一 : 超级计算机“天河一号”的使用介绍
“天河一号”超级计算机从2008年开始研制,按两期工程实施。下面是小编整理的关于超级计算机“天河一号”的使用介绍,欢迎大家参考!
主 题:超级计算机“天河一号”的使用介绍
主讲人:国家超级计算长沙中心应用工程师 冷灿
时 间:2016年11月17日下午2:30
地 点:老T4(第五教学楼东头梯形教室)
内 容:本着资源共享、合作共建的原则,湖南农业大学和国家超级计算长沙中心携手成立了全国第一家国家超级计算高校分中心,面向全校所有有高性能计算需求的院系、科研平台、实验室、教师、学生提供高性能计算服务。高性能计算所涉及的科研和教学领域主要有:粮油作物种植信息处理、农业信息化数据处理、作物生长数值模拟、大规模分子动力学数值模拟、基因表达谱数据分析、大规模CAD设计、生物信息学中蛋白质结构和相互作用预测、环境遥感数据处理等。
。www.61k.com)
培训具体内容包括:
1、系统平台架构
2、系统编译环境
3、系统登陆
4、作业管理
5、部署软件介绍
6、软件编译与测试
7、常见问题
主办单位:湖南农业大学信息化建设与管理中心
湖南农业大学科学技术处
湖南农业大学研究生院
湖南农业大学信息科学技术学院
“天河一号”满负荷运行
张婷表示,“天河一号”目前已经处于一个满负荷,甚至是超负荷运行的状态,每天在线运行任务超过1400多项,这是欧美国家级超算中心都很难达到的一个业务规模。
“截至目前,天津超算中心已经给全国100多家重要企业提供服务或是形成了深入的合作,已经阶段性地实现节省企业研发投入上亿元,为企业带来相关经济效益超过20亿元。”她说。
2010年,“天河一号”落户天津滨海新区的国家超级计算天津中心,面向国内外提供石油勘探、高端装备制造、生物医药、动漫设计、新能源、新材料等领域的超级计算服务。
张婷还透露,为了满足企业对云计算服务的需求,2016年,天津超算中心将搭建一批万核的服务平台,同时与国防科技大学联合研发纯自主试验机。
国家超级计算天津中心是由国家科技部于2009年5月批准成立的第一家超算中心,由天津滨海新区和国防科技大学共同建设。
天津超算中心坐落在天津经济技术开发区(泰达)外包服务园5号楼,占用房屋面积约8,500平方米,共建有2个大型机房共约4,000平米,其中一个机房用于安放“天河一号”超级计算机,第二个机房用于云计算和系统扩充。另外建有变电站、制冷站,变电站供电能力为13,600KVA,制冷站供冷能力为9,600KW,具有较强的配套保障能力。
天津超算中心的主业务计算机是 “天河一号”超级计算机,是由科技部863计划“高效能计算机及网格服务环境”重大项目支持,由国防科技大学与滨海新区于2009年9月联合研制成功第一期系统;后经采用自主CPU和自主的高速互联通信系统,以及全面优化,于2010年10月,研制完成了“天河一号”二期系统。“天河一号”超级计算机在2010年11月世界超级计算机Top 500排名中荣获世界第一。
天津超算中心高性能计算的主要应用领域包括:生物医药、石油地震勘探数据处理、动漫与影视渲染、新材料新能源、高端装备设计与仿真、航空航天、流体力学、天气预报、气候预测、海洋环境模拟分析等等。
深圳国家超级计算机中心
2009年5月批准成立,2011年6月安装调试,同年11月,超算中心投入运行启动仪式;2012年6月,正式向社会提供高性能计算业务的商业服务;截止至2014年5月,计算资源使用率已超过55%,高性能计算用户达到1,056个,云计算个人用户超过1,750,000人,机构达到13,221家。
国家超级计算深圳中心(深圳云计算中心)是国家在深圳布局建设、深圳建市以来单个投资额最大的重大科技基础项目。该项目是国家863计划,广东省和深圳市重大项目,同时也是深圳落实《珠江三角洲改革发展规划纲要(2008-2020)》和《深圳市综合配套改革方案》的具体行动。
国家超级计算深圳中心(深圳云计算中心)主机系统于2010年5月经世界超级计算组织实测确认,运算速度达每秒1,271万亿次,排名世界第二。同时配备高达17.2PB的海量存储及来源于各大运营商、教育网的丰富网络带宽资源。
国家超级计算深圳中心(深圳云计算中心)立足深圳、面向全国、服务华南、港、澳、台及东南亚地区,开展各种大规模科学计算和工程仿真、动漫渲染等计算业务,同时以其强大的数据处理和存储能力为社会提供云计算服务,将建成功能齐全、平台丰富、高效节能、国际一流的高性能计算研究开发中心和云计算服务中心。
长沙国家超级计算机中心
国家超级计算长沙中心2011年试运行,2014年11月4日,揭牌正式运营。继天津和深圳之后获批建设的第三家国家级超级计算中心。与国内其他超级计算中心不同的是,长沙超算中心完全依托高校运营。
选址:湖南大学校区内,采用国防科技大学“天河一号”高性能计算机,按每秒1000万亿次运算能力规划建设,总投资7.2亿元。国家超级计算长沙中心一期工程规划建筑面积30000平方米,计划于2011年底全部建成竣工,建成后运算能力将达每秒300万亿次,由湖南大学负责运营,国防科技大学提供计算设备和技术支持,坚持公益性与经营性相结合原则,为社会和公众提供高性能计算应用服务。
该中心自2011年试运行以来,已为气象、国土、水利、卫生/医疗、交通等公共服务部门提供了高性能的计算平台服务。该中心与国内高性能计算、云计算和动漫渲染领域机构建立了战略合作关系,已在省内外一些大型企业平台进行试用,正式运营后,将面向全国装备制造企业提供大规模仿真设计公共服务。
于2010年11月奠基开工,按照“政府主导、军地合作、省校共建、市场运作”的模式积极推进项目建设。项目主机设备于2011年6月在国防科大全面上网试运行,项目主体建筑工程于2013年7月竣工一次验收合格,同时,主机设备从国防科大搬迁至湖南大学新址,并完成安装调试,已具备了正式启动运营的基本条件。
超级计算机“天河一号”的使用介绍

二 : 这就是“天河一号”超级计算机,太霸气了
运算1小时,相当于13亿人同时计算340年;运算1天,相当于1台双核的高档桌面电脑运算620年——这是中国首台千万亿次超级计算机“天河一号”的管理者和运营者刘光明给该计算机做的形象比喻。(www.61k.com)

作为位于天津市滨海新区的国家超级计算天津中心主任的刘光明,其职业生涯与中国超级计算机发展史几乎“同龄”,曾参与我国银河-2、银河-3、“天河一号”的研制的他,见证了中国超级计算机20多年的跨越式发展。
2010年11月,中国首台千万亿次超级计算机“天河一号”横空出世,以每秒4700万亿次的峰值性能获得世界超级计算机排名第一的殊荣。
投入约4亿人民币的“天河一号”,在引领当前国际超级计算机技术发展的异构体系结构、自主高速互连通信技术、高安全等级的麒麟操作系统等技术领域获得重大技术突破,成为全球“性价比”最高的冠军计算机,构建起了中国多个产业领域的核心竞争力。
在日前的采访中,刘光明告诉记者,在经济建设领域,超算技术滞后带来重大影响的首先是石油勘探领域。
上世纪80年代中叶,靠严密计算方法确定地下油藏的技术在国际已经趋向成熟,但中国还没有实现相关技术突破,向国外购买超级计算机和石油勘探处理软件不仅价格昂贵,而且受到种种限制。
作为“国之重器”,“天河一号”的问世极大地满足了中国产业升级的需要。国家超算天津中心与中石油东方地球物理公司合作,运行的中国自主研发的石油地震勘探数据分析软件,将地下成像速度由过去的3天提高到1天。
通过自主的“天河一号”和自主的核心软件,中国石油勘探数据处理水平进入了世界先进行列,实现了石油数据处理技术的重大突围。
“普通工作站模拟一个汽车侧围,需要约160小时,而我们借助‘天河一号’进行超级计算处理后,用时缩减至10个小时以内。”天津汽车模具研究院副院长常青说,目前,天津汽车模具公司生产的设备已广泛应用于福特、路虎、奔驰等品牌汽车的生产上,“天河一号”给他们带来的利润每年接近1亿元人民币。
“天河一号”还吸引了国际客户的目光。欧盟第七框架科研计划与“天河一号”合作项目已经完成。
中欧项目顾问、德国于利希超级计算中心教授BerndMohr表示,中国在超级计算机领域经验丰富,欧盟希望通过这一合作,对未来高性能计算发展规划提供指导和参考。
“中国超算跻身国际领先水平的这一刻,中国人已经等了20多年。”据刘光明介绍,为促进产业技术创新和战略性新兴产业发展,天津中心成立了“大数据处理与应用国家地方联合工程实验室”,重点建设了滨海工业云、文化创意云、智慧城市BIM+GIS云、互联网个人健康与医疗云、互联网金融产业服务和智能交通云等多个“云平台”。
目前,“天河一号”每天运行的计算任务超过1000个,服务的科研团队超过600家。
天河一号正满负荷运行,为国家的科技创新服务,为国家的战略性新兴产业发展服务。
三 : 透过天河一号看超级计算机技术
2010-03-01 21:08:40 技术 | 评论(0) | 浏览(1899)
在去年10月底,长沙举办的中国高性能计算学术年会上,国防科技大学研制的千万亿次超级计算机“天河一号”成为焦点,这是我国国内计算能力最高的超级计算机,而且标志着我国超级计算机的研发能力成功实现了千万亿次计算的跨越。超级计算机不仅体现了一个国家战略性高技术的发展水平,也是与科技创新、国计民生密切相关的重要基础设施。超级计算机的各种应用,实际上会以不同的方式影响到我们每个人,这些似乎遥不可及的超级计算机实际上离我们“非常近”。 你应该知道的超级计算机
目前各种超级计算机的高速处理能力基本上都是利用并行体系结构实现的,并行计算(Parallel Computing)已成为提高处理性能的关键技术之一。简单地讲,并行计算技术就是用同时运行的多个处理机或计算机来处理同一任务,从而大幅度提高任务的处理速度、缩短了任务的处理时间。
超级计算机的五大形态
在超级计算机技术的发展历程中,先后出现过多种超级计算机并行体系结构,主要有如下5种。
●并行向量处理(Parallel Vector Processing,PVP)系统
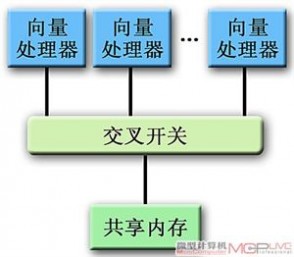
并行向量处理结构
采用一定数量的、并行运行的向量处理器和共享式内存(Shared Memory,SM)结构的计算机系统。PVP系统的SM结构,也就是采用高带宽的交叉开关将各个向量处理器与其共享的内存模块连接。向量处理器(Vector Processor)的一条指令能够同时对多个数据项(向量矩阵)执行运算,而一般的通用CPU属于标量处理器(Scalar Processor),每次只能对一个数据项进行处理。其代表机型有Cray XMP、Cray YNP、NEC SX2、我国的银河一号和二号等。
●对称式多处理(Symmetric Multi Processing,SMP)系统
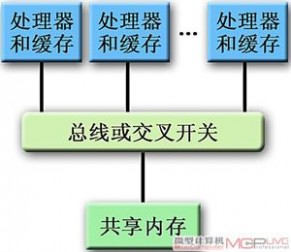
对称式多处理结构
采用一定数量、并行运行的微处理器和共享式内存(SM)结构的计算机系统,各处理器通过系统总线或交叉开关连接共享的内存模块,可“均等”或“对称”地共享内存和其它系统资源并由同一操作系统管理,提高整个系统的数据处理能力,因此SMP属于“一致性内存访问”(Uniform Memory Access,UMA)方式,SMP的代表机型有IBM R50、SGI Power Challenge、Sun SPARC Center 2000、曙光一号等。
●分布式共享内存(DistributedShared Memory,DSM)系统
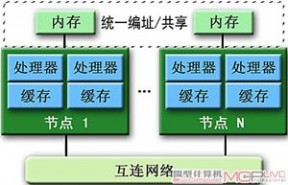
分布式共享内存结构
由一定数量的并行处理节点(Node)组成,每个节点都是一个相对完整的计算单元(配置有处理器和内存模块),各节点通过高速网络互连,系统由单一操作系统管理,分布于各个节点的全部内存被统一编址,可由所有用户共享。与SMP不同,DSM对内存资源的共享是非对称的,因为每个节点访问本地内存与远程节点内存时的延迟和带宽是不同的,故DSM系统属于“非一致性内存访问”(Non-Uniform Memory Access,NUMA)方式,其代表机型有SGI Origin 2000/3000、Sequent NUMA-Q、HP/Convex SPP 1600、银河三号和神威一号等。
●大规模并行处理(Massive Parallel Processing,MPP)系统
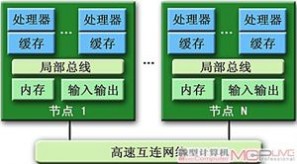
大规模并行处理结构
由成百上千计算节点组成的并行处理计算机系统,每个计算节点配置一个或多个处理器,各个节点相对独立,有各自独立的内存模块和操作系统。MPP系统的特点是可以获得很高的峰值运算速度,且由于系统的内存分布于各个节点,所以MPP属于“分布式内存”(Distributed Memory,DM)结构,具有易扩展性。MPP的易扩展性使其能够与SMP、DSM等结合,于是出现了SMP-MPP(各个MPP节点采用SMP并行多处理机)和DSMMPP(各个节点采用DSM并行多处理机)等复合型超级计算机系统。MPP系统的代表机型主要有IBM SP2、Intel Paragon、CRAY T3E、曙光1000等。
●机群式超级计算机系统
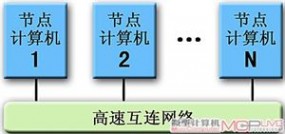
机群式超级计算机结构
上世纪90年代中后期,随着Intel芯片等造价低廉的微型计算机组件的出现和网络技术的迅速发展,使采用普通微型机或工作站作为计算节点并采用高速网络互连的并行计算系统成为了可能,超级计算机体系结构由此开始迈入工作站机群(Cluster of Workstations,COW)或工作站网络(Network of Workstations,NOW)时代。2000年以后,又出现了节点采用商用级处理器的机群系统(Cluster),以及采用SMP并行机作为计算节点的SMP机群或星群(Constellation)。从内存访问方式上看, 机群系统采用了与MPP相同的分布式内存(DM)结构,因而具有很高的可扩展性。机群系统的代表机型有洛斯阿拉莫斯国家实验室的Avalon Cluster、ASCI Blue Mountain、深腾1800/6800和曙光2000/3000等。
当今主流:机群式超级计算机概况
机群式超级计算机系统具有结构灵活、通用性强、安全性高、易于扩展、高可用性和高性价比等诸多优点,所以目前新建的超级计算机大都使用这种结构,只不过在具体采用的节点机型、拓扑结构及互连技术会有所不同。
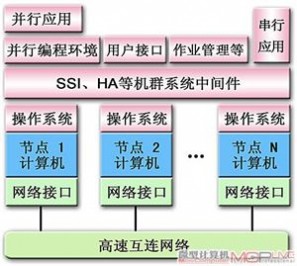
机群式系统的基本组成
高性能计算专业网站TOP500的全球超级计算机500强排名中,机群式系统所占比率连年上升,现已达到83%以上。机群是采用高速网络将大量的节点相互连接起来的系统,每个机群节点都是一个配置有处理器、内存、I/O设备、网卡和操作系统的计算机,各个节点以协同方式并行完成计算任务。机群系统与MPP一样,也是属于分布式内存结构,因而具有很强的可扩展性。具体而言,机群系统主要由节点计算机、高速互连网络、操作系统、单一系统映像等中间件、并行编程环境和应用程序等部分组成。
●机群节点的计算机
机群节点可以灵活采用高性能的微型机、工作站或SMP并行机等,节点机处理器的处理性能是影响机群系统整体性能的一个最关键的因素。理论上节点机处理器的主频和浮点运算速度是决定机群计算速度的主要因素(见后面介绍的峰值速度计算公式)。
由于图形加速处理器(GPU)具有很强的浮点和向量(矩阵数组)计算能力,所以在机群中采用一定数量以GPU作为处理器的计算加速节点,将能提升机群的性能,例如“天河一号”就采用GPU加速节点并提升了GPU的计算效率,实现了CPU与GPU融合的异构协同计算。
●机群的互联技术
机群系统一般可以采用高带宽的以太网、异步传输模式(ATM)、可扩展一致性接口(SCI)、QsNet、Myrinet和InfiniBand等网络技术实现节点机的互连,其中千兆/万兆级以太网、Myrinet和InfiniBand使用比较广泛,尤其是后者InfiniBand互连技术也被称为“无限带宽”InfiniBand最初由Mellanox公司提出,是一种基于输入输出总线的通用宽带互连技术,原本是为了解决因PCI等并行总线结构速度较慢而导致的服务器CPU输入输出瓶颈问题,这种瓶颈制约了服务器与存储设备、网络节点、其它服务器之间的通信能力,但由于InfiniBand非常适合于高性能计算系统,所以后来便成为一种广泛应用于超级计算机系统的开放性高速互连网络技术标准。
InfiniBand规范中定义了交换机、通道适配卡、线缆和子网管理器等标准设备,InfiniBand交换机在各个节点、各种设备之间建立点对点的串行连接并进行流量控制,可有效避免数据流量的阻塞。基于交换方式的点对点的串行连接使InfiniBand网络具有极强的可扩展性,一个网络可有数千个子网(Subnet)组成,每个子网有一个子网管理器、可支持上万个节点,这种子网架构实现了更有效的分散管理。
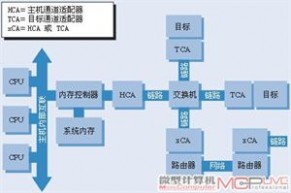
InfiniBand体系架构模型
InfiniBand采用串行双向数据传输方式,利用多路复用信号传输技术可实现并发的多通道数据传送,单个InfiniBand连接通道的线缆由4根信号线组成、可达2.5GB/s的基本传输速率,通过增加信号线数目并将多个通道组合成一个端口,就能使传输带宽成倍增加,最新的4倍数据率(QDR)InfiniBand已达到了10Gb/s的通道基本传输率,在1、4、12倍通道连接模式可使传输带宽分别达到10Gb/s、40Gb/s、120Gb/s的传输带宽。目前,InfiniBand在超级计算机的应用日益广泛,例如2009 China HPC TOP 10排名中有5套超级计算机都采用了InfiniBand互连技术,包括排名前2位的“天河一号”和“曙光5000A”。
机群的软件系统
超级计算机除了具备非常强大的计算能力,对操作系统以及软件的要求也比较高。
●节点机操作系统
操作系统为机群提供支持环境,决定了节点机之间的交互方式,应具备较强的适应性和稳定性,机群采用的操作系统主要有Linux、Sun Solaris UNIX和Windows NT等。其中,Linux因具有支持多种硬件平台、对系统资源的低占用率、开放代码、高安全性、稳定性和可靠性等诸多优点,特别是Linux提供了大量节点并行计算系统所需的标准消息传递机制(如后面介绍的MPI等)和高性能网络支持,使其在越来越多的机群系统中被广为采用。
●SSI和HA等中间件
机群系统是由大量节点计算机组成的并行处理系统,但从机群用户和程序员的角度而言,最好能使结构复杂的机群像一台计算机一样便于使用和管理,具有单机式的管理控制、单一的地址空间和单一的文件系统等特性,以有效降低用户操作和程序员编程的复杂度,即具有“单一系统映像”(Single System Image,SSI)特性。
SSI由相应的机群中间件实现,所谓的机群中间件(Middleware)是指在上层连接各个节点机的操作系统、实现对机群系统资源和网络通信等进行有效控制和管理的软件系统或服务程序, 并且能提供便于用户管理和配置系统的图形化操作界面的接口。除了SSI之外,机群一般还有“高可用性”(High Availability,HA)管理等中间件,HA用来快速检测和排除机群系统的故障点,以确保系统能可靠地连续运行。
●并行编程环境
适用于机群、MPP等分布式内存结构的并行编程环境,通常可由“并行虚拟机”(Parallel Virtual Machine,PVM)或“消息传递接口”(Message Passing Interface,MPI)等来实现。利用PVM工具,可以把互连的各种计算机虚拟为一台并行机,从而为编程人员提供了一个便于管理和使用的编程环境,而由PVM的编译库对程序进行转换,将程序的计算任务分解为若干子任务后合理分配到各个节点机进行并行处理。MPI是一种基于消息传递的并行计算规范,消息(Message)一般包括数据、指令或其它各种控制信号等,MPI提供了一套消息传递库,基于消息传递的并行编程实际上就是通过调用MPI的消息传递库函数实现节点机之间的数据交换,并提供并行处理任务之间的同步等。目前,基于PVM和MPI并行编程环境,都可以支持C、C++和FORTRAN等的并行编程。
衡量机群的计算性能的指标
机群系统的主要性能指标有峰值速度、实测速度和运行效率等,计算速度一般以计算机系统“每秒执行的浮点运算次数”(Float ingpoint Operations Per Second,Flops)为单位,并定义了扩展单位MFlops(百万次浮点运算每秒)、GFlops(十亿次浮点运算每秒)、TFlops(万亿次浮点运算每秒)和PFlops(千万亿次浮点运算每秒)等。
●峰值速度
峰值速度通过计算得出,故也称理论峰值速度, 其计算公式为【理论峰值速度(亿次)=节点机每个CPU主频(MHz)×CPU每个时钟周期执行浮点运算的次数×CPU总数目/108】。例如,“天河一号”的峰值速度为1206万亿次每秒(TFlops)或1.206千万亿次每秒(PFlops)。
●实测速度
用评测软件对机群系统计算速度的实际测试值,目前国际上通用的超级计算机或高性能计算机评测软件是《Linpack》——这是一套采用求解线性方程组和特征值问题的方法来综合评价超级计算机浮点运算性能的基准测试软件。实测速度能更客观地反映系统的实际计算性能,对用户而言,实测速度比峰值速度更有意义。
●运行效率
一般是指超级计算机实测速度与峰值速度的比率。运行效率越高,表明系统具有的处理资源等经过合理的系统设计得到了更有效的发挥。相对于由处理器数量和性能决定的理论峰值速度而言,运行效率显然是一个能够更全面、科学地反映超级计算机性能和技术先进性的指标。
试试看,构建一个低成本的小型机群系统!
利用低成本的普通微机组建的机群系统在很多实验室、高校和研究机构都发挥了作用,例如非常著名的贝奥武夫(Beowulf)机群(1994年由美国洛斯阿拉莫斯国家实验室搭建)。只要有一定数量的微机和适当的网络设备,人们都可以组建自己的机群系统或“超级计算机”,去完成一些任务量较大的数值处理或科学计算等方面的工作。
●硬件环境和组网
用来组建机群的微机配置和数量可根据具体情况选择,节点机的互连可采用易于实现的100M以太网。例如,为了降低成本可使用10台被闲置的计算机作为节点机,将各个节点机与100M以太网交换机连接组网并确认网络通信正常。
●软件配置和安装
节点机操作系统一般采用Linux,例如Red Hat Linux。机群软件系统的安装和配置可使用OSCAR、xCAT、Rocks、Clusterworx、SystemImager或Warewulf等集成化的Linux机群构建和管理工具包来完成。例如,基于Linux环境的OSCAR(Open Source Cluster Application Resources)就是集成有机群系统安装和设置、管理和并行编程环境等完整工具的软件包,且采用图形化安装向导,能一步步提示用户轻松地完成机群系统的安装配置和管理维护。
基于OSCAR的机群节点机中一台作为系统服务器(OSCAR Server),其余节点机都是用于并行计算的客户机(OSCAR Client)。安装基本步骤为:在选择作为OSCAR服务器的那台节点机上安装Red Hat Linux、配置和启动X-Window,然后安装和运行OSCAR,按照OSCAR安装界面上的提示依次进行“安装服务器”(Install OSCAR Server Packages)、“创建客户机映像”(Build OSCAR Client Image)、“定义和安装客户机”(Define OSCAR Clients)、“设置网络”(Setup Networking)和“完成机群设置”(Complete Cluster Setup)等步骤即可完成机群的安装和设置,之后可用“测试机群设置”(Test Cluster Setup)对安装好的机群进行测试。 超级计算机与大家广泛使用的微型计算机或个人电脑(PC)在系统规模和体系结构、性能和用途、硬件和软件、造价和耗电量都迥然不同。超级计算机一般由成百上千的处理器或处理机组成,可以协同有效地并行完成计算任务,因而具有超快的运算速度,能完成普通微型机很难承担的、极为复杂的大规模计算任务。有一个形象的比喻:如果把微型计算机的运算速度比作人的步行速度,则超级计算机的运算速度就可以比作火箭的飞行速度。
不过,超级计算机与普通计算机的发展之间也并非完全隔离的。一方面,普通的微型计算机等可以被用作超级计算机的节点机;另一方面,超级计算机的一些技术理念也被应用到了微型机,例如多核CPU、支持CUDA的GPU在技术上就分别与超级计算机的多处理器并行计算、向量处理类似。下面,我们可以从“天河一号”的一些数字来进一步体验超级计算机与微型计算机的差别。
“天河一号”超级计算机采用了多阵列、可配置、协同并行体系结构,系统由计算阵列、加速阵列和服务阵列组成,其中计算阵列、服务阵列分别由采用通用处理器(CPU)的计算节点机、服务节点机构成,加速阵列则由基于图形加速处理器(GPU)的大量加速节点机构成,实现了“CPU+GPU”的异构协同计算,提高了计算效能。此外,“天河一号”采用了便于维护和高密度的刀片式(Blade)结构,每个机位都有几十个可热插拔的刀片,每个“刀片”实际上就相当于一块计算机主板,组成一台配置有处理器、内存等模块的节点计算机。
“天河一号”的硬件与软件系统有啥不同?
“天河一号”的硬件系统由计算阵列、加速阵列、服务阵列、互连通信子系统、I/O存储子系统和监控诊断子系统等组成示。计算阵列有2560个计算节点,每个计算节点配置2个Intel处理器(Xeon E5540 2.53GHz)和32GB内存;加速阵列有2560个加速节点,每个加速节点配置2个AMD图形加速处理器(ATI Radeon HD 4870 575MHz)和2GB显存;服务阵列有512个服务节点,每个服务节点配置2个Intel处理器(Xeon E5450 3.0GHz)和32GB内存。

零售市场上的Radeon HD 4870
在硬件配置上我们可以发现Radeon HD 4870显卡的频率要低于市售产品,这是考虑到巨型计算机特殊的要求,既要追求浮点运算能力,也要同时考虑功耗的问题。很多人会觉得为什么需要如此之多的显卡GPU呢?这是因为在并行计算中,显卡GPU可以提供数倍于CPU的计算能力,以Radeon HD 4870显卡为例,其理论浮点运算能力就达到了1.2TFlops,是同时期CPU的的14倍。

天河一号的主板与显卡
“天河一号”系统共有6144个通用处理器(CPU)和5120个图形加速处理器(GPU)、内存总容量达98TB、峰值速度达1206 TFlops,Linpack实测性能为563.1TFlops,而配置双核处理器的普通微型计算机运算性能只有大约百亿次每秒。按照这样的速度对比,“天河一号”1天的计算任务量, 若由一台微型计算机来执行,大约需要连续计算160年才能完成。

“天河一号”的硬件系统
“天河一号”的I/O存储子系统采用全局分布共享并行I/O系统结构,磁盘总容量为1PB,相当于能够存储10800万册10MB的数字图书;系统的互连系统采用两级QDR InfiniBand架构,每个通信链路的带宽为40Gbps;“天河一号”的监控诊断子系统采用分布式集中管理架构,具有实时的系统监测、调控和诊断等功能。“天河一号”由103台机柜组成,总重量约155吨、占地面积近千平方米,每小时耗电1280度,投入研发的资金约6亿元。
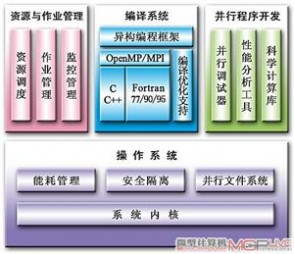
“天河一号”的软件系统
“天河一号”的软件系统包括操作系统、编译系统、资源管理系统和并行程序开发环境等。操作系统采用面向高性能并行计算的64位Linux,支持功耗管理、虚拟化和安全隔离等;编译系统支持C、C++、Fortran和Java等的并行编程,并提供了异构协同编程框架以有效发挥CPU与GPU的协同计算能力;资源管理系统可提供整个系统的资源统一视图,能实现多策略资源分配与作业调度,有效提高资源利用率和系统吞吐率。 级计算机都有哪些用武之地?
从世界的范围来看,超级计算机的应用目前几乎已涉及科学技术、工业设计、金融和经济管理以及军事国防等相关的各种领域,例如与人们生活密切相关的天气预报和气候模拟、地震预报和监测等方面的应用,还有环境监测和分析、石油等自然资源的勘探,生物及医学领域的基因与遗传工程、药物研制、医学影像的分析处理,航空航天领域的飞行器设计,军事武器的研制和模拟试验,还有基础科学研究等领域的大规模数值计算。除了具有超强大的科学计算能力之外,超级计算机具有高效的信息服务和事务处理能力,因此也可以用作信息服务、事务处理与决策支持等系统的高性能服务器。
●天气预报
目前的中短期天气预报主要是根据气象卫星等观测的大气实况资料,通过求解描述天气演变过程的动力学方程组实现的,这种大规模的数值计算必须由超级计算机完成。例如,在2008年北京奥运会举办时,北京市气象局所购置的IBM Systemp575超级计算机的计算能力是原有系统的10倍,基于IBM Systemp575更高的计算性能,新的天气预报系统可覆盖4.4万平方公里的区域,且能为每平方公里按小时提供天气和空气质量预报等。
●地球模拟器
日本海洋研究开发机构的“地球模拟器”是一套用于地球大气循环监测和分析、温室效应预测、地壳及地震监测和预报等大规模计算的向量处理超级计算机系统。于2002年开始运行,共有640个节点,占地面积3200平方米。为了降低耗电和维护费用,“地球模拟器”不久前进行了升级,计算节点减少到160个计算节点,耗电量降低了20%-30%、占地面积降低为650m2,但计算速度由原来的40TFlops提升到131TFlops。
●药品研制
开发一种新的药品,通常需要从研制和试验的很多步骤,一般需要大约15年的时间,而利用超级计算机则可以对药物研制、治疗效果和不良反应等进行模拟试验,从而将新药的研发周期缩短3~5年且可显著降低研发成本。例如,美国基因工程技术公司的研究团队曾将超级计算机应用于一种致活酶类药物的研发,在14个月之内从50多万个化学分子中筛选出两个候选药物进行最终合成和临床试验,整个过程中真正在实验室里合成的分子只有2000个,其余均用超级计算机模拟完成,仅此就节省了上百倍的时间和成本。
●石油勘探
石油勘探大多采用地震勘测的办法,即在地面进行爆破后,用探测仪器检测和采集震动反射波的大量数据,利用对这些数据计算、处理和分析结果确定地下储油位置。石油勘探中大量数值的快速计算、处理和分析,必需由高性能的超级计算机完成。例如,2007年曙光4000L超级计算机就曾在发现储量高达10亿吨的渤海湾冀东南堡油田的过程中发挥了关键作用,而其后的曙光5000A超级计算机的应用,则进一步达到了地下数千米的勘探深度。
●核爆炸模拟
《全面禁止核试验条约》的签订之后,相关的一些国家开始转向利用大规模数值计算的方法进行核武器的模拟试验,以评测核武器的各项性能,这种应用对计算性能有着很高的要求。例如,美国劳伦斯利夫摩尔国家实验室就曾使用计算速度为360 Tflops的IBM“蓝色基因”(BlueGene/L)超级计算机进行过极为逼真的核弹爆炸三维模拟。此外,法国原子能委员会最近也订购了一台由布尔公司生产的、计算速度为1000Tflops的Tera-100超级计算机,将接替目前的Tera-10超级计算机用于模拟核武器爆炸过程。
写在最后:超级计算机的未来征程
一般认为,自1946年第一台电子计算机ENIAC问世至今,超级计算机的发展已先后经历了5个阶段或5代,即早期的单处理器巨型机、向量处理系统、大规模并行处理系统、共享内存处理系统和机群系统。如前所述,从TOP500排名中可以看出,目前越来越多的超级计算机都在向机群体系结构靠拢,机群系统大有“一统天下”的势头。

升级后的“地球模拟器”
机群系统由于采用了分布式内存(DM)结构因而具有很高的可扩展性,理论上只要以高带宽的网络互连技术为基础,增加节点数量就能提高并行处理能力或计算速度。另外,由于机群系统可以采用低成本的微型机组件、免费的Linux操作系统和并行编程平台来构建,因而具有非常高的性价比。的确,易于扩展、高性价比等特点赋予了机群系统很强的生命力,但是机群系统的计算性能是否简单地利用其可扩展性就能无限地提升呢?事实上,当机群节点数量过于庞大时,就不可避免地会遭遇到网络延迟加剧和并行处理环境等方面的瓶颈,系统的可靠性会大打折扣且维护的难度明显增加,同时占地面积和耗电量也将十分惊人。因此,目前“正在兴旺时期”的机群技术并不是超级计算机技术发展的终结者,未来超级计算机性能的进一步提升,依然要靠超级计算机体系结构和关键技术的创新来实现,例如有关“第6代超级计算机”(HPC-G6)的概念和基本构想目前已经被提出。
按照有关专家和研究人员的构想,与现有第5代的机群系统相比,未来的HPC-G6将具备更高的可扩展性、可用性、可持续性、计算密度、可管理性、运行效率和性能功耗比等特征。更高的可扩展性意味着未来的HPC-G6可以更大规模地扩展节点数量及其互连带宽,实现数千甚至上万个节点的高速互连。更高的可用性和计算可持续性即系统具有高可靠的持续运算能力,更高的计算密度指单个机架空间中将能容纳更多的处理单元、具有更高的计算能力,更高的可管理性即能够采用简便的操作控制方式实现对整个系统的有效管理。HPC-G6将具有更高的运行效率,并且单位功耗所换取的计算能力,也就是性能功耗比将进一步提升。虽然,HPG-G6目前还只是作为一种概念和构想被提出,但它标志着人们已经开始准备向着实现更高性能计算的征程出发。
上一篇:未来802.11家族发展探秘
四 : 小黑客发现超级计算机中心天河一号内网存大量弱口令
昨天下午,乌云漏洞提交平台公开了一起弱口令事件,该弱口令存在于国家超级计算机中心的天河一号计算机集群中。

据漏洞资料显示,天河一号内网中的500多个用户其中有200多个为弱口令。该网络中有大量的计算机节点,可以随意分配计算机任何给任意节点。而且,一些节点的“破壳”漏洞还没有打上补丁。(注:破壳是Liux操作系统中的一个高危安全漏洞,利用这个漏洞可对目标计算机系统进行完全控制。)这些问题如果被恶意黑客发现,不仅可以利用其强大的计算机资源谋取私利,还有可能危及其他系统中的敏感数据。
该漏洞由乌云平台著名的13岁白帽黑客zph于今年2月12日发现,国家超级计算机中心目前已修复了此漏洞,并采取了相关防护措施。

天河一号计算机集群用户列表
年仅13岁的小白帽zph向安全牛表示,国家超级计算机中心其办公环境的Wifi无需密码即可连接,连接上即可直接扫描天河一号的计算机集群,而其中某台计算机的磁盘上大量用户存在弱口令,以及一些节点上的“破壳“漏洞还没有补上。
问题提交到乌云平台后,相关负责人表示由于其“专线用户自身安全管理不当所致”,目前已经“将专线与互联网隔离,指导用户强化密码,删除系统中的临时账户等”。
安全牛评
国家级超级计算中心是指运算速度在1千万亿次/秒以上的计算中心,目前中国共有5家国家级超级计算中心,而天河一号在投入使用时为世界最快的超级计算机。这种代表国家最高科技水平的计算机网络,居然出现如此低级的安全失误,可见我们的安全管理和安全意识亟待普及与加强。
原文地址:
本文标题:
天河一号超级计算机-超级计算机“天河一号”的使用介绍 本文地址:
http://www.61k.com/1168480.html