一 : 医疗编辑用户体验重中之重分析后台数据统计
如何能写出更符合患者需求的文章?如何分析自己之前的工作成功点失败点在哪里?这就是下面我说到的后台数据统计,数据统计是我个人认为比较重要的一项内容,它不仅可以为我们的文章编辑提供素材,还能让我们学会如何分析问题,找出症结所在。下面我们就来具体看一下,个人比较喜欢cnzz与百度统计联合看,朋友们可以根据自己的习惯。筛选来用,只需要在网站中加入统计代码即可,下面以我们的新上线的网站 中医治疗肿瘤网来举例说明。希望朋友能明白数据统计的重要意义:
1、 第一个比较重要的就是我们先简单看一下访问量的情况,最好每天做一个简单的记录。一星期做一个对比,找出流量偏大或者流量偏小的那天,仔细分析问题出在哪里,找到原因,及时与技术人员或者SEO人员沟通,发现问题及时交流,自己做个excel表格,每天统计,养成习惯。
2、 看搜索引擎关键词来源个数,看这个统计的重要意义在于我们能够有的放矢的分析网站的问题出在哪里,比如相对于昨天相比,谷歌的关键词少了,或者百度的关键词少了,那么我们在下一步的写作或者优化过程中就能够做到心中有数,有修改的方向等。
3、 关键词,查看一下关键词的搜索排名。这个是我们写文章标题的来源之一,也可以让我们看到那类标题是符合患者的搜索习惯的,根据排名,分析排名较好的单页文章取得较好排名的原因,总结经验,在以后的写作中继续保持等。
4、 受访页面,这个也是很重要的一项,我们要重点看一下访问量较高的页面的跳出率情况。跳出率过高说明用户体验很差,如果是单页文章,说明内容部分引导性做的不够,统计一段时间的受访页面,找出在正常范围内的跳出率,对于研究转化页面以及转化文章有非常大的好处。例如如果一个页面访问量很高,但是跳出率也过高的话,一方面说明我们页面的可读性差,另一方面说明我们没有做好充分的引导以及相关内容的推荐。这个我们以后会详细的说明。如果应对和修改这样的情况。
5、 访问明细,访问明细就是一个访客进入到我们网站的浏览情况,分析这个数据可以很好的指导我们在文章的写作中该如何做好相关内容的推荐以及对于PV明显不够的栏目或者页面做修改,也可以通过一些列的页面的点击情况来分析一个患者的心理,也就是说当他通过一个关键词进入页面后,看完文章心里有想法后还会关注其他哪些内容等。这对我们揣摩用户心里帮助很大。
总结:无论是做文案还是编辑,我们都不要尝试去臆想或者凭空猜测患者的心理,我们必须要做的就是拿数据说话,有了数据,才会有方向,才会发现是否进入误区,如:
来源词,搜索词乱,都是一些无关紧要的词,那么我们下一步需要调整什么,需要怎么做?
受访页面跳出率高,什么原因,为什么,该怎么做,从各个搜索引擎过来的词降低,少了哪些词,哪个搜索引擎,需要怎么调整,热点图,访客来到网站后喜欢点击哪个区域的东西,为什么,分析......
通过数据分析,我们就能找到工作的方向,也能了解到哪些地方做的不好,也就会分析自己的工作。每天可以抽出一个小时的时间来做整理数据与分析数据,然后有的放矢的开始一天的工作。这样坚持一段时间,我相信会看到效果。
本文系零度鸡尾酒www.zhongliuxinxi.com/原创,转载需注明出处。珍惜原创的劳动成果。
二 : 贝乐通——数据分析+图表统计 互联健身打造智慧健身管理软
多角色管理,高效便捷
信息管理、动态查询、整合计划,以最精确的方式大早最精英的团队,为您的会所注入精英与激情,永葆无限活力。[www.61k.com)
绑定客户群,感觉好安心
特设会员互动功能,随时随地激活会员健康细胞,把会员绑定在你身边,拥有固定客户群,让人好安心。
全面支持移动办公
可在任何终端直接配置,安卓市场和苹果商店均可下载贝乐通,适配大部分主流手机。让健身会所运营、管理不在局限任何场景。
便捷放心的云平台
贝乐通采用“云”来存储数据,容量大,完全排除由于硬件、机器 等故障导致的数据丢失;数据采用加密存储,即使打开数据库,也 只显示密文;贝乐通云服务器部署了透明加密系统,任何文件、数 据离开服务器都不能独立运行,保障会所会员和数据安全。
智能图表
智能绘图功能,自动绘制数据线性图。时间,给工作少一点,给自己多一点,终于有空闲一起动起来!
扩展:互联网养车第一品牌 / 互联网 智慧能源 / 上投智慧互联
三 : 基于主成分分析法的电影数据统计分析
【摘 要】本文利用主成分分析法对著名导演卡梅隆所执导六部影片的相关数据进行统计分析。结果表明,电影票房、获奖次数、观众评分等代表电影成功的因素是和拍摄电影时投入的时间和金钱紧密相关,一般情况下,投入的金钱和时间越多,出产的影片越能获得更高的得分和票房,就越能接近成功。
【关键词】卡梅隆;电影;票房;主成分分析法
1 数据来源
本文选取的指标共有六项,其中包括能代表电影成功的总票房,IMDB评分,获奖次数等,能代表拍摄电影时投入的制作花费和拍摄时间。
本文有的数据收集自Box Office Mojo官网上的票房排行榜(上映时间,北美总票房),有的数据收集自IMDB电影评分官网(IMDB评分),还有数据收集自维基百科(获奥斯卡奖数,制作花费,拍摄时间)进行数据统计,结果如表1所示。
表1 卡梅隆经典电影票房统计分析
2 主成份分析法
主成份分析法也称主分量分析或矩阵数据分析,通过变量变换的方法把相关的变量变为若干不相关的综合指标变量。
若某研究对象有两项指标ζ1和ζ2,从总体ζ(ζ1,ζ2)中抽取了N个样品,它们散布在椭圆平面内(见图1),指标ζ1与ζ2有相关性。η1和η2分别是椭圆的长轴和短轴,η1⊥η2,故η1与η2互不相关。其中η1是点ζ(ζ1,ζ2)在长轴上的投影坐标,η2是该点在短轴上的投影坐标。从图1可以看出点的N个观测值的波动大部分可以归结为η1轴上投影点的波动,而η2轴上投影点的波动较小。若η1作为一个综台指标,则η1可较好地反映出N个观测值的变化情况,η2的作用次要。综合指标η1称为主成份,找出主成份的工作称为主成份分析。
可见,主成份分析即选择恰当的投影方向,将高维空间的点投影到低维空间上,且使低维空间上的投影尽可能多地保存原空间的信息,就是要使低维空间上投影的方差尽可能地大。
3 主成份分析法的应用
3.1 原始数据的处理和标准化
为了更直观的表示电影上映距今多长时间与票房之间的关系,将第一项指标“上映时间”改为“上映距今”,并对原始数据进行标准化处理,得到相关矩阵如表2所示。
表2 标准化处理后的矩阵
3.2 主成份分析的计算结果
运行SPSS软件,录入上述数据,进行主成份分析,输出成分矩阵,如表3所示,输出成分图,如图2所示。
表3 成份矩阵
图2
3.3 结果分析
由主成份计算结果可知,选取三个主成份来进行分析,这三个主成份的方差累计贡献率达到了99.85%,其中第一主成分占67%,第二主成份占16%,第三主成份占14%,可以认为这三个主成分极大程度上反映了原始数据。
在第一主成份中,北美总票房,获奖数,制作花费,拍摄时间这三个占有很大的权重,而且他们的变化方向一致,呈正相关关系,这说明在拍摄电影时投入越多资金,拍摄时间越长,出产的电影越能得到更高的票房,而且更有机会获奖。事实上,投入更多资金就意味着能请更好的编剧写出更好的剧本,请更好的导演和著名影星,更能使用更高级的道具设备等,优越的硬件条件是出产好电影的基础;投入更多的时间拍摄就意味着导演对于每个镜头要求都非常严格,精工细作才能出产好的电影。
另外,上映距今和总票房之间变化方向相反,呈负相关关系,这与常识是不相符,一般情况下距今时间越长,总票房越高,但是现在的金钱与过去的是不等值的,而且在过去电影还没有现在这么流行,还不是人们日常生活必不可少的一部分,不是所有人都能看得起电影的,所以一定程度上是可以解释这种现象。
在第二主成份中,只有IMDB的占有权重很大,但是可以发现所有的指标变化方向都是一致的,呈正相关关系,只是反映没有第一主成份里那么明显,但是也从一定程度上说明了第一主成分说明的问题,不同的是总票房和获奖次数并不能准确说明电影是不是受观众喜爱,而IMDB评分则弥补了这一点。总的来说就是在拍摄电影时投入资金越多,拍摄时间越长,出产的电影越能获得观众的喜爱,从而获得高票房。
在成分图中可以更直观的看出总票房,获奖数,评分等与投入的金钱,时间之间的关系。成分图表明总票房,获奖数,IMDB评分,制作花费,拍摄时间这几项是[www.61k.com]密切相关的,且呈正相关关系,很好的验证了第一主成分,第二主成分中说明的问题。
4 总结
本文利用主成分分析法就卡梅隆的电影相关数据进行统计分析,得出了成功的电影背后少不了时间和金钱的投入。当然,不排除实际上还有很多影响因素,比如获奖次数,就《泰坦尼克号》来说一下激增到11项,这在电影史上是罕有的,也间接说明了《泰坦尼克号》是一部划时代的大作;《异形2》属于恐怖类科幻片,这类影片在当时想被奥斯卡奖提名都很难,而它是首部获奥斯卡奖的恐怖类科幻片,而且还不止一项;再说票房,北美历史上是发生过通货膨胀的,这也在一定程度上影响了票房的数据……但是计算结果还是可以反映一定问题的,不影响结论,在电影投入的越多,拍摄时间越长,完成的电影就越会得到观众喜欢,票房自然就会上去。卡梅隆导演就是深谙这个道理,他从不会在电影上吝啬,不论花多大代价,花多长时间,都会完成他的大作,一部《阿凡达》他酝酿了14年,耗资5亿美元(约合人民币27.2亿元),历时四年拍制,最终震撼了全世界,十年磨一剑,必是宝剑。
【参考文献】
[1]汪应洛.系统工程[M].北京:机械工业出版社,2009:54-60.
[2]方开泰.实用多元统计分析[M].上海:华东师范大学出版社,1989.
[3]崔凝凝,唐嘉庚.基于回归分析的中国电影票房影响因素研究[J].江苏商论,2012(08).
[4]王建陵.当代西方电影票房预测研究的发展演变[J].电影艺术,2009(01).
[责任编辑:陈双芹]
四 : matlab 实验05数据的统计分析
实验五 数据的统计分析
一、问题背景与实验目的
二、相关函数(命令)及简介
三、实验内容
四、自己动手
五、附录
一、问题背景与实验目的
在日常生活中我们会在很多事件中收集到一些数据(比如:考试分数、窗口排队人数、月用电量、灯泡寿命、测量误差、产品质量、月降雨量等数据),这些数据的产生一般都是随机的.这些随机数据乍看起来并没有什么规律,但通过数理统计的研究发现:这些随机数还是符合着某种分布规律的,这种规律被称为统计规律.
本实验旨在通过对概率密度函数曲线的直观认识、对数据分布的形态猜测、对某些概率分布的密度函数的参数估计(以正态为例)以及进行简单的正态假设检验,来揭示生活中的随机数据的一些统计规律.

二、相关函数(命令)及简介
1. 概率密度函数pdf系列.以normpdf( )为例,调用格式:
y=normpdf(x, mu,sigma),
计算参数为mu和sigma的样本数据x的正态概率密度函数.参数sigma必须为正.其中:mu为均值,sigma为标准差.
2. 参数估计fit系列.以normfit( )为例,调用格式:
[muhat, sigmahat, muci, sigmaci] = normfit(x, alpha),
对样本数据x进行参数估计,并计算置信度为100(1-alpha)%的置信区间.如alpha=0.01时,则给出置信度为99%的置信区间.不写明alpha,即表示alpha取0.05.
3.load( )函数.调用格式:
S = load('数据文件')
将纯数据文件(文本文件)中的数据导入Matlab,S 是双精度的数组,其行数、列数与数据文件相一致.
4. hist(x, m)函数:画样本数据x的直方图,m为直方图的条数,缺省值为10.
5. tabulate( )函数:绘制频数表.返回table矩阵,第一列包含x的值,第二列包含该值出现次数,最后一列包含每个值的百分比.
6.ttest(x,m,alpha) 函数:假设检验函数.此函数对样本数据x进行显著性水平为alpha的t假设检验,以检验正态分布样本x(标准差未知)的均值是否为m.h=1表示拒绝零假设,h=0表示不能拒绝零假设.
7.normplot(x)或weibplot(x) 函数:统计绘图函数,进行正态分布检验.
研究表明:如果数据是来自一个正态分布,则该线为一直线形态;如果它是来自其他分布,则为曲线形态.
完全类似地可探索以下一系列函数的用法与作用:
8.累积分布函数cdf系列,如:normcdf( ).
9.逆累积分布函数inv系列,如:norminv( ).
10.随机数发生函数rnd系列,如:normrnd( ).
11.均值与方差函数stat系列,如:normstat( ).
三、实验内容
1. 常见的概率分布的密度函数及其图形
1)常见概率分布的密度函数(20个,打√的10个将在后面作介绍)
序号
中文函数名
英文函数名
英文简写
备注
1
Beta分布
Beta
beta
2
二项分布
Binomial
bino
√
3
卡方分布
Chisquare
chi2
√抽样
4
指数分布
Exponential
exp
√
5
F分布
F
f
√抽样
6
Gamma分布
Gamma
gam
7
几何分布
Geometric
geo
√
8
超几何分布
Hypergeometric
hyge
9
对数正态分布
Lognormal
logn
10
负二项式分布
Negative Binomial
nbin
11
非中心F分布
Noncentral F
ncf
12
非中心t分布
Noncentral t
nct
13
非中心卡方分布
Noncentral Chi-square
ncx2
14
正态分布
Normal
norm
√
15
泊松分布
Poisson
poiss
√
16
瑞利分布
Rayleigh
rayl
17
T分布
T
t
√抽样
18
均匀分布
Uniform
unif
√
19
离散均匀分布
Discrete Uniform
unid
√
20
Weibull分布
Weibull
weib
2)常见概率分布的密度函数文字说明与图形演示:
(A)常见连续分布的密度函数
(1)正态分布
若连续型随机变量

的密度函数为:
则称
为服从正态分布的随机变量,记作 .特别地,称
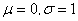
时的正态分布
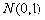
为标准正态分布,其概率分布的密度函数参见图1.一个非标准正态分布的密度函数参见图2中的虚线部分( ).
正态分布是概率论与数理统计中最重要的一个分布,高斯(Gauss)在研究误差理论时首先用正态分布来刻画误差的分布,所以正态分布又称高斯分布.一个变量如果是由大量微小的、独立的随机因素的叠加效果,那么这个变量一定是正态变量.比如测量误差、产品质量、月降雨量等都可用正态分布描述.
x=-8:0.1:8;
y=normpdf(x, 0, 1);
y1=normpdf(x, 1, 2);
plot(x, y, x, y1, ':' );
图1 标准正态分布 图2 标准正态与非标准正态
(2)均匀分布(连续)
若随机变量
的密度函数为

则称
服从区间 上的均匀分布(连续),记作 ,其概率分布的密度函数见参见图3
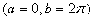
.
均匀分布在实际中经常使用,譬如一个半径为
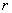
的汽车轮胎,因为轮胎上的任一点接触地面的可能性是相同的,所以轮胎圆周接触地面的位置
是服从 上的均匀分布,这只要看一看报废轮胎四周磨损程度几乎是相同的就可明白均匀分布的含义了.
x=-10:0.01:10;r=1;
y=unifpdf(x, 0, 2*pi*r);
plot(x, y);
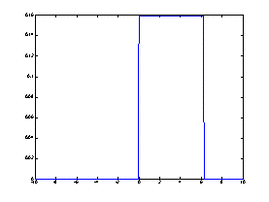
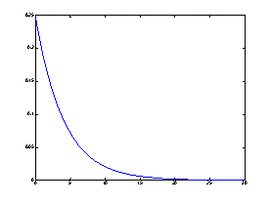
图3均匀分布(连续) 图4 指数分布
(3)指数分布
若连续型随机变量
的密度函数为:
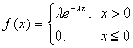
其中
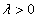
,
则称
为服从参数为
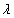
的指数分布的随机变量,记作 .
在实际应用问题中,等待某特定事物发生所需要的时间往往服从指数分布.如某些元件的寿命;某人打一个电话持续的时间;随机服务系统中的服务时间;动物的寿命等都常假定服从指数分布.
指数分布的重要性还在于它是具有无记忆性的连续型随机变量.即:设随机变量
服从参数为
的指数分布,则对任意的实数
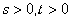
,有
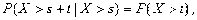
其概率分布的密度函数参见见图4 .
x=0:0.1:30;
y=exppdf(x, 4);
plot(x, y)
(B)常见离散分布的密度函数
(4)几何分布
在一个贝努里实验中,每次试验成功的概率为
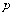
,失败的概率为
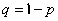
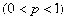
,设试验进行到第
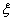
次才出现成功,则
的分布列为:
容易看到
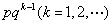
是几何级数
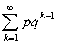
的一般项,于是人们称它为几何分布,其概率分布的密度函数参见图5 .
x=0:30;
y=geopdf(x, 0.5);
plot(x, y)
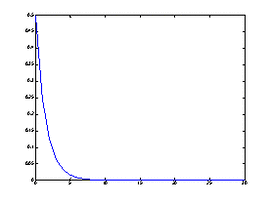
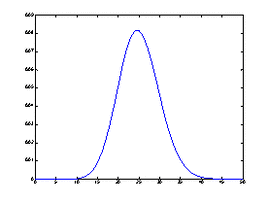
图5 几何分布 图6 二项分布
(5)二项分布
如果随机变量
的分布列为:
则这个分布称为二项分布,记为 .当
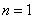
时的二项分布又称为0-1分布,分布律为
0
1
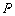
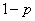
一般的二项分布的密度函数参见图6
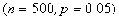
.
x=0:50;
y=binopdf(x, 500, 0.05);
plot(x, y);
(6)泊松(Poisson)分布
泊松分布是1837年由法国数学家泊松(Poisson S.D.1781-1840)首次提出的,其概率分布列是:

记为 ,其概率分布的密度函数参见图7
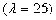
.
泊松分布是一种常用的离散分布,它与单位时间(或单位面积、单位产品等)上的计数过程相联系,譬如:单位时间内,电话总机接到用户呼唤次数;1平方米内,玻璃上的气泡数;一铸件上的砂眼数;在单位时间内,某种放射性物质分裂到某区域的质点数等等.
x=0:50;
y=poisspdf(x, 25);
plot(x, y);
注:对比二项分布的概率密度函数图可以发现,当二项分布的

与泊松分布
充分接近时,两图拟合程度非常高(图6与图7中的 ),直观地验证了泊松定理(泊松分布是二项分布的极限分布),请对比图6与图7.
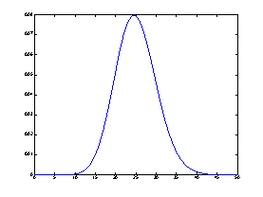

图7 泊松分布 图8 均匀分布(离散)
(7)均匀分布(离散)
如果随机变量
的分布列为:
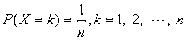
则这个分布称为离散均匀分布,记为 ,其概率分布的密度函数参见图8
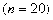
.
n=20;
x=1:n;
y=unidpdf(x, n);
plot(x, y, 'o-' );
(C)三大抽样分布的密度函数
(8) 分布
设随机变量 相互独立,且同服从正态分布
,则称随机变量 服从自由度为
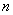
的 分布,记作 ,亦称随机变量

为 变量.其概率分布的密度函数参见图9
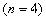
、图10
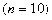
, 分布的密度函数解析式参见本章的附录表格.
x=0:0.1:20; x=0:0.1:20;
y=chi2pdf(x, 4); y=chi2pdf(x, 10);
plot(x, y); plot(x, y)
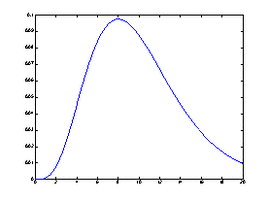
图9 分布
图10
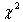
分布
(9)
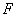
分布
设随机变量
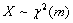
,

,且
与

相互独立,则称随机变量

服从自由度为
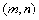
的
分布,记作
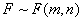
,其概率分布的密度函数参见图11,即
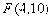
,
分布的密度函数解析式参见本章的附录表格.
x=0.01:0.1:8.01;
y=fpdf(x, 4, 10);
plot(x, y)
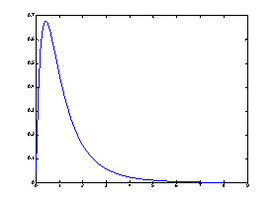
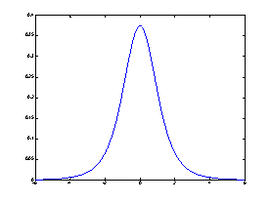
图11
分布 图12
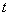
分布
(10)
分布
设随机变量
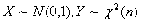
,且
与
相互独立,则称随机变量

服从于自由度为
的
分布,记作
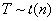
,其概率分布的密度函数参见图12,即
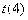
.
分布的密度函数解析式参见本章的附录表格.
细心的读者可能已经发现,图12的
分布图与图1、图2的正态分布十分相似.可以证明:当
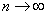
时,
分布趋于标准正态分布
.
x=-6:0.01:6;
y=tpdf(x, 4);
plot(x, y)
2.对给定数据画频数直方图(Histogram)或频数表(Frequency Table)
假定有若干个给定的数据集,它们满足上述10种分布之一,我们现在的任务就是利用画频数直方图等手段,确定它们到底服从哪一类分布.
例1:某一次书面考试的分数罗列如下,试画频数直方图.
鉴于数据的数量较大(包含有120个数据),可以先在一个文本文件中输入,保存为data1.txt.
75 69 100 80 70 74 78 59 72 73
63 79 69 81 62 87 80 66 86 75
70 85 85 64 78 65 69 67 78 72
60 50 57 83 77 79 78 74 67 83
71 67 71 74 84 74 83 75 73 74
60 91 65 69 80 63 86 67 73 80
74 68 72 80 95 61 77 85 82 71
80 76 83 69 87 76 72 69 66 86
74 87 59 81 88 75 83 71 77 81
88 67 67 76 71 76 79 79 90 62
80 85 81 75 72 57 94 91 83 78
66 74 79 74 82 79 87 76 81 68
x=load('data1.txt');
x=x(:);
hist(x)
结果参见图13.从图形形态上来看,图13较为接近图2所示的正态分布.

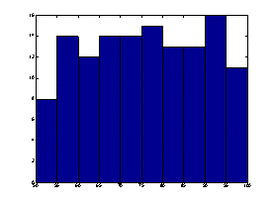
图13 例1的频数直方图 图14 例2的频数直方图
例2:某一次上机考试的分数罗列如下(data2.txt,包含有130个数据),试画频数直方图.
51 70 95 91 70 83 83 96 66 61
79 79 57 85 95 83 63 71 71 72
91 60 69 100 67 87 72 50 60 63
87 98 71 74 96 55 83 67 92 78
56 62 77 79 84 55 59 61 93 56
82 61 88 97 98 95 73 79 81 87
56 92 53 57 93 89 77 89 56 92
99 86 68 57 91 57 81 65 80 99
79 95 79 86 74 56 70 61 72 81
57 75 98 89 69 61 71 77 72 78
70 73 67 59 62 86 84 93 82 80
90 94 84 89 80 67 97 73 80 94
69 64 51 51 92 62 52 86 67 97
x=load('data2.txt');
x=x(:);
hist(x)
结果参见图14.图14看上去很接近图8所示的均匀分布(离散).
例3:以下给出上海1998年来的月降雨量的数据(data3.txt,包含有98个数据):
1184.4 1113.4 1203.9 1170.7 975.4 1462.3 947.8
1416.0 709.2 1147.5 935 1016.3 1031.6 1105.7
849.9 1233.4 1008.6 1063.8 1004.9 1086.2 1022.5
1330.9 1439.4 1236.5 1088.1 1288.7 1115.8 1217.5
1320.7 1078.1 1203.4 1480.0 1269.9 1049.2 1318.4
1192.0 1016.0 1508.2 1159.6 1021.3 986.1 794.7
1318.3 1171.2 1161.7 791.2 1143.8 1602.0 951.4
1003.2 840.4 1061.4 958.0 1025.2 1265.0 1196.5
1120.7 1659.3 942.7 1123.3 910.2 1398.5 1208.6
1305.5 1242.3 1572.3 1416.9 1256.1 1285.9 984.8
1390.3 1062.2 1287.3 1477.0 1011.9 1217.7 1197.1
1143.0 1018.8 1243.7 909.3 1030.3 1124.4 811.4
820.9 1184.1 1107.5 991.4 901.7 1176.5 1113.5
1272.9 1200.3 1508.7 772.3 813.0 1392.3 1006.2
x=load('data3.txt');
x=x(:);
hist(x)
结果参见图15.图15看上去很接近图10所示的 分布.

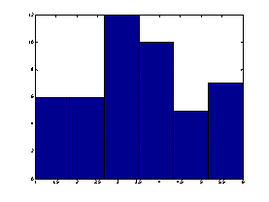
图15 例3的频数直方图 图16 例4的频数直方图
在重复数据较多的情况下,我们也可以利用Matlab自带的函数tabulate( )产生频数表,并以频数表的形式来发掘数据分布的规律.
例4:给出以下数据:(data4.txt,含有46个数据)
2 3 6 4 1 5 1 2 3 1 4 2 3 1 3 3 2 3 1 6 4 6 4
6 5 4 3 6 4 3 3 3 3 4 4 5 6 2 1 2 3 4 5 6 5 4
则:
x=load('data4.txt');
x=x(:);
tabulate(x)
hist(x, 6)
Value Count Percent
1 6 13.04%
2 6 13.04%
3 12 26.09%
4 10 21.74%
5 5 10.87%
6 7 15.22%
结果参见图16.图16看上去好象没有什么规律可循.
例5:现累积有100次刀具故障记录,当故障出现时该批刀具完成的零件数如下:(data5.txt)
459 362 624 542 509 584 433 748 815 505
612 452 434 982 640 742 565 706 593 680
926 653 164 487 734 608 428 1153 593 844
527 552 513 781 474 388 824 538 862 659
775 859 755 49 697 515 628 954 771 609
402 960 885 610 292 837 473 677 358 638
699 634 555 570 84 416 606 1062 484 120
447 654 564 339 280 246 687 539 790 581
621 724 531 512 577 496 468 799 544 645
764 558 378 765 666 763 217 715 310 851
x=load('data5.txt');
x=x(:);
hist(x) %%结果参见图17,很象图2所示的正态分布
figure
histfit(x) %%结果参见图18,加入了较接近的正态分布的密度曲线
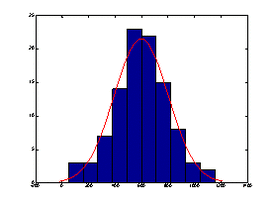
图17 例5的hist(x) 图18 例5的histfit(x)
3. 参数估计
当我们可以基本确定数据集
符合某种分布时,下一步我们就该确定这个分布的参数了.由于正态分布情况发生的比较多,故一般我们首先考虑的分布将是正态分布.考虑最多的也是正态分布情况.
对于未知参数的估计,可分两种情况:点估计与区间估计.
(1)点估计:构造样本
与某个统计量有关的一个函数,作为该统计量的一个估计,称为点估计.Matlab统计工具箱中,一般采用最大似然估计法给出参数的点估计.可以证明:
① 正态分布
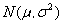
中,
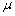
最大似然估计是

,
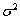
的最大似然估计是
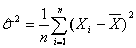
;
② 泊松分布

的
最大似然估计是
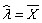
;
③ 指数分布
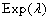
的
最大似然估计是
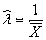
,等等.
例6:已知上述例1的数据服从正态分布
,试求出
和
的值.
解: x=load('data1.txt');
x=x(:);
[mu, sigma] = normfit(x)
mu =
75.3417
sigma =
8.8768
因此,
=mu=75.3412,
=sigma2=8.87682=78.7982.
(2)区间估计:构造样本
与某个统计量有关的两个函数,作为该统计量的下限估计与上限估计,下限与上限一般能够构成一个区间.这个区间作为该统计量的估计,称为区间估计.Matlab统计工具箱中,一般也采用最大似然估计法给出参数的区间估计.
例7:已知上述例1的数据集
服从正态分布
,试求出
和
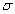
的置信度为95%的区间估计.
解: x=load('data1.txt');
x=x(:);
[mu, sigma muci, sigmaci] = normfit(x)
mu =
75.3417
sigma =
8.8768
muci =
73.7371
76.9462
sigmaci =
7.8781
10.1678
因此,73.7371
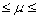
76.9462,7.8781

10.1678.
例8:从自动机床加工的同类零件中抽取16件,测得长度值为(data6.txt):
12.15 12.12 12.01 12.08 12.09 12.16 12.06 12.13
12.07 12.11 12.08 12.01 12.03 12.01 12.03 12.06
已知零件长度服从正态分布
,求零件长度的均值
和标准差
的置信度为99%的置信区间.
解: x=load('data6.txt');
x=x(:);
[mu, sigma, muci, sigmaci] = normfit(x, 0.01)
mu =
12.0750
sigma =
0.0494
muci =
12.0386
12.1114
sigmaci =
0.0334
0.0892
其中muci(1)、muci(2)分别是平均值
在99%置信度下的上下限;而sigmaci(1)、sigmaci(2)分别是标准差
在99%置信度下的上下限.
4.正态假设检验
对总体的分布律或分布参数作某种假设,根据抽取的样本观察值,运用数理统计的分析方法,检验这种假设是否正确,从而决定接受假设或拒绝假设,这就是假设检验问题.这里仅以正态假设检验为例,来说明假设检验的基本过程.
正态假设检验的一般过程是:
(1)对比正态分布的概率密度函数图,判断某统计量的分布可能服从正态分布;
(2)利用统计绘图函数normplot( )或weibplot( )进行正态分布检验.
(3)假设检验:利用Matlab统计工具箱给出的常用的假设检验方法的函数ttest(x,m,alpha),进行显著性水平为alpha的t假设检验,以检验正态分布样本x(标准差未知)的均值是否为m.运行结果中,当h=1时,表示拒绝零假设;当h=0时,表示不能拒绝零假设.
例9:试说明例5所示的刀具的使用寿命服从正态分布,并且说明在方差未知的情况下其均值m取为597是否合理?
解:(1)对比正态分布的概率密度函数图(图17、图18)以及对正态分布的描述(一个变量如果是由大量微小的、独立的随机因素的叠加效果,那么这个变量一定是正态变量.比如测量误差、产品质量等都可用正态分布描述),可得初步结论:该批刀具的使用寿命可能服从正态分布.
(2)利用统计绘图函数normplot(x) 进行分布的正态性检验.由于:
x=load('data5.txt');
x=x(:);
normplot(x)
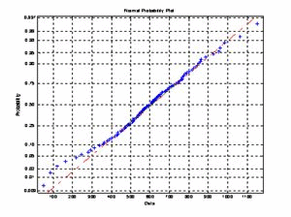
图19 刀具寿命分布正态性检验
结果如图19所示,经观察这100个离散点非常靠近倾斜直线段,图形为线性的,因此可得出结论:该批刀具的使用寿命近似服从正态分布.
(3)利用函数ttest(x,m,alpha)进行显著性水平为alpha的t假设检验.由于:
x=load('data5.txt');
x=x(:);
h=ttest(x,597,0.05)
得:h = 0
检验结果:h=0,表示不拒绝零假设,说明所提出的假设“寿命均值为597”是合理的.
读者可以验证:当执行h=ttest(x,555,0.05),将得到h = 1,表示拒绝零假设.请读者自行解释此结果的含义.
四、自己动手
1.了解本实验中虽已提及但没有详细介绍的其余10种概率分布的密度函数,如Beta分布、Gamma分布、Weibull分布等,写出它们的概率分布的密度函数表达式(本实验的附录中已经列出一部分),并画出相应的图形.
2.写出本实验所列出的10种概率累积分布函数表达式,并画出相应的概率累积分布函数图形.
3.用tabulate( )函数将例1、例2的分数数据按频数表的方式进行统计,每5分为一个分数段(可参见例4),观察数据分布有什么规律.
4.用weibplot(x)函数进行例9的正态分布检验,比较与例9的差别.
5.例3给出的上海1998年来的月降雨量的数据(data3.txt) 看上去很接近图10所示的
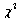
分布,但
分布好象没有直接进行参数估计的函数,试寻求对此数据进行参数估计的可能方法.
6.向例3给出的上海1998年来的月降雨量的数据(data3.txt) 中“补充”一些数据,使其看上去很接近正态分布,并求此时的均值
和标准差
的点估计与置信度为97%的区间估计.
7.在第6题基础上,说明在方差未知的情况下,其均值
取为1150是否合理?
8.ttest( )函数的完整用法是:[h,sig,ci] = ttest(x,m,alpha,tail)
其中 sig为观察值的概率,当sig为小概率时则对零假设提出质疑(这里的零假设为:
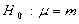
.也可以是其它形式,例如:

、
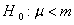
等);ci为真正均值μ的1-alpha置信区间;不写tail,表示其取值为0.
说明:若h=0,表示在显著性水平alpha下,不能拒绝零假设;若h=1,表示在显著性水平alpha下,可以拒绝零假设.
若 tail=0,表示备择(对立)假设为:

(默认,双边检验);若tail=1,表示备择(对立)假设为:
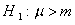
(单边检验);若tail=-1,表示备择(对立)假设为:

(单边检验).
试用该函数求解如下问题:某种电子元件的寿命X(以小时计)服从正态分布,
、
均未知.现测得16只元件的寿命如下:
159 280 101 212 224 379 179 264 222 362 168 250
149 260 485 170
问当取alpha=0.05时:(1)是否有理由认为元件的平均寿命不大于225(小时)?(2)是否有理由认为元件的平均寿命不大于295(小时)?
9.查看函数 ttest2( )的用法,并用于处理Matlab 统计工具中的数据文件gas.mat.回答问题:一月份油价price1与二月份油价price2的均值是否相同?
五、附录
附录:Matlab中的其它部分概率分布函数名及其数学意义列表:
函数名
对应分布
数学意义
batapdf
Beta分布
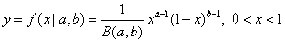
chi2pdf
卡方分布
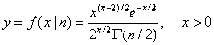
fpdf
F分布

gampdf
Gamma分布
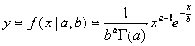
,
raylpdf
瑞利分布
,
tpdf
t分布
weibpdf
Weibull分布
本文标题:
数据统计分析表-医疗编辑用户体验重中之重分析后台数据统计 本文地址:
http://www.61k.com/1131297.html