一 : 赵刚:搜索引擎索引并处理网页的原理
赵刚在上一篇文章中给大家简单阐述了搜索引擎抓取网页的基本原理。如需了解上一篇的内容请到百度搜索赵刚的网站推广进入查看;紧接着搜索引擎就开始对已经抓取到的网页进行处理,为下一步的排序做准备了!
一 般搜索引擎会由专门的分析索引系统程序对收集回来的网页进行分析,然后并提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的所有关键词、关 键词位置、生成时间、大小、与其它网页的链接关系等),在搜索引擎提取到网页的基本信息之后,根据一定的相关度算法进行大量复杂计算,针对页面文字中及超 链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。本文由赵刚首发网站推广的博客,如果转载请保留版权!
赵刚觉得其中,最重要的就是提取关键词,建立索引文件。其他的操作还包括去除重复网页、分析超链接、计算网页的重要度等等。
类似与上边的这一系列的进程,我们做网站推广和网站优化的是看不到的,但是却可以明显的感觉的到。这也就是我们做网站优化的切入点。毕竟赵刚觉得这些最基本的东西也是搜索引擎最核心最经典的,他们是不会有大的改变的,即便是有也是一些算法的改进和完善。
只有当你了解了搜索引擎的这些基本原理之后,你所做的优化工作就会轻松很多,更不会迷茫!由于时间关系,赵刚就先简单介绍到这,下一篇文章会给大家分享搜索引擎的排序并提供检索服务的功能!
本文由赵刚首发赵刚的网站推广博客,如果转载请保留此版权!更多关于网站优化推广请访问:www.cnzg5.com.cn
二 : Google搜索引擎的工作原理
PPCblog.com呈现给我们一幅由Jess Bachman(在WallStats.com工作)精心描绘的示意图,这张流程图展示了每天拥有3亿次点击量的Google搜索按钮背后搜索引擎在那不到1秒的响应时间内所进行的处理。这张流程图演示了在你点击Google搜索按钮后,在Google返回查询结果前那一眨眼的功夫里,Google是如何处理你的搜索请求的?这可是搜索巨人Google年赢利额高达200亿美元的杀手级应用,也是Internet首屈一指的商业和技术神话,大家肯定都想知道Google这棵摇钱树背后的秘密。
Google官方对其搜索技术的叙述
我们搜索技术的后端软件会在服务器侧触发一系列执行时间不到1秒的并行计算,Google问世前的传统搜索引擎的搜索结果严重依赖于关键词在页面上出现的频度,我们使用了200多个指标信号(其中包括我们拥有专利的PageRank页面等级加权算法)用来检查万维网的链接结构(佩奇和布林最初的想法是把万维网的链接结构用图论的有向无环图来建模)并决定网页的重要程度,我们假定一个网页的重要程度取决于别的页面对它的引用,就像学术论文中的引用指数一样,重要的论文总是会被很多其他论文引用。然后我们再根据搜索条件进行超文本匹配分析(对bot抓取的页面内容进行关键词倒排索引检索)确定跟搜索请求最相关的网页。综合最重要的网页和跟搜索请求最相关的网页两个方面,我们就能按重要程度和用户搜索请求相关程度把查询结果排序后呈现给我们的用户。
数据中心:Google用来索引世界的塔
Google的数据中心高度机(www.61k.com)密,我们能了解到的不多:
1. 在美国本土有19个以上的数据中心,其余17个数据中心分布在美国以外的世界各地。
2. 每个数据中心有50万平方英尺那么大,建造一个数据中心要花费约6亿美元。
3. Google数据中心是世界上最高效的设施之一,而且也非常环保,几乎没有碳排放。
4. 数据中心使用50到100兆瓦的电力,由于需要冷却,通常建在便于用水的地方。
5. Google服务器安置在一个一组容得下1160台服务器的有房子那么大的标准集装箱容器中。
处理流程
1.你写博客、或在Twitter上推微博、更新站点等诸如此类往Web上添加内容的操作
2.Google bots程序(一种作为搜索引擎构件的智能代理程序)抓取你网页的title和description、keyword等内容
(1)Google爬虫沿着链接路径周游万维网,如果没有超文本路径到你的站点,你的站点将不会被索引
(2)如果你在robots.txt中设置不许索引,Google爬虫程序将不会抓取你的网页
(3)如果链接到你站点的超文本链接上有nofollow标签,Google爬虫将不会从这些链接路径周游到你的站点。
(4)Google也能通过blog软件或xml站点地图找到你的网站
(5)从PageRank越高的网站链接到你的网站的链接越多,你的网站的PageRank就越高。
(6)Google爬虫将周游所有未标注为nofollow的链接
3.一旦被Google爬虫访问到,网页几秒内就被索引了
(1)网页内容被存储在一个倒排索引中
① 网页标题和链接数据被保存在一个索引中,用于广度优先搜索
② 网页内容保存在另一个索引中,以用于检索频率不高的长尾、个性化、深度优先搜索
(2)当你用Google搜索时,你并没有在检索时时更新的万维网,而是在检索Google的缓存,Google定期更新其索引库,在Twitter实时搜索等的竞争下,Google的索引库更新周期趋短。
4.Google基于链接评估域名和网页的总体PageRank值。
5.检查网页以防止作弊行为
(1)Google的搜索质量和反垃圾信息审查和优化算法
(2) 1万多远程测试用户评价搜索结果的质量
(3) Google征请用户对有PageRank讹诈嫌疑的垃圾信息进行举报
(4) Google接到 (美国)数字千年版权法案的通知,要求Google从搜索结果中剔除涉嫌盗版的内容
6.在对页面做了损害分析后,现在每个页面都有很多用于辅助用户搜索的数据片(比如检索关键词)反向引用着它
7.用户发出搜索请求
(1)Google搜索质量工程师Patrick Riley:在大多数Google搜索中,你的搜索处于许多并行的控制过程或Google实验室的创新项目组过程中,可以说每一个查询请求都会参与一些Google的创意实验。
8.Google会用同义词匹配与你的搜索关键词语义相近的查询结果
9.生成初步的查询结果
(1)Google当然能返回成千上万数量无限的查询结果,但一般只显示不到1000条的查询结果,出于“少则得,多则惑”的考虑。(2)对查询结果做本地化处理,本土站点在查询结果中优先出现
10.对查询结果集按权威性和PageRank进行排序,重复的查询结果被剔除。
(1) Google根据关键词、广告类型、用户所处位置找出相关的被竞价拍卖的关键词广告
(2) 关键词广告必须遵守当地法律条文
① 广告业主的非法广告将被取缔
② 如果关键词的搜索流量过低或关键词广告点击量偏低,则会被自动禁用
③ 出于商业策略,像亚马逊这样的客户会给予优惠折扣。
(3) 关键词相关广告按收益潜力(对关键词进行竞价拍卖后的广告质量不断进行评估)排序
(4) 对广告业主来说广告内容一般都是固定的,但有时使用动态关键词使关键词广告与搜索关键词相关度更高
① 一些广告本身允许增加易变的附属信息,比如网站链接、电话号码、产品链接、地址等
(5) 当广告拥有了相当高的点击率,则会显示在搜索结果列表的上方,以使其更显眼。
(6) 其余的广告依序显示在相应的位置
11.对查询结果进行过滤处理
(1) 对通常的查询(比如在Google首页上发出的搜索请求),Google会把相关的专题性垂直搜索结果(比如新闻、购物、视频、书籍、地图等)也加到返回的查询结果中
(2) 个性化方面:用户访问过的网站在查询结果列表中会更靠上
(3) 大量使用锚点的网站有可能被从查询结果中删除
(4) 搜索结果集的聚簇性:如果网页被其他高PageRank的网站引用,则网页的重要性会大大提高。
(5) 趋势分析:对搜索流量爆增或有大量新闻的搜索关键词,Google会在新的查询结果中增加额外的PageRank权值。(Google有反映关键词搜索流量的Google趋势专题页面)
(6) 同一个域名下的多个网页如果具有相同的PageRank会被归为一组。
12. 最终返回给浏览器端的用户一个人性化的、布局良好的、查询结果和广告泾渭分明的有机查询结果页面。
所有这些步骤在总共不到1秒的响应时间内完成,每天3亿次的点击量给Google带来了超过200亿美元的年收入。
文章来源:honest Translate
三 : 搜索引擎的工作原理是怎样的?
搜索引擎的工作原理是怎样的?
搜索引擎的原理,可以看做三步:从互联网上抓取网页——→建立索引数据库——→在索引数据库中搜索排序。
利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。
搜索引擎的“网络机器人”或“网络蜘蛛”是一种网络上的软件,它遍历Web空间,能够扫描一定IP地址范围内的网站,并沿着网络上的链接从一个网页到另一个网页,从一个网站到另一个网站采集网页资料。它为保证采集的资料最新,还会回访已抓取过的网页。网络机器人或网络蜘蛛采集的网页,还要有其它程序进行分析,根据一定的相关度算法进行大量的计算建立网页索引,才能添加到索引数据库中。
真正意义上的搜索引擎,通常指的是收集了因特网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度高低,依次排列。
四 : 搜索引擎神秘的工作原理

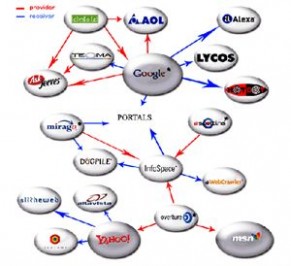
了解搜索引擎的工作原理对我们日常搜索应用和网站提交推广都会有很大帮助。
■ 全文搜索引擎
在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。
另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置/频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。
■ 目录索引
与全文搜索引擎相比,目录索引有许多不同之处。
首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。
其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。尤其象Yahoo!这样的超级索引,登录更是困难。(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录Yahoo雅虎的技巧)
此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。
最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。
目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。
目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围(注)。在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
(注):Yahoo已于2004年2月正式推出自己的全文搜索引擎,并结束了与Google的合作。
搜索引擎按其工作方式主要可分为三种,分别是全文搜索引擎(Full Text Search Engine)、目录索引类搜索引擎(Search Index/Directory)和元搜索引擎(Meta Search Engine)。
■ 全文搜索引擎
全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如Lycos引擎。
■ 目录索引
目录索引虽然有搜索功能,但在严格意义上算不上是真正的搜索引擎,仅仅是按目录分类的网站链接列表而已。用户完全可以不用进行关键词(Keywords)查询,仅靠分类目录也可找到需要的信息。目录索引中最具代表性的莫过于大名鼎鼎的Yahoo雅虎。其他著名的还有Open Directory Project(DMOZ)、LookSmart、About等。国内的搜狐、新浪、网易搜索也都属于这一类。
■ 元搜索引擎 (META Search Engine)
元搜索引擎在接受用户查询请求时,同时在其他多个引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等(元搜索引擎列表),中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,如Dogpile,有的则按自定的规则将结果重新排列组合,如Vivisimo。

除上述三大类引擎外,还有以下几种非主流形式:
1、集合式搜索引擎:如HotBot在2002年底推出的引擎。该引擎类似META搜索引擎,但区别在于不是同时调用多个引擎进行搜索,而是由用户从提供的4个引擎当中选择,因此叫它“集合式”搜索引擎更确切些。
2、门户搜索引擎:如AOL Search、MSN Search等虽然提供搜索服务,但自身即没有分类目录也没有网页数据库,其搜索结果完全来自其他引擎。
3、免费链接列表(Free For All Links,简称FFA):这类网站一般只简单地滚动排列链接条目,少部分有简单的分类目录,不过规模比起Yahoo等目录索引来要小得多。
由于上述网站都为用户提供搜索查询服务,为方便起见,我们通常将其统称为搜索引擎。
附:百度、谷歌搜索引擎原理及新网站应对
第一节 搜索引擎原理
1、基本概念
来源于中文wiki百科的解释:(网络)搜索引擎指自动从互联网搜集信息,经过一定整理以后,提供给用户进行查询的系统。
来源于英文wiki百科的解释:Web search engines provide an interface to search for information on the World Wide Web.Information may consist of web pages, images and other types of files.(网络搜索引擎为用户提供接口查找互联网上的信息内容,这些信息内容包括网页、图片以及其他类型的文档)
2、分类
按照工作原理的不同,可以把它们分为两个基本类别:全文搜索引擎(FullText Search Engine)和分类目录Directory)。
分类目录则是通过人工的方式收集整理网站资料形成数据库的,比如雅虎中国以及国内的搜狐、新浪、网易分类目录。另外,在网上的一些导航站点,也可以归属为原始的分类目录,比如“网址之家”(http://www.61k.com)。
全文搜索引擎通过自动的方式分析网页的超链接,依靠超链接和HTML代码分析获取网页信息内容,并按事先设计好的规则分析整理形成索引,供用户查询。
两者的区分可用一句话概括:分类目录是人工方式建立网站的索引,全文搜索是自动方式建立网页的索引。(有些人经常把搜索引擎和数据库检索相比较,其实是错误的)。
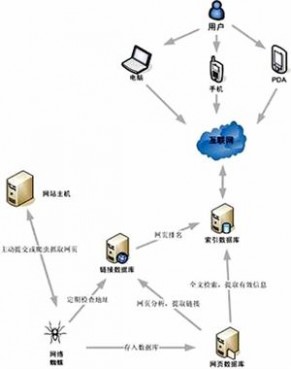
3、全文搜索的工作原理
全文搜索引擎一般信息采集、索引、搜索三个部分组成,详细的可由搜索器、分析器、索引器、检索器和用户接口等5个部分组成
(1)信息采集(Web crawling):信息采集的工作由搜索器和分析器共同完成,搜索引擎利用称为网络爬虫(crawlers)、网络蜘蛛(spider)或者叫做网络机器人(robots)的自动搜索机器人程序来查询网页上的超链接。
进一步解释一下:"机器人"实际上是一些基于Web的程序,通过请求Web站点上的HTML网页来对采集该HTML网页,它遍历指定范围内的整个Web空间,不断从一个网页转到另一个网页,从一个站点移动到另一个站点,将采集到的网页添加到网页数据库中。"机器人"每遇到一个新的网页,都要搜索它内部的所有链接,所以从理论上讲,如果为"机器人"建立一个适当的初始网页集,从这个初始网页集出发,遍历所有的链接,"机器人"将能够采集到整个Web空间的网页。
网上后很多开源的爬虫程序,可以到一些开源社区中查找。
关键点1:核心在于html分析,因此严谨的、结构化的、可读性强、错误少的html代码,更容易被采集机器人所分析和采集。例如,某个页面存在<body这样的标签或者没有</body></html>这样的结尾,在网页显示是没有问题的,但是很有可能会被采集拒绝收录,在例如类似../../***.htm这样的超链接,也有可能造成蜘蛛无法识别。这也是需要推广web标准的原因之一,按照web标准制作的网页更容易被搜索引擎检索和收录。
关键点2:搜索机器人有专门的搜索链接库,在搜索相同超链接时,会自动比对新旧网页的内容和大小,如果一致,则不采集。因此有人担心修改后的网页是否能被收录,这是多余的。
(2)索引(Indexing):搜索引擎整理信息的过程称为“建立索引”。搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。索引可以采用通用的大型数据库,如ORACLE、Sybase等,也可以自己定义文件格式进行存放。索引是搜索中较为复杂的部分,涉及到网页结构分析、分词、排序等技术,好的索引能极大的提高检索速度。
关键点1:虽然现在的搜索引擎都支持增量的索引,但是索引创建依然需要较长的时间,搜索引擎都会定期更新索引,因此即便爬虫来过,到我们能在页面上搜索到,会有一定的时间间隔。
关键点2:索引是区别好坏搜索的重要标志。
(3)检索(Searching):用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。有的系统在返回结果之前对网页的相关度进行了计算和评估,并根据相关度进行排序,将相关度大的放在前面,相关度小的放在后面;也有的系统在用户查询之前已经计算了各个网页的网页等级(Page Rank 后文会介绍),返回查询结果时将网页等级大的放在前面,网页等级小的放在后面。
关键点1:不同搜索引擎有不同的排序规则,因此在不同的搜索引擎中搜索相同关键词,排序是不同的。
第二节 百度搜索引擎工作方式
我所知道的百度搜索:由于工作的关系,小生有幸一直在使用百度的百事通企业搜索引擎(该部门现已被裁员,主要是百度的战略开始向谷歌靠拢,不再单独销售搜索引擎,转向搜索服务),据百度的销售人员称,百事通的搜索核心和大搜索的相同,只有可能版本稍低,因此我有理由相信搜索的工作方式大同小异。下面是一些简单介绍和注意点:
1、关于网站搜索的更新频率
百度搜索可以设定网站的更新频率和时间,一般对于大网站更新频度很快,而且会专门开设独立的爬虫进行跟踪,不过百度是比较勤奋的,中小网站一般也会每天更新。因此,如果你希望自己的网站更新得更快,最好是在大型的分类目录(例如yahoo sina 网易)中有你的链接,或者在百度自己的相关网站中,有你网站的超链接,在或者你的网站就在一些大型网站里面,例如大型网站的blog。
2、关于采集的深度
百度搜索可以定义采集的深度,就是说不见得百度会检索你网站的全部内容,有可能只索引你的网站的首页的内容,尤其对小型网站来说。
3、关于对时常不通网站的采集
百度对于网站的通断是有专门的判断的,如果一旦发现某个网站不通,尤其是一些中小网站,百度的自动停止往这些网站派出爬虫,所以选择好的服务器,保持网站24小时畅通非常重要。
4、关于更换IP的网站
百度搜索能够基于域名或者ip地址,如果是域名,会自动解析为对应的ip地址,因此就会出现2个问题,第一就是如果你的网站和别人使用相同的IP地址,如果别人的网站被百度惩罚了,你的网站会受到牵连,第二就是如果你更换了ip地址,百度会发现你的域名和先前的ip地址没有对应,也会拒绝往你的网站派出爬虫。因此建议,不要随意更换ip地址,如果有可能尽量独享ip,保持网站的稳定很重要。
5、关于静态和动态网站的采集
很多人担心是不是类似asp?id=之类的页面很难被收集,html这样的页面容易被收集,事实上情况并没有想的这么糟,现在的搜索引擎大部分都支持动态网站的采集和检索,包括需要登陆的网站都可以检索到,因此大可不必担心自己的动态网站搜索引擎无法识别,百度搜索中对于动态的支持可以自定义。但是,如果有可能,还是尽量生成静态页面。同时,对于大部分搜索引擎,依然对脚本跳转(JS)、框架(frame)、Flash超链接,动态页面中含有非法字符的页面无可奈何。
6、关于索引的消失
前面讲过,搜索的索引需要创建,一般好的搜索,索引都是文本文件,而不是数据库,因此索引中需要删除一条记录,并不是一件方便的事情。例如百度,需要使用专门的工具,人工删除某条索引记录。据百度员工称,百度专门有一群人负责这件事情——接到投诉,删除记录,手工。当然还能直接删除某个规则下的所有索引,也就是可以删除某个网站下的所有索引。还有一个机制(未经验证),就是对于过期的网页和作弊的网页(主要是网页标题、关键词和内容不匹配),在重建索引的过程中也会被删除。
7、关于去重
百度搜索的去重不如谷歌的理想,主要还是判别文章的标题和来源地址,只要不相同,就不会自动去重,因此不必担心采集的内容雷同而很快被搜索惩罚,谷歌的有所不同,标题相同的被同时收录的不多。
补充一句,不要把搜索引擎想得这么智能,基本上都是按照一定的规则和公式,想不被搜索引擎惩罚,避开这些规则即可。
第三节 谷歌搜索排名技术
对于搜索来说,谷歌强于百度,主要的原因就是谷歌更加公正,而百度有很多人为的因素(这也符合我国的国情),google之所以公正,源于他的排名技术Page Rank。
很多人知道Page Rank,是网站的质量等级,越小表示网站越优秀。其实Page Rank是依靠一个专门的公式计算出来的,当我们在google搜索关键词的时候,页面等级小的网页排序会越靠前,这个公式并没有人工干预,因此公正。
Page Rank的最初想法来自于论文档案的管理,我们知道每篇论文结尾都有参考文献,假如某篇文章被不同论文引用了多次,就可以认为这篇文章是篇优秀的文章。
同理,简单的说,PageRank 能够对网页的重要性做出客观的评价。PageRank 并不计算直接链接的数量,而是将从网页 A 指向网页 B 的链接解释为由网页 A 对网页 B 所投的一票。这样,PageRank 会根据网页 B 所收到的投票数量来评估该页的重要性。此外,PageRank 还会评估每个投票网页的重要性,因为某些网页的投票被认为具有较高的价值,这样,它所链接的网页就能获得较高的价值。
Page Rank的公式这里省略,说说影响Page Rank的主要因素
1、指向你的网站的超链接数量(你的网站被别人引用),这个数值越大,表示你的网站越重要,通俗的说,就是其它网站是否友情链接,或者推荐链接到你的网站;
2、超链接你的网站的重要程度,意思就是一个质量好的网站有你的网站的超链接,说明你的网站也很优秀。
3、网页特定性因素:包括网页的内容、标题及URL等,也就是网页的关键词及位置。
第四节 新网站如何应对搜索
以下内容是对上面分析的总结:
1、搜索引擎为什么不收录你的网站,存在以下可能(不绝对,根据各自情况不同)
(1)没有任何指向链接的孤岛网页,没有被收录的网站指向你的超链接,搜索引擎就无法发现你;
(2)网站中的网页性质及文件类型(如flash、JS跳转、某些动态网页、frame等)搜索引擎无法识别;
(3)你的网站所在服务器曾被搜索引擎惩罚,而不收录相同IP的内容;
(4)近期更换过服务器的IP地址,搜索引擎需要一定时间重新采集;
(5)服务器不稳定、频繁宕机,或者经不起爬虫采集的压力;
(6)网页代码劣质,搜索无法正确分析页面内容,请至少学习一下HTML的基本语法,建议使用XHTML;
(7)网站用robots(robots.txt)协议拒绝搜索引擎抓取的网页;
(8)使用关键词作弊的网页,网页的关键词和内容严重不匹配,或者某些关键词密度太大;
(9)非法内容的网页;
(10)相同网站内存在大量相同标题的网页,或者网页的标题没有实际含义;
2、新站如何做才正确(仅供参考)
(1)和优秀的网站交换链接;
(2)广泛登录各种大网站的网站目录列表;
(3)多去质量好的论坛发言,发言要有质量,最好不要回复,发言中留下自己网站地址;
(4)申请大网站的博客(新浪、网易、CSDN),并在博客中推广自己的网站;
(5)使用好的建站程序,最好能生成静态页面和自动生成关键词;
(6)重视每个网页的标题,以及<head>区域,尽量把符合的关键词放在这些容易被搜索索引的位置,重视文章的开头部分,尽可能在文章的开始部分使用类似摘要的功能(可以学学网易的文章样式)。
例如“基于开源jabber(XMPP)架设内部即时通讯服务的解决方案”;
标题部分:<title>基于开源jabber(XMPP)架设内部即时通讯服务的解决方案 - 肥龙龙(expendable)的专栏 - CSDNBlog</title>
关键词部分:<meta name="keywords" cCOLOR: #c00000">安装,">
文章描述部分:<meta name="description" cCOLOR: #c00000">是著名的即时通讯服务服务器,它是一个自由开源软件,能让用户自己架即时通讯服务器,可以在Internet上应用,也可以在局域网中应用。
XMPP(可扩展消息处理现场协议)是基于可扩展标记语言(XML)的协议,它用于即时消息(IM)以及在线现场探测。它在促进服务器之间的准即时操作。这个协议可能最终允许因特网用户向因特网上的其他任何人发送即时消息,即使其操作系统和浏览器不同。XMPP的技术来自于Jabber,其实它是 Jabber的核心协定,所以XMPP有时被误称为Jabber协议。Jabber是一个基于XMPP协议的IM应用,除Jabber之外,XMPP还支持很多应用。
下面就是如何架设内部即时通讯服务的步骤:
(7)按照web标准的要求,规范自己网页的html代码,让自己的网页通过w3c代码和css标准检测;
(8)不要想着作弊,做好网站内容最关键。
来自:
本文标题:
搜索引擎的工作原理-赵刚:搜索引擎索引并处理网页的原理 本文地址:
http://www.61k.com/1170062.html