一 : 精准的数据挖掘才是微博推广的精华
微博营销是长春网络推广的一种方式,如今很多人都在玩微博,同时也用来推广,可作用却是千差万别。其实,微博推广的精华就是做精准的数据挖掘,也就是将精准的内容发送给精准的客户。
一,如何才能找到你的精准客户?
1、精品的微博粉丝提取
例如你是做保健品的,那么就要从你竞争对手的微博粉丝提取出来,放入自己的数据库中,进行维护。2、根据关键词提取相近粉丝
如果说你想找一个跟长春网络营销相关的粉丝,那就可以在微博中查找“长春网络营销”、“网络营销”等相关关键词,就样又可以找到一部分用户集体,而这类用户是最精准的,而你在做推广时感觉对方是乐于承受的,没有反感,而且还会支持你,最终成为你的忠诚客户。
3、地域标签提取
微博营销可以精准到某一个区,比如你是做鲜花的,地点在某某小区,就可以用地域标签来收集在这个小区的微博用户,对他们进行实时网络推广,这样就建立了很好的联系,一旦他们有这方面的需求时会联想到你,然后去买你的鲜花。
二、如何打造精准的内容?
找准了精准的客户之后就要预备发布的内容了,做搜索引擎优化的伴侣都晓得“内容为王”,而微博推广也是如此,一个经典的内容备受粉丝的喜爱,在短工夫内就能打造很高的转发和评论,然后达到推广的目的。精准内容的预备有几个点:
地域剖析:首先定位粉丝在哪些区域,例如长春网络营销区域粉丝占70%,上海网络营销区域占20%,天津网络营销区域占10%,那么在预备微博内容其实长春区域占主体,这样可以从@长春那些事儿@安全长春等这些平台收集一些内容,至于上海和天津的新闻恰当发布即可。
性别剖析:剖析一下粉丝中男女比例,如男人占30%,女士占70%,则微博内容就要以女人喜爱为主。
标签剖析:微博标签剖析就是把具有一样喜欢的人群归为一类,比如旅游、长春网络营销等。
工作剖析:剖析粉丝归于哪一个集体,各个集体所占比重是多少,比如CEO,HR等。
三、如何掌控精准的发布时间?
精准的用户和微博内容预备好了,接下来就是如何来发布的问题了,说到微博发布玩过微博使用的伴侣首要为想到皮皮时光机,掌控精准发布工夫咱们可以从以下几个方面来着手。
1、微博守时工具;常用的有皮皮时光机,月光宝盒等,我们只需求预备好发布的内容,设置好发布时间,内容就会主动发布,很方便。
2、剖析粉丝在线人数;看在哪个时间段粉丝在线人数最多,就可重点来进行微博发布,通常情况下早上8:30-9:30正午12:00-13:00,晚上20:00-23:00这段时间里在线的粉丝人数比较多。俗话说:顾客就是上帝,这句话一点也不假,只有找到了精准顾客后,然后根据顾客的需求去恰当的网络推广,在精准的时间里将精准的内容发布给精准的客户,这样一来谁还会说微博推广难做呢?
注:此文属笔者璐欣原创,转载请注明出处(http://www.luxinseo.com)谢谢合作!
二 : 中文微博热点话题挖掘
《统计与信息论坛杂志》2014年第六期
一、相关理论
(一)话题检测与跟踪技术TDT作为一种主题检索技术,其特点主要在于关注与特定事件主题相关的数据。传统的检索技术是从内容来检索、确定文档的分类,而TDT技术是基于事件,利用分析文档与事件主题联系来获取特定主题信息,它从来源数据流中自动发现主题并把与主题相关的内容联系在一起。TDT的研究任务主要包括五部分:对新闻广播等报道进行切分(报道切分),检测未知话题(话题检测),跟踪已知话题(话题跟踪),检测未知话题首次相关报道(首次报道检测)以及检测报道间相关性(报道关联性检测)[7]。
(二)中文分词及词性标注中文分词就是将汉字序列切分成有意义的词,以字为单位,句和段则通过标点等分隔符来划界。目前主流的中文分词算法分为四类:基于字符串匹配的分词,基于理解的分词,基于统计和基于语义的分词[8]。词性标注是根据句子上下文环境给句中的每个词标记一个正确的词性,主要是机器针对多标记词(即有多种词性的词)和未登录词(即在训练语料中未出现的词)标记词性。词性标注技术与分词技术一样,在自然语言处理、机器翻译、文本自动检索及分类、文字识别、语音识别等实际应用中占有重要地位[5]。目前比较典型的标注算法归纳起来有:基于规则的方法,基于统计的方法,规则与统计相结合的方法。本文选用的是规则与统计相结合的方法。
(三)向量空间模型向量空间模型(VectorSpaceModel,VSM)是一个应用于信息过滤、信息撷取、索引评估相关性的代数模型,文本分析对象通常是以词为单位的VSM数据[9]。运用这个模型把文本表示为向量,就可以将文本处理简化为向量空间中的向量运算。当文档转化为向量时,文档中每个词对应向量的每个特征项维度,所有文档中的词所对应的维度构成了整个空间,而特征权重则是每个词对应每一维的取值,于是,一个文档Dj转化为特征向量D?j可表示为:其中tij是特征项,wij是特征权重,M是文本tij中的特征项总数。另外,文本中作为特征项的词不能重复,即各特征项tij互异,且文本的内部结构不需要考虑,因此特征项tij无先后顺序。
(四)K-means文本聚类K-means算法以欧式距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大,得到紧凑且独立的簇是聚类的最终目标。K-means算法中距离的计算公式如下:第一步,从数据对象中任意选择K个对象(K值需要预先设定)作为初始聚类中心。第二步,计算剩下的对象与这些聚类中心的相似度(距离),并分别将它们分配给最相似的(聚类中心所代表的)类。第三步,重新计算每个新类的聚类中心(该聚类中所有对象的均值)。第四步,不断重复第二、三步,直到标准测度函数开始收敛为止,一般采用均方差作为标准测度函数。该算法在处理大数据集时是相对高效和可伸缩的,计算的复杂度为ON(kt),其中N是数据对象的数目,t是迭代的次数(一般K≤N,t≤N,同时算法对顺序不太敏感,因此较适合对VSM表示的文本集进行聚类。本文聚类效果的验证采用类平均相似度,公式为:其中AVGT()SIM表示类T的平均相似度;CT表示类T所包含的微博条数;ft(avg(sim))表示类T中单条微博文t的个体平均相似度,即t与类T中其余微博文的相似程度之和取平均值。将类中所有微博文的个体平均相似度之和取一次平均值,从而得到类的平均相似度。
二、研究设计
(一)识别流程本文基于TDT技术设计出中文微博热点话题识别流程,主要环节如图1所示。首先通过微博爬虫系统获取所需的数据,如微博内容、评论数、转发数、受众数等;接着从获取数据中提取话题识别的数据源,利用中文分词处理过滤数据;对预处理后的微博内容中的每个特征词,利用特征词权值计算方法TF-IDF(TermFrequency–InverseDocumentFrequency)计算特征权重并建立向量空间模型,再利用K-means文本聚类来归纳出多个话题;最后对多个话题的影响力进行计算并分析,通过效果验证识别出热点话题。
(二)热点判定———话题影响力设计本文基于微博特点和话题本身,提出热度的判定因素———话题影响力。微博热点话题影响力为该话题中单条相关微博内容的影响力总和,单条微博内容的影响力又分为直接影响力和间接影响力。由于用户发表的微博文直接呈现给关注该用户的[www.61k.com)受众,因此单条微博的直接影响力与该条微博发布用户的关注人数(受众数)相关[10]。本文此处只考虑微博评论数与第一层的转发数。定义话题影响力相关计算公式如下:其中Inf()T为话题T的影响力;n为该类中与话题相关的微博条数;Inf()t为单条相关微博内容t的影响力。一个话题的影响力为话题中所包含的所有相关微博内容影响力之和。其中InfD()t为单条相关微博内容t的直接影响力;InfI()t为单条相关微博内容t的间接影响力。单条微博的影响力为直接影响力与间接影响力之和。题T的影响力为:
三、实证分析
本文实验数据随机选取了2011年12月8日到2011年12月14日这7天内的微博数据,通过新浪微博API接口共爬取微博内容2103条。根据研究设计的热点话题挖掘流程,对该周内新浪微博热点话题挖掘进行实证研究。
(一)数据预处理首先对微博内容进行文本预处理,即进行去重、分词、无效信息过滤、降维等操作。实验中使用C#版本的中科院ICTCLAS中文分词系统对微博文本进行分词处理,同时标注词性,并过滤微博内容,保留名词及名词性词语,然后将所有的单字过滤,再去除所有的英文字符、数字和一系列数学符号等非中文词,只留下有意义的中文词语。图2为关于“2012年伦敦奥运会期间英国女王出租宫殿套间”话题文本示例。
(二)话题识别文本预处理后,针对每条微博内容,利用特征词权值计算方法TF-IDF计算各个单词权重,以构成一个向量空间模型用于聚类。实验中,K值在最大值范围内通过多次实验结果验证来选取。经过多次试验,最终将该周的微博内容聚为10类,并对各类进行类关键词提取,结果如表1所示。以上10类中,所提取的关键词具有较强实时性的有6个,关键词所包含信息较为日常的类有4个。此时若设置类平均相似度阈值为0.01,则恰好包含较强实时信息的6个类别。将类平均相似度高于阈值且包含较强实时信息的类定义为一个话题,则从微博内容中发现话题数目为6个,分别为类3、4、6、7、8、10。
(三)话题影响力排序大多关于热点发现的算法认为,在聚类后出现的热点词频率较高,则该话题即为热点话题。这种原理是基于热点词与话题的附属关系,但却忽略了当话题较分散的情况下聚类也能进行,同时在聚类结果中,可能有些话题只是局部较热的小话题,整体来讲算不上热度很高[11],因此可以设置一个阈值来区分话题冷热,话题热度(本文中以话题影响力来衡量)高于阈值则表示聚类出来的话题为“热点话题”,低于阈值则视为“非热点话题”。热点与非热点的概念是相对的,因此也可以根据话题影响力公式计算出每个话题的热度,然后按照热度分数排序,分数越高表示话题影响力越大,热度越高。实验中,挖掘热点话题的数据来源时间段Δh为2011年12月8日至2011年12月14日。由于实验中发现话题的总数较少,故本实验不以预先设定话题影响力阈值来划分“热点”与“非热点”,只将话题按影响力大小排序,即设定所发现话题均为热度不同的热点话题。根据话题影响力相关计算公式(4)~(8),计算得到实验中所提取的6个话题在当前时段的影响力评分及排名,如表2所示。考虑到微博转发会使微博的影响扩散,相对于评论其影响力更大,因此公式(8)中α取值为0.4,β取值为0.6.从以上分析结果可以看出,在实验识别出的2011年12月8日到2011年12月14日的6个话题中,影响力从大到小依次是江苏丰县校车事故、南京大屠杀纪念日、韩国海警被刺事件、电影《金陵十三钗》即将上映、广东陆丰乌坎村群体事件、双子座流星雨爆发。
(四)效果验证话题识别与跟踪的效果一般使用准确率和召回率两个参数来衡量,公式如下:A表示已提取出的与话题相关内容,B表示已提取出的与话题不相关内容,C表示未提取出的与话题相关内容。在全部文本数据中,与话题相关的数目为A+C,而被判定与话题相关的数目为A+B。召回率和精度是不可能两全其美。当召回率较高时,精度反而降低;反之精度高时,召回率就会有所降低。因此,本文用这两个度量值融合而成的一个度量值F来衡量这个效果。F值公式如下:实验以“召回率”、“准确率”验证热点话题发现效果,根据公式(9)、(10)、(11)计算出每个话题的召回率与准确率,如表3所示。从表3可以看出,6个热点话题召回率从高到低依次为:韩国海警被刺事件,江苏丰县校车事故,南京大屠杀周年纪念,双子座流星雨,陆丰乌坎村群体事件,电影《金陵十三钗》话题,各类话题召回率均较高。相反,各类话题准确率均较低,最高为双子座流星雨,仅为0.769,最低为广东陆丰群体事件,仅为0.641。聚类准确率低与微博内容零散、谈论话题范围极其广泛有关,即话题聚类时噪声数据太多,导致β值较大。实验表明微博热点话题发现的“召回率”较高而准确率较低,这与微博内容的不规范性、随意性等特点有关。从综合衡量召回率和准确率的F值来看,热点识别取得了良好的效果。尽管微博内容存在一定的不规范和随意性,但从实证分析中可以看到,聚类所选取出的6类热点话题F值均保持在0.75以上。
四、结论
本文借鉴TDT技术,设计了一套中文微博热点话题挖掘流程,并利用一段时间内的少量新浪微博数据进行热点发掘实证研究。该流程可以使微博站点外部用户利用少量微博数据便能挖掘微博热点,以满足其监控舆情或发现商机的需要。本文主要的创新工作有以下两点:第一,将识别热点话题的主流技术TDT运用于中文微博平台,同时还在流程设计中结合了中文微博的特性。第二,微博平台往往以单一的微博数量指标来衡量话题热度,而本文则提出了以话题影响力的大小来评判话题热度。由于新浪爬虫程序爬取的数据有限,因而本文仅限于对能收集到的数据进行研究,实证结果难免有一定的局限。另外,微博内容较杂乱,噪声信息较多,话题聚类效果也有待提高,因此相关聚类算法的改进也是未来研究的方向。话题影响力验证方法还需完善,后期可以对热点话题进行动态跟踪,以发现热点话题的整体趋势变化。
作者:何跃 帅马恋 冯韵 单位:四川大学 商学院
三 : 波克斯和亨特著作中的数据集(BOXHUN DATASET)_数据挖掘_科研数据集
波克斯和亨特著作中的数据集(BOXHUN DATASET)
数据摘要:
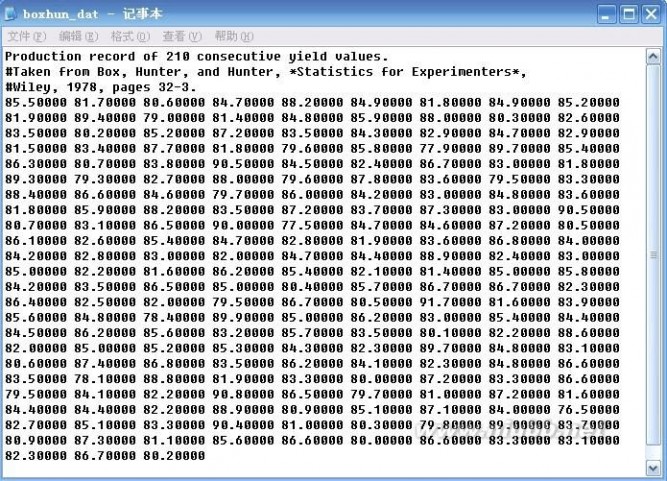
Production record of 210 consective yield values.
中文关键词:
时间序列,化学,产品,产值,
英文关键词:
time series,chemistry,production,yield value,
数据格式:
TEXT
数据用途:
The data can be used for time series analysis.
数据详细介绍: BOXHUN DATASET
Abstract: Production record of 210 consective yield values.
Source: Hipel and Mcleod (1994).
波克斯 波克斯和亨特著作中的数据集(BOXHUN DATASET)_数据挖掘_科研数据集
Copyright:
The time
series may be freely copied and used, provided this source is clearly acknowledged. Citations to the Time Series Data Library should be as follows: Hyndman, R.J. (n.d.) Time Series Data Library, http://robjhyndman.com/TSDL
数据预览:
波克斯 波克斯和亨特著作中的数据集(BOXHUN DATASET)_数据挖掘_科研数据集
点此下载完整数据集
四 : 浅析如何在平淡微博推广秘笈中挖掘智慧
当我还停留在博客推广的那一阶段,有一天却发现自己落后了,微博的迅速的发展,却让我措手不及,原来现在已经到了微博的时代,适应时代推广的要求,我必须要从博客时代走向微博时代,不然我的推广很难会有进展。在做好微博推广时,我也下了不少的功,现在就将我做微博推的秘笈和大家分享一下。
在做微博推广时,我先把自己的网站微博做了细致的定位,以及微博的装修,都做了很大的改观,看起来微博比较温暖。能够达到我最初的微博定位。我第一个选择的微博平台是,新浪微博,毕竟新浪是第一个推出微博的平台,我想新浪微博的实力或是人群应该更广一点。随之便注册一网易微博,腾讯微博,搜狐微博,以这四大微博为主力。全面而细致的做好内容。就开始了我全新的微博之旅。
网站推广之微博推广秘笈一:参加微群,并积极在微群中推广自己的微博。主动是关注微群,在微群中,你会结识很多的目标客户,然后利用机会,从而做到推广自己的微博,有人知道了你的微博,慢慢的才会有人关注你,关注你便会关注你的内容。这时你的微博推广才能够很好的进行下去。
网站推广之微博推广秘笈二:定期设立互动话题,积极讨论并回复评论者留言。微博的主要特点就是互动性强,所以在有人给你评论或是留言给你时,你一定要积极主动的去回评人家。礼上往来,才能更好的加强和互动用户的关系。
网站推广之微博推广秘笈三:微博主要的是要有人气,有粉丝的关注,所以在建立微博初期你的人气不是很高是时,要建立忠实粉丝群体(一般是认识的人),定时转发你的微博,这样慢慢你的微博就会有人关注。
网站推广之微博推广秘笈四:微博推广的关键在于内容。也就是所谓的“内容为王”的原则。否则其他辅助手段再好,也是白搭。至于如何确定受众群体,内容版块,以及时间的设定等等,就是你的事情了。所以每一篇微博内容,要做到让大众接受,并能够转发,才是最好的微博内容。和大家互动起来。
网站推广之微博推广秘笈五:定时更新微博。微博也要每天更新,不要好久都没有更新,但是更新也不要刷屏,意思就是更新频率也不能过快,过犹不及,人家微博的页面都是你的内容。也会让人很反感,反感的后果就是取消关系,拉黑你。所以适可而止。要更新也要不更新过快。
现在有些企业也开始意识到微博的市场的巨大,于是就快速的发自己产品广告,加粉丝,也加了不少僵尸粉,但是却并没有收到很好的效果。究其原因,是没有真正的了解和掌握微博推广的方法,要了解用户的心里,才能做好微博的推广。我一直觉得,缺乏互动交流,没有互动,人家对你的产品也不会去理会,所以微博推广的互动性至关重要。
以上就是我在做微博推广时所用到的秘笈,大这可以认真的研读,说的再多,我们也要从现在开始执行,认真去做,相信大家一会把微博推广做的越来越好,网站的推广会更上一层楼。新事物的出现必然有它存在的合理性,如何运用好它,则需要你下一番心思。最后,希望我的上述观点能够给大家来一些帮助,同时也希望各位站长们做好微博推广,让你的网站从中获得最大的利益。本文来源:www.dwdok.com 第五代充值软件A5首发,转载请注明,谢谢!
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1