一 : Hyper-V装CentOS需要的Linux Integration Components的步骤分享
步骤如下:
首先需要kernel-devel和gcc
我的是64位的CentOS,还需要adjtimex RPM确保时间准确性
因为没网,安装就得从光盘安装。要将yum的repo设置为光盘
于是
# cd /etc.d

两个repo
CentOS内有两个repo
CentOS-及CentOS-
是在线更新repo
是输入设备repo
先将的CentOS-更名,让系统跳过该repo
# mv CentOS--.bk
设定repo来源,baseurl设为光驱目录 /mnt/cdrom,enabled为1代表启动
# vim CentOS-
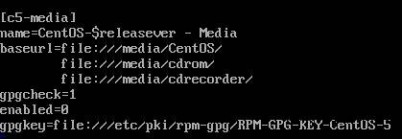
vim CentOS-
改成
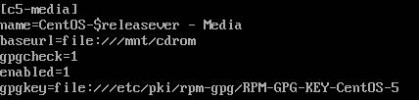
改成
把CentOS的碟载入本虚拟机光驱
然后挂载到目录
# mkdir /mnt/cdrom
# mount /dev/cdrom /mnt/cdrom

挂载到目录
安装kernel-devel套件
# yum install kernel-devel -y
完成后安装gcc套件
# yum install gcc -y
64位系统还需要安装adjtimex RPM
# rpm –ivh /mnt/cdrom/Centos/adjtimex-1.20-2.1.x86_64.rpm
然后umount 原始安裝光碟
# umount /mnt/cdrom
在Hyper-V控制器里面把微软官网
Linux Integration Services v2.1 for Windows Server 2008 Hyper-V R2
地址.aspx?displaylang=zh-tw&FamilyID=eee39325-898b-4522-9b4c-f4b5b9b64551
解压得到的ISO加载到光驱
然后
# mount -t iso9660 /dev/cdrom /mnt/cdrom
# cp /mnt/cdrom/* /opt/linux -R
然后去安装就行了
# cd /opt/linux_ic_v21_rtm
# make
# make install
最后重启
# reboot
配置好了可以ifconfig看看

ifconfig看看
名称分别为ifcfg-eth0,ifcfg-eth1….如果你有一块CentOS网卡IP,就只有ifcfg-eth0一个文件,如果你有两块或者两块以上的CentOS网卡IP,就会有ifcfg-eth1、ifcfg-eth2等文件的出现。
。www.61k.com)文件结构:
1 vim /etc/sysconfig/network-scripts/ifcfg-teh0
2 .启动服务service network restart
CentOS网卡编辑主机用的DNS服务器信息命令:vim /etc

二 : 娘在,儿必归
无论我现在怎么样,还是希望以后会怎么样,都应当归功于我天使一般的母亲。我记得母亲的那些祷告,它们一直伴随着我,且将陪伴我一生。
———亚伯拉罕·林肯
娘亲,已年逾花甲。好不容易把我们姐弟四个拉扯大,又老了。她是地地道道的农民子女,湖北巴东人氏。面对清贫如水坚硬如山的生活,娘亲流淌的是汗水,而不是泪。她懂得奋斗、懂得感恩、懂得怎么样用朴实的语言构筑属于她与儿女们大气如画、平静似水、质朴纯真的现实生活。
娘亲不善言辞。“孩子,世事如棋局局新,人无远虑,必有近忧”,是平时娘亲最爱说的口头禅,听说还是来源于外祖母的原版“拷贝”。小时候,我们姐弟四个都很调皮,常常是“早出晚归”玩得太阳下山了才回家,每次都能听到娘亲没完没了地用这句话唠叨我们姐弟四个。前不久,无意中听见已为人母的姐姐也用这句话唠叨其贪玩的儿子时,我才发觉她已经“中毒”很深。
读书时,很庆幸,没有在娘亲的棍棒下生活、学习。初中、高中、大学都离家较远,每次回家,娘亲都高兴得不知所措。“没吃饭吧?”这似乎是娘亲固定的欢迎词。继而,厨房里很快想起锅碗瓢盆的叮当声。为儿女做饭,可能是天下所有母亲难舍的情结吧?不知道该如何拦住娘亲,只有傻站在锅台前看着娘亲为我炒腊肉洋芋片。“孩子,世事如棋局局新,人无远虑,必有近忧啊,乡里娃没权没势,就得靠自己的勤快,多学点书,到时候也就不用求别人哒......”,我总是似懂非懂的应着,眼睛滴溜溜着盯着快炒熟的洋芋片。
娘亲活了大半辈子,只进过城一次。( 文章阅读网:www.61k.com )
那是我读大三时。由于寒暑假我都在学校勤工俭学,两年没回家。娘亲就闹着要去学校看看我,天不亮娘亲就提着大袋小袋出发了,里面装得是鸡蛋、红枣、腊肉,还有几十斤洋芋。姐姐弟弟都说城里有,不用带,娘亲却执意不肯。娘亲从没坐过车船,也没有见过奔涌的大江,走完三四十里山路,再到车船上折腾十来个小时,所以就一路晕着吐着,吐着晕着在第三天上午才到达城里。当时,我在报社实习,娘亲一到就迫不及待地给我打了电话,又是紧张又是激动,后来听她说,拔了几次才打通。接电话的是位声音“噶蹦脆”的女孩子。她听不懂娘亲的方言,急了,就要娘亲用普通话。娘亲小心翼翼地说不会。“说英语,也行呀。”她建议。娘亲愣了,只好放下听筒。我接到娘亲时,她已经在寒冷的街道上站了四个多小时。
工作啦,远离在家乡的城市,一年只能回家一次,偶能成行两回,就算是很奢侈啦,手机就成了我和娘亲沟通的唯一工具。十一长假,我回去啦,在娘亲给我继续炒腊肉洋芋片时,我才得以有时间仔细端详一下母亲的背影:年过半百,背已微驼,发丝凌乱,娘亲确实无可奈何地老了。再慈祥的爱也难挡住岁月的匆匆。厨房里热气渐浓,娘亲也模糊在缭绕的烟雾里。
娘亲平凡地过着日子,她放心不下的是田里的庄稼和远在异乡的孩子们。她一辈子也只有这么两件最令她得意作品:弯着腰的稻穗,直着腰的儿女!
又快到春节了,朋友们又都开始讨论这个春节怎么过了。有的说泡温泉,有的说去旅游,有的说留守工厂,当问及我时,又都恍然大悟,说你肯定是回老家过年。
是的,每年春节,我都必定回家过年。
因为,娘在,儿必归。
后记:
又是一年团圆之际,儿子想把这段文字献给您,平平淡淡,但有心是真。
娘我想对你说,漫漫长路,虽然儿子与你相依相伴的时间越来越少,但是,儿子一直都会默默地为您祝福,在黄昏,在黎明,在我寻梦的每一个角落。
娘我想对您说,有您的牵挂,我想儿子会更懂事,有我的念思,我想您会更幸福安康!
最后说一句,愿天下所有爹娘都幸福快乐!年关即近,愿远在他乡的儿女早日归家。
写文/青衣墨豆
三 : 75面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)
面板数据分析简要步骤与注意事项
(面板单位根—面板协整—回归分析)
步骤一:分析数据的平稳性(单位根检验)
按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。
因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。
由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程, Hadri Z统计量的检验原假设为不存在普通的单位根过程。
有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验LLC(Levin-Lin-Chu)检验和不同根单位根检验Fisher-ADF检验(注:对普通序列(非面板序列)的单位根检验方法则常用ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我们说此序列是平稳的,反之则不平稳。
如果我们以T(trend)代表序列含趋势项,以I(intercept)代表序列含截距项,T&I代表两项都含,N(none)代表两项都不含,那么我们可以基于前面时序图得出的结论,在单位根检验中选择相应检验模式。
但基于时序图得出的结论毕竟是粗略的,严格来说,那些检验结构均需一一检验。具体操作可以参照李子奈的说法:ADF检验是通过三个模型来完成,首先从含有截距和趋势项的模型开始,再检验只含截距项的模型,最后检验二者都不含的模
型。并且认为,只有三个模型的检验结果都不能拒绝原假设时,我们才认为时间序列是非平稳的,而只要其中有一个模型的检验结果拒绝了零假设,就可认为时间序列是平稳的。
此外,单位根检验一般是先从水平(level)序列开始检验起,如果存在单位根,则对该序列进行一阶差分后继续检验,若仍存在单位根,则进行二阶甚至高阶差分后检验,直至序列平稳为止。我们记I(0)为零阶单整,I(1)为一阶单整,依次类推,I(N)为N阶单整。
步骤二:协整检验或模型修正
情况一:如果基于单位根检验的结果发现变量之间是同阶单整的,那么我们可以进行协整检验。协整检验是考察变量间长期均衡关系的方法。所谓的协整是指若两个或多个非平稳的变量序列,其某个线性组合后的序列呈平稳性。此时我们称这些变量序列间有协整关系存在。因此协整的要求或前提是同阶单整。
但也有如下的宽限说法:如果变量个数多于两个,即解释变量个数多于一个,被解释变量的单整阶数不能高于任何一个解释变量的单整阶数。另当解释变量的单整阶数高于被解释变量的单整阶数时,则必须至少有两个解释变量的单整阶数高于被解释变量的单整阶数。如果只含有两个解释变量,则两个变量的单整阶数应该相同。
也就是说,单整阶数不同的两个或以上的非平稳序列如果一起进行协整检验,必然有某些低阶单整的,即波动相对高阶序列的波动甚微弱(有可能波动幅度也不同)的序列,对协整结果的影响不大,因此包不包含的重要性不大。而相对处于最高阶序列,由于其波动较大,对回归残差的平稳性带来极大的影响,所以如果协整是包含有某些高阶单整序列的话(但如果所有变量都是阶数相同的高阶,此时也被称作同阶单整,这样的话另当别论),一定不能将其纳入协整检验。 协整检验方法的文献综述:(1)Kao(1999)、Kao and Chiang(2000)利用推广的DF和ADF检验提出了检验面板协整的方法,这种方法零假设是没有协整关系,并且利用静态面板回归的残差来构建统计量。(2)Pedron(1999)在零假设是在动态多元面板回归中没有协整关系的条件下给出了七种基于残差的面板协整检验方法。和Kao的方法不同的是,Pedroni的检验方法允许异质面板的存在。(3)Larsson et al(2001)发展了基于Johansen(1995)向量自回归的似然检验的面板协整检验方法,这种检验的方法是检验变量存在共同的协整的秩。
主要采用的是Pedroni、Kao、Johansen的方法。
通过了协整检验,说明变量之间存在着长期稳定的均衡关系,其方程回归残差是平稳的。因此可以在此基础上直接对原方程进行回归,此时的回归结果是较精确的。
这时,我们或许还想进一步对面板数据做格兰杰因果检验(因果检验的前提是变量协整)。但如果变量之间不是协整(即非同阶单整)的话,是不能进行格兰杰因果检验的,不过此时可以先对数据进行处理。引用张晓峒的原话,“如果y和x不同阶,不能做格兰杰因果检验,但可通过差分序列或其他处理得到同阶单整序列,并且要看它们此时有无经济意义。”
下面简要介绍一下因果检验的含义:这里的因果关系是从统计角度而言的,即是通过概率或者分布函数的角度体现出来的:在所有其它事件的发生情况固定不变的条件下,如果一个事件X的发生与不发生对于另一个事件Y的发生的概率(如
果通过事件定义了随机变量那么也可以说分布函数)有影响,并且这两个事件在时间上又有先后顺序(A前B后),那么我们便可以说X是Y的原因。考虑最简单的形式,Granger检验是运用F-统计量来检验X的滞后值是否显著影响Y(在统计的意义下,且已经综合考虑了Y的滞后值;如果影响不显著,那么称X不是Y的“Granger原因”(Granger cause);如果影响显著,那么称X是Y的“Granger原因”。同样,这也可以用于检验Y是X的“原因”,检验Y的滞后值是否影响X(已经考虑了X的滞后对X自身的影响)。
Eviews好像没有在POOL窗口中提供Granger causality test,而只有unit root test和cointegration test。说明Eviews是无法对面板数据序列做格兰杰检验的,格兰杰检验只能针对序列组做。也就是说格兰杰因果检验在Eviews中是针对普通的序列对(pairwise)而言的。你如果想对面板数据中的某些合成序列做因果检验的话,不妨先导出相关序列到一个组中(POOL窗口中的Proc/Make Group),再来试试。
情况二:如果如果基于单位根检验的结果发现变量之间是非同阶单整的,即面板数据中有些序列平稳而有些序列不平稳,此时不能进行协整检验与直接对原序列进行回归。但此时也不要着急,我们可以在保持变量经济意义的前提下,对我们前面提出的模型进行修正,以消除数据不平稳对回归造成的不利影响。如差分某些序列,将基于时间频度的绝对数据变成时间频度下的变动数据或增长率数据。此时的研究转向新的模型,但要保证模型具有经济意义。因此一般不要对原序列进行二阶差分,因为对变动数据或增长率数据再进行差分,我们不好对其冠以经济解释。难道你称其为变动率的变动率?
步骤三:面板模型的选择与回归
面板数据模型的选择通常有三种形式:
一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。一种是固定效应模型(Fixed Effects Regression Model)。如果对于不同的截面或不同的时间序列,模型的截距不同,则可以采用在模型中添加虚拟变量的方法估计回归参数。一种是随机效应模型(Random Effects Regression Model)。如果固定效应模型中的截距项包括了截面随机误差项和时间随机误差项的平均效应,并且这两个随机误差项都服从正态分布,则固定效应模型就变成了随机效应模型。
在面板数据模型形式的选择方法上,我们经常采用F检验决定选用混合模型还是固定效应模型,然后用Hausman检验确定应该建立随机效应模型还是固定效应模型。
检验完毕后,我们也就知道该选用哪种模型了,然后我们就开始回归:
在回归的时候,权数可以选择按截面加权(cross-section weights)的方式,对于横截面个数大于时序个数的情况更应如此,表示允许不同的截面存在异方差现象。估计方法采用PCSE(Panel Corrected Standard Errors,面板校正标准误)方法。Beck和Katz(1995)引入的PCSE估计方法是面板数据模型估计方法的一个创新,可以有效的处理复杂的面板误差结构,如同步相关,异方差,序列相关等,在样本量不够大时尤为有用。
这是我在查阅各种资料后得出的关于面板数据的总结,最近在做面板的实证论文,所以需要这个,欢迎大家继续扩充,只要是关于面板的都行,关于具体如何在Eviews6中实现的更好,不甚感激。
----------
*横截面的异方差与序列的自相关性是运用面板数据模型时可能遇到的最为常见的问题,此时运用OLS可能会产生结果失真,因此为了消除影响,对我国东、中、西部地区的分析将采用不相关回归方法( SeeminglyUnrelated Regression, SUR)来估计方程。而对于全国范围内的估计来说,由于横截面个数大于时序个数,所以采用截面加权估计法(Cross SectionWeights, CSW) 。
*一般而言,面板数据可用固定效应(fixed effect) 和随机效应(random effect) 估计方法,即如果选择固定效应模型,则利用虚拟变量最小二乘法(LSDV) 进行估计;如果选择随机效应模型,则利用可行的广义最小二乘法(FGLS) 进行估计
(Greene ,2000) 。它可以极大限度地利用面板数据的优点,尽量减少估计误差。至于究竟是采用固定效应还是随机效应,则要看Hausman 检验的结果。
*单位根检验:在进行时间序列的分析时,研究者为了避免伪回归问题,会通过单位根检验对数据平稳性进行判断。但对于面板数据则较少关注。随着面板数据在经济领域应用,对面板数据单位根的检验也逐渐引起重视。面板数据单位根的检验主要有Levin、Lin 和Chu 方法(LLC 检验) (1992 ,1993 ,2002) 、Im、Pesaran 和Shin 方法( IPS 检验) (1995 ,1997) 、Maddala 和Wu 方法(MW检验) (1999) 等。 *协整检验:协整检验是考察变量间长期均衡关系的方法。在进行了各变量的单位根检验后,如果各变量间都是同阶单整,那么就可以进行协整检验了。面板协整检验理论目前还不成熟,仍然在不断的发展过程中,目前的方法主要有:
(1)Kao(1999)、Kao and Chiang(2000)利用推广的DF和ADF检验提出了检验面板协整的方法,这种方法零假设是没有协整关系,并且利用静态面板回归的残差来构建统计量。
(2)Pedron(i1999)在零假设是在动态多元面板回归中没有协整关系的条件下给出了七种基于残差的面板协整检验方法。和Kao的方法不同的是,Pedroni的检验方法允许异质面板的存在。
(3)Larsson et a(l2001)发展了基于Johansen(1995)向量自回归的似然检验的面板协整检验方法。这种检验的方法是检验变量存在共同的协整的秩。
*一般的顺序是:先检验变量的平稳性,当变量均为同阶单整变量时,再采用协整检验以判别变量间是否存在长期均衡关系。如果变量间存在长期均衡的关系,我们可以通过误差修正模型(ECM) 来检验变量间的长期因果关系;如变量间不存在协整关系,我们将对变量进行差分,然后通过向量自回归模型(VAR),检验变量间的短期因果关系。
四 : Hyper-V装CentOS需要的Linux Integration Components的步骤分享
步骤如下:
首先需要kernel-devel和gcc
我的是64位的CentOS,还需要adjtimex RPM确保时间准确性
因为没网,安装就得从光盘安装。要将yum的repo设置为光盘
于是
# cd /etc/yum.repo.d

两个repo
CentOS内有两个repo
CentOS-Base.repo及CentOS-Media.repo
Base.repo是在线更新repo
Media.repo是输入设备repo
先将的CentOS-Base.repo更名,让系统跳过该repo
# mv CentOS-Base.repo CentOS-Base.repo.bk
设定repo来源,baseurl设为光驱目录 /mnt/cdrom,enabled为1代表启动
# vim CentOS-Media.repo

vim CentOS-Media.repo
改成

改成
把CentOS的碟载入本虚拟机光驱
然后挂载到目录
# mkdir /mnt/cdrom
# mount /dev/cdrom /mnt/cdrom
![]()
挂载到目录
安装kernel-devel套件
# yum install kernel-devel -y
完成后安装gcc套件
# yum install gcc -y
64位系统还需要安装adjtimex RPM
# rpm –ivh /mnt/cdrom/Centos/adjtimex-1.20-2.1.x86_64.rpm
然后umount 原始安裝光碟
# umount /mnt/cdrom
在Hyper-V控制器里面把微软官网
Linux Integration Services v2.1 for Windows Server 2008 Hyper-V R2
地址:http://www.microsoft.com/downloads/details.aspx?displaylang=zh-tw&FamilyID=eee39325-898b-4522-9b4c-f4b5b9b64551
解压得到的ISO加载到光驱
然后
# mount -t iso9660 /dev/cdrom /mnt/cdrom
# cp /mnt/cdrom/* /opt/linux -R
然后去安装就行了
# cd /opt/linux_ic_v21_rtm
# make
# make install
最后重启
# reboot
配置好了可以ifconfig看看

ifconfig看看
名称分别为ifcfg-eth0,ifcfg-eth1….如果你有一块CentOS网卡IP,就只有ifcfg-eth0一个文件,如果你有两块或者两块以上的CentOS网卡IP,就会有ifcfg-eth1、ifcfg-eth2等文件的出现。
文件结构:
1 vim /etc/sysconfig/network-scripts/ifcfg-teh0
2 .启动服务service network restart
CentOS网卡编辑主机用的DNS服务器信息命令:vim /etc/resolv.conf
五 : 开始做SEO的6个重要步骤分析
Seo讲求更多是技巧与策略,还有就是态度;但凡是要沉下心搞优化,在学习中多实践,在实践中多思考,会进步的更快,偶做优化那么长时间,有过迷茫有过兴奋,有过惊喜也有过教训,这里向初涉优化的朋友们分享一下自己的几点心得,我喜欢交流,与推友交流、与客户交流有时候真的会让我们事半功倍,快速提升!61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1