
41
计数问题。
如图像中直线l的参数化形式如下:
ρl=xcosθl+ysinθl………………………(4.20)
即ρl是θl的三角函数,即图像空间的一个点在Hough空间成为一条正弦曲线,那么对共线的n个点做作变换,在Hough空间会产生n条正弦曲线,且这些正弦曲线交于点(ρl,θl),点的值等于n,如下图所示。
图31 图像空间
Figure 31 Image Space
图32 Hough空间 Figure 32 Hough Space
日常所需要校正的车牌大致分为两类:一类是车牌整体旋转一个角度θ,形成原因一般是挂放的不规范;另一类是歪斜车牌,形成的原因主要是图像采集时的透视误差造成的。
采用Hough变换的方法找出需要倾斜的角度,需要从图像中找出两条直线做为基准线,一条是水平直线,另一条是垂直方向的直线。找到之后,以此边界线为参照物结合Hough变换检测的直线的参数ρ即可找到倾斜的角度。
利用Hough变换查找倾斜角度的流程图如图33所示,旋转的角度和方式与车
42
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
牌倾斜原因有关。其中水平偏移校正的依据是tan(θ2?θ1)=dx。
dy
图33 利用Hough变换查找倾斜角度
Figure 33 Search the angle of inclination by Hough
首先采用Hough变换检测出需要校正的车牌的水平边界线和垂直边界线,采用极坐标表示,分别为θ1ρ1和θ2ρ2。然后计算θ2?θ1?
的容忍区间。如果θ2?θ1?π2<ε,这里ε是判断车牌类型π
2<ε,表明车牌只是由于挂放不规范产生了倾斜,其水
平边界与垂直边界的夹角近似为
成车牌的校正。如果θ2?θ1?π2,边框仍保持矩形,这时,只要旋转θ1就可以完π
2≥ε,则表明边框变形比较大,已形成了歪斜车牌,
进行水平偏移校正时先设dx为一在将车牌旋转θ1的同时还需要做水平的偏移校正。
个像素,然后用公式tan(θ2?θ1)=dx计算出高度dy,对图像的垂直方向每隔dy个dy
43
像素水平平移一个像素以达到精确的校正效果。
利用Hough变换查找牌照倾斜角度的方法,最重要的是找到基准线,并且做为基准线的这条直线应该满足水平直线和垂直直线的要求。Hough变换基准线的选择,通常是图像中最长的一条直线。在有车牌边框的图像中,车牌边框往往成为了基准线,但是倾斜的车牌其边框通常也是倾斜的。本课题在车牌定位算法中,车牌边框已经去除,所以基准线往往从字母或者数字中查找,并不能保证其水平性和垂直性。因此,本课题采用了另外一种方法,即利用投影的方法来找出车牌倾斜的角度。
2)利用投影找出倾斜角度
车牌字符大多分布在牌照的中央位置,车牌的水平投影如图34所示。
图34 车牌二值子图及其水平投影
Figure 34 The binary plate and its horizontal projection
本课题采取了线性拟合的方法,计算出车牌上边或下边图像值为1的点拟合直线与水平X轴的夹角,从而得到车牌旋转的角度。即:
1)先求出直线方程y=p1*x+p2的斜率系数p1;
2)计算夹角α=arctan(p1)*360/2π;
3)求得车牌旋转角度为α。
用投影法求取车牌旋转角度的主要程序如下:
%(1)在车牌二值子图上边至水平投影数组的第一个峰下降点处扫描找第一个为1的点
k1=1;
for l=1:n2
44
for k=1:k2 %从上边至水平投影数组的第一个峰下降点k2扫描 if sbw1(k,l)==1
xdata(k1)=l;
ydata(k1)=k;
k1=k1+1;
break;
end
end
end
%(2)线性拟合,计算与x夹角
fresult = fit(xdata',ydata','poly1'); %poly1 Y = p1*x+p2
p1=fresult.p1;
angle=atan(fresult.p1)*180/pi; %弧度换为度,360/2pi, pi=3.14
4.3.2 坐标变换校正图像
在求出牌照偏移角度后,判断其是否为0,若倾斜角度不为0,则需要对其进行校正,即对车牌图像进行旋转操作。
对车牌图像的旋转操作是通过坐标变换实现的。旋转前的图像坐标为:
?x0=rcos(α) ?yrsin()α=?0
旋转后的图像坐标为:
?x0=rcos(α?θ)=rcos(α)cos(θ)+rsin(α)sin(θ)=x0cos(θ)+y0sin(θ) ??y0=rsin(α?θ)=rsin(α)cos(θ)?rcos(α)sin(θ)=?x0sin(θ)+y0cos(θ)
根据这一坐标变换,就可以计算出旋转后图像中各个像素的值。完成了图像的旋转。这种方法相对比较复杂,但是不会因旋转丢失任何信息。另外还有一种简单的算法[17],可能会损失部分信息,但是速度比较快。该方法如下:
根据水平边的斜率对像素位置进行校正,取平行四边形底边最低像素为基准
45
点,做一条水平直线为基准底边,将底边L的像素垂直下移到基准边上,其他的元素再依次下移。
设车牌下边两个端点像素的坐标为(x1,y1),(x2,y2),那么对于车牌中任一像素
(x,y),校正后的坐标为(x′,y′),坐标变换如图35所示。
图35 坐标变换示意图
Figure 35 Coordinate Transform
其坐标变换公式为:
?x′=x?(x?x1)(y1?y2)……………………(4.21) ?′yy=+?x2?x1?
第二种方法的效果和第一种大致相同,但是效率提高了。图36是利用Hough变换和投影法分别进行车牌倾斜校正的对比图。
(a)
46
(b)
图36 两种校正算法的比较
Figure 36 The comparison of two arithmetic
从上面两幅图的比较中我们可以看出,由于摄取的车牌图像在二值化过程之后其边框大多已经被去掉,因此采用Hough变换进行车牌旋转校正的时候基准线只能是从字符中攫取比较长的一条直线做为基准线,往往不能满足对基准线的要求,对旋转的效果产生了一定的影响。例如在图(a)中,应用投影法的车牌的旋转角度为?1.78°,而应用Hough变换的车牌的旋转角度为?3.59°;在图(b)中,应用投影法的车牌的旋转角度为?1.78°,而应用Hough变换的车牌的旋转角度为?3.59°。应用Hough变换旋转后,车牌依然呈现出倾斜的趋势。两个效果对比可以看出,投影法的效果更好。
4.4 字符切分
国内汽车牌照种类很多,格式不一,为研究方便以常见的蓝色车牌为例来说明。2007年颁布的车牌规范规定车牌总长440mm,牌照中的7个字符的实际总长为409mm左右,宽140mm,每个字符45mm宽,90mm高,字符间距为10mm,其中第二个字符与第三个字符的间距较为特殊,为15.5mm,最后一个字符与第一个字符距边界25mm。这样,如果平均分配每个字符在牌照中占据的宽度,那么每个字
47
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
符宽度为:width/7(width为车牌图像的宽度)。但是,实际上,第二个第三个字符之间存在一个黑点,牌照左右两边与图像边缘也都有一定的宽度,所以每个字符的宽度应该小于width/7。考虑所有的情况,一般情况下最小的宽度为width/9。因此,字符的宽度可以从width/9到width/7之间渐进的变化得到。
经过车牌字符图像的二值化和倾斜校正,得到的是一个只包含牌照字符的水平条形区域,为了进行字符识别,需要将牌照字符从图像中分割出来。这里常用投影法,既简单又快捷。投影法切分车牌字符的思想是根据车牌字符的特点,将车牌图像进行垂直方向的投影,因为字符区域的黑色像素点比较多,比较集中,同时每个车牌字符之间有一定的空隙间隔隔开。这样投影下来得到的投影图应该有多个相对集中的投影峰值群,只要根据峰值群的特点进行分割,就可以得到车牌的字符。
对图像的垂直方向进行投影,得到的投影图如图37所示。
图37 字符投影图
Figure 37 The projection of characters
从图37的投影图可以看出,图中有七个比较集中的投影峰值群,且每个峰值之间都有一定的间隔。根据这一特点,从左往右依次定位出每个字符的起始和结束位置,并且进行切割。然后对切割出来的每个字符图像进行水平投影。根据水平投影像素累加值进行水平切割,从而得到精确切割后的字符。
车牌字符切分的具体算法为:
1)对车牌图像进行垂直投影,计算出字符的宽度后,确定字符的中间位置,并计算相邻两个字符之间的间距,即中间距离的差值。取其最大值定为第二个字符
48
和第三个字符之间的距离。以此为分界线,分别向前、后两个方向进行切分,从而定位出每个字符的左右边界,并保存在数组里。由于MATLAB的数组可以存放不同大小的数据,为字符边界信息的存储提供了极大的便利。
2)对每个切分出的字符进行水平投影,确定字符的具体的上下边界,保存到数组里。
3)由于用于最后识别的字库中字符模板为24×48像素,所以这里对切分出来的字符进行归一化处理,统一为24×48像素。
4)将归一化后的字符的信息保存在数组里,做为参数输入字符识别模块与模板比较进行字符识别。
切分后的字符效果如图38所示:
图38 字符切分后的效果图
Figure 38 Characters Segmentation
最后介绍一下确定字符宽度和中心距离的算法:首先对垂直投影进行峰谷分析,根据预先设定的阈值查找并记录每一个字符的上升点,及每一个字符的下降点。计算前一个下降点到后一个上升点之间的距离就是两个字符之间的谷宽度。然后计算相邻两个字符的上升点的差值,减去它们之间的谷宽度,就可以得到每一个字符的宽度。用字符上升点的位置加上字符的宽度的一半,就可以得到字符的中间位置。该算法操作起来比较方便,并且可以和字符左右边界的确定同时进行。
4.5 本章小结
本章主要介绍车牌识别的第二步——车牌字符切分算法。车牌字符切分分为车牌二值化、车牌倾斜校正和车牌字符切分三个步骤。车牌字符切分的流程图如图39所示。
49
图39 车牌字符切分算法
Figure 39 Plate Characters Segmentation Arithmetic
车牌字符切分中关键的一步是二值化,二值化的效果好坏对后面的字符切分以及字符识别都有很大的影响。二值化过程中很重要的一个方面就是阈值的选取,这里介绍了一种全局阈值的算法:Otsu算法,由于一维的Otsu算法无法很好的适应系统需求,所以采用了二维的Otsu算法,并对其进行了改进,对二维直方图上的区域进行重新划分,改进后的算法所需时间少于原有的二维算法。之后研究了车牌的倾斜校正算法,主要研究现在常用的两种算法:Hough变换和投影法。经过对比证明使用投影法的车牌校正效果要优于使用Hough变换的车牌校正效果,因此本课题采取投影法结合坐标变换校正车牌的算法。最后根据车牌垂直投影的特点进行字符的切分,取得了比较好的效果。
在完成车牌字符切分后,得到了单个字符的信息,下一步研究车牌字符识别的算法。
50
5 车牌字符识别
车牌字符进行准确切分后,本章完成车牌识别最后一步——车牌字符识别,这一步也是计算量比较大的一部分。经过多年的研究,目前有多种字符识别的方法,本章主要对模板匹配法和神经网络法进行对比,并分别进行改进,提高了两种方法的运算速度。
5.1 车牌字符识别综述
目前已经提出的车牌字符识别的方法有以下几种:
1)模板匹配字符识别算法[26]。模板匹配字符识别算法的实现方法是计算输入模式与样本之间的相似性,取相似性最大的样本为输入模式所属类别。该方法识别速度快,但是对噪点比较敏感。在实际应用中,为了提高正确率往往需要使用大的模板或多个模板进行匹配,处理时间则随着模板的增大以及模板个数的增加而增加。
2)统计特征匹配法。统计特征匹配法的要点是先提取待识别模式的一组统计特征,然后按照一定的准则所确定的决策函数进行分类判决。实际应用中,当字符出现字符模糊、笔画融合,断裂、部分缺失时,此方法效果不理想,鲁棒性较差。
3)神经网络字符识别算法。主要有两种方法:一种方法是先对待识别字符进行特征提取,然后用所获得的特征来训练神经网络分类器。其中,字符特征的提取是研究的关键,特征参数过多会增加训练时间,过少会引起判断上的歧义。另一种方法是充分利用神经网络的特点,直接把待处理图像输入网络,由网络自动实现特征提取直至识别。这种网络互连较多,待处理信息量大,抗干扰性能好,识别率高。但是产生的网络结构比较复杂,输入模式维数的增加可能导致网络规模庞大。
51
4)支持向量机模式识别算法[27]。支持向量机(Support Vector Machine,SVM)是Vapnik及其研究小组针对二类别的分类问题提出的一种分类技术,其基本思想是在样本空间或特征空间,构造出最优平面使超平面与不同类样本集之间的距离最大,从而达到最大的泛化能力。主要有两种方法应用于字符识别:一种是先对待识别字符进行特征提取,然后用所获得的特征来训练SVM分类器。另一种是直接将每个字符的整幅图像做为一个样本输入,不需要进行特征提取,节省了识别时间。
这四种方法中,模板匹配是车牌字符识别最早使用的方法之一,神经网络字符识别算法是目前比较流行的算法,本章重点研究这两种算法。
5.2 模板匹配字符识别
5.2.1 模板匹配字符识别
首先以二维图像的处理为例介绍一下传统的模板匹配算法。算法的基本思想是:将归一化的字符二值图像与模板库中的字符二值化图像逐个进行匹配,采用相似度的方法计算车牌字符与每个模板字符的匹配程度,取最相似的就是匹配结果。
匹配时相似度函数定义为:
2S(i,j)=∑∑f(m,n)?2∑∑fij(m,n)t(m,n)+∑∑tij(m,n)……(5.1) 2ij
m=1n=1m=1n=1m=1n=1MNMNMN
其中,f(i,j)为待识别车牌字符图像中像素点(i,j)的灰度值,这里的取值为0或1,t(i,j)为模板字符图像中像素点(i,j)的灰度值,这里的取值为0或1;M和N为模板字符点阵横向和纵向包含的像素个数。
匹配的步骤为:
1)依次取出模板字符,将模板字符按照上、下、左、右四个方向,在周围五个像素的范围内滑动,每次分别计算出相似度S值,取其中S的最大值做为字符与模板字符之间的相似度函数。
2)依次从待识别的字符与模板字符的相似度中找出最大相似度所对应的模板
52
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
字符,判断是否大于该字符的阈值T,如果S大于T,那么待识别的字符的匹配结果就是该模板字符,反之,如果S小于T,表示不匹配,则需要重新检测。
该匹配算法的缺点主要有:
1)计算量大,公式(5.1)的计算量随着原图像及模板所包含的像素增加而迅速增大,而且执行匹配运算的次数,随着原图的增大而增多,匹配效率不高。
2)原图中字符的平均灰度值的变化会影响到匹配结果的正确性。
3)原图中字符的方位旋转和尺度缩放不适应,会产生字符变形的现象,对匹配结果的正确性有很大影响。
4)抗噪性较差。原图中的噪点对结果有很大影响。
针对上述不足,人们提出了很多改进的算法,例如:序贯相似性检测算法、幅度排序算法、分层搜索的序贯判决算法等。这些算法大都只有在原图比模板大很多且图形比较大的情况下,对速度的提高才很明显。本文采用了一种改进的模板匹配算法。该算法的主要思想是:首先根据字符的结构特征将其进行划分,依次抽取其六个特征,然后根据提取的特征用模板匹配的方法进行识别,输出最后的结果。以数字的识别为例介绍该算法。
5.2.2 创建匹配模板
创建匹配模板是用来匹配分割出来的字符,其尺寸大小应该是一定的。根据我国车牌的特殊要求,将字符模板分为汉字、英文字母和数字模板,其中汉字模板取宋体,英文字母和数字模板来自OCR字库。图像的尺寸太大,模板匹配所需时间就长;但是,如果图像太小,其包含的有用信息就会减少,表达的内容就不够完整,所以模板必须适中。在本系统中,牌照的字符宽度一般不会超过20个像素,为了保证模板图像信息的完整性,同时综合实际牌照中的字符长宽比例关系,以及系统处理速度等,规定二值化后的模板的大小为24×48像素。
在实际的匹配过程中,由于切分出的车牌字符可能变形,或者存在噪点,所以需要对模板进行加权处理。通过加权可以更好地进行相似字符之间的区分,同时应
53
加入一些实际的车牌字符,进行统计分析,提高模板的适用性。
下面以一个二值化模板为例来说明加权的具体方法。图40是字符2的二值化模板,右边是没有加权的模板,左边是经过加权处理的模板,左边模板中的黑色小方块就是加权区域,如果原来黑色为1、白色为0,那么加权区为-1。一般来讲,现在国内使用的车牌识别系统使用的模板大多都是加权的,因为车牌识别系统需要识别的字符样本集比较少,容易通过加权进行区分。
图40 加权后模板与原模板
Figure 40 The weighted template and the original template
5.2.3 提取车牌特征
在字符切分好后,如果直接将其与模板进行对比,所要对比的信息量比较大,程序运行时间将会大大增加。所以首先对切分好的字符进行特征提取,然后根据提取的信息进行分类,最后输出结果。这里,主要使用了类似九宫格的方法,在图像水平方向上将图像均分成三部分,在每一部分用一条水平方向的扫描线从左到右穿过数字,进行查找;同样的,在垂直方向上也将图像均分成三部分,在每一部分用一条垂直方向的扫描线从上到下穿过数字,进行查找,取这六条线上的特征作为车牌图像的特征。
下面以数字2的特征提取为例详细介绍一下图像特征的提取方法:
图41 特征提取
Figure 41 Feature extraction
54
1)水平方向的特征
将数字平均分成上、中、下三部分,在每部分中分别以水平方向的扫描线从左到右穿过数字,然后从上到下进行扫描,计算每条扫描线与黑色像素区域的交点数。计算时,考虑从某点开始连续出现的几个黑像素点为一个交点。根据扫描线的位置,在上部分扫描得到的最大交点数定义为上部特征数,在中间部分扫描得到的最大交点数定义为中部特征数,在下部分扫描得到的最大交点数定义为下部特征数。在数字2中,上部特征数为2,下部特征数为1,中部特征数为1。
2)垂直方向的特征
将数字平均分成左、中、右三部分,在每个部分中分别以垂直方向的扫描线从上到下穿过数字,然后从左到右进行扫描,计算每条扫描线与黑色像素区域的交点数。计算时,考虑从某点开始连续出现的几个黑像素点为一个交点。根据扫描线的位置,在左侧部分扫描得到的最大交点数定义为左部特征数,在右侧部分扫描得到的最大交点数定义为右部特征数,在中间部分扫描得到的最大交点数定义为中间特征数。在数字2中,左部特征数可能为2、也可能为3,右部特征数为3,中间特征数为3。
就这样,得到了数字2的六个特征值,按照从上到下、从左到右的顺序排列依次为:2、1、1、2或3、3、3。
根据上述定义,进行特征提取,就可以得到每个需要识别的字符的特征值。
5.2.4 模板匹配
模板匹配是该算法的最后一步。一般的模板匹配法是用已知的模板和原图像中同样大小的一块区域去对比。然后平移到下一个像素,仍然进行同样的操作直到将所有的位置都对比完。这里只需要将提取出的特征进行对比即可。
具体算法为:给定输入图像I和识别字符类型集{S1,S2,…,Sn},那么字符识别
问题可以描述为找到相关度量函数C(i)的最大的可信度P(SiI)。P(SiI)是通过加
55
权矩阵的计算得到的各个字符匹配的对于最大匹配字符的概率,计算公式如下:
P(SiI)=C(i)…………………………(5.2) Max[C(i)]A
其中A={i,0<i<n}。
算法的实现过程为:
1)根据前面提取的特征值将字符进行一个粗略的分类,将其归入可能的字符集合A中,然后使用失配加权惩罚模型,计算k类字符的相关度量函数值C(k)。
2)从C(k)中找到最大值,并且计算出每类字符的加权匹配概率P(SiI),P(SiI)最大的字符类Si即为所求目标。
5.2.5 模板匹配字符识别法小结
模板匹配字符识别法流程图如图42所示。
图42 模板匹配字符识别流程图
Figure 42 The workflow of template matching character recognition
基于模板匹配的字符识别算法对字符识别之前的车牌的处理算法要求较高,字符清晰度的变化对识别的准确率有较大影响。在实际中为了提高正确率往往需要使用大量的模板进行匹配,处理时间也会相应的增加。只用最开始的模板进行匹配时,
56
343张图片中正确识别出254张,识别准确率为74.1%,平均识别时间为0.7s;在加入一些实际车牌上切分出来的经过二值化的车牌字符之后,识别准确率有了一些提高,343张图片中正确识别出295张,识别准确率为86%,平均识别时间为0.8s;采用特征提取的方法之后,一些容易混淆的字符的识别准确率在一定程度上有所提高,343张图片中正确识别出325张,识别准确率为94.8%,平均识别时间为0.6s。
5.3 基于神经网络的车牌字符识别
5.3.1 人工神经网络
按照美国神经网络学者Nielsen的定义[38]:人工神经网络是一个并行、分布处理结构,它由处理单元及其称为联接的无向讯号通道互连而成。这些处理单元具有局部内存,可以完成局部操作,即它必须仅仅依赖于经过输入联接到达处理单元的所有输入信号的当前值和存储在处理单元局部内存中的值。每个处理单元有一个单一的输出联接,输出信号可以是任何需要的数学模型。
神经网络有许多种,例如径向基神经网络、Hopfield网络、竞争型神经网络、反向传播网络(BP网络)等。现在将神经网络与车牌字符识别相结合的有BP神经网络和径向基神经网络,本课题采用的是在模式识别中广泛使用的BP神经网络。
5.3.2 BP神经网络简介
1986年,Rumelhart和McCelland为首的科学家出版的《Parallel Distributed Processing》一书中,完整地提出了误差逆传播学习算法,即著名的反向传播(Back-Propagation,BP)模型。该模型的提出对神经网络的发展具有里程碑式的意义,大大推动了当时已趋于停滞的神经网络的发展。
BP网络是一种多层前馈型神经网络,其神经元的传递函数是S型函数,输出量为0到1之间的连续量,它可以实现从输入到输出的任意非线性映射。目前,BP网络主要用于函数逼近、模式识别、分类以及数据压缩四个方面。
57
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
BP网络的结构如图43和图44所示[37]。一般包括由输入节点构成的输入层,隐节点构成的隐含层和由输出节点构成的输出层。
图43 BP神经网络结构示意图
Figure 43 The BP neural network structure
a1=f1(W1p+b1)a2=f2(W2p+b2)
a3=f3(W3f2(W2f1(W1p+b1)+b2)+b3)a3=f3(W3p+b3)
图44 三层BP网络示意图
Figure 44 Three layers of BP neural network
从三层网络的示意图可以看出,多层网络中的某一层的输出称为下一层的输入。即:
am+1=fm+1(Wm+1am+bm+1),m=0,1,…,M-1……………(5.3)
这里,M是网络的层数。第一层的神经元从外部接收输入:
a0=p…………………………………(5.4)
它是等式(5.3)的起点。最后一层神经元的输出是网络的输出:
a=aM…………………………………(5.5)
BP网络的学习算法参见参考文献[39]。BP神经网络算法的学习过程由正向传
58
播和反向传播组成。在正向传播过程中,输入信息从输入层经隐含层逐层处理,并传向输出层。每一层神经元的状态只影响下一层神经元的状态。如果输出层得不到期望的输出,则转入反向传播,将误差信号沿原来的连接通道返回,通过修改各层神经元的权值,使得误差信号最小。
BP模型虽然在各方面都有重要的意义,但它存在如下问题:
1)存在局部极小问题。
2)算法的收敛速度慢,通常需要迭代几千步甚至更多。
3)难以决定隐层和隐层节点的个数。
要解决这些问题,就需要对BP算法进行改进。
5.3.3 改进的BP神经网络
BP算法的改进的目的大致分为三个方面:一是提高网络训练的精度;二是提高训练的速度;三是避免落入局部极小值点。常用的方法有:
(1)初始权重的优化
一方面,BP网络的误差曲面存在多个局部最小点;另一方面,算法采用误差梯度下降的方法调整网络权重。这两个方面导致了网络的训练结果极容易落入局部极小点。所以,网络的初始权重对网络的最终训练结果影响非常大,它是影响网络最终能否达到某一可以接受精度的重要因素之一。
2)学习率自适应调整
BP算法的收敛特性和收敛速度很大程度上取决于学习率,对于不同的问题的取值范围也会不同。训练的过程中可以通过改变学习率来提高网络收敛速度。
3)动量法
动量法是指在每个权值调整值上加上一项正比于前一次权重调节量的值,引入动量项后,使得权重的调整向着底部的平均方向变化,即动量项起到缓冲与平滑的作用,有利于改善网络收敛过程中的稳定性,调节网络的收敛速度。
本课题采用了有动量的梯度下降法对神经网络进行改进,提高了学习速度并
59
增加了算法的可靠性。改进算法为:
Wij(k+1)=Wij(k)+η[(1?α)D(k)+αD(k?1)]……………(5.6)
其中,D(k)表示k时刻的负梯度,D(k?1)表示k-1时刻的负梯度,η为学习率,α∈[0,1]是动量因子。当α=0时,权值修正只与当前负梯度有关系,当α=1时,权值修正就完全取决于上一次循环的负梯度了。这种方法加入的动量项实质上相当于阻尼项,它减小了学习过程的振荡趋势,从而改善了收敛性。
改进后的BP算法中有两个参数η和α。步长η对收敛性影响很大,对于不同的问题其最佳值相差也很大,通常可在0.1~0.3之间试探,对于较复杂的问题应该用较大的值。动量项系数α影响收敛速度,在很多应用中其值可在0.9~1之间选择,本系统选择0.94。
5.3.4 应用于字符识别的神经网络设计
设计BP网络的关键之处在于大量的有代表性的训练样本,以及高效、稳定、快速收敛的学习方法。BP网络的应用过程如图45所示。
图45 BP网络的应用过程
Figure 45 The application process of BP Net
本系统采用了四个BP网络来完成所有车牌字符的识别,分别是识别数字字符的BP网络,识别英文字符的BP网络,识别汉字的BP网络,区分汉字、英文和数字字符的分类BP网络。所有的BP网络都是三层结构。
BP神经网络的建立主要是三个层的神经元数目的确定。
1)输入层节点数
BP网络的输入层的节点个数,为图像预处理后所输出的特征的维数。本课题输入层的节点数设为24×48。
60
2)隐层节点数
在BP网络中,隐层节点数不仅与输入/输出层的节点数有关,更与需解决的问题的复杂程度和转换函数的形式以及样本数据的特性等因素有关。一般地,隐层神经元的数目越多,BP网络越精确,但是训练时间也就相应越长。如果隐层神经元选取太多,会造成识别率急剧下降,降低抗噪点能力。确定隐层节点数的基本原则是:在满足精度要求的前提下取尽可能紧凑的结构,即取尽可能少的隐层节点数。
在本系统中,对于实现字符分类的神经网络,其隐层神经元个数可以取少一些;其他三个用来实现字符识别的神经网络,可以根据输出层神经元的多少来确定其个数,即输出层神经元越多,其隐层神经元个数也越多。
3)输出层节点数
输出层的节点数的确定,决定于如何设定标准输出,也就是说如何对目标期望输出进行编码。
用于区分汉字、英文字母、数字的分类BP网络只需要输出三种结果,所以其输出层神经元个数为2,即(0,0),(0,1) ,(1,0)。
用于识别数字字符的BP网络,由于一共只有10个数字,所以采用了8421码进行编码,输出层的神经元数目为4。输出编码为:(0,0,0,0)→0,(0,0,0,1)→1,(0,0,1,0)→2,(0,0,1,1)→3,(0,1,0,0)→4,(0,1,0,1)→5,(0,1,1,0)→6,(0,1,1,1)→7,(1,0,0,0)→8,(1,0,0,1)→9。
用于识别英文字符的BP网络,英文字符一共有26个,所以输出层的神经元数目为5。输出编码为:(0,0,0,0,0)→A,(0,0,0,0,1)→B,(0,0,0,1,0)→C,(0,0,0,1,1)→D,(0,0,1,0,0)→E,(0,0,1,0,1)→F,(0,0,1,1,0)→G,(0,0,1,1,1)→H,(0,1,0,0,0)→I,(0,1,0,0,1)→J,(0,1,0,1,0)→K,(0,1,0,1,1)→L,(0,1,1,0,0)→M,(0,1,1,0,1)→N,(0,1,1,1,0)→O,(0,1,1,1,1)→P,(1,0,0,0,0)→Q,(1,0,0,0,1)→R,(1,0,0,1,0)→S,(1,0,0,1,1)→T,(1,0,1,0,0)→U,(1,0,1,0,1)→V,(1,0,1,1,0)→W,(1,0,1,1,1)→X,(1,1,0,0,0)→Y,(1,1,0,0,1)→Z。
对于用于识别汉字字符的BP网络,由于牌照中的中文字符的种类不超过50个,
61
并且考虑到字符断裂时产生的新字符,所以,假定会输出60个不同的中文字符,所以神经网络的输出层的神经元的个数为6。由于字符较多,这里就不一一列举编码规则了。
以用于识别汉字字符的BP网络为例,其建立BP网络并进行BP网络训练的代码为:
chinese_net=newff(minmax(P),[netDots,S],{'logsig','logsig'},'traingdm','learnh');
chinese_net.LW{2,1}=chinese_net.LW{2,1}*0.01;
chinese_net.b{2}=chinese_net.b{2}*0.01;
chinese_net.trainParam.goal=0.0007;
chinese_net.trainParam.show=20;
chinese_net.trainParam.epochs=3000;
chinese_net.trainParam.mc=0.94;
chinese_net=train(chinese_net,P,T);
在网络训练过程中,可能会出现误差越来越大以致网络无法收敛的情况。这是由于网络中神经元的初始权值选取的不够好,只需重新更换权值就可以实现收敛。
5.3.5 神经网络字符识别法小结
BP网络的算法流程框图如图46所示。
基于BP神经网络的字符识别算法目前属于车牌识别系统的主流算法之一,在车牌识别系统中得到了广泛的应用。但是基本的BP网络存在着收敛速度慢、存在局部极小、难以决定隐层和隐层节点的个数等缺点,所以本系统在应用中采用了有动量的梯度下降法进行改进,即按照某一时刻的负梯度方向修正网络权值,同时加入动量因子,修正负梯度方向的值,使得整个网络能够更快更好的收敛。在整个识别过程中,采用了四个BP网络,分别完成分类、汉字识别、英文字母识别、以及数字识别的功能,首先通过分类网络对输入向量进行分类,判断输入向量是汉字、英文字母还是数字,根据分类结果将输入向量输入到相应的神经网络中进行识别。
62
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
最终,343张图片中正确识别出336张,识别准确率为98%,识别时间为0.4s。
图46 BP算法流程
Figure 46 Flow of BP arithmetic
5.4 本章小结
本章主要介绍车牌字符识别的过程。车牌字符识别是在前面一系列处理后的最后一步,也是计算量很大的一步。本章主要对车牌字符识别中的模板匹配字符识别算法和神经网络字符识别算法进行研究,改进以及对比。
其中,模板匹配字符识别算法主要对特征提取进行了改进,按照字符特点将其划分为六个区域,分别提取每个区域的特征值。可以看出,改进后识别准确率得到了提高。
基于神经网络的字符识别算法主要采用有动量的梯度下降法对原网络进行了改进,按照某一时刻的负梯度的值修正网络,并加入了动量项,用以修正该时刻的
63
网络值。改进后的网络取得了较好的效果。
从下表可以看出,基于神经网络的字符识别的算法在准确率和识别速度上均优于模板匹配字符识别算法。
表1 字符识别方法结果分析 总数 正确数 错误数 正确率 所需时间
模板匹配法
BP网络法 在完成车牌识别系统的定位、字符切分和字符识别的算法研究后,下一章介绍用MATLAB的GUI搭建的测试平台,并采用该平台对上述算法进行测试。
64
6 系统测试及分析
6.1 测试平台搭建
根据上文研究的算法,利用MATLAB的M语言分别实现了车牌识别系统的定位、字符切分和字符识别功能模块,利用MATLAB的GUI工具箱开发了测试系统,验证上面设计的算法在车牌识别系统中的应用效果,
利用MATLAB的图形用户开发环境(GUIDE)设计了本测试平台,流程如下:
图47 车牌识别测试系统流程
Figure 47 The Workflow of the plate license recognition testing system
搭建本测试平台产生的M函数构成了两个相同名称的文件:
1)run.fig。它包含了所有函数的GUI对象或元素的完整图形描述以及它们的空间排列。包含四个菜单:文件,视频设备,识别参数设置,系统设置;一个用于
65
显示汽车图片的axes对象;一个用于显示截取的车牌图像的axes对象;和三个用于输出识别结果的文本框。
2)run.m。它包含了控制GUI操作的代码。该文件含有启动和退出GUI时调用的函数,以及用户和GUI对象交互时执行的回调函数,回调函数中包含了车牌识别的三个模块:车牌定位,车牌字符切分和车牌字符识别。
在GUIDE开发环境下可以方便的添加各个控件,并对其进行排列,具体排列方法在此不再赘述。
启动测试界面时,将会先用load 'global_var.mat'语句导入识别参数设置值,当改变参数设置后,使用update_global_var(muban, range, province, confidence)语句更新识别参数设置值,使之与当前设置一致。然后通过文件菜单导入图像并显示出来,部分代码为:
image=imread(file); %file为图像的绝对路径
axes(handles.PicShow);
imshow(image);
guidata(hObject,handles);
输入的图像信息和识别参数设置值以参数的形式传送到go.m文件中,在该文件中,完成整个车牌的识别。该模块调用三个子模块:车牌定位模块location.m、车牌字符切分模块segmentation.m和车牌字符识别模块ocr.m,其代码为:
[bw, grounding] = location (image); % 从汽车图像中截取出车牌图像
seg = segmentation (bw); % 对截取到的车牌图像进行字符切分 load net.mat; % 导入训练好的改进BP网络
number = ocr(bw, seg, net); % 根据切分的字符识别出具体车牌号 在每个子模块中,先用load 'global_var.mat'语句导入最新的识别参数设置值。识别时首先将图像image以参数的形式输入到location.m中,利用小波变换和投影法对图像进行定位,得到车牌部分的图像bw,同时根据车牌的颜色特征判断出车牌的底色grounding。然后将车牌部分的图像bw输入到segmentation.m中,对其用
66
改进的Otsu算法进行二值化,然后根据其投影进行倾斜校正和字符的切分,得到了切分后的七个字符的图像seg。接着导入net.mat文件,该文件中存有对创建的匹配字符模板进行BP网络训练得到的网络对象net。将切分好的字符图像seg和训练好的网络对象net输入到ocr.m中,调用函数sim模拟一个网络,根据训练好的网络net及输入向量seg进行模拟网络输出,最终得到识别的结果。
最后,将识别结果输出到文本框中,显示在界面上。即完成了车牌识别的整个过程。
6.2 测试平台介绍
根据上述过程搭建的测试平台的界面如图48所示:
图48 车牌识别测试系统界面
Figure 48 The interface of the plate license recognition testing system
该测试平台共设有四个系统菜单,分别是文件、视频设备、识别参数设置和系统设置。各菜单功能定义如下:
67
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
1)文件菜单如图49所示:
图49 测试系统文件菜单
Figure 49 The file menu of the plate license recognition testing system
文件菜单包括三个子菜单:录像文件、图片文件和清除本地记录。其中录像文件用于导入视频,然后从视频中抓出车辆图片,用于后续识别。图片文件用于直接导入已抓取的图像文件,然后进行识别。清除本地记录用于清除当前窗口中的所有图像信息。
2)视频设备菜单如图50所示:
图50 测试系统视频设备菜单
Figure 50 The video device menu of the plate license recognition testing system
视频设备菜单主要用于对所采用的视频设备属性进行设置,包括四个子菜单:设备编号、显示设置、通道设置、格式设置。这里假定有四个视频设备,安装在不同地方,拍摄路面情况,可以先从设备编号中选择要打开的视频设备,然后对该设备所抓取的汽车图像进行识别。如果视频设备打开成功,就可以对其显示方式、显
68
示通道及格式进行设置。
3)识别参数设置如图51所示。
图51 测试系统识别参数设置菜单
Figure 51 The recognition parameters setting menu of the testing system
在识别参数设置中,首先是车牌模板设置。这里包括了目前常用的车牌:民用货车尾牌(单行)、民用车牌(2002个性化)、警车车牌、武警车牌、军用车牌及民用车牌,由于目前仍有大量92式的车牌存在,所以这里的民用车牌又分为92式和92式黄牌,同时新的个性化车牌都归入了2002个性化车牌中。车牌模板的右边是识别范围,包括0~100%,可以对所要识别的汽车图像的范围进行设置,即上、下、左、右四个边界范围的设置。车牌图像大多集中于图像的下半部分,所以可以选择较小的范围,缩小需识别图像的范围,有利于识别速度的提高。在车牌模板的下边是省份和置信度设置。省份设置是在区、省市代码模糊的时候可以进行直接替换。置信度用于设置输出的最低置信度,取值一般在75~90之间,如果取值太小,则出错的概率加大,如果取值太大,则可能导致无法正确截取到车牌。当上述参数都设置好以后,即可点击确定按钮保存上述设置。
4)系统设置菜单设置如图52所示。
69
系统设置下只设了一个子菜单,即初始化配置文件。其主要功能是将所有的设置都恢复到系统默认状态,即清除了当前显示的图像;视频设备选取1#设备;识别参数设置中,车牌模板全选,识别范围上边为0、下边为100、左边为0、右边为100,省份为空,置信度为75。初始化配置文件在重新启动程序时生效。
图52 测试系统系统设置菜单
Figure 52 The system parameters setting menu of the testing system
6.3 测试结果分析
测试数据库为353张卡口图片,像素大小都为768×288,均为路口摄像头拍摄得到的实物图像。
使用测试系统的步骤为:
1)对识别参数进行设置。由于353张测试图片几乎都是民用车牌,所以车牌模板选择了民用车牌(2002个性化)、民用车牌(92式黄牌)以及民用车牌(92式)。识别范围的设置为:上边为0,下边为100%,左边为0,右边为100%。这里的省份无设置,置信度为75。
2)从文件菜单导入图片,然后系统自动进行识别,显示结果信息。
例如,对测试图片数据库中的图23进行识别时,首先用文件菜单导入测试图片数据库中的图片23.jpg,这张图片上汽车的车牌号为沪DE6933。测试系统得到的结果如图53所示。在最上面显示出导入的汽车图片,左下角第一栏显示了定位后得到的车牌;第二栏分别显示出了识别出的车牌号码,车牌的颜色,以及车牌的宽度;第三栏指明了整幅图像的分辨率,最后一栏显示出导入的汽车图像的文件名,指明是对哪张图片进行的识别。
70
下面是一些测试中的典型图片的处理结果分析。
1)图53中的车辆图像存在着曝光过度的问题,车牌部分和其余部分对比度较差,采用传统方法进行边缘检测时边缘模糊现象比较严重,而且用改进前的Otsu算法进行二值化处理有部分车牌字符信息缺失,造成难以识别。本系统采用了小波变换和改进的Otsu算法进行识别。虽然图像对比度较差,但车牌部分的垂直特征还是很明显的,用小波分解的高频信息可以较准确的捕捉到这部分信息,对车牌进行准确定位。采用改进的Otsu算法对二维直方图范围进行重新划分后,扩大了目标物体的区域,防止了目标物体被误认为是背景的问题,完整的得到了车牌字符的二值化图像。可以看到,本系统正确的截取了车牌图像,准确的识别出了车牌字符。
图53 测试分析(1)
Figure 53 The testing analysis(1)
2)图54是一幅黄色车牌的车辆图片。图中可以看到,车牌上方有一个很大的排气格栅,两边车灯的大小也与车牌大小比较相像,在使用传统算法时,这些都对车牌的准确定位造成很大的干扰。但是,车灯部分的垂直纹理特征很弱,在使用小波分解提取高频特征后,几个车灯部分的信息几乎全部消除了,在进行形态学处理
71
后,也只留有几个很小的区域块,在车牌初步定位时即被认作伪车牌而去除。排气栅格部分虽然包含较多的垂直纹理特征,但是其尺寸比车牌要大许多,在车牌的初步定位时也被当成伪车牌去除掉。经过上述的处理,最后可以准确定位到真正的车牌区域。根据车牌颜色特征判断出车牌是黄色车牌之后,进行二值化处理,将二值化处理的结果进行反色处理,将其改为字符为白色、背景色为黑色的二值图像,接着进行字符的切分,最后采用改进的BP网络准确识别出了车牌字符。
图54 测试分析(2)
Figure 54 The testing analysis(2)
3)图55是对车牌倾斜比较严重的牌照的识别处理情况。该车牌边框信息较弱,在车牌定位二值化处理之后,车牌边框已被去除,这时使用Hough变化查找倾斜角度时,车牌水平方向和垂直方向最长的一条直线其实也是倾斜的,这时查找的倾斜角度并不是真正的倾斜角度,根据该角度进行校正后的车牌依然是倾斜的。而采用投影法,由于判断的标准是MATLAB坐标轴,查找出倾斜角度并进行校正后,车牌的位置就很正了。倾斜校正并切分字符后,采用改进的BP网络进行字符识别时由于“浙”字有些许变形,很容易和“湘”字混淆,造成识别错误,在增加了模板
72
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
之后,就可以准确的识别出来了。
图55 测试分析(3)
Figure 55 The testing analysis(3)
图56 测试分析(4)
Figure 56 The testing analysis(4)
73
4)图56中车牌部分字符磨损,因此在用传统的方法进行定位的时候很容易由于边缘检测的边缘不明显而使得定位后的车牌部分缺失前两个字符,但是使用小波变换分解后强化了对其垂直分量的提取,使得车牌部分完整的定位了出来。在车牌二值化的时候,如果前两个字符二值化效果不好,会导致字符信息缺失,给BP网络的识别带来了很大的困难。使用改进的Otsu算法之后,扩大了目标物体的范围,使得前两个模糊的字符的主要边缘信息都得到了保留,在改进的BP网络中,加入一些较模糊的字符模板之后就能够正确识别。
图57 测试分析(5)
Figure 57 The testing analysis(5)
5)图57中,由于汽车的位置接近摄像头的边缘,导致车牌位于整幅图像的左侧,截取时左边颜色较深,为较强干扰信号,第一个字符甚至有些模糊,而且车牌本身的悬挂位置也是倾斜的。在将图像进行预处理后,发现左边字符和背景的对比度较差,如果采用传统的方法进行定位,第一个字符很容易就会丢失。在使用小波变换提取的边缘图像中,敏锐的捕捉到了首字符的垂直边缘信息,从而完整的定位
74
了车牌。采用Otsu算法进行二值化的时候,“鲁”字的上半部分几乎全部被作为目标处理,造成无法识别。采用改进的Otsu算法后,其自适应的特点对目标和背景做了很好的区分,得到了较清晰的字符轮廓,再采用改进的BP网络正确的识别出了字符。
但是系统还有一些待改进的地方,例如对于图58中的图片无法定位。
图58 测试分析(6)
Figure 58 The testing analysis(6)
图中,车牌图像较为模糊,与图像非车牌部分对比度很差,车牌上方有很长的垂直的排气格栅。而本系统中使用的小波变换的算法,主要是依靠提取车牌垂直部分的条纹信息来进行车牌的定位,因此,在车牌较为模糊的情况下,垂直的排气格栅对车牌的定位造成了很大的干扰,从而出现了车牌无法识别的情况。可以考虑在初步定位后对其垂直投影进行分析,如果其垂直投影不满足车牌图像垂直投影图中几大峰群的特点,则可将其判断为伪车牌,从而舍弃该部分,对于剩余部分进行重新定位,直到查找出车牌为止。
图59中的车牌则在字符识别方面出现了易混字符识别错误的问题。
75
图59 测试分析(7)
Figure 59 The testing analysis(7)
图中,车牌中的“沪D”被识别成了“沪O”,这是由于字母“D”和“O”的特征非常相近造成的。说明系统采用的模板还是不足以区分两者的信息,可以考虑对于字母“D”多增加一些加权的模板,同时增加一些从车牌上获得的字符模板来训练BP网络。
采用搭建的测试平台对353幅768×288的卡口车辆图像进行识别,除去有四幅图像由于摄取的图片中只拍到了汽车的部分图像,导致没有车牌而无法进行识别之外,其余车牌的识别结果如表2所示。
表2 车牌识别结果分析 总数 正确数 错误数 准确率
车牌定位
车牌字符识别 识别时间~1s
76
从上面的表格可以计算出,整个车牌系统的识别率为96.2%。系统可以较准确的进行定位,无法准确定位的车牌图像往往是由于车牌上方有垂直条纹、且大小与车牌相仿的图像块,这些干扰的去除需要对算法的进一步改进,例如可以考虑在粗定位后对图像的垂直投影图进行分析,将不符合几大峰群条件的伪车牌部分去除,然后重新进行搜索。车牌字符识别的准确率达到了98%,还是比较理想的,其中,字符识别错误的原因大多是由于字符特征非常接近,结果无法识别,可以通过增加字符模板解决这个问题。
综上所述,本系统具有以下特点:
1)车牌识别准确率较高,达到了96.2%,基本满足需求;
2)车牌系统适应性较好,对天气的变化以及车身的弱干扰有较好的适应性; 3)系统的运行时间在0.7s~1s之间,实时性比较好。
6.4 本章小结
在车牌的定位、字符切分和字符识别的算法研究的基础上,本章搭建了测试平台,对所研究的算法进行测试。通过对353张卡口图像的识别,车牌识别准确率达到了96.2%。测试结果表明此系统具有较好的识别准确率、实时性和鲁棒性。采用小波变换提取边缘信息,并用改进的Otsu算法进行字符的二值化之后,对于光照条件较差、较为模糊的各种底色车牌都能做到较准确的识别。但是系统还存在一些不足,例如垂直干扰可能造成无法定位,有些相近的字符无法区分等,还需要对算法做进一步的改进。
77
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
7 总结与展望
7.1 总结
车牌识别系统作为智能交通系统中重要的一部分,近年来引起专家们的重视,并已有部分产品投入使用。但在实际使用过程中,仍然存在着系统移植性差、对光照的适应性差、准确率不够高等缺点,在后续处理中还需人工辅助完成,所以对车牌识别系统的算法的研究改进一直在进行。
本文以MATLAB为开发工具,在353张卡口汽车图像组成的数据库的支持下,对车牌识别进行了研究,对多种算法进行了分析、比较与改进,并提出了一些自己的见解,效果较好。
在课题的研究过程中,主要完成了以下工作:
1)在对国内外大量文献的阅读研究基础上,使用MATLAB开发了一套车牌识别系统,完成了车牌定位、车牌字符切分和车牌字符识别等功能,搭建了系统测试平台。实验证明,整个系统的识别准确率达到96.2%,单幅图像识别时间在0.7s~1s之间,基本满足实际要求。
2)车牌定位作为车牌识别系统的第一步,对识别准确率和运行时间有很大影响。在车牌定位中,最重要的是边缘的提取,边缘提取的效果好,后面进行形态学处理后车牌特征明显,车牌定位的准确性就高。本系统采用小波变换分解提取垂直分量的算法来提取边缘,有效的抑制了噪点的影响,在其后采用初步定位与精确定位相结合的方法实现了车牌的定位。小波变换分解后的高频垂直分量和低频水平分量,非常有益于图像特征的提取。从对小波变换的分析图来看,进行小波变换分解后,车牌部分的高频特征与非车牌部分的特征有着明显的差异,因而对车牌的定位
78
有很大帮助。在车牌识别中,如果仅仅应用车牌特征,或者仅仅使用投影法进行定位,车牌图像定位到非车牌区域的可能性会比较大,所以将两者结合,通过两次定位,可以达到较好的效果。实验证明,在349张图片中,最终准确定位的图片有343张,准确率为98.3%,较好的满足了要求。
3)车牌的二值化对于车牌字符识别有着非常重要的作用。二值化效果好,车牌图像的特征就明显,可以更好的满足后面的车牌字符切分与识别的需要。二值化算法的阈值的选取对于二值化的效果有很大的影响,这里采用了全局阈值的算法,传统的Otsu算法中,使用一维算法得到的特征不够明显,无法满足要求。而传统的二维算法计算范围缩小,可能会使得车牌不完整,所以本文对其进行改进,扩大了二维算法的计算范围,将复杂度降低为一维,在获得良好效果的同时,运行时间有所缩短。实验证明,改进的二维Otsu算法效果较好。
4)车牌的倾斜校正对车牌字符识别有很大的影响。一个倾斜的车牌字符的识别与一个很正的车牌字符的识别是不一样的。传统上,很多系统采用Hough变换来进行校正。但是Hough变换要从图像中截取较长一段直线来作为参照物,这样就需要前面保留有车牌边缘,且此边缘的横线和竖线都满足需求,这在实际中较难操作。本系统利用车牌水平投影,采用线性拟合的方法检测车牌的倾斜角度。借助MATLAB图像坐标轴的横轴确定倾斜角度,保证了参照物满足对横线和竖线的要求。实验证明,用投影法检测牌照的角度,然后使用坐标变换方法进行倾斜牌照校正处理,方法简单且效果良好。
5)车牌字符识别是车牌识别系统识别车牌的最后一步。传统算法中模板匹配字符识别和神经网络字符识别都是常用的算法。这里采用同一个模板数据库,利用前面切分好的字符,对两种方法进行了比较研究。对于模板匹配字符识别,在传统算法的基础上,对车牌字符的特征提取进行了改进,将其划分为六个部分,统计出各部分的特征,改进后识别准确率达94.8%。对于神经网络字符识别方法,由于传统的BP网络存在收敛速度慢等问题,所以对其进行了改进,采用有动量的梯度下降法,在原网络中加入了动量项,大大的改善了网络的收敛性,改进后识别准确率
79
达98%。实验结果证明,神经网络字符识别的准确率和运行时间均优于模板匹配字符识别的算法。
7.2 展望
目前的车牌识别系统在快速发展中,虽然已经有一些公司开发的产品取得实际应用,但是在准确率和识别速度方面仍有很大的提高空间,对算法的研究仍然是车牌识别的一个重点。本课题还可在以下几个方面进行深入的研究:
1)与摄像头等硬件设备相连接,进一步改进算法,将设计的系统产品化。
2)本文中的算法设计还需更加的优化,比如在车牌初步定位后对得到的区域的垂直投影进行判断,将不符合车牌区域多个集中峰群特征的区域舍弃,直到找到车牌区域为止;在字符识别模板方面,增加易混淆字符的加权模板,并将识别出的字符做为模板,从而增大模板的数量。使得系统的准确率更高,鲁棒性更好。
3)在将来的牌照识别系统中,可以开发出更多的功能以得到更多的车辆信息,比如说:车型、车速等。
4)目前的车牌识别系统只能处理单个车牌的图像,对于一幅图像中多个车牌的识别无能为力,本文提出的车牌识别算法也是针对单一车牌图像的。在同一图像中快速准确、鲁棒地识别多个车牌,是车牌识别系统未来发展的方向之一。
通过对本课题的研究,笔者感觉车牌识别仍有许多内容需要学习,希望能够得到专家的指正,也希望获得更多的建议和意见。
80
参考文献
[1] 王丰元,计算机视觉在交通工程测量中的应用,中国公路学报,1999,Vol.15(7),p32~p34
[2] Yuntao Cui,Qian Huang,Automatic license extraction from moving vehicles, IEEE Transaction on Pattern Analysis and Machine Intelligence,1999,7(4),p126~p130
[3] Eun Ryung Lee,Kee King,Automatic recognition of a car license plate using color image processing,Journal of Korea Institute of Telematics and Electronics, 1995,24(2) ,p128~p131
[4] Luis Salgado. Automatic car plate detection and recognition through intelligent vision engineering. IEEE Trans PAMI,1999,vol.17,p71~p76
[5] 刘智勇,刘迎建,车牌识别中的图像提取及分割,中文信息学报,2000,14(4),p26~p29
[6] 熊军,高敦堂,沈庆宏等,基于字符纹理特征的快速定位算法,光电工程,2003,30(2),p60~p63
[7] 陈振学,汪国有,刘成云,一种新的车牌图像字符分割与识别算法,微电子学与计算机,2007,24(2),p42~p44
[8] 张引,潘云鹤,彩色汽车图像牌照定位新法,中国图像图形学报,2001,6(4),p374~p377
[9] Daubechies I.,Ten Lecture on Wavelets.SIAM,Philadelphia,1992
[10] 飞思科技产品研发中心.MATLAB 6.5辅助小波分析与应用,北京,电子工业出版社,2003
[11] 郑治真,沈萍,杨选辉等,小波变换及其MATLAB工具的应用,北京,地震出版社,2001
[12] 飞思科技产品研发中心,MATLAB 6.5辅助图像处理,北京,电子工业出版社,2003
[13] 胡小锋,赵辉,Visual C++/MATLAB图像处理与识别实用案例精选,北京,人民邮电出版社,2004
[14] Ming G.He,Alan L.Harvey,Hough transform in car number plate skew detection. ISSPA,1996,25-30,p593~p597
高隽,梁栋等,基于分形维数的车牌字符识别,中国公路学报,2002,[15] 甘龙,
15(4),p75~p77
81
[16] 迟晓君,孟庆春,基于投影特征值的车牌字符分割算法,计算机应用研究,2006,7,p256~p257
[17] 韩智广,老松杨,谢毓湘等,车牌分割与校正,计算机工程与应用,2003,9,p210~p212
[18] Trier,Jain A.K,Goal-directed evaluation of binarization methods,IEEE Trans Pattern Analysis and Machine Intelligence,1995,17(12),p1191~p1201
陈继荣,基于修正思想的车牌图像定位与二值化处理,计算机工程,[19] 洪健,
2007,33(8),p175~p177
[20] 潘梅森,张奋,雷翅阳,一种车牌号码图像二值化的新方法,计算机工程,2008,34(4),p209~p211
[21] 欧阳庆,不均匀光照下车牌图像二值化研究,武汉大学学报(工学版),2006,39(4),p143~p146
[22] N Otsu,A threshold selection method from gray-level histograms[J] ,IEEE Transaction on System Man and Cybemetic,1979,9(1) , p62~p66
[23] 郝颖明,朱枫,2维Otsu自适应阈值的快速算法[J],中国图像图形学报,2005,10(4),p484~p488
[24] Kesidis A.L,Papamarkos N,On the Inverse Hough Transfom,IEEE Transaction on Pattern Analysis and Machine Intelligence,1999,21(12),p1329~p1343
[25] 吴大勇,魏平,侯朝桢等,一种车牌图形中的字符快速分割与识别方法,计算机工程与应用,2002,(3),p232~p233
[26] 刘静,几种车牌字符识别算法的比较,电脑与电信,2008,(8),p72~p74
[27] 吴进军,杜树新,SVM在车牌字符识别中的应用,电路与系统学报,2008,13(1),p84~p87
[28] 高学,金连文,尹俊勋等,一种基于支持向量机的手写汉字识别方法,电子学报,2002,30(5),p651~p654
[29] Krebel Ulrich H G,Pairwise classification and support vector machines
Massachusetts,The MIT [A] ,Advances in Kernel Methods,Support Vector Learning[C],
Press,1999
[30] Bennett K,Blue J,A support vector machine approach to decision trees[R] ,Resselaer Polytechnic Institute,Troy,NY,R.P.I Math report,1997,p97~p100
[31] Hsu C W,Lin C J,A Comparison on Methods for Muti-Class Support Vector
82
59基于MATLAB的车牌识别系统研究(课设参考文献)_牌照识别
Machines,technical report,Dept. of Computer Science and Information Eng.,Nat’ Taiwan Univ. ,2001
[32] 王海涛,黄文杰,朱永凯等,基于聚类分析与神经网络的车牌字符识别,数据采集与处理,2008,23(2),p238~p242
[33] 何通能,贾志勇,基于小波矩的车牌字符识别研究,浙江工业大学学报,2005,33(2),p170~p172
[34] 王润民,钱盛友,邹永星,基于SVM混合网络的车牌字符识别研究,为计算机信息,2007,23(12-1),p222~p224
[35] Han A.Hegt,Ron J.Dela,High performance license plate recognition system,IEEE Transaction on Pattern Analysis and Machine Intelligence,1998,7
(9),p132~p137
周孝宽,车牌图像的快速匹配识别方法,计算机工程与应用,2003,[36] 胡爱明,
(7),p90~p91
[37] Martin T.Hagan,Howard B.Demuth,Mark H.Beale,Neural Network Design,北京,机械工业出版社,2002
[38] 丛爽,面向MATLAB工具箱的神经网络理论与应用[M],合肥,中国科学技术大学出版社,1998
[39] 蒋宗礼,人工神经网络导论[J],北京,高等教育出版社,2008
83
致谢
两年半的学习生活,使我感慨颇深。在此,感谢所有在学习和生活中给予我关心和帮助的人们。
首先我要感谢我的导师陈洪亮教授。我在学业上取得的成绩与陈老师的悉心指导是分不开的。陈老师深厚的专业知识背景和开阔的视野给我很多启发和帮助,以宽容的心态对待我的个性,给了我广阔的发展空间,让我不仅对本专业还对其它相关专业有了深刻的认识。在待人处事方面,陈老师也给了我很多教诲,让我对人、对社会有了更全面的认识。
其次我要感谢电工电子实验教学中心张峰老师,殳国华老师,王昕老师以及其他各位老师。他们以其严谨的治学风格,认真做实事的态度让我受益匪浅。
我还要感谢实验室的各位同学:曹爱华,任宁,董志坤,晏立等,以及B0603194班的林建平、王广文、朱子晟等同学,同时非常感谢朱林师兄,他们在日常生活和学习中给我提供巨大的帮助和便利。
最后我要感谢我的家人,特别是韩斐,感谢他们多年以来对我的无私关怀和照顾,他们一直是我前进的动力,支持我克服一个又一个困难。
84
上海交通大学硕士学位论文 攻读学位期间发表的学术论文
攻读学位期间发表的学术论文
[1] 王璐,陈洪亮,步进电机驱动器保护电路设计,电工技术,2008年第十一期,已发表
85
基于MATLAB的车牌识别系统研究
作者:
学位授予单位:王璐上海交通大学
本文链接:http://d.g.wanfangdata.com.cn/Thesis_D058677.aspx
授权使用:沈阳理工大学(sylgdx),授权号:5359285f-f5a1-4ef7-901f-9e6101195dce
下载时间:2011年1月4日
三 : 基于MATLAB的图像识别技术的原棉异纤在线检测
??第23卷??第2期2004年4月天??津??工??业??大??学??学??报Vol.23??No.2
????????????????
JOURNALOFTIANJINPOLYTECHNICUNIVERSITYApril??2004
基于MATLAB的图像识别技术的原棉异纤在线检测
艾世一,王跃存,刘??迪
1
1
2
??
(1.天津工业大学信息与通信学院,天津300160;2.天津纺织集团天一有限公司,天津300170)
摘??要:基于MATLAB图像识别技术开发了原棉异纤在线检测系统,讨论了原棉图像自动采集及判别处理系统的
软硬件结构,分析其系统初始化、预处理、图像特征提取及判别的过程和原理.实际验证,应用本系统的原棉异纤在线检测,识别率可达到99%以上,从而可以达到减轻工人劳动强度和提高生产效率的目的.
关键词:图像处理;图像识别技术;在线检测
中图分类号:TS104.22??????文献标识码:A??????文章编号:1671??024X(2004)02??0070??04
On??linemeasuringforunusual??fineinrawcottonbasedonimage??recognitiontechnologywithMATLAB
AIShi??yi1,WANGYue??cun1,LIUDi2
(1.SchoolofInformationandCommunication,TianjinPolytechnicUniversity,Tianjin300160,China;2.TianjinTextileGroup,TianyiCoLTD,Tianjin300170,China)
Abstract:Thedifferentfineonlinedetectionsystemofrawcottonbasedonimage??recognitiontechnologywithMATLAB
isdescribed.Thesoftwareandhardwarestructureoftheonlinemeasuringsystemarediscussed,andtheprinci??pleofthesysteminitial,pretreatment,image??characteristiccollectionanddifferentiatesareanalysed.Ithasprovedthat,usingthissystem,thediscerningratecanbemorethan99%,thuscanreduceworker??slaborin??tensityandimproveproductionefficiency.
Keywords:imageprocess;image??recognitiontechnology;on??linemeasuring
????棉花在采摘、加工和运输等过程中经常混入一些杂质,为保证纱线质量,这些杂质在纺纱前必须彻底清除.一般的杂质,如沙石泥土等颗粒性物质,其比重或形状与棉纤维有较大差异,因此,可以通过机械的方式进行除杂.但是像头发、细绳头、尼龙草等纤维状的杂质很难用机械的方法将它们清除,需要用其他方法进行清除.目前,图像识别技术已经在许多行业得到了应用[1].随着以MATLAB为代表的高性能数值计算工具的出现,算法的实现变得更加得简单和高效,从而推动了图像识别技术的进一步发展,使其应用范围更加广泛.同时,随着纺织机械技术的提高,使得图像处理技术在纺织行业的应用具有了实际意义.本文重点讨论原棉图像的采集与检测处理系统的软硬件结构、理论基础以及基于MATLAB的图像的判别计算,并对实验结果进行分析.
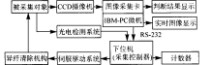
1??系统的组成及工作原理
????图像采集及处理系统的原理图如图1所示.图中CCD摄像机采用16位黑白普通摄影头,图像采集卡采用普通PCI电视影像采集卡.图像采集及检测处理系统的工作流程是:当被检测对象(原棉)走到某一设定位置时,由光电检测系统自动产生一个 对象到!电脉冲信号,并将该信号送给由单片机构成的下位采集控制器,采集控制器检测到该信号后立即通过RS??232串行口向上位微机发送 请采样!信号.上位IBM??PC微机接收到该信号后立即采集一帧BMP位图格式的图像,并产生一个相应的BMP位图格式图像文件,然后对该位图文件中的图像数据阵列进行相应的预处理及判别计算,以决定被检测原棉中是否含有异纤.当上
??????:(?),,,;(1956?),,,,.
第2期????????????????艾世一等:基于MATLAB的图像识别技术的原棉异纤在线检测?????????????????71?
位IBM??PC微机处理判别完一帧图像后,立即将判别结果信号通过RS??232串行口发送给下位采集控制器,下位采控器随即对接收到的判别结果信号进行识别和显示控制决策:若结果为 不合格!立即发出 清除异纤!控制命令,经伺服放大后驱动清除机构在预定的位置上清除异纤,同时记录下清除异纤的个数;若处理结果为 合格!,则发出默许信号,则对象通过[2].在下位采集控制器发出相应的控制信号之后,随即检测是否有下一个 对象到!信号,若有,则立即采集下一帧BMP图像并进行相应的处理,如此往复
.
L个灰度级,具有第k个灰度级的灰度rk的像素共有nk个.则第k个灰度级,或者说rk出现的频率为:nk
????k=0,1,2,?,L-1N
????这个关系也可以用图形表示.这个图形是由灰度??????hk=
轴及一系列垂直于灰度轴的线段组成,垂足f=rk,各线段长度与hk成正比.
????直方图hk虽然不能直接反映出图像的内容,但对它进行分析可以得出图形的一些反映出图像特点的特征.通常一幅均匀量化的自然图像的灰度直方图在低值灰度区间上频率较大,这样的图形较暗区域中的细节常常看不清楚.为使图像变清晰,通常可通过变换使图像的灰度动态范围变大,并让灰度频率较小的灰度级经变换后频率变得大一些,使变换后的图像灰度直方图在较大的动态范围内趋于均化.事实证明,通过图像直方图均化进行图像增强是一种有效的方法.
图1??图像采集及处理系统原理图
Fig.1??Principlepictureofimagerecognitionsystem
????用图像f(x,y)的直方图代替灰度的分布密度函数pf(f),则直方图均化后的图像g为:??????f=T[f]=
2??软件结构及功能
????本图像检测处理软件的结构主要包括:图像采集及预处理、图像特征提取、图像判别等几个功能模块[3].以下分节对各功能模块进行论述.2.1??图像的预处理
????图像的预处理是在特征提取算法之前的一个必要的也是很关键的过程,其作用是在特征提取之前使图像的边缘尽可能地明显,噪声尽可能地减小,从而使后面的特征提取算法得到最好的结果.图像增强是预处理过程中常用的方法,为了改善视觉效果或者便于人和机器对图像的理解和分析,根据图像的特点或存在的问题采取的简单改善方法或者加强特征的措施.在图像增强的众多方法中,直方图均化是一种十分有效的方法.图像的直方图是图像的重要统计特征,它可以认为是图像灰度函数的近似.通常图像的灰度密度函数与像素所在的位置有关,例如设图像在点(x,y)处的灰度分布密度函数为p(x,y),那末图像的灰度密度函数为:??????p(z)=
p(x,y)dxdySD
????对于数字图像,可以对上述公式作离散近似.设原图像的像素总数为N,灰度级的个数为L,第k个灰度级出现的频数为nk.若原图像f(x,y)在像素点(x,y)处的灰度为rk,则直方图均化后的图像g(x,y)在(x,y)的灰度值sk为:
L??L=0N
????通过对图2和图3的比较可以看出,经过直方图??????sk=T[rk]=
均化,图像的细节更加清楚了,而从图像的直方图上可以看出,在直方图调整之前,高灰度的比例很大,经过直方图调整,各灰度等级的比例更加平衡,使图像对比度增强,从而使得图像的边缘更加明显.
k
#p(u)du
f0
f
#
图2??原始图像Fig.2??Primitiveimage
式中,D是图像的定义域;S是区域D的面积.在实际中可以用数字图像灰度直方图来代替.灰度直方图是一个离散函数,它表示数字图像每一灰度级出现频率
,2.2??图像特征提取算法
????图像特征提取计算是图像处理的关键部分,在本

?72?????????????????????????????????天??津??工??业??大??学??学??报????????????????????????????第23卷
图4??卷积运算模板Fig.4??Template

image
图3??直方图均化后的图像Fig.3??Pictureafterimageenhancement
系统中包括卷积滤波和中值滤波两步,其中卷积滤波是通过将经过预处理的图像矩阵与模板矩阵作卷积来实现的;而其得到的结果再用中值滤波进行降噪,从而能提取出图像中异纤的完整图像.2.2.1??卷积滤波
????卷积滤波是线性滤波的一种,用来对图像的某种特征进行加强,而去除其它特征.经过预处理的图像与适当的模板作卷积可以起到滤除噪声、提取边缘的作用.在本系统使用的算法中,二维卷积是通过快速傅立叶变换来实现的,这也是快速傅立叶变换的一个重要应用.由线性系统理论可知,两个函数卷积的傅立叶变换等于两个函数的傅立叶变换的乘积.该特性与快速傅立叶变换一起应用可以快速计算函数的卷积.
????假设A为M*N图像矩阵,B为P*Q模板矩阵,则快速计算卷积的方法如下:%对A和B补0,使其大小都为(M+P-1)*(N+Q-1).&对矩阵A和B分别进行快速傅立叶变换(FFT).?将两个FFT结果相乘,再对得到的乘积进行傅立叶反变换.对卷积运算而言,模板的选择是最重要的.根据原棉中异纤的形态多为纤维状丝状物,并经过大量实验,最终选取如图4所示的大小为25*25的圆形模板,并对圆周上的像素赋予比较高的权值,从而突出了圆周上各点的特征.此模板最大程度地提取了图像中异纤的曲率特征,去除了图像中原棉的特征,从而达到很好的效果.
????如果用A表示经过预处理的图像矩阵,用B表示图4所示的模板矩阵,C表示卷积滤波的结果,使用MATLAB图像处理工具箱提供的二维快速傅立叶函数fft2和二维傅立叶反变换函数ifft2,则有以下计算式:
??????C=ifft2(fft2(A)(fft2(B))
????如图5所示,卷积滤波后的输出图像比较完整地提取了异纤的图像,并且只含有少量易于处理的噪声

.
图6??中值滤波后的图像
Fig.6??Pictureaftermiddlevaluefiltration
图5??卷积滤波后的图像
Fig.5??Pictureafterconvolutionfiltration
2.2.2??中值滤波
????中值滤波是抑制噪声的非线性处理方法.所谓中值是指对于给定的n个数值{a1,a2,?,an},将它们按大小有序排列.当n为奇数时,位于中间位置的那个数值称为这n个数值的中值.当n为偶数时,位于中间位置的两个数值的平均值称为这n个数值的中值,记作med(a1,a2,?,an).中值滤波就是这样的一个变换,图像中滤波后某像素的输出等于该像素邻域中各像素灰度的中值.
????根据卷积滤波后图像的噪声点分散的特征,并经过多次实验,决定采用3*3模板的中值滤波,即某一像素的灰度值等于其周围8个相邻像素灰度值的中值.MATLAB图像处理工具箱提供了 medfilt2!函数实现中值滤波运算[4].如图6所示,经中值滤波后的图像比较完整地保留了异纤的特征,消除了绝大多数的噪声,可进行下一步的决策判断

.
第2期????????????????艾世一等:基于MATLAB的图像识别技术的原棉异纤在线检测?????????????????73?
2.3??判别算法
????判别算法用以把待检测对象的计算机感官指标与标准指标比较,从而确定待检产品是否合格.判断图像中是否含有异纤的根据是图像中灰度值非零像素的最大连通数是否超过一定的阈值[5],即在八邻域范围内,相互连通的非零像素数的最大值是否超过阈值.但计算过程并非要计算图像中所有像素的连通数取其最大值,而是依次计算非零像素的连通数,若遇到超过阈值的像素便马上停止继续计算,并作出判断.很明显,这种算法能够节省大量的运算时间.
????(1)关于图像检测速度,采集并检测一帧大小576)432像素的BMP位图须用1.71s,按此速度,每分钟可检测35幅图像.与人眼识别、手工清除异纤相比,效率略低.今后,可以通过进一步简化算法来缩短检测时间,从而提高整个系统的工作效率.
????(2)关于图像识别率,该检测软件对异纤的识别率均在99%以上,而且通过对检测算法的进一步优化,识别率可望进一步提高.
????(3)关于检测准确度,对感官指标判别的准确率均在98%以上.准确率略低于识别率的原因在于,系统将少量的无异纤图像识别为有异纤,但对整个系统的工作效率影响不大.同样也可以通过进一步优化算法来提高准确率.
3??原棉异纤在线检测的试验结果及分析
????首先将图像采集卡及摄像头接入上位IBM??PC通用微型计算机,并设置好检测环境,如灯光环境及待检测图像背景等,以使待检对象的边缘清晰;其次要视具体情况设置好图像检测处理软件的各相关参数、视频亮度、对比度和视频格式等软件环境;然后即可进行检测实验.该实验的检测项目包括:采集一帧位图BMP图像,检测处理一帧BMP位图图像,采集并检测一帧位图BMP图像.具体检验参数包括:采集及检测图像的分辨率、所用时间、图像识别率、图像检测准确率等.各检测参数的大小均取各检测实验项目连续完成200次后计算的平均值.具体实验数据如表1所示.
表1??原棉异纤图像检测的验数据Tab.1??Experimentresultsofdetectionof
differentfibreincotton
检测内容采集一帧BMP检测一帧BMP采集并检测一帧BMP
分辨率/像素576*432576*432576*432
时间/s0.241.471.71
识别率/%准确率/%?99.399.3
?98.698.6
4??结??论
????试验数据表明,采用本系统,原棉的异纤在线检测识别率可以达到99%以上,证实了计算机图像处理识别技术应用于原棉中异纤的在线检测的可行性,具有一定的应用价值.本文所述系统的软件和硬件还存在许多不足之处,在识别率较高的同时系统响应速度却略显不尽如人意,也有待于在今后的研究中不断完善和优化.参考文献:
[1]??梁德群.基于图像识别的工业检测技术[J].光子学报,
1993,(2):22-23.
[2]??吴更石.多模式实时工业图像检测系统[J].计算机工程
与应用,1998,(9):34-35.
[3]??张书琴.苹果、桃等农副产品品质检测与分级图像处理系
统的研究[J].农业工程学报,1999,(1):15-17.
[4]??孙兆林.MATLAB6.X图像处理[M].北京:清华大学出
版社,2002.180-182.
[5]??陈桂明.MATLAB数理统计(6.X)[M].北京:科学出版
社,2002.216-217.
????现对表1的实验数据,做如下分析和说明:
四 : 基于ISO 11784/5的动物识别标签设计
 引 言
引 言
1 国际动物识别标准介绍
ISO 11784:动物的射频识别——代码结构。
ISO 11785:动物的射频识别——技术标准。
ISO 11784和11785分别规定了动物识别的代码结构和技术准则。标准中没有对应答器样式尺寸加以规定,因此可以设计成适合于所涉及动物的各种形式,如玻璃管状、耳标或项圈等。
1.1 代码结构——国际标准ISO 11784
代码结构为64位,如表1所列。其中的27~64位可由各个国家自行定义。

各国国内识别代码由该国自行管理。27~64位也可以分配用于区别不同的动物类型、品种、所在区域、饲养者等等。这些在此标签内没有做出规定。
技术准则规定了应答器的数据传输方法和阅读器规范。工作频率为134.2 kHz,数据传输方式有全双工和半双工两种,阅读器数据以差分双相代码表示。应答器采用FSK调制,NRZ编码。
由于较长的应答器充电时间和工作频率的限制,通信速率较低。
1.2 技术标准——国际标准ISO 11785
ISO 11785技术标准规定了电子标签的数据传输方法和读写器规范,以便激活电子标签的数据载体。制定该技术标准的目的是使范围广泛的不同制造商的电子标签能够使用一个共同的读写器来询问。动物识别用的符合国际标准的读写器能够识别和区分使用全双工/半双工的系统(负载调制)的电了标签和使用时序系统的电子标签。
1.2.1 全双工/半双工系统
全双工/半双工电子标签通过活化场得到电源,并立即开始传输存储的数据。因为是不需要副载波的负载调制过程,同时数据表示成差分双相代码(DBP),把读写器频率除以32即可以得到位率。当频率为134.2 kHz时,传输速率(位率)为4 194bps。
全双工/半双工数据报文包括了11位的起始域(头标)、64位(8字节)有用数据、16位(2字节)CRC以及24位(3字节)终止域(尾标)。每传输8位后,插入一个逻辑“1”电平的填充位,以便避免出现头标为“00000000001”的情况。在给定传输速率的情况下,传输128位大约需要30.5 ms。
1.2.2 时序系统
每50 ms后活化场暂停3 ms。时序电子标签事先已经通过活化场充入了能量,在活化场暂停后大约1~2 ms开始传输存储的数据。
电子标签用频移键控(2FSK)调制法。位编码采用NRZ逻辑“O”与基频134.2 kHz对应,逻辑“1”与频率124.2 kHz对应。
把发送频率除以16就可以得到比特率。因此,在频移键控情况下,比特率对于逻辑“O”为8 387 bps,对于逻辑“1”为7 762 bps。
时序数据报文包括了8位起始域01lllllOb、64位(8字节)有用数据、16位(2字节)CRC以及24位(3字节)终止域,没有填充位。
在给定传输速率的情况下,传输112位最多需要14.5ms(“1”序列)。
2 动物识别卡片结构说明
根据动物识别的标准,可以得到动物识别卡片数据发送的顺序,即从第1个字节的bitO发送到第16个字节的bit7。
动物识别卡片数据发送表见本刊网站(编者注)。表中内容说明如下:
(1)DATAl~DATA64
①National ID:高位到低位=DATA27~DATA64=NID37~NIDO
举例:假设要写入的是11223344556(十进制)(最大为274877906944),
对应于十六进制是1A21A278BE,对应于二进制是01 1010 **** 0001 1010 **** 0111**** 1011 ****,
对应于表中的NID就是从NID37~NID0。
②Country ID:高位到低位=DATAl7~DATA26=CID9~CIDO
举例:假设要写入的是1000(十进制)(最大为1024),
对应于十六进制是3E8,
对应于二进制是11 1110 1000,
对应于表中的CID就是从CID9~CID0。
③DATA BLOCK:DATAl6。
④Resetved:DATA2~DATAl5。
⑤Animal FLAG:DATAl。
(2)CRC部分为8字节的校验
CRC计算例程如下:
bur[0]~buf[7]为8字节有效数据。crc_value为2字节CRC校验数据。

}
}
3 射频读写基站EM4095介绍
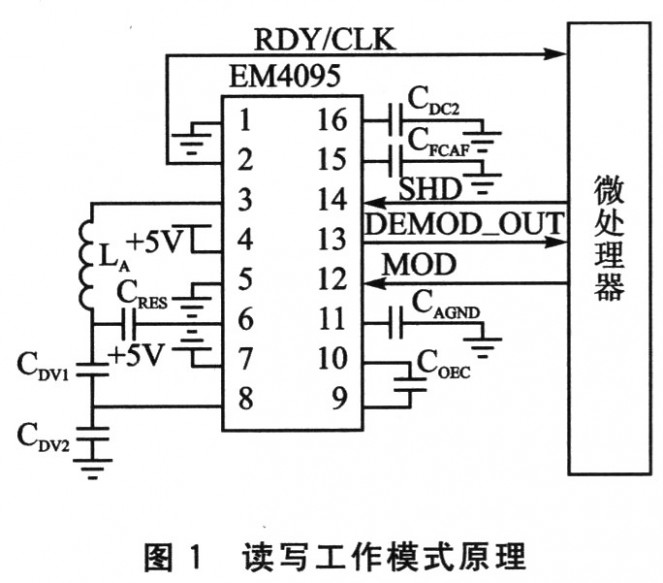
EM4095是用于RFID的CMOS集成收发器电路基站芯片,有以下功能:
◆利用载波驱动天线;
◆用于可读写应答器的AM调制磁场;
◆对从天线传输来的应答器的调制信号进行AM解调;
◆与微处理器通过简单接口通信。
特点如下:
◆集成的锁相环系统,以实现用自适应载波频率来匹配天线谐振频率;
◆无需外部晶振;
◆100~150 kHz载波频率范围;
◆用桥驱动方式直接驱动天线;
◆以OOK(100%AM调制)的方式进行数据传输;
◆用外部可调整系数的单端驱动器以AM调制的方式进行数据传输;
◆兼容多种应答器协议(如EM400X、EM4050、EM4150、EM4070、EM4170、EM4069……);
◆睡眠模式1μA;
◆兼容USB电压范围;
◆40~+85℃温度范围;
◆小外形塑料封装SO16。
典型工作模式原理如图1所示。
4 射频读写卡片EM4205介绍
4.1 基本说明
EM Microelectronic的低频率RFID IC EM4205用来满足动物识别、废料管理、工业的物流管理和存取控制应用等领域的特定需求。这个符合ISO 11784/11785的应答器芯片(transponder chip)可满足目前及未来家畜(1ive—stock)需用,提供高质量的读取范围。
EM4205特别适于低成本的动物标签应用,并符合ISO 11784/11785标准,有助于产品的一致性和设备的互通性。对大多数的动物识别应用而言,ISO的数据完整性是很重要的。EM4205/4305可避免数据发生未授权的修改,也可避免在生产流程中因UV光线所造成的数据损失。另外,使用者可通过编程(user—programmable)内存来记录特定应用的信息,如药品的编码、日期或与拥有者相关的数据。内存可由密码来保护,以达到完整性及保密的目的。
EM4205为了满足一些特殊应用,如玻璃管转换器(glass tube transponder),采用了最小的尺寸,以便将对电子产品的影响减到最小。
4.2 工作原理
EM4205通过外部线圈及内部集成的电容一起组成谐振电路,从连续的125 kHz磁场中获取能量启动。芯片从内部的EEPROM中读出数据,并通过与线圈并联的负载的开断产生深幅调制,将数据发送出去。通过对125kHz磁场的100%幅度调制,可以执行各种命令并更新EEPROM中的数据。
EM4205/4305支持几种Bi—phase和Manchester,操作模式(配置选项)存储在EEPROM的配置字中。所有EEPROM字可以通过设置锁位进行保护。芯片还包括一个可编程的32位的UID(Unique Identification)。
4.3 特 点
◆512位EEPROM,16字×32位分布;
◆32位UID(唯一识别码);
◆兼容ISO 11784/11785协议;
◆32位口令读和写保护;
◆可使EEPROM字进入只读锁定状态;
◆2种编码方式(曼彻斯特、Bi—phase);
◆多种数据传输率(8、16、32、64个RF时钟);
◆具有读卡器先问询的特点;
◆频率范围为100~150 kHz;
◆芯片自带整流器和电压钳位;
◆无需外部电容(电压保持);
◆温度范围为一45℃~+85℃;
◆非常低的功率消耗;
◆加大的焊点(200μm×400μm)允许直接连接天线(EM4305);
◆EM4205:2个谐振电容210 pF或250 pF(mask版本可选);
◆EM4305:3个谐振电容210 pF或250 pF或330pF(mask版本可选);
◆协议和EM4469/4569兼容;
◆双缓冲保护字。
4.4 EEPROM组成
字14和15用于保护字O和13免于被误操作。
EEPROM的512位有16个字,每个字由32位组成。EEPROM字的编号为O~15,在字中的位编号为O~31位,LSB优先的原则(即先发送LSB)。
EEPROM字中的32位通过一个写的命令进行编程。开始2个字,代表工厂芯片类型、谐振电容大小及UID号码,且可以由用户自行编程。它们不能作为默认的信息,但可以存储一些有用的信息只允许读命令访问。(通过写保护)
字2是32位的密码。
字3是自由读写。和O、1一样,它们可以存储一些有用的信息,只允许读命令访问。
字4是配置字,决定设备操作模式等选项。
字5~13是自由读写的数据块(288位),可以作为默认信息的一部分。
字14、15是保护字,用来防止写命令对字0~13的修改。
5 用EM4205制作动物识别卡
第1步:设计EM4205配置字。
对于符合ISO11784/5的FDX—B模式,EM4205应该配置为:
◆Bi—phase
◆RF/32
◆返回4 BLOCK 16字节(128位)ISO11784/5的有效数据,则BLOCK4为00020C8F。
第2步:计算8字节64位的有效数据。
参考动物识别卡片数据发送表以及说明。
◆将十进制的National ID转化为38位的二进制数,最低位对应于标签结构中的第64位。
◆将十进制的Country ID转化为10位的二进制数,加入到38位National ID之前。
◆加入1位DATA BLOCK。
◆加入14位Reserved位O。
◆加入1位Animal FLAG。
上述5项组成64位二进制数据。
第3步:计算2字节CRC。
根据上文的CRC计算例程,计算64位(8字节)数据的2字节CRC校验字节。
第4步:组成16字节的动物标签最终数据。
以发送的顺序组成16字节(128位)的数据。
◆加入000000001。
◆加入8字节有效,然后再加入2字节CRC校验数据,每个字节后面跟1个1。
◆加入3字节空数据,每个字节后面跟1个1。
第5步:16字节数据写入卡片。
由于每个BLOCK(32位)的发送顺序为位O一位31,将16个字节放入4个BLOCK中的时候要作如下处理:
第1个BLOCK:BYTE4+BYTE3+BYTE2+BYTEl。
第2个BLOCK:BYTE8+BYTE7+BYTE6+BYTE5。
第3个BLOCK:BYTEl2+BYTEll+BYTElO+BYTE9。
第4个BLOCK:BYTEl6+BYTEl5+BYTEl4+BYTEl3。
至此,由EM4205卡编写而成的ISO11784/5动物识别卡制作完成。
结 语
本文介绍了用EM4205通用读写射频卡制作动物标签卡的基本过程和方法,对于从事动物识别领域的卡片制造商、系统集成商、中间件集成商有一定的实用价值。
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1