一 : 前端本地文件操作与上传
12.12年度营销活动开抢,入驻就送超级大礼,马上咨询
前端无法像原生APP一样直接操作本地文件,否则的话打开个网页就能把用户电脑上的文件偷光了,所以需要通过用户触发,用户可通过以下三种方式操作触发:
通过input type=”file” 选择本地文件
通过拖拽的方式把文件拖过来
在编辑框里面复制粘贴
第一种是最常用的手段,通常还会自定义一个按钮,然后盖在它上面,因为type=”file”的input不好改变样式。如下代码写一个选择控件,并放在form里面:
<form>
<input type="file" id="file-input" name="fileContent">
</form>
然后就可以用FormData获取整个表单的内容:
$("#file-input").on("change", function() {
console.log(`file name is ${this.value}`);
let formData = new FormData(this.form);
formData.append("fileName", this.value);
console.log(formData);
});
把input的value和formData打印出来是这样的:
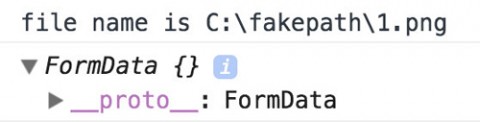
可以看到文件的路径是一个假的路径,也就是说在浏览器无法获取到文件的真实存放位置。同时FormData打印出来是一个空的Objet,但并不是说它的内容是空的,只是它对前端开发人员是透明的,无法查看、修改、删除里面的内容,只能append添加字段。
FormData无法得到文件的内容,而使用FileReader可以读取整个文件的内容。用户选择文件之后,input.files就可以得到用户选中的文件,如下代码:
$("#file-input").on("change", function() {
let fileReader = new FileReader(),
fileType = this.files[0].type;
fileReader.onload = function() {
if (/^image/.test(fileType)) {
// 读取结果在fileReader.result里面
$(`<img src="${this.result}">`).appendTo("body");
}
}
// 打印原始File对象
console.log(this.files[0]);
// base64方式读取
fileReader.readAsDataURL(this.files[0]);
});
把原始的File对象打印出来是这样的:

它是一个window.File的实例,包含了文件的修改时间、文件名、文件的大小、文件的mime类型等。如果需要限制上传文件的大小就可以通过判断size属性有没有超,单位是字节,而要判断是否为图片文件就可以通过type类型是否以image开头。通过判断文件名的后缀可能会不准,而通过这种判断会比较准。上面的代码使用了一个正则判断,如果是一张图片的话就把它赋值给img的src,并添加到dom里面,但其实这段代码有点问题,就是web不是所有的图片都能通过img标签展示出来,通常是jpg/png/gif这三种,所以你应该需要再判断一下图片格式,如可以把判断改成:
/^image/[jpeg|png|gif]/.test(this.type)
然后实例化一个FileReader,调它的readAsDataURL并把File对象传给它,监听它的onload事件,load完读取的结果就在它的result属性里了。它是一个base64格式的,可直接赋值给一个img的src.
使用FileReader除了可读取为base64之外,还能读取为以下格式:
// 按base64的方式读取,结果是base64,任何文件都可转成base64的形式
fileReader.readAsDataURL(this.files[0]);
// 以二进制字符串方式读取,结果是二进制内容的utf-8形式,已被废弃了
fileReader.readAsBinaryString(this.files[0]);
// 以原始二进制方式读取,读取结果可直接转成整数数组
fileReader.readAsArrayBuffer(this.files[0]);
其它的主要是能读取为ArrayBuffer,它是一个原始二进制格式的结果。把ArrayBuffer打印出来是这样的:

可以看到,它对前端开发人员也是透明的,不能够直接读取里面的内容,但可以通过ArrayBuffer.length得到长度,还能转成整型数组,就能知道文件的原始二进制内容了:
let buffer = this.result;
// 依次每字节8位读取,放到一个整数数组
let view = new Uint8Array(buffer);
console.log(view);
如果是通过第二种拖拽的方式,应该怎么读取文件呢?如下html(样式略):
<div class="img-container">
drop your image here
</div>
这将在页面显示一个框:

然后监听它的拖拽事件:
$(".img-container").on("dragover", function (event) {
event.preventDefault();
})
.on("drop", function(event) {
event.preventDefault();
// 数据在event的dataTransfer对象里
let file = event.originalEvent.dataTransfer.files[0];
// 然后就可以使用FileReader进行操作
fileReader.readAsDataURL(file);
// 或者是添加到一个FormData
let formData = new FormData();
formData.append("fileContent", file);
})
数据在drop事件的event.dataTransfer.files里面,拿到这个File对象之后就可以和输入框进行一样的操作了,即使用FileReader读取,或者是新建一个空的formData,然后把它append到formData里面。
第三种粘贴的方式,通常是在一个编辑框里操作,如把div的contenteditable设置为true:
<div contenteditable="true">
hello, paste your image here
</div>
粘贴的数据是在event.clipboardData.files里面:
$("#editor").on("paste", function(event) {
let file = event.originalEvent.clipboardData.files[0];
});
但是Safari的粘贴不是通过event传递的,它是直接在输入框里面添加一张图片,如下图所示:

它新建了一个img标签,并把img的src指向一个blob的本地数据。什么是blob呢,如何读取blob的内容呢?
blob是一种类文件的存储格式,它可以存储几乎任何格式的内容,如json:
let data = {hello: "world"};
let blob = new Blob([JSON.stringify(data)],
{type : 'application/json'});
为了获取本地的blob数据,我们可以用ajax发个本地的请求:
$("#editor").on("paste", function(event) {
// 需要setTimeout 0等图片出来了再处理
setTimeout(() => {
let img = $(this).find("img[src^='blob']")[0];
console.log(img.src);
// 用一个xhr获取blob数据
let xhr = new XMLHttpRequest();
xhr.open("GET", img.src);
// 改变mime类型
xhr.responseType = "blob";
xhr.onload = function () {
// response就是一个Blob对象
console.log(this.response);
};
xhr.send();
}, 0);
});
上面代码把blob打印出来是这样的:

能得到它的大小和类型,但是具体内容也是不可见的,它有一个slice的方法,可用于切割大文件。和File一样,可以使用FileReader读取它的内容:
function readBlob(blobImg) {
let fileReader = new FileReader();
fileReader.onload = function() {
console.log(this.result);
}
fileReader.onerror = function(err) {
console.log(err);
}
fileReader.readAsDataURL(blobImg);
}
readBlob(this.response);
除此,还能使用window.URL读取,这是一个新的API,经常和Service Worker配套使用,因为SW里面常常要解析url。如下代码:
function readBlob(blobImg) {
let urlCreator = window.URL || window.webkitURL;
// 得到base64结果
let imageUrl = urlCreator.createObjectURL(this.response);
return imageUrl;
}
readBlob(this.response);
关于src使用的是blob链接的,除了上面提到的img之外,另外一个很常见的是video标签,如youtobe的视频就是使用的blob:

这种数据不是直接在本地的,而是通过持续请求视频数据,然后再通过blob这个容器媒介添加到video里面,它也是通过URL的API创建的:
let mediaSource = new MediaSource();
video.src = URL.createObjectURL(mediaSource);
let sourceBuffer = mediaSource.addSourceBuffer('video/mp4; codecs="avc1.42E01E, mp4a.40.2"');
sourceBuffer.appendBuffer(buf);
具体我也没实践过,不再展开讨论。
上面,我们使用了三种方式获取文件内容,最后得到:
FormData格式
FileReader读取得到的base64或者ArrayBuffer二进制格式
如果直接就是一个FormData了,那么直接用ajax发出去就行了,不用做任何处理:
let form = document.querySelector("form"),
formData = new FormData(form),
formData.append("fileName", "photo.png");
let xhr = new XMLHttpRequest();
// 假设上传文件的接口叫upload
xhr.open("POST", "/upload");
xhr.send(formData);
如果用jQuery的话,要设置两个属性为false:
$.ajax({
url: "/upload",
type: "POST",
data: formData,
processData: false, // 不处理数据
contentType: false // 不设置内容类型
});
因为jQuery会自动把内容做一些转义,并且根据data自动设置请求mime类型,这里告诉jQuery直接用xhr.send发出去就行了。
观察控制台发请求的数据:
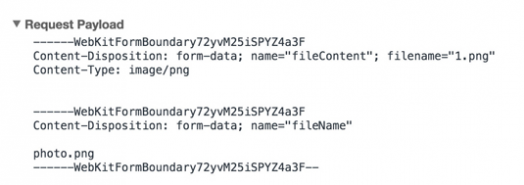
<form enctype="multipart/form-data" method="post">
<input type="file" name="fileContent">
</form>
如果xhr.send的是FormData类型话,它会自动设置enctype,如果你用默认表单提交上传文件的话就得在form上面设置这个属性,因为上传文件只能使用POST的这种编码。常用的POST编码是application/x-www-form-urlencoded,它和GET一样,发送的数据里面,参数和参数之间使用&连接,如:
key1=value1&key2=value2
特殊字符做转义,这个数据POST是放在请求body里的,而GET是拼在url上面的,如果用jq的话,jq会帮你拼并做转义。
而上传文件用的这种multipart/form-data,参数和参数之间是且一个相同的字符串隔开的,上面的是使用:
——WebKitFormBoundary72yvM25iSPYZ4a3F
这个字符通常会取得比较长、比较随机,因为要保证正常的内容里面不会出现这个字符串,这样内容的特殊字符就不用做转义了。
请求的contentType被浏览器设置成:
Content-Type:
multipart/form-data; boundary=—-WebKitFormBoundary72yvM25iSPYZ4a3F
后端服务通过这个就知道怎么解析这么一段数据了。(通常是使用的框架处理了,而具体的接口不需要关心应该怎么解析)
如果读取结果是ArrayBuffer的话,也是可以直接用xhr.send发送出去的,但是一般我们不会直接把一个文件的内容发出去,而是用某个字段名等于文件内容的方式。如果你读取为ArrayBuffer的话再上传的话其实作用不是很大,还不如直接用formData添加一个File对象的内容,因为上面三种方式都可以拿到File对象。如果一开始就是一个ArrayBuffer了,那么可以转成blob然后再append到FormData里面。
使用比较多的应该是base64,因为前端经常要处理图片,读取为base64之后就可以把它画到一个canvas里面,然后就可以做一些处理,如压缩、裁剪、旋转等。最后再用canvas导出一个base64格式的图片,那怎么上传base64格式的呢?
第一种是拼一个表单上传的multipart/form-data的格式,再用xhr.sendAsBinary发出去,如下代码:
let base64Data = base64Data.replace(/^data:image/[^;]+;base64,/, "");
let boundary = "----------boundaryasoifvlkasldvavoadv";
xhr.sendAsBinary([
// name=data
boundary,
'Content-Disposition: form-data; name="data"; filename="' + fileName + '"',
'Content-Type: ' + "image/" + fileType, '',
atob(base64Data), boundary,
//name=imageType
boundary,
'Content-Disposition: form-data; name="imageType"', '',
fileType,
boundary + '--'
].join('rn'));
上面代码使用了window.atob的api,它可以把base64还原成原始内容的字符串表示,如下图所示:

btoa是把内容转化成base64编码,而atob是把base64还原。在调atob之前,需要把表示内容格式的不属于base64内容的字符串去掉,即上面代码第一行的replace处理。
这样就和使用formData类似了,但是由于sendAsBinary已经被deprecated了,所以新代码不建议再使用这种方式。那怎么办呢?
可以把base64转化成blob,然后再append到一个formData里面,下面的函数(来自b64-to-blob)可以把base64转成blob:
function b64toBlob(b64Data, contentType, sliceSize) {
contentType = contentType || '';
sliceSize = sliceSize || 512;
var byteCharacters = atob(b64Data);
var byteArrays = [];
for (var offset = 0; offset < byteCharacters.length; offset += sliceSize) {
var slice = byteCharacters.slice(offset, offset + sliceSize);
var byteNumbers = new Array(slice.length);
for (var i = 0; i < slice.length; i++) {
byteNumbers[i] = slice.charCodeAt(i);
}
var byteArray = new Uint8Array(byteNumbers);
byteArrays.push(byteArray);
}
var blob = new Blob(byteArrays, {type: contentType});
return blob;
}
然后就可以append到formData里面:
let blob = b64toBlob(b64Data, "image/png"),
formData = new FormData();
formData.append("fileContent", blob);
这样就不用自己去拼一个multipart/form-data的格式数据了。
上面处理和上传文件的API可以兼容到IE10+,如果要兼容老的浏览器应该怎么办呢?
可以借助一个iframe,原理是默认的form表单提交会刷新页面,或者跳到target指定的那个url,但是如果把ifrmae的target指向一个iframe,那么刷新的就是iframe,返回结果也会显示在ifame,然后获取这个ifrmae的内容就可得到上传接口返回的结果。
如下代码:
let iframe = document.createElement("iframe");
iframe.display = "none";
iframe.name = "form-iframe";
document.body.appendChild(iframe);
// 改变form的target
form.target = "form-iframe";
iframe.onload = function() {
//获取iframe的内容,即服务返回的数据
let responseText = this.contentDocument.body.textContent
|| this.contentWindow.document.body.textContent;
};
form.submit();
form.submit会触发表单提交,当请求完成(成功或者失败)之后就会触发iframe的onload事件,然后在onload事件获取返回的数据,如果请求失败了的话,iframe里的内容就为空,可以用这个判断请求有没有成功。
使用iframe没有办法获取上传进度,使用xhr可以获取当前上传的进度,这个是在XMLHttpRequest 2.0引入的:
xhr.upload.onprogress = function (event) {
if (event.lengthComputable) {
// 当前上传进度的百分比
duringCallback ((event.loaded / event.total)*100);
}
};
这样就可以做一个真实的loading进度条。
本文讨论了3种交互方式的读取方式,通过input控件在input.files可以得到File文件对象,通过拖拽的是在drop事件的event.dataTransfer.files里面,而通过粘贴的paste事件在event.clipboardData.files里面,Safari这个怪胎是在编辑器里面插入一个src指向本地的img标签,可以通过发送一个请求加载本地的blob数据,然后再通过FileReader读取,或者直接append到formData里面。得到的File对象就可以直接添加到FormData里面,如果需要先读取base64格式做处理的,那么可以把处理后的base64转化为blob数据再append到formData里面。对于老浏览器,可以使用一个iframe解决表单提交刷新页面或者跳页的问题。
总之,前端处理和上传本地文件应该差不多就是这些内容了,但是应该还有好多细节没有提及到,读者可通过本文列的方向自行实践。如果有其它的上传方式还请告知。
二 : C++之文件IO操作流
前两节介绍了C++的IO流类库,标准设备IO操作流中部分预定义流对象的成员函数以及IO格式控制。(www.61k.com]那今天我将继续介绍关于C++中的流操作内容——文件IO操作流fstream。并会着重讲解C++是如何对文件进行操作的。
文件指存放在外部介质上的数据的集合。大家都知道操作系统是以文件为单位来对数据进行管理的。因此如果你要查找外部介质的数据,则先要按文件名找到指定文件,然后再从文件中读取数据,如果要把数据存入外部介质中,如果没有该文件,则先要建立文件,再向它输入数据。由于文件的内容千变万化,大小各不相同,为了统一处理,在C++中用文件流的形式来处理,文件流是以外存文件为输入输出对象的数据流。输出文件流表示从内存流向外存文件的数据,输入文件流则相反。根据文件中数据的组织形式,文件可分为两类:文本文件和二进制文件。文本文件又称为ASCII文件,它的每个字节存放一个ASCII码,代表一个字符。二进制文件则是把内存中的数据,按照其在内存中的存储形式原样写在磁盘上存放。比如一个整数20000,在内存中在两个字节,而按文本形式输出则占5个字节。因此在以文本形式输出时,一个字节对应一个字符,因而便于字符的输出,缺点则是占用存储空间较多。用二进制形式输出数据,节省了转化时间和存储空间,但不能直接以字符的形式输出。
1.在C++中对文件进行操作分为以下几个步骤:(1)建立文件流对象;(2)打开或建立文件;(3)进行读写操作;(4)关闭文件;用于文件IO操作的流类主要有三个fstream(输入输出文件流),ifstream(输入文件流)和ofstream(输出文件流);而这三个类都包含在头文件fstream中,所以程序中对文件进行操作必须包含该头文件。首先建立流对象,然后使用文件流类的成员函数open打开文件,即把文件流对象和指定的磁盘文件建立关联。成员函数open的一般形式为:
文件流对象.open(文件名,使用方式);
其中文件名可以包括路径(如:e:\c++\file.txt),如果缺少路径,则默认为当前目录。使用方式则是指文件将被如何打开。以下就是文件的部分使用方式,都是ios基类中的枚举类型的值:

此外打开方式有几个注意点:
(1)因为nocreate和noreplace,与系统平台相关密切,所以在C++标准中去掉了对它的支持。
(2)每一个打开的文件都有一个文件指针,指针的开始位置由打开方式指定,每次读写都从文件指针的当前位置开始。每读一个字节,指针就后移一个字节。当文件指针移到最后,会遇到文件结束符EOF,此时流对象的成员函数eof的值为非0值,表示文件结束。
(3)用in方式打开文件只能用于输入数据,而且该文件必须已经存在。
(4)用app方式打开文件,此时文件必须存在,打开时文件指针处于末尾,且该方式只能用于输出。
(5)用ate方式打开一个已存在的文件,文件指针自动移到文件末尾,数据可以写入到其中。
如果文件需要用两种或多种方式打开,则用"|"来分隔组合在一起。除了用open成员函数打开文件,还可以用文件流类的构造函数来打开文件,其参数和默认值与open函数完全相同。比如:文件流类 stream(文件名,使用方法);如果文件打开操作失败,open函数的返回值为0,用构造函数打开的话,流对象的值为0。所以无论用哪一种方式打开文件,都需要在程序中测试文件是否成功打开。
在每次对文件IO操作结束后,都需要把文件关闭,那么就需要用到文件流类的成员函数close,一般调用形式:流对象.close();关闭实际上就是文件流对象和磁盘文件失去关联。
2.介绍完文件的打开和关闭,接下来说说文件的读写。我将分别从文本文件读写和二进制文件的读写来介绍。其实文件的读写是十分容易的。流类库中的IO操作<<、>>、put、get、getline、read和write都可以用于文件的输入输出。
(1)文本文件的读写:
写文件:
1 #include "stdafx.h"
2 #include <iostream>
3 #include <fstream>
4
5 int main()
6 {
7 //打开文件
8 std::ofstream file("file.txt",std::ios::out|std::ios::ate);
9 if(!file)
10 {
11 std::cout<<"不可以打开文件"<<std::endl;
12 exit(1);
13 }
14
15 //写文件
16 file<<"hello c++!\n";
17
18 char ch;
19 while(std::cin.get(ch))
20 {
21 if(ch=='\n')
22 break;
23 file.put(ch);
24 }
25
26 //关闭文件
27 file.close();
28
29 return0;
30 }
键盘输入字符:

读文件file.txt:
1 #include "stdafx.h"
2 #include <iostream>
3 #include <fstream>
4
5 int main()
6 {
7 //打开文件
8 std::ifstream rfile("file.txt",std::ios::in);
9 if(!rfile)
10 {
11 std::cout<<"不可以打开文件"<<std::endl;
12 exit(1);
13 }
14
15 //读文件
16 char str[100];
17 rfile.getline(str,100);//读到'\n'终止
18 std::cout<<str<<std::endl;
19
20 char rch;
21 while(rfile.get(rch))//文件指针指向字符‘\n’的下一个
22 {
23 std::cout.put(rch);
24 }
25
26 std::cout<<std::endl;
27
28 //关闭文件
29 rfile.close();
30
31 return0;
32 }
读出显示字符:

扩展:c io流读取文件 / c 文件流操作 / 文件io操作
其实建立ifstream类和ofstream类的对象时,ios:in和ios:out可以省略,因为ifstream类默认为ios:in,ofstream类默认为ios:out;
(2)最初设计流的目的是用于文本,因此在默认情况下,文件用文本方式打开。在以文本模式输出时,若遇到换行符"\n"(十进制为10)则自动扩充为回车换行符(十进制为13和10)。所以,如果我们输入的整数10,那么在文件输出时会转化为13和10,然而这并不是我们所需要的。为了解决这样的问题,就要采用而二进制模式,使其所写的字符不转换。在对二进制文件进行IO操作时,打开文件时要指定方式ios::binary,即以二进制形式传送和存储。接下来我用read函数和write函数来对二进制文件进行读写。在示例描述之前先简单介绍一下这两个函数:
read函数常用格式为:文件流对象.read(char *buf,int len);
write函数常用格式为:文件流对象.write(const char *buf,int len);
两者格式上差不多,第一个参数是一个字符指针,用于指向读入读出数据所放的内存空间的其实地址。第二个参数是一个整数,表示要读入读出的数据的字节数。以下是二进制文件的读写的示例:
定义一个精灵类(用于文件数据处理):
1 class Sprite
2 {
3 private:
4 std::string profession;//职业
5 std::string weapon;//武器
6 staticint count;//个数
7 public:
8 Sprite(){}
9 Sprite(std::string profession,std::string weapon):profession(profession),weapon(weapon)
10 {
11 }
12 void showSprite();//显示精灵信息
13 };
14
15 int Sprite::count=0;
16
17 void Sprite::showSprite()
18 {
19 ++count;
20 std::cout<<"精灵"<<count<<" 职业:"<<profession<<" 武器:"<<weapon<<std::endl;
21 }
写文件:
1 #include "stdafx.h"
2 #include <iostream>
3 #include <fstream>
4 #include <string>
5
6 int main()
7 {
8 //建立对象数组
9 Sprite sprites[3]={
10 Sprite("法师","魔杖"),
11 Sprite("战士","屠龙宝刀"),
12 Sprite("道士","倚天剑")
13 };
14
15 //打开文件
16 std::ofstream file("file.dat",std::ios::ate|std::ios::binary);
17 if(!file)
18 {
19 std::cout<<"文件打开失败!";
20 abort();//等同于exit
21 }
22
23 //写文件
24 for(int i=0;i<3;i++)
25 file.write((char*) &sprites[i],sizeof(sprites[i]));
26
27 //关闭文件
28 file.close();
29
30 return0;
31 }
读文件file.dat:
1 #include "stdafx.h"
2 #include <iostream>
3 #include <fstream>
4 #include <string>
5
6 int main()
7 {
8 //建立对象数组
9 Sprite rsprites[3];
10
11 //打开文件
12 std::ifstream rfile("file.dat",std::ios::binary);
13 if(!rfile)
14 {
15 std::cout<<"文件打开失败!";
16 return1;//等同于exit
17 }
18
19 //读文件
20 for(int i=0;i<3;i++)
21 {
22 rfile.read((char*) &rsprites[i],sizeof(rsprites[i]));
23 rsprites[i].showSprite();
24 }
25
26 //关闭文件
27 rfile.close();
28
29 return0;
30 }
读出显示字符:

在read函数还是write函数里都要把数据转化为char*类型,代码中sizeof函数是用于确定要读入读出的字节数。
在文件结束处有个标志位EOF,在用文件流读取文件时,使用成员函数eof()(函数原型:int eof())可以检测到结束符。如果该函数返回值为非零,则表示到达文件末尾。返回零则表示未达到文件末尾。
(3)前面所介绍的文件都是按顺序来读取的的,C++中又提供了针对于文件读写指针的相关成员函数,使得我们可以在IO流中随意移动文件指针,从而对文件的进行随机地读写。类istream针对读指针提供3个成员函数:
tellg()//返回输入文件读指针的当前位置;
seekg(文件中的位置)//将输入文件中的读指针移动到指定位置
seekg(位移量,参照位置)//以参照位置为基准移动若干字节
其中参照位置是枚举值:
beg//从文件开头计算要移动的字节数
cur//从文件指针的当前位置计算要移动的字节数
end//从文件的末尾计算要移动的字节数
如果参照位置省略,则默认为beg。而类ostream针对写指针提供的3个成员函数:
tellp()//返回输出文件写指针的当前位置;
seekp(文件中的位置)//将输出文件中的写指针移动到指定位置
seekp(位移量,参照位置)//以参照位置为基准移动若干字节
现在我对上一示例中读取二进制文件代码稍作更改:
1 #include "stdafx.h"
2 #include <iostream>
3 #include <fstream>
4 #include <string>
5
6 int main()
7 {
8 //建立对象数组
9 Sprite rsprites[3];
10
11 //打开文件
12 std::ifstream rfile("file.dat",std::ios::binary);
13 if(!rfile)
14 {
15 std::cout<<"文件打开失败!";
16 return1;//等同于exit
17 }
18
19 //读文件
20 for(int i=0;i<3;i++)
21 {扩展:c io流读取文件 / c 文件流操作 / 文件io操作
22 rfile.read((char*) &rsprites[i],sizeof(rsprites[i]));
23 rsprites[i].showSprite();
24 }
25
26 Sprite rsprite;//建立对象
27
28 std::cout<<"改变读取顺序:"<<std::endl;
29 rfile.seekg(sizeof(Sprite)*2,std::ios::beg);//读取精灵道士信息
30 rfile.read((char*) &rsprite,sizeof(Sprite));
31 rsprite.showSprite();
32
33 rfile.seekg(-int(sizeof(Sprite)*2),std::ios::end);//读取精灵战士信息
34 rfile.read((char*) &rsprite,sizeof(Sprite));
35 rsprite.showSprite();
36
37 rfile.seekg(-int(sizeof(Sprite)*2),std::ios::cur);//读取精灵法师信息
38 rfile.read((char*) &rsprite,sizeof(Sprite));
39 rsprite.showSprite();
40
41 //关闭文件
42 rfile.close();
43
44 return0;
45 }
结果:

扩展:c io流读取文件 / c 文件流操作 / 文件io操作
三 : 文件操作 SHFILEOPSTRUCT与SHFileOperation()
关于 SHFILEOPSTRUCT 收藏 在Windows的shellapi文件中定义了一个名为SHFileOperation()的外壳函数,用它可以实现各种文件操作,如文件的拷贝、删除、移动等,该函数使用起来非常简单,它只有一个指向SHFILEOPSTRUCT结构的参数。[www.61k.com)使用SHFileOperation()函数时只要填写该专用结构--SHFILEOPSTRUCT,告诉Windows执行什么样的操作,以及其它重要信息就行了。SHFileOperation()的特别之处在于它是一个高级外壳函数,不同于低级文件处理。当调用SHFileOperation操作文件时,相应的外壳拷贝处理器(如果有的话)被调用。如在删除某个文件时,SHFileOperation会将删除的文件放到Recycle Bin中。SHFileOperation()函数的原形为: WINSHELLAPI int WINAPI SHFileOperation (LPSHFILEOPSTRUCT lpFIleOp); 函数中参数类型为一个LPSHFILEOPSTRUCT结构,它包含有进行文件操作的各种信息,其具体的结构如下: Typedef struct _ShFILEOPSTRUCT { HWND hWnd; //消息发送的窗口句柄; UINT wFunc; //操作类型 LPCSTR pFrom; //源文件及路径 LPCSTR pTo; //目标文件及路径 FILEOP_FLAGS fFlags; //操作与确认标志 BOOL fAnyOperationsAborted; //操作选择位 LPVOID hNameMappings; //文件映射 LPCSTR lpszProgressTitle; //文件操作进度窗口标题 }SHFILEOPSTRUCT, FAR * LPSHFILEOPSTRUCT; 在这个结构中,hWnd是指向发送消息的窗口句柄,pFrom与pTo是进行文件操作的源文件名和目标文件名,它包含文件的路径,对应单个文件的路径字符串,或对于多个文件,必须以NULL作为字符串的结尾或文件路径名之间的间隔,否则在程序运行的时候会发生错误。另外,pFrom和pTo都支持通配符*和?,这大大方便了开发人员的使用。例如,源文件或目录有两个,则应是:char pFrom[]="d:Test1�d:Text.txt�",它表示对要D:盘Test1目录下的所有文件和D:盘上的Text.txt文件进行操作。字符串中的""是C语言中的''的转义符,'�'则是NULL。wFunc 是结构中的一个非常重要的成员,它代表着函数将要进行的操作类型,它的取值为如下: ·FO_COPY: 拷贝文件pFrom到pTo 的指定位置。 ·FO_RENAME: 将pFrom的文件名更名为pTo的文件名。 ·FO_MOVE: 将pFrom的文件移动到pTo的地方。 ·FO_DELETE: 删除pFrom指定的文件。 使用该函数进行文件拷贝、移动或删除时,如果需要的时间很长,则程序会自动在进行的过程中出现一个无模式的对话框(Windows操作系统提供的文件操作对话框),用来显示执行的进度和执行的时间,以及正在拷贝、移动或删除的文件名,此时结构中的成员lpsz
shfileoperation 文件操作 SHFILEOPSTRUCT与SHFileOperation()
ProgressTitle显示此对话框的标题。(www.61k.com)fFlags是在进行文件操作时的过程和状态控制标识。它主要有如下一些标识,也可以是其组合: ·FOF_FILESONLY:执行通配符,只执行文件; ·FOF_ALLOWUNDO:保存UNDO信息,以便在回收站中恢复文件; ·FOF_NOCONFIRMATION:在出现目标文件已存在的时候,如果不设置此项,则它会出现确认是否覆盖的对话框,设置此项则自动确认,进行覆盖,不出现对话框。 ·FOF_NOERRORUI:设置此项后,当文件处理过程中出现错误时,不出现错误提示,否则会进行错误提示。 ·FOF_RENAMEONCOLLISION:当已存在文件名时,对其进行更换文提示。 ·FOF_SILENT:不显示进度对话框。 ·FOF_WANTMAPPINGHANDLE:要求SHFileOperation()函数返回正处于操作状态的实际文件列表,文件列表名柄保存在hNameMappings成员中。 ·SHFILEOPSTRUCT结构还包含一个SHNAMEMAPPING结构的数组,此数组保存由SHELL计算的每个处于操作状态的文件的新旧路径。 同时也有一个重要的应用就是:在进行文件操作时,可以使用CFile类中的Remove()函数来删除一个文件,但是这样的操作将永久性的删除该文件,不能在必要的时候再恢复该文件,解决这个问题的唯一方法就是把文件送到Windows系统中的回收站(Recycle Bin)里面,而不是简单的永久性删除它,这样用户就可以在必要的时候恢复这个文件。用这个函数实现编程来实现Windows回收站的文件存取操作。在使用该函数删除文件时必须设置SHFILEOPSTRUCT结构中的神秘FOF_ALLOWUNDO标志,这样才能将待删除的文件拷到Recycle Bin,从而使用户可以撤销删除操作。需要注意的是,如果pFrom设置为某个文件名,用FO_DELETE标志删除这个文件并不会将它移到Recycle Bin,甚至设置FOF_ALLOWUNDO标志也不行,在这里你必须使用全路径名,这样SHFileOperation才会将删除的文件移到Recycle Bin。代码如下: void CFileOperationView::OnFileDelete() { int nOk; char strSrc[]="d:Vb�";//源文件路径; char strDst[]="d:Vb1�";//目标文件路径; char strTitle[]="文件拷贝"; //文件删除进度对话框标题 SHFILEOPSTRUCT FileOp;//定义SHFILEOPSTRUCT结构对象; FileOp.hwnd=this->m_hWnd; FileOp.wFunc=FO_DELETE; //执行文件删除操作; FileOp.pFrom=strSrc; FileOp.pTo=strDst; FileOp.fFlags=FOF_ALLOWUNDO;//此标志使删除文件备份到Windows回收站 FileOp.hNameMappings=NULL; FileOp.lpszProgressTitle=strTitle; //开始删除文件 nOk=SHFileOperation(&FileOp); if(nOk) TR
shfileoperation 文件操作 SHFILEOPSTRUCT与SHFileOperation()
ACE("There is an error: %dn",nOk); else TRACE("SHFileOperation finished successfullyn"); }
61阅读提醒您本文地址:
四 : 教你怎么制作exe程序可执行文件
很多软件的运行都需要搭建环境,只有exe文件可以在不安装软件和数据库的环境下运行,那么怎么制作exe程序可执行文件呢,下面小编教你如何制作。
工具/原料
Microsoft Visual Studio 2008
方法/步骤
1、双击桌面上的Microsoft Visual Studio 2008,打开软件
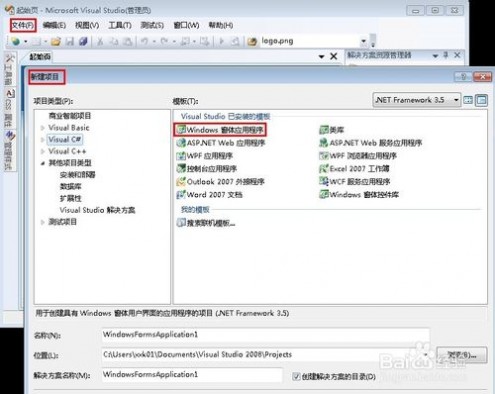
2、点击【文件】——【新建项目】——【windows窗体应用程序】
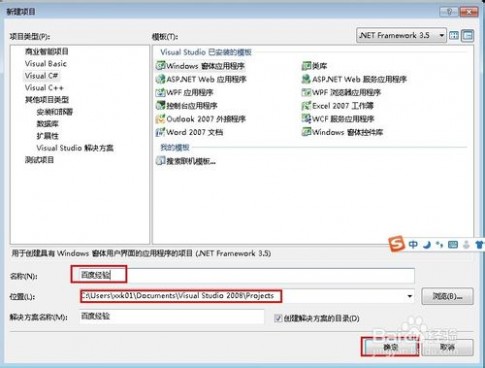
3、输入项目名称,选择程序文件路径,点击【确定】
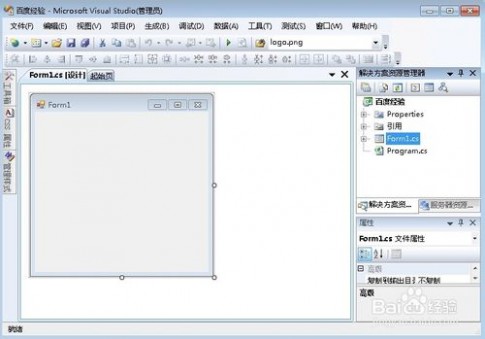
4、这样就打开了项目编辑窗口,完全的可视化编程界面
5、修改窗体里面的TEXT属性,这里就是窗口显示的名字
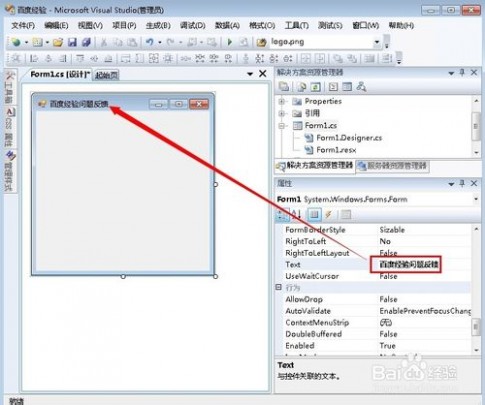
6、打开工具箱,把“TextBox”拖动到窗体中,它现在是单行文本
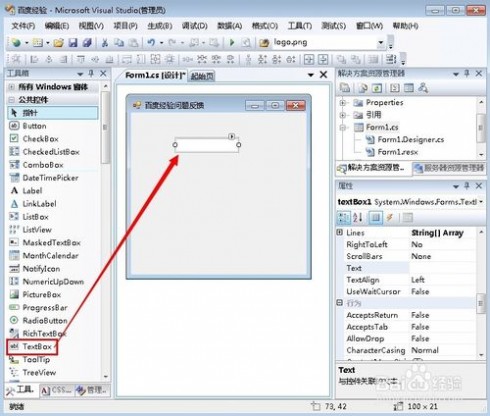
7、点击单行文本框的小三角符号,弹窗的框里面勾选复选按钮,如图所示
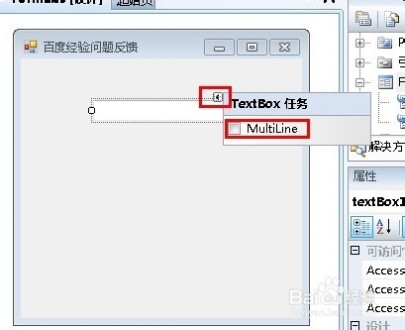
8、此时,文本框就变为了多行文本框
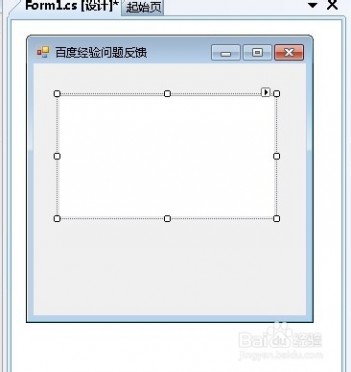
9、拖动一个button按钮到窗体上
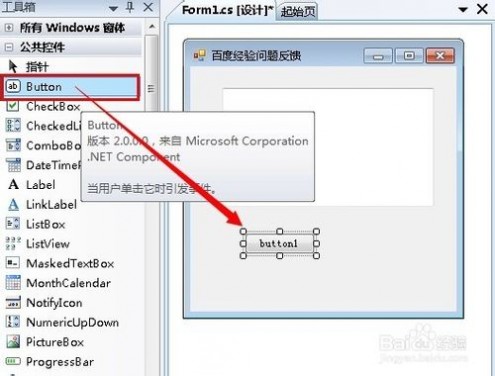
10、调整按钮位置和大小,修改按钮名字
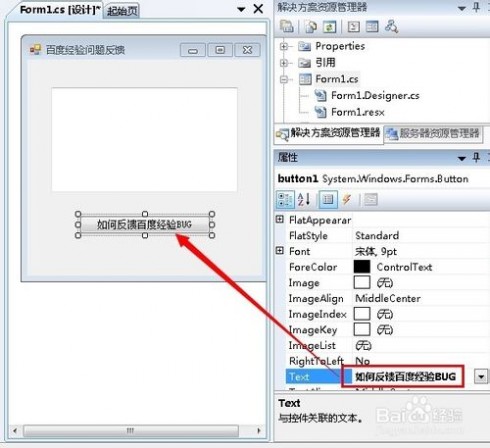
11、双击button按钮,打开代码编辑界面

12、如图所示在Click事件中输入如下代码

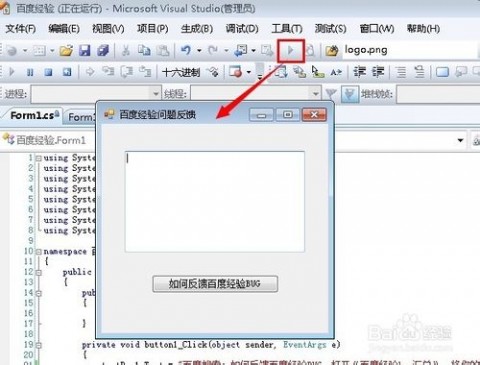
13、点击绿色三角按钮,运行程序如图所示
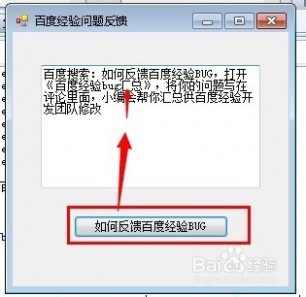
14、点击按钮【如何反馈百度经验BUG】会在文本框中出现如图文字
15、点击如图所示按钮,打开程序所在位置
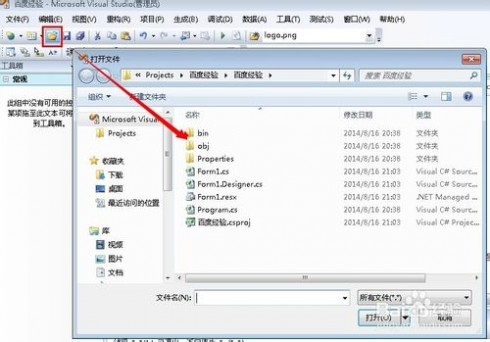
16、进入到如图所示文件目录下,就可以看见我们制作好的exe文件
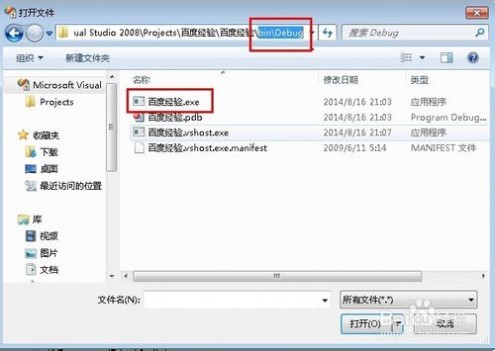
17、在"百度经验.exe"上直接单击右键,复制
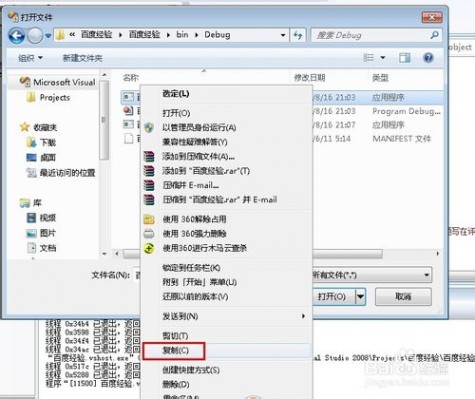
18、这个文件直接粘贴出来,放在任何电脑上都可以直接运行了,记住exe文件容易被误解为病毒程序记得放行或者添加信任哦
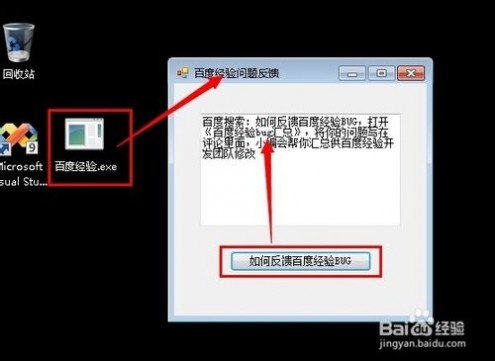
END
以上就是怎么制作exe程序可执行文件方法过程,大家看明白了吗?希望这篇文章对大家有所帮助想,谢谢阅读!
本文标题:该文件没有程序与之关联来执行该操作-前端本地文件操作与上传61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1