一 : robots.txt的规则误区及百度和Google的robots工具的使用
对于robots.txt文件对于网站的作用大家都知道,但是通过观察发现,有些朋友对于robots.txt文件的规则还是有一定的误区。
比如有很多人这样写:
User-agent: *
Allow: /
Disallow: /mulu/
不知道大家有没有看出来,这个规则其实是不起作用的,第一句Allow: / 指的是允许蜘蛛爬行所有内容,第二句Disallow: /mulu/指的是禁止/mulu/下面的所有内容。
表面上看这个规则想达到的目的是:允许蜘蛛爬行除了/mulu/之外的网站所有页面。
但是搜索引擎蜘蛛执行的规则是从上到下,这样会造成第二句命令失效。
正确的规则应该是:
User-agent: *
Disallow: /mulu/
Allow: /
也就是先执行禁止命令,再执行允许命令,这样就不会失效了。
另外对于百度蜘蛛来说,还有一个容易犯的错误,那就是Disallow命令和Allow命令之后要以斜杠/开头,所以有些人这样写:Disallow: *.html 这样对百度蜘蛛来说是错误的,应该写成:Disallow: /*.html 。
有时候我们写这些规则可能会有一些没有注意到的问题,现在可以通过百度站长工具(zhanzhang.baidu.com)和Google站长工具来测试。
相对来说百度站长工具robots工具相对简陋一些:
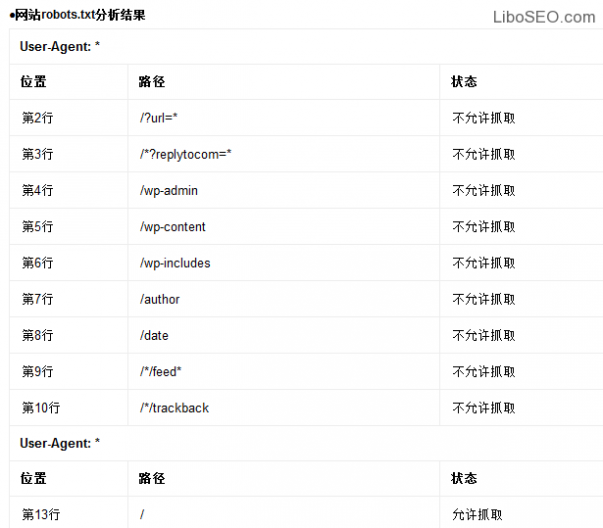
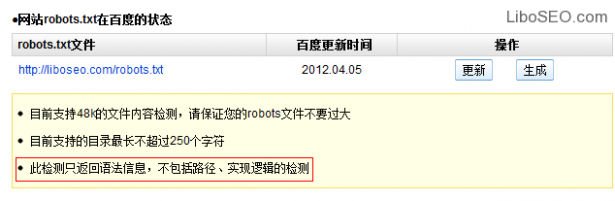
百度Robots工具只能检测每一行命令是否符合语法规则,但是不检测实际效果和抓取逻辑规则。
相对来说Google的Robots工具好用很多,如图:
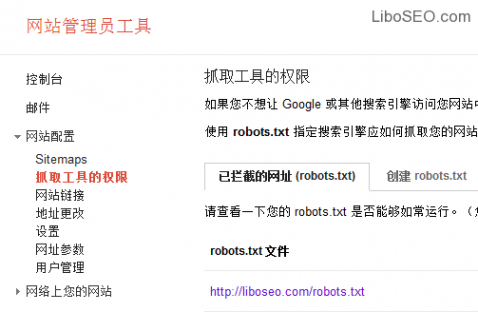
在谷歌站长工具里的名称是抓取工具的权限,并报告Google抓取网站页面的时候被拦截了多少个网址。
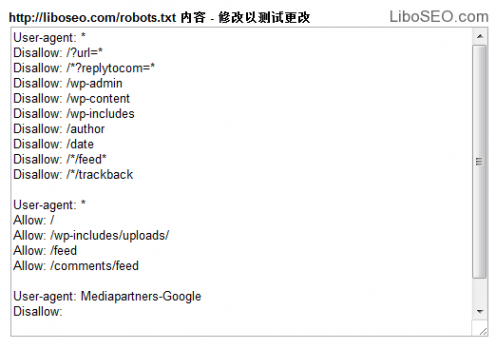
还可以在线测试Robots修改后的效果,当然这里的修改只是测试用,如果没有问题了,可以生成robots.txt文件,或者把命令代码复制到robots.txt文本文档中,上传到网站根目录。
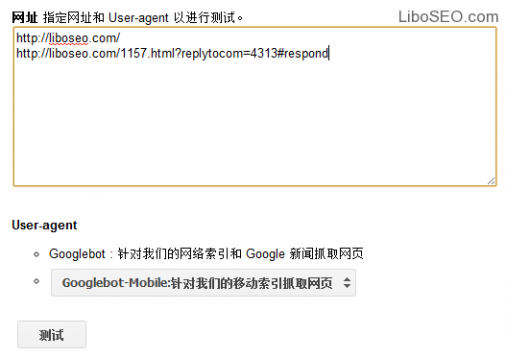
Google的测试跟百度有很大的区别,它可以让你输入某一个或者某些网址,测试Google蜘蛛是否抓取这些网址。
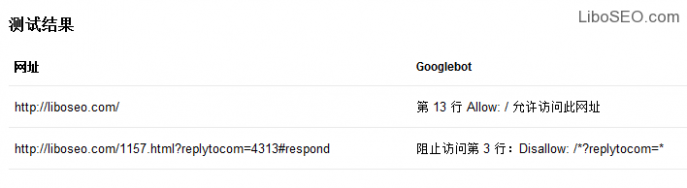
测试结果是这些网址被Google蜘蛛抓取的情况,这个测试对于Robots文件对某些特定url的规则是否有效。
而两个工具结合起来当然更好了,这下应该彻底明白robots应该怎么写了吧。
转载请注明来自逍遥博客,本文地址:,转载请注明出处和链接!
注:相关网站建设技巧阅读请移步到建站教程频道。
二 : 百合花和百合的区别
一般人们说的百合指的是百合科百合属这类植物的鳞茎,这类植物大概有300多种,因其鳞茎由许多白色鳞片层环抱而成,状如莲花,因而取 “百年好合”之意命名。百合花指的是这类植物的花朵,花朵呈漏斗状喇叭形,较大,花瓣六片,色彩多种,很具观赏性,其中有的品种有香味。
有不少百合花的鳞茎可以可食用,而人们平时所吃的百合就是个别百合花的鳞茎。百合中含有蛋白质、脂肪、淀粉以及钙、铁磷等多种矿物质,还含有丰富的维生素等营养元素。对人体有良好的滋补作用,还能防止因天气干燥所引起的季节性疾病,具有养心安神,润肺止咳的功效,对病后虚弱的人非常有益。
三 : 百度框计算和 Google 的 pagerank 哪个是正道?
[百度框]百度框计算和 Google 的 pagerank 哪个是正道?网友姚旭对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
框计算和pagerank本身没有可比性
一个是比较宽泛的搜索引擎功能扩展, 一个是搜索引擎rank技术
产品形态比较相近的倒是有两个
百度的开放平台(以前叫阿拉丁): http://open.baidu.com/举例: http://www.61k.coms?bs=%CA%AE%B6%FE%C5%AD%BA%BA&f=8&wd=%CC%EC%C6%F8%D4%A4%B1%A8&n=2&inputT=1357
google的OneBox举例: http://www.61k.comhk/#hl=zh-CN&safe=strict&q=%E5%A4%A9%E6%B0%94%E9%A2%84%E6%8A%A5&aq=f&aqi=&aql=&oq=&fp=1b07ded1155adb3f&biw=1280&bih=679
两者从形式上看很类似, 都是将原本搜索结果的内容, 已特殊形式直接展现在搜索结果中
百度目前支持第三方提交的结果, 包括文本链接形式的, 也包括app形式的
google目前似乎没有主动提交的方式, 是google自身收集的信息源并控制展现形式
类似的结果形式, 对于很多特定类型的搜索需求来说是一个趋势, bing(不是http://cn.bing.com)也有很多, 比如飞机票,酒店查询等等
至于这类结果是否是越多越好, 是否需要由搜索引擎来严格控制类型防止影响互联网生态, 这个还有待后续进一步验证.
网友魏大鹏对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
百度的框计算,从本质来说是阻截了其他各个网站的流量,将用户留在了自己的网站里面,从另一方面来说,是将用户引向自己,百度越来越像百度站内搜索了.搜索结果中包括框计算直接内嵌在搜索结果中,前面的结果也基本指向百度自己的站内结果.
而google的PR,是对网站评级的一种权重,然后在搜索结果显示时,根据关键词匹配和PR,来对答案进行排序,与框计算不属于同类产品.google现在所做的,正好与百度相反,尽量减少用户在google页面的停留,而把用户指引到目标网站上,PR算法改进和新的对原创内容权重提升,还有google瞬时搜索,无一不是朝着这个目标前进,包括那个每天让google损失大量广告收入的手气不错.
从长远角度看,google的做方法更有利于其他网站的发展,能为其他网站带来流量,而百度的做法,基本断了其他网站的后路,加之搜索结果广告和抄袭掺杂,百度的做法让人不耻.
网友毛朴澄对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
搜索的核心目标是帮助用户更快得找到需要的内容,从这个角度,至少目前框计算是有助于搜索更好得满足这个核心需求的,尤其在中国的互联网环境下。很多人讨论搜索引擎,言必讨论生态链的问题,看起来眼光很长远,但实际上情绪宣泄或者利益纠葛为主。至少目前,框计算为用户带来了更好的体验,所以我觉得框计算是成功的。但是长远来看,如何处理生态链的问题,甚至积极去更好得扶持生态链,是百度必须重视起来的,目前百度的业务完全离不开搜索,这样的扩张实际上在蚕食生态链中网站们的利益,这不是长远之计。
网友alsotang对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
不同的两样东西,没法比啊。
网友飞翔猪对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
将其理解为2种筛选搜索结果的方式。
人工审核+第三方内容供应商 vs 基于链接分析的机器算法
对于前者,有三个问题
1、一个好的第三方内容供应商能让搜索结果有一个极大的提升,而反之伤害也很大,特别是百度在占有绝对性垄断地位的情况下,已经撕下了开放平台以及所谓只提供确定性结果的遮羞布,公然把它当做独家买断的广告形式。
2、一个第三方供应商未必能满足日趋多样化的需求。多个第三方内容供应商则意味着监管成本以及搜索质量波动的风险加大。
3、法律风险。这些第三方内容,内容的确是第三方提供的,但是,是放在百度的页面展示的,百度有没有必要为这些内容负责呢,百度这个时候已经不是作为搜索引擎了给用户提供链接。它是和第三方合作提供内容,而且是展示在百度自己的服务器上。应该要对内容负责。
对于后者,我相信机器算法总是不断进步的。
网友Longworld对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
顺应互联网的自然生态才是王道,百度之所这么做其实就是垃圾站太多了,惩罚垃圾站宁可错杀也不能放过。不过与此同时百度的广告收入也很稳定。毕竟有钱的大公司也很乐意花钱做这些广告,相比之下比电视广告便宜多了。个人浅见。
网友HuangFei对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
加入框计算有点像内容提供商,虽然还是第三方内容。 如果google也这么做,会不会涉嫌垄断?
网友金凡对[百度框]百度框计算和 Google 的 pagerank 哪个是正道?给出的答复:
互联网本来只有两层,一层是信息发布者(网站经营者),另外一层是信息接收者(网民),但随着信息发布源头和信息接收者得迅速扩张,出现了中间层(搜索引擎),搜索引擎的功能就是所有网民的一个窗口,通过这个窗口,用户可以看到几乎所有的信息,而通过这个窗口,政府也可以更加方便地控制网民所能看到的东西,搜索引擎本身是不产生多少内容的,搜索引擎现在秉持两种理念,百度的理念是生存优于理想,google的理念是不作恶,所以我们看到的是百度是严格实行信息控制的公司,而google上面的信息是算法控制的,没有人为的干涉。
当然百度现在提供了一个开放平台,就是能够让更多的人开发web app ,所以现在百度相当于是已经跨出了搜索引擎,走向一种全方位信息服务平台,这样肯定是一种不错的模式,能够盈利,并且用户也乐于去习惯百度提供的这种服务。
但是百度所丧失的是什么,在使用百度的过程中,我发现,其实搜索的结果没有什么明显的改进。也就是说百度的工程师也许很辛苦地努力工作,但是用户当初最需要,现在也是最重视的功能还是没有得到很大的改进,web app不能让用户耳目一新,百度让我们思考,搜索在技术上是否已经达到了巅峰,比如百度原本有一个庞大的信息库,而这些信息完全可以进行按规则的排列组合,但是他们却没有做。
至于google ,只能说它现在和百度的情况一样,他们都在吃老本。
我觉得没有什么好寄希望于这两个公司了,只是期望有小的,更具革新性的公司能够涌现,给我们带来耳目一新的感觉!
四 : 百度蜘蛛 和 Google bot 的区别
百度:61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1