一 : 详解123.125.71.*百度蜘蛛IP段
今天在我的一个网站日志中看到了这么一个ip,当时是比较紧张的,之前百度一位工程师说过这是属于降权蜘蛛,后来我问了很多朋友也查了大量的资料,证实这不是百度降权蜘蛛,但仍然比较危险,这个百度蜘蛛为考察期的百度蜘蛛。
如果你是新站,很正常
任何一个新战访问的百度蜘蛛都是123开头的,所以你不必担心,只要你好好检查你的原创内容,并且不要随便更改网站的架构,相信很快就能脱离百度考察期,我们平时常说的百度沙盒。如果随便改网站的架构,你的考察期可能会拖长很长时间,因为百度蜘蛛也不知道你结构究竟什么时候能确定,最主要就是为了确定你到底要给用户一个什么样的体验。用户体验很重要。
如果你是老站,那就太危险了
一般来说,你如果是老站的话,并且曾经日志中是220开头的,这个时候如果百度蜘蛛访问的ip变成了123.125.71.*这个ip段,那就需要非常谨慎了,你需要看看你近段时间是不是采集了大量的文章,如果是,需要尽快的删除,并且更新大量的原创文章。是不是你的网站结构变了,这个也是有很大的影响,如果架构变了,就有可能被当做新站处理。还有一点就是是否作弊了,关于哪些行为属于作弊的,下次为大家详细分析。
本文由东庄家园站长www.iccdz.com原创写作,转载请注明文章来源
二 : 关注百度蜘蛛IP 近距离了解站点收录情况
众所周知,百度蜘蛛,是百度搜索引擎的一个自动程序,它的作用是访问收集整理互联网上的网页、图片、视频 等内容,然后分门别类建立索引数据库, 使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。分析和了解百度蜘蛛你可以很直观的掌握自己站点收录情况,当你了解百度蜘蛛以及其对应蜘 蛛IP的含义后,你再也不必要在不知情的情况因为站点迟迟不为百度收录而烦恼,也不会因为百度短暂的快照不更新而放弃原本一颗坚持建站的心,那么剩下的就 只有肯勤奋的付出,坚持原创,坚持外链,站点可观的收录和理想的排名将成为水到渠成的事,这一切只因为你深刻了解百度蜘蛛。
那么我们通过什么方式去了解一个个搜索引擎的蜘蛛程序呢?
其实很简单,每一个蜘蛛程序就犹如一个用户,他对任意站点的访问,都尤其访问的轨迹,linux主机下我们完全可以透过网站主机日志文件去观察和分 析各大搜索引擎的蜘蛛来访情况,并根据来访Ip去分析和判断当前站点具体收录情况,了解和分析站点目前所存在的问题,诸如:URL是否符合蛛蛛抓爬习 惯,robots.txt文件是否设置合理,网站结构是否合理等。本文主要以百度蜘蛛作为分析和介绍对象,从而帮助站长能更好的针对自己的站点进行SEO优化和推广。
首先,我们先来看看一下具体的日志截图(该截图来源于本博客网站)
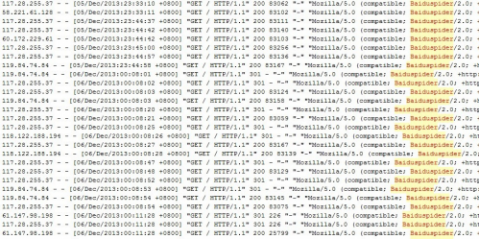
百度蜘蛛IP分析
透过以上截图可以得知百度蜘蛛来访时以Baiduspider名称显现,并且来访IP存在多个,那么多的百度蜘蛛IP到底分别是代表啥呢?
在百度站长平台《百度spider介绍》一文中已有相应的解释、并且清楚的说明百度不同的产品使用不同的user-agent

本人在此也不具体分解,有了解必要的朋友可以去参看原文,原文地址:http://zhanzhang.baidu.com/wiki/161
今天想给大家介绍的主要是百度蜘蛛IP、从本博客的站点日志截图可看出,Baiduspider是多个IP来访的,那么具体分
为哪几类蜘蛛、具体有代表啥意义呢?
一、代表性沙盒蜘蛛IP:
123.125.68.* 这个蜘蛛经常来,别的来的少,表示网站可能要进入沙盒了,或被者降权。
220.181.68.* 每天这个IP 段只增不减很有可能进沙盒或K站。
二、代表性正常蜘蛛IP:
220.181.7.*、123.125.66.* 代表百度蜘蛛IP造访,准备抓取你东西。
121.14.89.* 这个ip段作为度过新站考察期。
203.208.60.* 这个ip段出现在新站及站点有不正常现象后。
210.72.225.* 这个ip段不间断巡逻各站
125.90.88.* 广东茂名市电信也属于百度蜘蛛IP 主要造成成分,是新上线站较多,还有使用过站长工具,或SEO综合
检测造成的。
220.181.108.95这个是百度抓取首页的专用IP,如是220.181.108段的话,基本来说你的网站会天天隔夜快照,绝对
错不了的,我保证。
220.181.108.92 同上98%抓取首页,可能还会抓取其他 (不是指内页)220.181段属于权重IP段此段爬过的文章或首页
基本24小时放出来。
123.125.71.106 抓取内页收录的,权重较低,爬过此段的内页文章不会很快放出来,因不是原创或采集文章。
220.181.108.91属于综合的,主要抓取首页和内页或其他,属于权重IP 段,爬过的文章或首页基本24小时放出来。
220.181.108.75重点抓取更新文章的内页达到90%,8%抓取首页,2%其他。权重IP 段,爬过的文章或首页基本24
小时放出来。
220.181.108.86专用抓取首页IP 权重段,一般返回代码是304 0 0 代表未更新。
123.125.71.95 抓取内页收录的,权重较低,爬过此段的内页文章不会很快放出来,因不是原创或采集文章。
123.125.71.97 抓取内页收录的,权重较低,爬过此段的内页文章不会很快放出来,因不是原创或采集文章。
220.181.108.89专用抓取首页IP 权重段,一般返回代码是304 0 0 代表未更新。
220.181.108.94专用抓取首页IP 权重段,一般返回代码是304 0 0 代表未更新。
220.181.108.97专用抓取首页IP 权重段,一般返回代码是304 0 0 代表未更新。
220.181.108.80专用抓取首页IP 权重段,一般返回代码是304 0 0 代表未更新。
220.181.108.77 专用抓首页IP 权重段,一般返回代码是304 0 0 代表未更新。
123.125.71.117 抓取内页收录的,权重较低,爬过此段的内页文章不会很快放出来,因不是原创或采集文章。
220.181.108.83专用抓取首页IP 权重段,一般返回代码是304 0 0 代表未更新。
注:以上IP尾数还有很多,但段位一样的123.125.71.*段IP 代表抓取内页收录的权重比较低.可能由于你采集文章或拼
文章暂时被收录但不放出来.(意思也就是说待定)。
220.181.108.*段IP主要是抓取首页占80%,内页占30%,这此爬过的文章或首页,绝对24小时内放出来和隔夜快照
在了解蜘蛛IP对应的作用和含义后,我们如何判断百度到底有无收录或抓取站点内容呢?大家可以根据每一行日志后
抓取返回的状态响应码去分析:
1、成功抓取 返回代码是 200 0 0;
2、网站没更新 返回代码是304 0 0;
3、蜘蛛来过 返回的是200 0 64
本文由《点滴互动》SEO优化 栏目整理提供,转载须注明出处,谢谢!
三 : 通过网站日志了解百度蜘蛛的认可度
相信大家对百度蜘蛛都很了解,站长们都是欢迎蜘蛛的光临,但是否真正了解百度蜘蛛的来意,相信这点大家才是非常关心的话题了,现编者根据以往观察网站运行的日专给大家分享一下,不对之处还请指正。
一、整点式爬行,这种爬行争对新站或即将要被降权的网站,指的是每天24小时,每小时百度蜘蛛都会对你网站首页进行爬行,并且爬行数量基本一致。这是新站当中最常见的,也只对新站才会出现,这种怕行百度一定不会收录,并且快照也不会更新。这是百度对你网站的一种考察,这类爬行是百度对你网站首页内容的分析,网站是否有更新,更新的力度如何,内容是否充实等等,顺便也会爬一些首页上的数据回去对比分析,并带回文章的URL路径,安排蜘蛛的下次爬取目标。另一种就是对于百度认为你站已经正常了的,或因网站出现问题,如服务器不稳定,网页经常无法打开,网页有违法问题等等,就会出现类似的爬行方式,那么你就要小心了,出现这种爬行方式,你的站多半会被降权。其表现为次日首页的快照日期未更新或回滚到之前的日期,收录停止,甚至严重的会删除掉一些已收录的网页。那么做为站长的你就要检查下网站看那方面出了问题,并且及时修正问题就不严重了,在两三天内就是恢复。
二、 确认收录爬行,有点类似于谷歌蜘蛛爬虫,各个爬虫分工明确,有条不紊,各司其职。这种爬行方式若出现在你的网站日志里,那么恭喜你,你的网站已通过审核期,百度开台正式收录你的网页了。确认收录爬行就是指你网站有新的内容出现后,百度蜘蛛第一次爬行过后,收录是一定不会给你放出来的,这时百度还有很多因素不能确定,如果百度蜘蛛认为有必要进行对比计算的话,那么百度蜘蛛就还需要再进行第二次爬行,对爬取的内容与存在于索引库中的内容进行对比运算、比较计算的,文章内容是否新鲜,与索引库中内容是否重复等,如果认为你这个文章内容是有必要收录,百度蜘蛛会进行第三次爬行,爬行后会立即放出收录页面。如若网站权重高,百度就不会重复如些动作,即一次通过,直接先放出来,然后进行排名的运算,最后根据运算结果得出与索引库中有高度重复文章将会慢慢删除掉,这就是为何有些网站头天收录第二天就没有了,头天收录排名第一,次日就见不到踪影了,正是这个原因。
三、爆发式或间隙式爬行,经常在网站日志中看到百度蜘蛛能在一两分钟内爬行几百次。百度蜘蛛如此高效率的爬行,说明网站在这个时段的更新效率非常高,说明百度蜘蛛已撑握了你网站的更新规律,如若在此时更新文章便可达到秒收的效果,但这并不说明网站权重高,收录快,只能说是碰巧网站所更新文章被百度爬行蜘蛛遇到了。有时更新的文章一个小时,甚至几个小时都没有被收录,这样只能说明网站的更新没有按时更新造成,蜘蛛一离开就更新了,所以新站长们须时时关注日志,撑握百度蜘蛛来访规律加以利用方可事伴功备。
四、圈养式爬行,这就相当于是网站自家养的一个蜘蛛爬虫,时时刻刻爬行于网站之内,只要一有文章更新即刻爬取到传送加索引库,先给予放行,并赋予高权重,收录后搜索关键词基本在第一页,之后才进行数据对比,如若与索引库中重复,次日后便在索引库中删除;若文章太过于垃圾或属于是绿萝算法打击的对象范围之内将会直接降权或删除处理。这种达到秒收的网站才是权重高,蜘蛛爬虫几乎时时刻刻为其服务。
以上是我个人根据长期分析日专获取的相关经验与其大家分享,若有错误之处还请指正,网站运行日志是站长最得力的工具,特别是新站站长,要养成每日必看日志的习惯,最后祝各位新站站长朋友早日脱离百度考察期。
转载请保留本文链接:
四 : 百度蜘蛛在IIS日志中留下200 0 64的百度官方解答
本文的出发点:最近我的站出现蜘蛛抓取返回200 0 64,于是开始搜索资料分析这些状态码,搜索“蜘蛛抓取返回200 0 64”的期间看到了很多不靠谱的答案,更有甚者说这是“K站前兆”,所以最后决定附上官方聊天记录转告大家一个官方的回答。
直接告诉大家蜘蛛返回200 0 64代码的原因:
网站开启了GZIP。
蜘蛛返回200 0 64完全是正常现象,大家完全没有必要惊慌!
下面有百度站长平台工作人员的回答截图:
近期因站长平台加入了页面优化建议功能,没有进行过GZIP压缩的站点都会提示使用GZIP。
所以会有更多的站长搜索这个问题,希望大家多多转载,不要让谣言散播。
五 : 站长务必全面解决网站缺陷 减轻百度蜘蛛访问压力
网站优化的工作分为很多块:外链、内链、内容编辑、数据分析等等,其中分析iis日志也是其中的工作之一。分析iis日志的最终目的是观察百度蜘蛛每天对网站的爬行情况,并通过观察总结出其中的不足,最后做出相应的解决方案,以求让网站优化工作更完美。
分析iis日志的方法多种多样,相信各位站长不会陌生,但是现在笔者并非为大家介绍如何分析iis日志,而是想和大家分享一下究竟哪些网站缺陷会让百度蜘蛛的访问压力变大。好了,废话不再多说,现在就进入正题吧。
缺陷一:网站存在没有得到合理处理的死链接
死链接是一种对蜘蛛非常不友好的存在,死链接的产生一般是网站由于改版或者更改域名之后没有及时处理旧链接而产生的,而死链接的大量存在,将会导致百度蜘蛛对网站的访问压力加大。可以想象,每次百度蜘蛛兴高采烈地来到你的网站上爬行链接,却接二连三遇到一些死链接的挡道,重复的情况不断出现,最后让蜘蛛不再信任你的网站,继而也产生网站不被收录的结果。
&&解决方案:
【1】百度站长平台如今已经推出一项名为“死链接提交”的服务功能,我们站长应该重视这一项服务,把网站上哪些无用的、冗余的死链接提交到百度上去,让百度蜘蛛认识到该链接是死链接而不必去爬行。
【2】重定向死链接也是一种常用的方法,具体方法必须根据你的网站的服务器决定,当然前提是网站死链接数量不是太大的情况下就采取这种办法,如果数量太多,重定向就显得不那么符合用户体验了。
缺陷二:误导蜘蛛的网站地图
网站地图的制作也是网站优化必须做的一项工作,网站地图如果制作得好,会有利于蜘蛛对网站的爬行和收录。但是很多站长不太重视这项工作,通常都会选取一些不怎么靠谱小工具来制作网站地图,导致出现一些差错,最后让百度蜘蛛在网站上“迷路”。
&&解决方案:
笔者建议,如果站长有能力自己制作网站地图就自己制作,毕竟你会比一些工具更熟悉你的网站;如果实在制作不出来,那么就选用一些权威性的工具来制作,如百度站长工具、站长之家工具等等,做好后仔细测试一下,尽量不要让其出现过多漏洞。
缺陷三:网站陷阱让蜘蛛备受折磨
何为网站陷阱?所谓的网站陷阱就是网站存在某些问题,让蜘蛛在爬行网站时候发生错误,陷入网站之中,继而无法走出网站。通常我们很难会发现这种情况,但是我们可以通过查看iis日志或者百度站长工具的“压力反馈”来观察,如果蜘蛛爬行压力越来越大,我们就要随时意识到,网站可能存在一些陷阱。
&&解决方案:
【1】网站尽量静态化。尽管百度一直表明自己的搜索蜘蛛能够很好地抓取含有动态参数url的页面,但是毕竟能力有限,如果我们的网站某个页面含有过多的参数的url,那么抓取起来就是一件难事了,如下图:
如此多的参数url会让百度蜘蛛暗暗叫苦,还可能导致蜘蛛陷入这个“参数黑洞”中无法爬出来。因此我们做站的时候应该尽量选用能够静态化的程序,这样才能很好地防止蜘蛛陷阱。
【2】不要让蜘蛛在内链中打转。外链可以通过一层扣一层来形成链轮,内链也是可以的,很多站长为了快速提升关键词排名,不惜滥用锚文本,造成页面之间的链接轮回,导致蜘蛛不停地爬来爬去,最后陷入陷阱无法逃脱出来。
其实,百度蜘蛛即使再聪明、最智能,它也不过是由人类编写出来的一段代码而已,但是站长们也应该学会尊重百度蜘蛛,尽量解决网站存在的缺陷,让其能够更好地爬行网站、收录网站,这样我们的网站优化工作才会更加完美无缺。本文专为明星QQ头像http://www.qiuqq.com供稿,希望转载的朋友加上一条链接,谢谢大家支持!
本文标题:百度蜘蛛ip段详解-详解123.125.71.*百度蜘蛛IP段61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1