一 : SEO新手 浅谈搜索引擎工作原理
搜索引擎工作原理如下:
也许很多人会问,现在互联网发展到今时今日,已成为了区别于现实世界的另一个世界,也就是虚拟的世界,那么他的网页数量到目前究竟有多少呢?如果要具体说出一个确切的数据,肯定没有人能够回答的出来的,但是我敢肯定的说,目前的网页数量至少是以千亿来计算,因为这是一个随时变化的数据,而且数据非常庞大,没有人能精确算出来。这些网页,组成不同的网站,存储在世界各地不同的服务器上,并且分布在世界各地数据中心和机房里。
也许还有大部分人认为,当我们在搜索框里敲入搜索请求,搜索引擎就会实时地从世界各地的服务器上进行查询信息、收集整理,并把查询结果排序展示在用户面前。包括我之前还没有接触搜索引擎时,也是认为搜索引擎就是这样子工作的,但是今天我知道这是一个错误的认为,搜索引擎不是这样工作的。
全球这么多网页,搜搜引擎是不可能进行实时地全部抓取,并整理排序的,对全球网页进行全部抓取需要很大的储存空间和技术,目前没有哪一个搜索引擎能承受的起的。据统计,如果搜索引擎是进行实时工作的话,当你发出你的搜索请求到看到搜索结果,这个“实时”可能要等上好几年甚至更长。
那么面对如此庞大的数据库,搜索引擎又是如何去工作的呢?就此,漠阳子SEO博客给大家分析一下!
我们通俗地说,其实是这么一回事,搜索引擎尽最大的能力,预先就去深入大量网站,把这些网页的部分认为是有价值的信息预先存储在自己的服务器上;然后,当用户搜索时,再从自己的服务器上把适合的信息展现出来。就好比如我们在互联网上找资料和在自己电脑上找资料的区别。
从搜索引擎的基本技术来讲,包括抓取、索引、排序三个方面。
第一,抓取
相信大家对于搜索引擎里所说的“蜘蛛”、“机器人”不会很陌生,他就像是搜索引擎的一大猛将,根据一定的程序规则,这位“猛将”在互联网上进行扫描,以网站的链接为桥梁进行不断的爬行。从而所进过的新站、旧站,只要是它认为是有价值的信息,就进行抓取,并收入囊中。
第二,索引
每一个搜索引擎都会有自己的一套分析索引系统,对抓取回来的网页进行相关的提取,比如网页的URL、编码、页面内容、链接、生成时间、关键词等,通过一定的算法进行复杂的计算,并计算出网页的相关度(关键词、重要性),然后建立一个索引数据库。
第三。排序
排序,简单地说就是当用户输入关键词并发出搜索请求后,搜索引擎的系统就会根据你的关键词在网页索引数据库里进行查找,然后再显示在搜索结果上返回给用户。按照自然排名来说,这些索引数据库里的网页事先已经计算好相关度的了,越接近搜索请求的要求就越排在前面。这也是为什么我们要对网站进行优化的关键所在,想必每个网站都是想跻身在前面的。
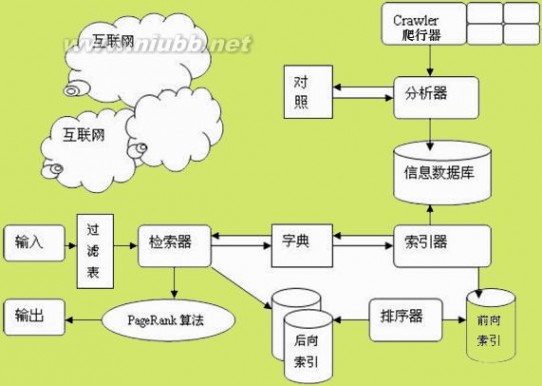
最后我们来看一幅搜索引擎工作原理的图,这样会更直观明了。
如果图片不清楚的话,大家可以点击查看大图的。希望本文能够给你带来帮助。
二 : 汽车工作原理动画之三(引擎)
三 : 离子引擎:离子引擎-工作原理
离子引擎就是使用电离气体作为推进剂的飞船推进设备,与太阳帆一道,都属于电推进家族。它也是目前性能最好、最成熟的电推进系统。 最早的离子引擎于1960年左右由NASA的Glenn研究中心制成,但之后一直处于试验阶段,1998年,美国彗星探测器"深空1号"首次将离子引擎作为主力推进系统应用在深空飞行。日本于2003年发射的隼鸟号小行星探测器使用的也是离子推进器。 早在1974年相关院所就开始研制离子电推力系统。2012年10月,我国发射的首颗民用新技术试验卫星"实践9号"就采用了510所研制的离子电推进系统。 目前,NASA的最新一代离子推进器的功率达到7KW,而中国电推力器的功率达到1KW至5KW量级。中国空间技术研究院计划在2020年完成50千瓦量级大功率推力器的关键技术攻关。
离子引擎_离子引擎 -工作原理
Deep Space 1的离子引擎结构图,上排标注自左向右为:推进剂贮藏装置、电中和器,下排为:供电系统、电离室、离子加速电极、推力(图片提供:Boeing Electron Dynamic Devices)。
阴极在电离室左端。
离子引擎运转的首要条件就是制造离子气体。这通常需要由电子枪来完成。管状阴极发出的电子束被射入经磁化的电离室,与充在室中的气体原子碰撞,令原子电离成一价正离子。如上图所示,电离室的另一端装有一对金属网,网上加有上千伏(Deep Space 1的所加电压是1280伏)的电压,可将离子加速到每秒30米的速度,并从尾部排出,形成离子束,由此产生推力。在这一点上,离子推进技术与传统的化学推进技术一致:推力都是靠喷射物质产生的,只是令物质喷出的方式不同而已。至于电子枪的电源,一般由飞船的太阳能电池板充当就可以,这样的结构被称为太阳能——电推进系统,至今为止采用离子引擎的几项任务都使用此系统。
如果想让离子引擎正常工作,还有个疑难问题必须解决:引擎持续喷射出正离子束,会将带有负电的电子留在其中,这就形成了引擎中强大的负电场,严重阻碍了正离子的继续排出,电子积累足够多的话,甚至会将排出的正离子再吸引回来。解决此问题的方案是在喷射离子的排气网附近再安装一支电子枪作为电中和器,持续向离子束中注入电子,既可以中和离子束,又避免了引擎过度带电。
当然在实际使用中,还要考虑许多具体细节,比如形成持续离子流的方法。在发展早期,NASA Lewis中心的Harold Kaufman发明了电离汞蒸汽的设备,当时已到Marshall中心工作的Stuhlinger则研制出了利用钨或铼制成的表面电离铯原子的方法。不过Deep Space 1和SMART-1都使用氙作为推进剂,原因除了氙的推进效率更高之外,更考虑到惰性气体不易对探测器的设备造成损坏,比汞和铯强上很多。尤其是铯,作为活动性最强的碱金属,其强腐蚀性对设备的耐用性和稳定性也是个很不利的因素。
另外,还可以利用微波来电离气体,这样的系统叫做微波离子引擎。旨在探测小行星糸川并取样返回的Hayabusa探测器即安装了此种引擎,它亦采用氙作为推进剂,除去离子化设备之外,其他部分与普通离子引擎无甚差别,不过没有查到其电中和器具体使用的是什么装置,未敢定论。
各探测器的离子引擎。上左:Lewis中心设计的引擎正在JPL进行测试,蓝光由带电离子发出(图片提供:NASA / JPL)。该引擎是Deep Space 1的引擎原型。上右:Deep Space 1的离子引擎,排气网安装在图中央的支撑环内(图片提供:NASA / JPL)。下左:测试中的SMART-1引擎(图片提供:ESA)。下右:Hayabusa的微波离子引擎,其原形机在测试时曾连续运转了超过18000小时(图片提供:ISAS)。
其实离子引擎的工作原理并不很复杂,之所以长期没能投入实际使用,不仅仅是由于阿波罗登月计划的干扰,更有新技术的可靠性问题,而各探测任务的参与者往往不希望承担新技术带来的不必要风险。举例来说,虽然理论上讲可以用电子枪解决离子的中和问题,不过要检验这一方法的有效性,必须要排除离子束与真空区域边界相互作用的影响,这在地球上是几乎不可能做到的,所以其效果究竟如何一直不能定论。而作为NASA新千年计划的第1个组成部分,Deep Space 1的主要目的之一就是测试包括离子引擎在内的十余项新技术,科学探测反倒在其次;SMART-1和Hayabusa也为各自的机构承担着类似的技术测试任务,它们自然即可较少地顾及新技术失败的风险了。
四 : 搜索引擎工作原理概述
让网络营销管理 简单、直接、有效、可视化
Simple,direct,effeftive,and visualization
搜索引擎工作原理的几个基本问题解答
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
类型:
A.全文检索搜索引擎(全文索引)
B.目录搜索引擎(目录索引)
C.元搜索引擎
E.其他非主流形式
A.全文搜索引擎:名副其实的搜索引擎,通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。如:百度、Google、360
B.目录搜索引擎:目录索引虽然有搜索功能,但在严格意义上算不上是真正的搜索引擎,以人工方式或半自动方式搜集信息,仅仅是按目录分类的网站链接列表而已。用户完全可以不用进行关键词查询,仅靠分类目录也可找到需要的信息。如:搜狐、新浪、网易。
C. 元搜索引擎:是通过一个统一的用户界面帮助用户在多个搜索引擎中选择和利用合适的(甚至是同时利用若干个)搜索引擎来实现检索操作,并将结果返回给用户。如:搜星搜索引擎,优客搜索、360综合搜索。
D. 其他:如垂直搜索引擎:不同于通用的网页搜索引擎,垂直搜索专注于特定的搜索领域和搜索需求(例如:机票搜索、旅游搜索、生活搜索、小说搜索、视频搜索等等),在其特定的搜索领域有更好的用户体验,更加专注、具体和深入。
用户检索系信息展示的结果是怎么来的?
SEO搜索引擎优化,是一种利用搜索引擎的搜索规则来提高目的网站在有关搜索引擎内的排名的方式。
前提:了解搜索引擎自然排名机制、工作原理。
目的:对网站进行内部和外部的调整优化,改进网站在搜索引擎中关键词的自然排名,获得更多流量,从而达到网络营销及品牌建设的目标。
网页快照:网页缓存或者备份网页
1,保留网页修改前的内容信息。
2,体现蜘蛛爬行网站的频率等分析蜘蛛的信任度
3,当网页打不开时或者打开速度慢时,可以用网页快照打开,很快就会打开。以文本方式打开网页内容,加载速度快。
了解搜索引擎的原因:保证用户体验的基础上尽量迎合搜索引擎。搜
索引擎要解决什么问题,有哪些技术上的困难,有什么限制,搜索引
擎又怎样取舍。
搜索引擎工作首要环节是什么??
答案:如何有效的获取并利用这些信息。
数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做“spider”。
如:Baiduspdier、sosospdier、Googlebot、Sogou Web Spider等。 通过日志能查询详细情况。
蜘蛛:是搜索引擎用来爬行和访问页面的程序。访问互联网上的html网页,建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。
索引数据库等简单说明。
没有抓取和纳入索引数据库的信息等等详细说明。
问题:搜索引擎是如何抓取网页???
发现某一个链接 → 下载这一个网页 → 加入到临时库 → 提取网
页中的链接 → 在下载网页 → 循环。
通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。
robots协议,网站时要访问的第一个文件,用以来确定哪些是被允许抓取的哪些是被禁止抓取的,遵守君子协议。
例子:
1. 允许所有SE(搜索引擎)收录本站:robots.txt为空就可以,什么都不要写。
2. 禁止所有SE(搜索引擎)收录网站的某些目录:
User-agent: *
Disallow: /目录名1/
Disallow: /目录名2/
Disallow: /目录名3/
3. 禁止某个SE(搜索引擎)收录本站,例如禁止百度:
User-agent: Baiduspider
Disallow: /
User-agent: Googlebot
4. 禁止所有SE(搜索引擎)收录本站: User-agent: *
它的用途是告诉上一子集,确定某个对象用的。
链接的几种形式:
文本链接:www.61k.com
超链接:www.61k.com
锚文本:SEO优化
抓取策略:
深度策略广度策略
1、抓取友好性:抓取压力调配降低对网站的访问压力
2、常用抓取返回码示意
3、多种url重定向的识别
4、抓取优先级调配
5、重复url的过滤
6、暗网数据的获取
7、抓取反作弊
8、提高抓取效率,高效利用带宽
—原文地址: 本文由杭州橙速网络科技有限公司原创提供,转载请注明出处
五 : 搜索引擎分类与工作原理
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1