一 : Notepad++字符空行替换技巧四则新手进阶
1、删除文本中的空格
选中想删除空格的文本,按“Ctrl+H”,在find what后输入空格,在Replace with处不输入任何东西。然后点击“Replace all"
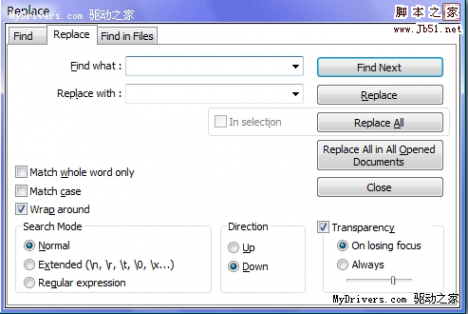
2、删除行的首个单词/空格/行号
菜单选择TextFX > TextFX Tools > Delete Line Numbers or First word
3、删除空行
菜单选择:TextFX > TextFX Edit > Delete Blank Lines
然后选择:TextFX > TextFX Edit > Delete Surplus Blank Lines
4、大小写转换
TextFX > TextFX Characters, 根据需求使用下面的选项:

二 : Boost学习之分解字符串--tokenizer
Boost.Tokenizer用容器的表现形式将1个字符串或其它字符序列分解为一系列单词(Token)
所需头文件:
分解例子
typedefboost::tokenizer<boost::char_separator<char>> Token;
boost::char_separator<char> sep(",;");
std::string str("1 2 3 4 5 ; 6, 7");
Token tok(str, sep);
Token::iterator it = tok.begin();
for (; it != tok.end(); ++it)
{
TRACE("\n%s", it->c_str());
}
boost::tokenizer的外观表现为1个保存单词的容器,通过访问它的迭代器就可得到分解后的单词。说它“表现”为1个容器的原因是它并不象vector之类的容器那样一开始就储存了一堆单词,而是在访问它的迭代器时才开始分解源序列(不仅仅是字符串哦)。
它的类声明为:
template <
classTokenizerFunc =char_delimiters_separator<char>,
classIterator = std::string::const_iterator,
class Type =std::string
>class tokenizer;
模板参数描述
TokenizerFunc用于分解序列,见后文
Iterator访问该序列的迭代器类型。
Type单词的类型,通常是std::string。
boost::tokenizer的构造函数使用2种方式接收输入数据:容器和迭代器
//使用容器
template<classContainer>
tokenizer(const Container& c,constTokenizerFunc& f =TokenizerFunc[www.61k.com]());
//使用迭代器
tokenizer(Iterator first, Iterator last,constTokenizerFunc& f = TokenizerFunc());
这里的容器不一需要一定是string,也可以是任何表现为字符容器的类,同样迭代器也可以很自由,如下例:
#include<iostream>
#include<boost/tokenizer.hpp>
#include<list>
int main(){
usingnamespace std;
usingnamespace boost;
char s[] ="This is, a test";
//分解list容器里的字符
{
list<char> vec_s(s,s+strlen(s));
typedef tokenizer<
char_delimiters_separator<char>,
list<char>::const_iterator//使用list的迭代器
> listtok;
listtok tok(vec_s);
for(listtok::iterator beg=tok.begin();beg!=tok.end();++beg){
cout << *beg<< " ";
}
}
//分解从控制台读入的字符串
{
//输入流迭代器
typedef istream_iterator<char,char>initer;
typedef tokenizer<
char_delimiters_separator<char>,
initer//使用输入流迭代器
> cintok;
cin >> noskipws;//不跳过空格
cintok tok = cintok( initer(cin), initer());
for(cintok::iterator beg=tok.begin(); beg!=tok.end();++beg){
cout << *beg<< " ";
}
}
return0;
}
细说TokenizerFunction参数
TokenizerFunction是1个函数对象,其目的是分析1个给定的序列,直至找到1个单词或到达序列末尾。然后它更新该单词,并通知调用者当前单词之后的下1个字符的位置。
对于tokenizer来说,它只关心TokenizerFunction里的2个 方法,1个当然是函数对象一定有的operator(),另1个是reset()。
operator()的作用是从序列中取出下1个单词,tokenizer的 迭代器前进一次就会调用一次,其定义如下:
template <typename InputIterator, typenameToken>
bool operator()(InputIterator&
next, InputIterator end,Token&tok);由tokenizer调用时,模板类型InputIterator和Token被特化为tokenizer::Iterator和tokenizer::Type(见tokenizer类声明)。
参数描述
next,end这是一对迭代器,用于访问序列中的字符,其中的next在调用完成后应该指向当前单词后的下一字符。
tok存放分解出的单词。
bool返回值 返回值为true时表明tok有效,否则表示已经到序列尾部或解析出错。
reset()定义如下
void reset()它在每次分析序列之前调用,一般用于重置一些状态变量。
要自己定义1个TokenizerFunction用 于tokenizer还必须 确保它可赋值和可拷贝(即operator=和拷贝构造必须可用)
下例中我们自定义了1个函数对象作为tokenizer的TokenizerFunction参数:
#include<iostream>
#include<boost/tokenizer.hpp>
#include<string>
//自定义1个separator,分解指定分隔符的序列
struct my_separator
{
//一般用于重置一些状态变量,这里用不上
void reset(){ }
template<typename InputIterator, typenameToken>
booloperator()(InputIterator& next, InputIterator end,Token& tok)
{
//存放单词的,一般应该是1个string(见tokenizer::Type模板参数)
tok = Token();
//找到有效位置
for (;next != end && *next ==m_sep;++next);
//到结尾返回false
if (next == end) return false;
//取出单词
for (;next != end && *next !=m_sep; ++next)
{
tok += *next;
}
return true;
}
//构造函数,指定分隔符
my_separator(char c)
:m_sep(c){;}
private:
charm_sep;
};
int main()
{
usingnamespace std;
usingnamespace boost;
string s ="Thi|s is,| a| |tes|t";
//指定'|'作为分隔符
tokenizer<my_separator> mytok(s,my_separator('|'));
for(tokenizer<my_separator>::iteratorbeg=mytok.begin(); beg!=mytok.end(); ++beg)
{
cout << '<'<< *beg<< ">";
}
return0;
}
其实大部分情况我们并不需要自己写TokenizerFunction,Boost.Tokenizer帮我们准备好的几个TokenizerFunction足以满足大部分需要,下面是这些TokenizerFunction的介绍:
char_delimiters_separator
默认参数,以标点符号各空格字符作为分隔符
它的构造函数如下:
char_delimiters_separator(bool return_delims = false,
const Char*returnable = 0,
const Char*nonreturnable = 0);
参数描述
return_delims是否返回发现的分隔符。注意不是所有分隔符都可返回。有关解释请见其它2个参 数。
returnable指定可返回的分隔符。这些分隔符当 return_delims 为 true 时将作为单词返回。由于这通常是标点符号,所以如果以 0作为该参数提供,则可返回分隔符将是所有使 std::ispunct(C) 为 true 的 C. 如果该参数为 "",则代表没有可返回分隔符。
nonreturnable指定不可返回的分隔符。这些分隔符不可作为单词返回。由于这通常是空白字符,所以如果该参数为 0,则不可返回分隔符将是所有使std::isspace(C) 为 true 的C. 如果该参数为 "", 则代表没有不可返回的分隔符。
区别不可返回和可返回分隔符的原因是,有些分隔符仅用作分隔单词而没有更多的意义。以字符串 "b c +"为例。假设你在写1个简单的计算器,分析后缀形式的表达式。空格和加号都可以用作分隔单词,你只对加号感兴趣而对空格不感兴趣。将空格作为单词返回只会使你的代码复杂化。这时你需要指定加号为可返回分隔符,而空格为不可返回分隔符。
char_separator
由指定的字符作为分隔符
它的构造函数如下:
char_separator(const Char* dropped_delims,
const Char*kept_delims = 0,
empty_token_policy empty_tokens = drop_empty_tokens);
参数描述
dropped_delims以字符串的形式指定多个可返回分隔符
kept_delims以字符串的形式指定多个不可返回分隔符
empty_tokens当在输入序列中出现2个连续的分隔符时,是否要输出1个空白单词或是直接跳过。
empty_tokens可以是drop_empty_tokens(跳过)或keep_empty_tokens(输出空白单词)
例:
#include<iostream>
#include<boost/tokenizer.hpp>
#include<string>
int main()
{
std::stringstr = ";;Hello|world||-foo--bar;yow;baz|";
typedefboost::tokenizer<boost::char_separator<char>>
tokenizer;
boost::char_separator<char> sep("-;","|", boost::keep_empty_tokens);
tokenizertokens(str, sep);
for(tokenizer::iterator tok_iter =tokens.begin();
tok_iter != tokens.end(); ++tok_iter)
std::cout << "<"<< *tok_iter<< ">";
std::cout<< " ";
returnEXIT_SUCCESS;
}
输出结果:
<> <><Hello><|><world><|> <><|> <><foo><><bar><yow><baz><|><>
escaped_list_separator
对csv (逗号分隔)格式进行分解,并支持转义符
它的构造函数如下:
escaped_list_separator(Char e = '\\', Char c = ',',Char q ='\"');
escaped_list_separator(string_type e, string_type c, string_typeq);这2个构造函数的区别是第1个只能指定1个字符作为分隔符,而第二个可以指定多个。
参数 描述
e指定转义符字符,默认是反斜杆'\'
c指定分隔符字符,默认是逗号','
q指定作为引号的字符,默认是引号'\"'
参数e指定的转义符与C语言中的转义符一样,如果单词中含有分隔符,可以用引号包起来。如果单词中又有分隔符又有引号,则需要使用转义符:
转义序列结果
<转义符><引号><引号>
<转义符>n换行
<转义符><转义符><转义符>
例:
#include<iostream>
#include<boost/tokenizer.hpp>
#include<string>
int main()
{
usingnamespacestd;
usingnamespace boost;
string s ="Field 1,\"putting quotes a\\\"round fields, allows commas\",Field3";
tokenizer<escaped_list_separator<char>> tok(s);
for(tokenizer<escaped_list_separator<char>>::iterator
beg=tok.begin(); beg!=tok.end();++beg)
{
cout << *beg<< " ";
}
returnEXIT_SUCCESS;
}
输出结果:
Field1
putting quotes a"round fields, allows commas
Field3
offset_separator
偏移分隔符,按偏移量将1个字符序列分解为多个字符串
构造函数如下:
template<typename Iter>
offset_separator(Iter begin,
Iter end,
bool bwrapoffsets = true, bool breturnpartiallast = true);
参数描述
begin,end指定整数偏移量序列
bwrapoffsets指明当所有偏移量用完后是否回绕到偏移量序列的开头继续。例如字符串 "1225200101012002" 用偏移量 (2,2,4)分解,如果bwrapoffsets为 true, 则分解为 12 25 2001 01 01 2002. 如果 bwrapoffsets 为 false, 则分解为12 25 2001,然后就由于偏移量用完而结束。
breturnpartiallast 指明当被分解序列在生成当前偏移量所需的字符数之前结束,是否创建1个单词,或是忽略它。例如字符串"122501" 用偏移量 (2,2,4) 分解,如果 breturnpartiallast 为 true,则分解为 12 2501. 如果为 false, 则分解为 1225,然后就由于序列中只剩下两个字符不足四个而结束。
使用这个类时,将它的某个对象传入到任何需要 TokenizerFunction的地方。如果该对象是缺省构造的,则被分解序列中的每个字符将被作为1个单词返回(即缺省值为偏移量 1, 且 bwrapoffsets 为true)。
例:
// simple_example_3.cpp
#include<iostream>
#include<boost/tokenizer.hpp>
#include<string>
int main(){
usingnamespace std;
usingnamespace boost;
string s ="12252001";
intoffsets[] = {2,2,4};
offset_separator f(offsets, offsets+3);
tokenizer<offset_separator>tok(s,f);
for(tokenizer<offset_separator>::iterator
beg=tok.begin(); beg!=tok.end();++beg){
cout << *beg<< " ";
}
}
Tokenizer迭代器
boost::tokenizer的主要功能都集中在它的迭代器中,我们甚至可以直接使用tokenizer的迭代器来处理序列。
通过make_token_iterator来产生创建迭代器:
template<class Type, class Iterator, classTokenizerFunc>
typenametoken_iterator_generator<TokenizerFunc,Iterator,Type>::type
make_token_iterator(Iterator begin, Iterator end,constTokenizerFunc& fun);
参数描述
begin被分析序列的开始
end被分析序列的末尾
fun某个符合 TokenizerFunction 的函数对象
迭代器的类型由token_iterator_generator::type来取得,token_iterator_generator的定义为
template <
class TokenizerFunc =char_delimiters_separator<char>,
class Iterator = std::string::const_iterator,
class Type = std::string
>
class token_iterator_generator;
模板参数描述
TokenizerFunc用于分析序列的 TokenizerFunction.
Iterator用于指定序列的迭代器类型。
Type单词的类型,通常为 string.
例子
/// simple_example_5.cpp
#include<iostream>
#include<boost/token_iterator.hpp>
#include<string>
int main()
{
using namespace std;
using namespace boost;
string s = "12252001";
int offsets[] = {2,2,4};
offset_separator f(offsets, offsets+3);
typedeftoken_iterator_generator<offset_separator>::typeIter;
Iter beg =make_token_iterator<string>(s.begin(),s.end(),f);
Iter end =make_token_iterator<string>(s.end(),s.end(),f);
// 上面这行语句也可以这样写:
// Iter end;
for(;beg!=end;++beg){
cout << *beg<< " ";
}
}
三 : vim替换^m字符
替换^M字符
在Linux下使用vi来查看一些在Windows下创建的文本文件,有时会发现在行尾有一些“^M”。[www.61k.com]有几种方法可以处理。
1.使用dos2unix命令。一般的分发版本中都带有这个小工具(如果没有可以根据下面的连接去下载),使用起来很方便:
$ dos2unix myfile.txt
上面的命令会去掉行尾的^M。
2.使用vi的替换功能。启动vi,进入命令模式,输入以下命令:
:%s/^M$//g # 去掉行尾的^M。
:%s/^M//g # 去掉所有的^M。
:%s/^M/[ctrl-v]+[enter]/g # 将^M替换成回车。
:%s/^M/\r/g # 将^M替换成回车。
3.使用sed命令。和vi的用法相似:
$ sed -e ‘s/^M/\n/g’ myfile.txt
注意:这里的“^M”要使用“CTRL-V CTRL-M”生成,而不是直接键入“^M”
当时用第一种方法的时候 他说skipping binary files..无法完成
幸亏第三种方法成功了 嘿嘿
四 : IOS简单的字串替换方法stringByTrimmingCharactersInSet_eqi
一、Foundation framework中用于收集cocoa对象(NSObject对象)的3种集合分别是:
NSArray用于对象有序集合(数组)
NSSet用于对象无序集合(集合)
NSDictionary用于键值映射(字典)
以上3种集合类是不可变的(一旦初始化后,就不能改变)
以下是对应的3种可变集合类(这3种可变集合类是对应上面3种集合类的子类):
NSMutableArray
NSMutableSet
NSMutableDictionary
注:这些集合类只能收集cocoa对象(NSOjbect对象),如果想保存一些原始的C数据(例如,int,float, double, BOOL等),则需要将这些原始的C数据封装成NSNumber类型的,NSNumber对象是cocoa对象,可以被保存在集合类中。
===================NSArray====================
Ordered collection of objects.Immutable(youcannot add or remove objects to it once it’s created)
Important methods:
+ (id)arrayWithObjects:(id)firstObject,...;//nilterminated
- (int)count; //得到array中的对象个数
-(id)objectAtIndex:(int)index;//得到索引为i的对象
-(BOOL)containsObject:(id)anObject;//当anObject出现在array中,则返回yes(实际是通过isEqual:方法来判断)
-(unsigned)indexOfObject:(id)anObject;//查找array中的anObject,并返回其最小索引值。没找到返回NSNotFound.
-(void)makeObjectsPerformSelector:(SEL)aSelector;
-(NSArray *)sortedArrayUsingSelector:(SEL)aSelector;
- (id[www.61k.com])lastObject; // 得到array中最后1个对象。如果array中没有任何对象存在,则返回nil
注:
类方法arrayWithObjects可以创建anautoreleasedNSArrayof the items.例如
@implementation MyObject
- (NSArray *)coolCats{
return [NSArrayarrayWithObjects:@“Steve”,@“Ankush”, @“Sean”, nil];
}
@end
Other convenient create with methods (all return autoreleasedobjects):
[NSStringstringWithFormat:@“Meaning of %@ is%d”, @“life”, 42];
[NSDictionarydictionaryWithObjectsAndKeys:ankush,@“TA”, janestudent, @“Student”, nil];
[NSArrayarrayWithContentsOfFile:(NSString*)path];
-----创建数组-----
NSArray*array = [[NSArray alloc]initWithObjects:@"One",@"Two",@"Three",@"Four",nil];
self.dataArray = array;
[arrayrelease];
NSLog(@"self.dataArray countis:%d",[self.dataArray count]);
NSLog(@"self.dataArray index 2is:%@",[self.dataArray objectAtIndex:2]);
------从1个数组拷贝数据到另一数组(可变数级)-------
//arrayWithArray:
NSArray *array1 = [[NSArray alloc] init];
NSMutableArray *MutableArray= [[NSMutableArray alloc] init];
NSArray *array = [NSArrayarrayWithObjects:@"a",@"b",@"c",nil];
NSLog(@"array:%@",array);
MutableArray =[NSMutableArray arrayWithArray:array];
NSLog(@"MutableArray:%@",MutableArray);
array1 = [NSArrayarrayWithArray:array];
NSLog(@"array1:%@",array1);
//Copy
//idobj;
NSMutableArray *newArray = [[NSMutableArrayalloc] init];
NSArray *oldArray = [NSArrayarrayWithObjects:@"a",@"b",@"c",@"d",@"e",@"f",@"g",@"h",nil];
NSLog(@"oldArray:%@",oldArray);
for(int i = 0; i <[oldArray count]; i++){
obj =[[oldArray objectAtIndex:i] copy];
[newArrayaddObject: obj];
}
NSLog(@"newArray:%@", newArray);
[newArrayrelease];
//快速枚举
NSMutableArray*newArray = [[NSMutableArray alloc] init];
NSArray *oldArray = [NSArrayarrayWithObjects:
@"a",@"b",@"c",@"d",@"e",@"f",@"g",@"h",nil];
NSLog(@"oldArray:%@",oldArray);
for(id obj in oldArray)
{
[newArrayaddObject: obj];
}
NSLog(@"newArray:%@", newArray);
[newArrayrelease];
//Deepcopy
NSMutableArray *newArray = [[NSMutableArray alloc] init];
NSArray *oldArray = [NSArrayarrayWithObjects:
@"a",@"b",@"c",@"d",@"e",@"f",@"g",@"h",nil];
NSLog(@"oldArray:%@",oldArray);
newArray =(NSMutableArray*)CFPropertyListCreateDeepCopy(kCFAllocatorDefault,(CFPropertyListRef)oldArray,kCFPropertyListMutableContainers);
NSLog(@"newArray:%@",newArray);
[newArray release];
===================NSMutableArray====================
Mutable version of NSArray.
-(void)addObject:(id)anObject;//在array最后添加anObject, 添加nil是非法的.
- (void)addObjectsFromArray:(NSArray*)otherArray;//在array最后把otherArray中的对象依次添加进去。
-(void)insertObject:(id)anObjectatIndex:(int)index;//在索引index处插入anObject,若index被占用,会把之后的object向后移。
-(void)removeObjectAtIndex:(int)index; //删除index处的对象,后面的对象依次向前移。
-(void)removeObject:(id)anObject;//删除所有和anObject相等的对象,同样使用isEqual:作为相等比较方法.
- (void)removeAllObjects;
注:我们不能把nil加到array中。但有的时候我们真想给array加1个空的对象,可以使用NSNull来做这件事。如:
[myArray addObject:[NSNullnull]];
-----给数组分配容量-----
//NSArray*array;
array =[NSMutableArrayarrayWithCapacity:20];
-----在数组末尾添加对象-----
//- (void)addObject: (id) anObject;
//NSMutableArray *array =[NSMutableArrayarrayWithObjects:@"One",@"Two",@"Three",nil];
[arrayaddObject:@"Four"];
NSLog(@"array:%@",array);
-----删除数组中指定索引处对象-----
//-(void)removeObjectAtIndex: (unsigned) index;
//NSMutableArray *array =[NSMutableArrayarrayWithObjects:@"One",@"Two",@"Three",nil];
[arrayremoveObjectAtIndex:1];
NSLog(@"array:%@",array);
-----数组枚举-----
//1、- (NSEnumerator*)objectEnumerator; //从前向后
NSMutableArray *array = [NSMutableArrayarrayWithObjects:@"One",@"Two",@"Three",nil];
NSEnumerator*enumerator;
enumerator = [arrayobjectEnumerator];
id thingie;
while (thingie = [enumeratornextObject]) {
NSLog(@"thingie:%@",thingie);
}
//2、- (NSEnumerator*)reverseObjectEnumerator; //从后向前
NSMutableArray *array = [NSMutableArrayarrayWithObjects:@"One",@"Two",@"Three",nil];
NSEnumerator*enumerator;
enumerator = [arrayreverseObjectEnumerator];
id object;
while (object = [enumeratornextObject]) {
NSLog(@"object:%@",object);
}
//3、快速枚举
NSMutableArray *array = [NSMutableArrayarrayWithObjects:@"One",@"Two",@"Three",nil];
for(NSString *string inarray){
NSLog(@"string:%@",string);
}
-----NSValue(对任何对象进行包装)-----
//将NSRect放入NSArray中
NSMutableArray *array = [[NSMutableArray alloc] init];
NSValue *value;
CGRect rect = CGRectMake(0,0, 320, 480);
value = [NSValuevalueWithBytes:&rect objCType:@encode(CGRect)];
[arrayaddObject:value];
NSLog(@"array:%@",array);
//从Array中 提取
value = [array objectAtIndex:0];
[valuegetValue:&rect];
NSLog(@"value:%@",value);
----★使用NSMutableArray要防止内存泄露★------
NSObject* p1 = [[NSObject alloc] init];
NSObject* p2 = [[NSObject alloc] init];
NSMutableArray* objectsArray = [[NSMutableArray alloc]init];
[objectsArrayaddObject:p1];
NSLog(@"p1 count:%d", [p1 retainCount]);//输出2,也就是执行追加对象后,对象的计数器也被加1
//[p1 release];
//NSLog(@"p1 count:%d", [p1 retainCount]);
//同样做数组替换时
[objectsArray replaceObjectAtIndex:0 withObject:p2];
NSLog(@"p2 count:%d", [p2 retainCount]);//输出 2,同样也是2
NSLog(@"p1 count:%d", [p1retainCount]);//输出 1,对象p1仍然存在
//[p2 release];
//NSLog(@"p2 count:%d", [p2 retainCount]);
//执行清空数组
[objectsArray removeAllObjects];
NSLog(@"p2 count:%d", [p2 retainCount]);//输出 1,对象p2仍然存在
//[p2 release];
由此可知,每次执行上面的数组操作后,要执行对象release,如上面注释中的语句,才能保证内存不泄露。
NSSet
Unordered collection of objects.
Immutable. You cannot add or remove objects to it once it’screated.
Important methods:
+ setWithObjects:(id)firstObj,...; //nilterminated
Enumerators也就是iterators 或 enumerations.我们可以使用它来1步1步迭代出集合中的所 有成员.
下面是我们可能使用它来列举所有的 key- ‐vaule对
NSEnumerator*e = [myDictkeyEnumerator];
for(NSString *sin e) {
NSLog(@"keyis %@, valueis %@", s,[myDictobjectForKey:s]);
}
注:NSArray 也有1个类似的方法得到 array 的成员迭代 器 :objectEnumerator
NSDictionary *dictionary = [[NSDictionary alloc]initWithObjectsAndKeys:@"One",@"1",@"Two",@"2",@"Three",@"3",nil];
NSString *string =[dictionary objectForKey:@"One"];
NSLog(@"string:%@",string);
NSLog(@"dictionary:%@",dictionary);
[dictionaryrelease];
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1