一 : 了解搜索引擎技术
此文纯理论知识,很不错的搜索引擎的资料。(www.61k.com)
搜索引擎的定义 搜索引擎是传统IR技术在Web环境中的应用。一般来说,搜索引擎是一种用于帮助用户在Internet上查询信息的搜索工具,它以一定的策略在Internet中搜索,发现信息,对信息进行理解,提取,组织和处理,并为用户提供检索服务,从而起到信息导航的目的。
搜索引擎是传统IR技术在Web环境中的应用。一般来说,搜索引擎是一种用于帮助用户在Internet上查询信息的搜索工具,它以一定的策略在Internet中搜索,发现信息,对信息进行理解,提取,组织和处理,并为用户提供检索服务,从而起到信息导航的目的。
搜索引擎的体系结构典型的搜索引擎结构一般由以下三个模块组成:信息采集模块(Crawler),索引模块(Indexer),查询模块(Searcher)。
Crawler:从web中采集网页数据
Indexer:对Crawler采集数据进行分析生成索引。
Searcher:接受查询请求,通过一定的查询算法获取查询结果,返回给用户。
-->Crawler
Crawler负责页面信息的采集,工作实现基于以下思想:既然所有网页都可能链接到其他网站,那么从一个网站开始,跟踪所有网页上的所有链接,就有可能检索整个互联网。Crawler首先从待访问URL队列中获取URLs,根据URL从中抓取网页数据,然后对网页进行分析,从中获取所有的URL链接,并把它们放到待访问的URL队列中,同时将已访问URL移至已访问的URL队列中。不断重复上面的过程。
Crawler存在以下的关键问题:
>多线程抓取时的任务调度问题:
搜索引擎会产生多个Crawler同时对网页进行抓取,这里需要一个好的分布式算法,使得既不重复抓取网页,又不漏掉重要的站点。
>网页评估
在抓取网页时存在一定的取舍,一般只会抓20%左右的网页。评估算法中典型的油Google发明的Pgaerank。
>更新策略
每经过一段时间,Crawler对以抓取的数据经行更新,保证索引网页是最新的。
>压缩算法
网页抓取后,通过一定的压缩机制保存到本地,从而减少存储容量,同时也减少各服务器之间的网络通信开销
-->Indexer
搜索引擎在完成用户的检索请求时,并不是即时的检索Web数据,而是从预先采集的网页数据中获取。要实现对采集页面的快速访问,必须通过某种检索机制来完成。
页面数据可以用一系列关键字来表示,从检索毙敌来说,这些关键词描述了页面的内容,只要找到页面,便可以找到其中的关键词,反过来,通过关键词对页面创建索引,便可以根据关键字快速的找到相应的网页。
Indexer中存在的问题:
>索引存储:
一般来讲,数据量和索引量的比例接近1:1。索引的存储一般采用分布式策略,检索的数据分布在不同的服务器上。Google存储索引的服务器大概有1000多台。
>索引更新:
页面数据更新时,索引数据必须相应的更新。更新策略一般采用增量索引方式。
>索引压缩:
索引也存在数据压缩的问题。索引压缩是通过对具体索引格式的研究实现压缩。
>网页相似性支持:
索引的结构还必须为网页相似性分析提供支持。
>多语言,多格式支持:
网页数据具有多种编码格式,通过Unicode,索引支持多种编码查询。同时索引还必须有对Word,Excel等文件格式进行分析的功能。
-->Searcher
Searcher是直接与用户进行交互的模块,在接口上有多种实现的方式,常见的主要是Web方式。
Searcher通过某种接口方式,接受用户查询,对查询进行分词(stemming)处理,获取查询关键字。通过Indexer获取与查询关键字匹配的网页数据,经过排序后返回给用户。
Searcher中的问题:
>检索结果的排序:
对不同的用户采用不同的排序策略。
>排序结果排重:
排重可以提高结果数据的质量。
>检索结果的相似性分析:
主要用在类似网页功能中,需要在索引结构中提供支持。
>检索的速度:
主要依赖索引结构的设计。同时在体系结构上还有很多技术可以用来提升速度。如:Cache,负载均衡等。
相关核心技术:分布式技术:
当搜索引擎处理数据达到一定规模时,为了提高系统的性能,必须采用分布式技术。Crawler通过多个服务器互相合作,提高数据采集的速度。Indexer在生成索引数据时通过并行算法,在不同机器上同时进行。Searcher也可以在不同的机器上进行同时查询,提高速度。中文分词:
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。现有分词算法可以分为三大类:基于字符串比配的的分词方法,基于理解的分词方法和基于统计的分词方法。网页排序:
现在搜索引擎中网页的 排序主要利用了页面间的链接关系,描述链接的文本以及文本自身内容,重要的链接分析算法有Hits和Pagerank,HillTop等。海量数据存储:
搜索引擎的挑战之一就是处理数据的巨大,如何存储如此大的数据,数据的更新,快速的检索...压缩技术:
压缩技术极大的减少了数据的大小,对于不同类型的数据,需要采用不同的压缩方法,主要的数据压缩主要有:网页数据的压缩和索引数据的压缩。选择压缩技术主要从开放性,速度与压缩比等多方面进行综合考虑。Google中选择了Alib(RFC1950)进行压缩,在压缩速度上Zlib超过Bzip,压缩比上Bzip好于Zlib。
二 : 搜索引擎技术原理
搜索引擎(search engine)是指根据一定的策略、运用特定的计算机程序搜集互联网上的信息,在对信息进行组织和处理后,为用户提供检索服务的系统。(www.61k.com)一、Web搜索引擎技术综述(一) 、引子随着网络技术的应用与发展,互连网已经成为信息的重要来源地。搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的,互联网用户使用网络获取信息过程中,搜索引擎也成为必不可少的工具。调查表明,当前的所有互连网应用中,网络信息搜索是仅次于电子邮件的第二大应用,而这些搜索绝大多数是专门的,高度复杂的搜索引擎实现的。按照信息搜集方法和服务提供方式的不同,搜索引擎系统可以分为三大类:① 目录式搜索引擎,以人工方式或半自动方式搜集信息,由编辑员查看信息之后,人工形成信息摘要,并将信息置于事先确定的分类框架中,由于web信息的海量性和人工处理能力、经济代价的限制,这类搜索引擎信息的即时性和全面性难以保证,它的优秀代表是Yahoo等。② 机器人搜索引擎,由一个称为蜘蛛(Spider)的机器人程序以某种策略自动地在互联网中搜集和发现信息,由索引器为搜集到的信息建立索引,由检索器根据用户的查询输入检索索引库,并将查询结果返回给用户,这类搜索引擎实现较为复杂,但能很好的实现信息的全面获取和即时更新,它的优秀代表是Google等。③ 元搜索引擎,这类搜索引擎没有自己的数据,而是将用户的查询请求同时向多个搜索引擎递交,将返回的结果进行重复排除、重新排序等处理后,作为自己的结果返回给用户,这类搜索引擎兼集多个搜索引擎的信息,并且加入新的排序和信息过滤,可以很好的提高用户满意度。(二) 、web搜索引擎的原理和实现web搜索引擎的原理通常为:首先是用蜘蛛(Spider)进行全网搜索,自动抓取网页;然后将抓取的网页进行索引,同时也会记录与检索有关的属性,中文搜索引擎中还需要首先对中文进行分词;最后,接受用户查询请求,检索索引文件并按照各种参数进行复杂的计算,产生结果并返回给用户。1.利用网络蜘蛛获取网络资源这是一种半自动化的资源(由于此时尚未对资源进行分析和理解,不能成为信息而仅是资源)获取方式。所谓半自动化,是指搜索器需要人工指定起始网络资源URL(Uniform Resource Locator),然后获取该URL所指向的网络资源,并分析该资源所指向的其他资源并获取。如Google的在利用蜘蛛程序获取网络资源时,是由一个认
搜索引擎技术 搜索引擎技术原理
为管理程序负责任务的分配和结果的处理,多个分布式的蜘蛛程序从管理程序活动任务,然后将获取的资源作为结果返回,并重新获得任务。[www.61k.com]2.利用索引器从搜索器获取的资源中抽取信息,并建立利于检索的索引表当用网络蜘蛛获取资源后,需要对这些进行加工过滤,去掉控制代码及无用信息,提取出有用的信息,并把信息用一定的模型表示,使查询结果更为准确。Web上的信息一般表现为网页,对每个网页,须生成一摘要,此摘要将显示在查询结果的页面中,告诉查询用户各网页的内容概要。模型化的信息将存放在临时数据库中,由于web数据的数据量极为庞大,为了提高检索效率,须按照一定规则建立索引。不同搜索引擎在建立索引时会考虑不同的选项,如是否建立全文索引,是否过滤无用词汇,是否使用meta信息等。3.检索及用户交互这部分的主要内容包括:用户查询(query)理解,即最大可能贴近的理解用户通过查询串想要表达的查询目的,并将用户查询转换化为后台检索使用的信息模型;根据用户查询的检索模型,在索引库中检索出结果集;结果排序:通过特定的排序算法,对检索结果集进行排序。由于web数据的海量性和用户初始查询的模糊性,检索结果集一般很大,而用户一边不会有足够的耐性逐个查看所有的结果,所以怎样设计结果集的排序算法,把用户感兴趣的结果排在前面就十分重要。(三) 、web搜索引擎的最新动态当前,搜索引擎技术已经趋于成数,用户满意度也保持在一个可以接受的水平。在信息搜集技术,索引建立技术,检索技术和结果集排序技术方面,最近几年,Google创造性的提出page rank技术,并把他用于结果排序。而搜索引擎的研究与信息集成逐渐融合,在这方面的研究主要集中在两个方面:查询扩展(query expansion)和结果集的动态分类。二、Google技术(一)Google技术概论Google 秉持开发“完美的搜索引擎”的信念。所谓完美的搜索引擎,就如公司创始人之一 Larry Page 所定义的那样,可以“确解用户之意,切返用户之需”。为了实现这一目标,Google 坚持不懈地追求创新,而不受现有模型的限制。因此,Google 开发了自己的服务基础结构和具有突破性的 Page Rank技术,使得搜索方式发生了根本性变化。Google 的开发人员从一开始就意识到:要以最快的速度提供最精确的搜索结果,则需要一种全新的服务器设置。大多数的搜索引擎依靠少量大型服务器,这样,在访问高峰期速度就会减慢,而 Google 却利用相互链接的 PC 来快速查找每个搜索的答案。 这一创新技术成功地缩短了
搜索引擎技术 搜索引擎技术原理
响应时间,提高了可扩展性,并降低了成本。(www.61k.com]这也是其他公司一直在效仿的技术。与此同时,Google 从未停止过对其后端技术的改进,以使其技术效率更高。Google 搜索技术所依托的软件可以同时进行一系列的运算,且只需片刻即可完成所有运算。而传统的搜索引擎在很大程度上取决于文字在网页上出现的频率。Google 使用Page Rank 技术检查整个网络链接结构,并确定哪些网页重要性最高。然后进行超文本匹配分析,以确定哪些网页与正在执行的特定搜索相关。在综合考虑整体重要性以及与特定查询的相关性之后,Google 可以将最相关最可靠的搜索结果放在首位。1、Page Rank 技术:通过对由超过 50,000 万个变量和 20 亿个词汇组成的方程进行计算,Page Rank 能够对网页的重要性做出客观的评价。Page Rank 并不计算直接链接的数量,而是将从网页 A 指向网页 B 的链接解释为由网页 A 对网页 B 所投的一票。这样,Page Rank 会根据网页 B 所收到的投票数量来评估该页的重要性。此外,Page Rank 还会评估每个投票网页的重要性,因为某些网页的投票被认为具有较高的价值,这样,它所链接的网页就能获得较高的价值。重要网页获得的 Page Rank(网页排名)较高,从而显示在搜索结果的顶部。Google 技术使用网上反馈的综合信息来确定某个网页的重要性。搜索结果没有人工干预或操纵,这也是为什么 Google 会成为一个广受用户信赖、不受付费排名影响且公正客观的信息来源。 2、超文本匹配分析:Google 的搜索引擎同时也分析网页内容。然而,Google 的技术并不采用单纯扫描基于网页的文本(网站发布商可以通过元标记控制这类文本)的方式,而是分析网页的全部内容以及字体、分区及每个文字精确位置等因素。Google 同时还会分析相邻网页的内容,以确保返回与用户查询最相关的结果。 Google 的创新并不限于台式机。 为了确保通过便携式设备访问网络的用户能够快速获得精确的搜索结果,Google 还率先推出了业界第一款无线搜索技术,以便将 HTML 即时转换为针对 WAP、I-mode、J-SKY 和 EZWeb 优化的格式。(二)Google 查询的全过程Google 查询的全过程通常不超过半秒时间,但在这短短的时间内需要完成多个步骤,然后才能将搜索结果交付给搜索信息的用户。1. 网络服务器将查询发送到索引服务器。索引服务器所包含的内容与书本末尾的索引目录相似,即说明哪些网页包含与查询匹配的文字。2.查询传输到文档服务器,由后者实际检索所存储的文档。然后,生成描述每个搜索结果的摘录。3. 瞬间返回用户需要的搜索结果。三
搜索引擎技术 搜索引擎技术原理
、百度技术(一)、百度搜索引擎概论百度搜索引擎由四部分组成:蜘蛛程序、监控程序、索引数据库、检索程序。[www.61k.com)百度搜索引擎使用了高性能的“网络蜘蛛”程序自动的在互联网中搜索信息,可定制、高扩展性的调度算法使得搜索器能在极短的时间内收集到最大数量的互联网信息。百度在中国各地和美国均设有服务器,搜索范围涵盖了中国大陆、香港、台湾、澳门、新加坡等华语地区以及北美、欧洲的部分站点。百度搜索引擎拥有目前世界上最大的中文信息库。(二)、百度搜索关键技术1、查询处理以及分词技术随着搜索经济的崛起,人们开始越加关注全球各大搜索引擎的性能、技术和日流量。网络离开了搜索将只剩下空洞杂乱的数据,以及大量等待去费力挖掘的金矿。 但是,如何设计一个高效的搜索引擎?我们可以以百度所采取的技术手段来探讨如何设计一个实用的搜索引擎.搜索引擎涉及到许多技术点,比如查询处理,排序算法,页面抓取算法,CACHE机制,ANTI-SPAM等等.这些技术细节,作为商业公司的搜索引擎服务提供商比如百度、GOOGLE等是不会公之于众的.我们可以将现有的搜索引擎看作一个黑盒,通过向黑盒提交输入,判断黑盒返回的输出大致判断黑盒里面不为人知的技术细节。查询处理与分词是一个中文搜索引擎必不可少的工作,而百度作为一个典型的中文搜索引擎一直强调其“中文处理”方面具有其它搜索引擎所不具有的关键技术和优势。2、Spelling Checker拼写检查错误提示(以及拼音提示功能) 拼写检查错误提示是搜索引擎都具备的一个功能,也就是说用户提交查询给搜索引擎,搜索引擎检查看是否用户输入的拼写有错误,对于中文用户来说一般造成的错误是输入法造成的错误。这就依赖于百度的拼写检查系统,其大致运行过程如下: 后台作业: (1)百度分词使用的词典至少包含两个词典一个是普通词典,另外一个是专用词典(专名等),百度利用拼音标注程序依次扫描所有词典中的每个词条,然后标注拼音,如果是多音字则把多个音都标上,比如“长大”,会被标注为“zhang da /chang da”两个词条。(2)通过标注完的词条,建立同音词词典,比如上面的“长大”,会有两个词条: zhang daà长大 , chang daà长大。(3)利用用户查询LOG频率信息给予每个中文词条一个权重; (4)随着分词词典的逐步扩大,同音词词典也跟着同步扩大。拼写检查: (1)用户输入查询,如果是多个子字符串,不作拼写检查; (2)对于用户查询,先查分词词典,如果发现有这个单词词条,不作拼写检查; (3)如果发现词典里面不包含用户查询,启动拼写检查系统;首
搜索引擎技术 搜索引擎技术原理
先利用拼音标注程序对用户输入进行拼音标注; (4)对于标注好的拼音在同音词词典里面扫描,如果没有发现则不作任何提示; (5)如果发现有词条,则按照顺序输出权重比较大的几个提示结果。(www.61k.com]
三 : 搜索引擎SEO伪技术你掌握到第几层了?
对于SEO行业鱼龙混杂,在网站SEO还是个半成品的时候就有人找我做业务,于是就硬着头皮接了下去,想着努力冲关,于是SEO网站也就放松了,也是断断续续的更新,网站排名迟迟不好。
后渐渐明白SEO行业的越来越多的东西,慢慢明白业务的那些事,更明白些许沉淀的东西,包括那个半成品,甚至是什么都不懂,原来也只不过是一些伪SEO技术而已。
伪技术一.理论高手类
想当年也是喜欢看书,理论东西多,脑袋都装满了,看什么都东西都能说的头头是道,是个屎都能说出百种味道,但是又不失逻辑,这或许就是TM的学术派吧。
为什么那么多人都喜欢从事学术派呢?此类问题暂且不论,简行SEO以前也是想走这一派,后家里频频出事让我渐渐明白什么才是最重要的,这似乎跟SEO是一样的。
失去了你才知道什么是最重要的,失败了你才知道哪些东西才是SEO应该专注的重点。
经常看电视上那些人讲的头头是道,有理有据,让他下来按照他自己说的操作一遍计都难的要死,在台上看SEO老师讲的很好,逻辑有序,案例给力,也许他们也并没有说的那么厉害,伪艺术永远存在于世界每个角落里,但是想要学习这个技术,理论还是有必要过一遍,勤奋是技术派的本性,理论似乎才是伪技术的核心。
伪技术二.时代与趋势感
所谓时代趋势,大势所向,在这个时代你就得顺应趋势不是吗,别人家添枝增叶了,你家也得加紧了,简行SEO提醒你这TM不是顺应趋势,这TM叫扎堆跟风玩高仿。
同样道理很多人基于生存都过于看重竞争市场,反而忽略了本位市场,害怕用户流失,剑走偏锋,也是在跟自己玩火,虚到了另一个境界,伪之又伪,没有本真可言,策略一次又一次的失误,最后也会酿成大祸。
SEO行业存在那么多年,叫失了那么多年,简行SEO提醒你过于新的东西也可能会害了你,为什么要这样说?
SEO是技术,之前有(“SEO”是SEO优化的一道魔之碍障)一文也说过SEO人员,要面对三个层面,一是用户,二是百度,三是网站,技术过多是网站上的应用层面,思维过多是用户和运营方面的认识,要如何运营这些技术,合理操作,而不是一时的昙花一现。过多的新东西也只不过是内心愿景的虚妄而已,变为现实远远没有那么容易的。
伪技术三.无技术派
当然这个谈起来多少有些扯淡,一个没有技术的人怎么运营一个好网站呢?这种天言之论,千奇世界,这个时代什么样的人会没有呢?
一个网站不做SEO根本就做不上来排名,这种事现在这社会什么事不可能,一个网站不做SEO就会有排名,当然有可能的,但是多数公司只要有网站都会在这方面给于人才支持的,毕竟在搜索时代不敢保证明天仍然存在原位。
一个SEO皮毛大师只要有一个网站排名好的网站,也可称SEO高手,有谁不服吗,不服你也搞一个好排名的网站瞧一瞧,这种现实感,让你不得不恐惧到底谁者是真的有技术,到底哪个机构才有真的值你花钱去学习技术?世界这么大,伪技术这么多,我还真有点割据,究竟如何分辨?
老司机不换岗,新司机就难以找到新工作,实在不行就得改行了,SEO这种类层次的行业好与不好,人各自知,如果你想把这个行业做好,就努力做,认真做。如果不看好就趁早改行,毕竟多数都是从爱好中找到了事业,而不是从伪好中学会了挣钱套路,否则最后还是会害人害己的。
四 : 页面解析之搜索引擎技术的排序算法
联网的出现和迅速发展使信息检索的环境发生了重大变化。而基于互联网的搜索引擎的排名算法直接关系到用户在新的环境里进行信息检索的使用体验。 现有的搜索引擎排名算法,以基于网页链接结构的算法为主,主要的两种代表性算法是PageRank算法和Hits算法,基于这两种算法国内外许多学者和研究机构又进行了新的探索和改进。
在此基础上形成了一些适于搜索引擎使用的成熟的综合排名模型。 本文研究分析了国内外搜索引擎的发展背景,以及对搜索引擎排序有重要影响的SEO技术。在此基础之上,对PageRank算法和Hits算法进行了深入的分析。
一、PageRank
算法PageRank是最著名的搜索引擎Google采用的一种算法策略,是根据每个网页的超级链接信息计算网页的一个权值,用于优化搜索引擎的结果。由拉里-佩奇提出。
简单说,PageRank算法是计算每个网页的综合得分数,即假如网页A链向网页B,则网页B加一分,当然。不同链接网页对于指向网页的加分也是不同的,一个页面的得分情况是由所有链向它的页面的重要性经过递归算法得到的。
PageRank算法的基本原理推导如下:
PR(A) = (1-d) + d*(PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
其中,PR(A)是指网页A的PR值。
T1,T2,...,Tn是指网页A的链入网页。
PR(Ti)是指网页Ti的PR值(i=1,2,...,n)。
C(Ti)是指网页Ti的链出数量(i=1,2,...,n)。
D是一个衰减因子,0<d<1,通常取值为0.85。
从以上公式可以看出,影响一个网页PR值的主要因素如下:
(1)该网页的链入数量。
(2)该网页的链入网页本身的PR值。
(3)该网页的链入网页本身的链出数量。
根据上面分析可以判断:一个网页的链入数量越多,这些链入网页的PR值越高,这些网页本身的链出数量越少,则该网页的PR值越高。
Google给每一个网页都赋予一个初始PR值(1-d),然后利用PageRank算法收敛计算其PR值。
网页的链入链出关系,时刻都在变化,那么PR值也需要更新,可以用定时任务重复计算后更新,使得网页的最终PR值达到一个均衡稳定的状态。
Google的查询过程是这样的:首先根据用户输入的查询关键词对于网页数据库中的网页尽情匹配,然后对于匹配到的网页按照其本身的PR排序呈献给用户。
此外,一个网页在检索结果列表中的位置还与其它很多因素相关,比如检索词在网页中的位置等。
PageRank的缺陷在于不考虑链接的价值,这对通用搜索引擎比较合适,但对主题相关的垂直搜索引擎而言并不是很好的策略。
二、HITS
PageRank算法对于向外链接的权值贡献是平均的,即不考虑不同链接的重要性,但是页面链接中可能某些是广告、导航或者注释链接,平均权值显然不太符合实际情况。
HITS(Hyperlink Induced Topic Search)算法则是一种经典的专题信息提取策略,能够提高垂直查准率。
1、原理
HITS算法由Jon Kleinberg提出,其对每个网页都要计算两个值:权威值(authority)和中心值(hub)。
(1)权威网页
一个网页被多次引用,则它可能是很重要的;一个网页虽然没有被多次引用,但是被重要的网页引用,则它也可能是很重要的;一个网页的重要性被平均的传递到它所引用的网页。这种网页称为权威网页。
(2)Hub网页
提供指向权威网页的链接集合的Web网页,它本身可能并不重要,或者说没几个网页指向它,但是它提供了指向就某个主题而言最为重要的站点的链接集合,这种网页叫做Hub网页。
(3)算法思想
首先利用通用搜索引擎得到一个网页的初始子集I,当然I内的页面都是和用户查询条件有很大相关性。然后把I指向的网页和指向I的网页都包含进来,形成基础集合E,E中的每个页面都具有一个authority权值和hub权值,分别记作a和h,a值表示网页与查询条件相关度的高低,h反应的是该页面链出相关度页面的多少情况。a=(a1, a2, ..., an)和h=(h1, h2, ..., hn)代表E中所有网页的authority和hub向量,初始时把所有的ai和hi都设置为1,然后利用下面的公式进行计算:
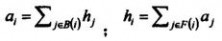
其中,B(i)和F(i)分别表示指向该网页的网页链接集合和该网页指向的网页链接集合。用n*n的矩阵A表示集合E的网页节点间的连接,如果节点i和节点j之间有连接,则A[i,j]=1,则A[i,j]=0,因此,上面公式可以表示为:
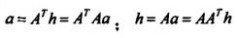
迭代计算a和h,直至收敛。这样我们集中求ATA和AAT。最后按照authority和hub值排序,将a和h值大于阈值M的网页挑出来。
若一个网页由很多好的hub指向,则其权威值会相应增加;若一个网页指向很多好的权威页,则hub值也会相应增加。HITS算法最后输出的一组具有较大hub值的网页和具有较大权威值的网页。
2、缺陷
HITS算法在提高一定的垂直查准率的同时,也存在如下缺陷:
(1)HITS算法忽略了网页内容的差异,对于每个链接网页赋予相同的加权常数,因为每个网页中都会有一些广告链接等非相关的链接网页,这些非相关网页和相关网页同等对待,会容易产生主题漂移现象。
(2)在开始形成url集合E中,对于初始集合I中网页的一些非相关链接也加入到E中,增加了无谓的下载量,也致使后边更多的无关网页参与到了计算,对准确率存在一定的影响。
3、改进
改进方向如下:
(1)主题漂移
(2)下载过滤
以上就是搜索引擎技术之排序算法,虽然公式有点麻烦,但是仔细钻研的话就会有所收获的哦,谢谢大家阅读。
五 : 搜索引擎重复网页发现技术分析
中科院软件所 作者:张俊林l 按照去处重复的级别进行分类,去处重复三个级别:
1. 镜像站点:根据站点内相似页面多少进行判断.实现相对简单.
2. 完全相同网页:实现相对简单并且速度比较块,可以根据页面MD5整个文档来说,每个文档一个HASH编码,然后排序,将相同的找出.
3. 部分相同页面:实现相对负责,目前大多工作在这个部分.
评价:
三个级别应该从最高级别到较低级别分别进行,因为有很大比例(22%)的内容是完全相同的,这个部分实现起来相对简单,而且如果这个部分已经识别,那么针对部分相同页面的计算量会大量减少,这样应该可以减少总体的计算时间..
l 按照去重的时机,可以分为以下三类
(1) 抓取页面的时候去重,这样可以减少带宽以及减少存储数量;
(2) 索引之后进行去重;
(3) 用户检索时候进行再次去重;增加准确性,耗费时间;
评价:
可以结合三个时机某个或者所有都结合,对于GOOGLE来说,很可能是结合了2和3两种方法, GOOGLE的很多思路建立在后台计算和实时计算联合,比如相关度计算,后台计算重要性得分,在用户输入查询后得到初始数据集合,然后根据这个数据集合之间文档的关系重新调整顺序;比如去处重复,首先在后台进行重复发现,为了增加精确度,在返回查询结果后,在返回文档集合内,又根据“描述”部分重新计算哪些文档是重复的,这样增加了准确性,估计其它很多相关算法也采取这种联合策略,为了加快速度,实时计算部分可以和CACHE部分结合进行计算。
l 按照不同的特征选择方法,有几种方式:
1. 完全保留特征
2. 特征选择,设置不同的选择策略来保留部分特征,抛弃其它特征
a. 比如对于单词级别的抛弃权重小的单词(I-MATCH)
b. 对于SHINGLE方法,可以保留部分SHINGLE抛弃其它SHINGLE
(1) 一种是保留FINGERPRINT第I个位置为0的SHINGLE,其它抛弃;
(2) 一种是每隔I个SHINGLE进行抽样保留,其它抛弃;这两种得到的文档SHINGLE数目是变长的;
(3) 一种是选择最小的K个SHINGLE,这种得到定长的SHINGLE数目;
(4) 用84个RABIN FINGERPRINT函数对于每个SHINGLE进行计算,保留数值最小的84个FINGERPRINT,这个方法是定长的.
对于SHINGLE类方法来说,还可以区分为:定长的和变长的block切分算法
定长算法:速度快,但是如果内容有稍微变化(比如插入或者删除一个字符或者单词),其影响会比较大。比如Shingle及其改进方法(Super-Shingle),CSC及其改进方法(CSC-SS)。
变长算法:速度相对慢,但是内容变化只是造成局部影响。比如CDC,TTTD等算法。
评价: 为了提高计算速度,一种策略是在特征提取的时候,抛弃部分特征,保留部分特征,通过减少特征数目来加快计算速度.另外一个策略是粒度尽可能加大,比如SUPER-SHINGLE,MEGA-SHINGLE甚至是文档基本;为了提高算法效果,策略是采取变长的内容切割算法比如CSC算法等;这三种策略是方法加快速度和准确性的发展方向.
一些初步的结论:
1. 对于信息检索类型的方法来说,由于其特征选择是基于单词的,所以计算速度是个根本的问题,所以基本上是不实用的;
2. 从利用的信息来看,实用的系统还是应该立足于只是利用文本内容来判别相似性,排除掉利用链接信息等方法;
3. 从算法特征抽取粒度来看,应该立足于SHINLGE类的粒度甚至是文档级别的粒度算法;而SHINGLE类别的算法又应该优先选择抛弃部分特征的算法以及变长的算法;
4. 从去重级别角度考虑,应该将完全相同的文档和部分相同的文档识别分开进行,而且首先进行完全相同文档的识别,这样会有效加快计算速度;
5. 从去重时机考虑,可以考虑结合后台去重以及实时去重,这样增加去重的效果;
6. 从压缩编码方法来看,最有效的方式可能是RABIN FINGERPRINT变体算法;
7. 从聚类方法来看,最有效的方式可能是UNION FIND算法,目前比较快的算法基本上都采用这个方法;
8. 从整体方法选择来看,应该选择改进的SHINLGE方法,在此基础上进行进一步的改进;
三. 方法效率比较
1. SHINGLING 方法:时间效率O((mn)2) ,其中 m是SHINGLE的大小,n是文档数目.计算时间为:3千万文档,10台机器算一天,或者一台机器算10天;
2. 改进的SHINGLE方法(On the Evolution of Clusters of Near-Duplicate Web Pages.):时间效率接近于线性的O(n),计算时间为:1亿5千万网页计算3个小时;
3. IMACH方法: 最坏的情况下时间复杂度是(O(d log d)),速度比较快
4. BLOOM FILTER方法:10k数据花费大约66ms;
从计算效率考虑,速度排序为:
1. 改进的SHINGLE方法;
2. IMATCH方法;
3. BLOOM FILTER方法;
4. SHINGLE方法;
四. 目前代表性解决方法分析
1. Shingle方法(1997年)
a. 特征抽取
Shingle方法:所谓Shingle类似于自然语言处理中常用的N-GRAM方法,就是将相互连续出现窗口大小为N的单词串作为一个Shingle,两者的不同点在于Shingle是这些串的集合,相同的串会合并为一个,而N-GRAM则由于考虑的是文本线性结构,所以没有相同合并步骤.每个Shingle就是文档的一个特征,一篇文档就是由所有这些Shingle构成的.
b. 压缩编码
40 bit长度 Rabin FingerPrint方法;至于存储方式则类似于传统信息检索领域的倒排文档技术,存储<Shingle,ID>信息以记录某个特征在哪些文档中出现过,然后进一步计算文档的相似性;
c. 文档相似度计算
(1) 相似度:任意两个文档A和B,相似度指的是两者相同的Shingle数目占两者Shingle数目总和的比例;
(2) 包含度:指的是两者相同的Shingle数目占某篇文档Shingle数目的比例;
d. 优化措施:
(1) 分布计算然后合并;
(2) 抛弃超高频出现Shingle,分析发现这些Shingle是无意义的片断;
(3) 完全相同文档保留一份进行聚类;(文档是否完全相同根据压缩编码后数值是否相同判断)
(4) Super Shingle:关于Shingle的Shingle,从更大结构上计算相似性以节省存储空间;
2. Google可能采取的方法
a. 特征抽取
类似于Shingle方法,不同点在于:对于每个单词根据HASH函数决定属于哪个LIST,这样每个文档由若干个这样的LIST构成;
b. 压缩编码
FingerPrint方法;对于组成文档的LIST进行FingerPrint方法计算;
c. 文档相似度计算
编辑距离(Edit Distance):如果两个文档有任何一个FingerPrint相似就判断为内容接近.
d. 聚类方法
首先对<FingerPrint,Doc ID>按照Doc ID进行排序;然后采取Union Find聚类方法,聚类结果就是相似文档集合;
e. 优化措施
3. HP实验室方法(2005年)
a. 特征抽取
基于内容的Chunk方法:变长而非定长的Chunk算法(TTTD算法);将一篇文档分解为若干个长度不同的Chunk,每个Chunk作为文本的一个特征.与shingle方法相比这种变长Chunk方法能够增加系统招回率;
b. 压缩编码
128bit MD5 HASH方法;每篇文章压缩编码后由若干 <Chunk 长度, 定长HASH编码>二元组构成;
c. 文档相似度计算
(1) 构建所有文档和Chunk构成的二分图;
(2) 找到文档A包含的所有CHUNK,计算这些CHUNK还被哪些其它文档包含;
(3) 计算这些文档和A的相似性;
d. 聚类方法:Union Find 算法
e. 优化措施:Bipartite 划分,本质上是将大规模数据分成小规模数据进行识别然后再合并结果.相当于分布计算;
4.bloom filter(2005年)
(1).特征抽取方法
基于内容的语块(Content-defined chunking CDC):CDC将文档切分为变长的内容片断,切分边界由rabin fringerprint和预先制定的maker数值匹配来进行判断。
(2)编码(构造 bloom filter集合元素)
对于切分的片断进行编码。bloom filter的编码方式如下:整个文档是由片断构成的,文档由长为m的二值数组表示。在将一个元素(内容片断)进行编码插入集合的时候,利用k个不同的hash函数进行编码,每个hash函数设置m个位置的某个位置为1。这种技术以前主要用来进行判断某个元素是否被集合包含。
(3)相似度计算方法
bloom filter方法:对于两个已经编码的文档(两个长度为m的二值数组),通过bit逻辑运算AND计算,如果两者很多位置都同时为1,那么两个文档被认为是近似的。
(4)优势
1.文档编码形式简洁,便于存储。
2.由于计算相似性是BIT逻辑运算,所以速度快。
3.相对Shingling 方式来说便于判断文档包含关系。(某个文档包含另外一个短小的文档)
5.内容+链接关系(2003年)
1.特征抽取方法
这个方法在抽取特征的时候同时考虑了文档的内容因素以及链接关系因素。
内容因素:通过Random Projection技术将文档内容从高维空间映射到低维空间,并且由实数表示,如果两个文档映射后的数字越接近则表明两者内容越相似。
链接因素:通过考虑类似于PAGERANK的连接关系,将某个网页的内容因素计算获得的分值通过链接传播到其他网页(传播关系见下列公式),多次叠代计算后得到每个页面的链接得分。
2.相似度计算方法
每个文档由二元组<RP,HM>构成,RP代表内容部分的数值,HM代表链接关系代表的数值。如果两个文档每个项之间的差值都小于指定值,则判断两个文档是相似的。
3.效果
只采取内容精度达到90%,两者结合精度达到93%。从中看出,链接的作用并不明显。这可能跟这个方法的链接使用方法有关,因为通过链接计算的还是内容的情况。
6.I-Match方法(2002年)
(1)I-Match不依赖于完全的信息分析,而是使用数据集合的统计特征来抽取文档的主要特征,将非主要特征抛弃。输入一篇文档,根据词汇的IDF值过滤出一些关键特征,并且计算出这篇文档的唯一的Hash值,那些Hash值相同的文档就是重复的。
(2)使用SHA1作为Hash函数,因为它的速度很快而且适用于任何长度。SHA-1生成一个20-byte 或者160-bit 的hash值并且使用一个安全的冲突消解算法,使得不同的标志串(token streams)生成相同的hash值的概率非常低。.把<docid, hashvalue>元组插入树结构的时间复杂度是(O(d log d)),其他的如检索数据结构(hash表)需要(O(d))。对重复(duplicate)的识别是在将数据插入hash数组或是树结构中进行的,任何的hash值的冲突就表示检测到一个重复内容。
(3)最坏的情况下时间复杂度是(O(d log d)),速度比较快。
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1