一 : PHP正则表达式的几则使用技巧
PHP正则表达式主要用于字符串的模式分割、匹配、查找及替换操作。使用正则表达式在某些简单的环境下可能效率不高,因此如何更好的使用PHP正则表达式需要综合考虑。
我的PHP正则入门,是起源于网上的一篇文章,这篇文章由浅入深的阐述了PHP正则表达式使用的方法,我觉得是一个很好的入门材料,不过学成还是要靠个人,在使用的过程中,还是会不断地忘记,因此反反复复的阅读了这篇文章有四五遍,对于其中一些比较困难的知识点,甚至要用很久才能消化,但是只要能见坚持着看完,你会发现自己对于正则的运用能力就会显著提高。
PHP正则表达式的定义:
用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找及替换操作。
PHP中的正则函数:
PHP中有两套正则函数,两者功能差不多,分别为:
一套是由PCRE(Perl Compatible Regular Expression)库提供的。使用“preg_”为前缀命名的函数;
一套由POSIX(Portable Operating System Interface of Unix )扩展提供的。使用以“ereg_”为前缀命名的函数;(POSIX的正则函数库,自PHP 5.3以后,就不在推荐使用,从PHP6以后,就将被移除)
由于POSIX正则即将推出历史舞台,并且PCRE和perl的形式差不多,更利于我们在perl和php之间切换,所以这里重点介绍PCRE正则的使用。
PCRE正则表达式
PCRE全称为Perl Compatible Regular Expression,意思是Perl兼容正则表达式。
在PCRE中,通常将模式表达式(即正则表达式)包含在两个反斜线“/”之间,如“/apple/”。
正则中重要的几个概念有:元字符、转义、模式单元(重复)、反义、引用和断言,这些概念都可以在文章[1]中轻松的理解和掌握。
常用的元字符(Meta-character):
元字符 说明
A 匹配字符串串首的原子
Z 匹配字符串串尾的原子
b 匹配单词的边界 /bis/ 匹配头为is的字符串 /isb/ 匹配尾为is的字符串 /bisb/ 定界
B 匹配除单词边界之外的任意字符 /Bis/ 匹配单词“This”中的“is”
d 匹配一个数字;等价于[0-9]
D 匹配除数字以外任何一个字符;等价于[^0-9]
w 匹配一个英文字母、数字或下划线;等价于[0-9a-zA-Z_]
W 匹配除英文字母、数字和下划线以外任何一个字符;等价于[^0-9a-zA-Z_]
s 匹配一个空白字符;等价于[ftv]
S 匹配除空白字符以外任何一个字符;等价于[^ftv]
f 匹配一个换页符等价于 x0c 或 cL
匹配一个换行符;等价于 x0a 或 cJ
匹配一个回车符等价于x0d 或 cM
t 匹配一个制表符;等价于 x09或cl
v 匹配一个垂直制表符;等价于x0b或ck
oNN 匹配一个八进制数字
xNN 匹配一个十六进制数字
cC 匹配一个控制字符
模式修正符(Pattern Modifiers):
模式修正符在忽略大小写、匹配多行中使用特别多,掌握了这一个修正符,往往能解决我们遇到的很多问题。
i -可同时匹配大小写字母
M -将字符串视为多行
S -将字符串视为单行,换行符做普通字符看待,使“.”匹配任何字符
X -模式中的空白忽略不计
U -匹配到最近的字符串
e -将替换的字符串作为表达使用
格式:/apple/i匹配“apple”或“Apple”等,忽略大小写。 /i
PCRE的模式单元:
//1 提取第一位的属性
/^d{2} ([W])d{2}1d{4}$匹配“12-31-2006”、“09/27/1996”、“86 01 4321”等字符串。但上述正则表达式不匹配“12/34-5678”的格式。这是因为模式“[W]”的结果“/”已经被存储。下个位置“1”引用时,其匹配模式也是字符“/”。
当不需要存储匹配结果时使用非存储模式单元“(?:)”
例如/(?:a|b|c)(D|E|F)1g/ 将匹配“aEEg”。在一些正则表达式中,使用非存储模式单元是必要的。否则,需要改变其后引用的顺序。上例还可以写成/(a|b|c)(C|E|F)2g/。
PCRE正则表达式函数:
| 以下为引用的内容:
|
函数的具体使用,我们可以通过PHP手册来找到,下面分享一些平时积累的正则表达式:
匹配action属性
| 以下为引用的内容:
|
在正则中使用回调函数
| 以下为引用的内容:
|
带断言的正则匹配
| 以下为引用的内容:
|
替换HTML源码中的地址
| 以下为引用的内容:
|
最后,正则工具虽然强大,但是从效率和编写时间上来讲,有的时候可能没有explode来的更直接,对于一些紧急或者要求不高的任务,简单、粗暴的方法也许更好。
而对于preg和ereg两个系列之间的执行效率,曾看到文章说preg要更快一点,具体由于使用ereg的时候并不多,而且也要推出历史舞台了,再加个个人更偏好于PCRE的方式,所以笔者就不做比较了,熟悉的朋友可以发表下意见,谢谢。
本文来自Cocowool的博客园博文《PHP中正则的使用》
二 : 什么是正则表达式?
什么是正则表达式
一个正则表达式,就是用某种模式去匹配一类字符串的一个公式。[www.61k.com]很多人因为它们看上去比较古怪而且复杂所以不敢去使用——很不幸,这篇文章也不能够改变这一点,不过,经过一点点练习之后我就开始觉得这些复杂的表达式其实写起来还是相当简单的,而且,一旦你弄懂它们,你就能把数小时辛苦而且易错的文本处理工作压缩在几分钟(甚至几秒钟)内完成。正则表达式被各种文本编辑软件、类库(例如Rogue Wave的tools.h++)、脚本工具(像awk/grep/sed)广泛的支持,而且像Microsoft的Visual C++这种交互式IDE也开始支持它了。我们将在如下的章节中利用一些例子来解释正则表达式的用法,绝大部分的例子是基于vi中的文本替换命令和grep文件搜索命令来书写的,不过它们都是比较典型的例子,其中的概念可以在sed、awk、perl和其他支持正则表达式的编程语言中使用。你可以看看不同工具中的正则表达式这一节,其中有一些在别的工具中使用正则表达式的例子。还有一个关于vi中文本替换命令(s)的简单说明附在文后供参考。
正则表达式基础
正则表达式由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,我们下面会给予解释。在最简单的情况下,一个正则表达式看上去就是一个普通的查找串。例如,正则表达式"testing"中没有包含任何元字符,,它可以匹配"testing"和"123testing"等字符串,但是不能匹配"Testing"。
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。
| 元字符 | 描述 | |
|---|---|---|
| 匹配任何单个字符。例如正则表达式r.t匹配这些字符串:rat、rut、r t,但是不匹配root。 | ||
| 匹配行结束符。例如正则表达式weasel$能够匹配字符串"He's a weasel"的末尾,但是不能匹配字符串"They are a bunch of weasels."。 | ||
| 匹配一行的开始。例如正则表达式^When in能够匹配字符串"When in the course of human events"的开始,但是不能匹配"What and When in the"。 | ||
| 匹配0或多个正好在它之前的那个字符。例如正则表达式.*意味着能够匹配任意数量的任何字符。 | ||
| 这是引用府,用来将这里列出的这些元字符当作普通的字符来进行匹配。例如正则表达式\$被用来匹配美元符号,而不是行尾,类似的,正则表达式\.用来匹配点字符,而不是任何字符的通配符。 | ||
[c1-c2] [^c1-c2] | 匹配括号中的任何一个字符。例如正则表达式r[aou]t匹配rat、rot和rut,但是不匹配ret。可以在括号中使用连字符-来指定字符的区间,例如正则表达式[0-9]可以匹配任何数字字符;还可以制定多个区间,例如正则表达式[A-Za-z]可以匹配任何大小写字母。另一个重要的用法是“排除”,要想匹配除了指定区间之外的字符——也就是所谓的补集——在左边的括号和第一个字符之间使用^字符,例如正则表达式[^269A-Z]将匹配除了2、6、9和所有大写字母之外的任何字符。 | |
| 匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 | ||
| 将 \( 和 \) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用\1到\9的符号来引用。 | ||
| 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her)匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 | ||
| 匹配1或多个正好在它之前的那个字符。例如正则表达式9+匹配9、99、999等。注意:这个元字符不是所有的软件都支持的。 | ||
| 匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的。 | ||
\{i,j\} | 匹配指定数目的字符,这些字符是在它之前的表达式定义的。例如正则表达式A[0-9]\{3\}能够匹配字符"A"后面跟着正好3个数字字符的串,例如A123、A348等,但是不匹配A1234。而正则表达式[0-9]\{4,6\}匹配连续的任意4个、5个或者6个数字字符。注意:这个元字符不是所有的软件都支持的。 |
最简单的元字符是点,它能够匹配任何单个字符(注意不包括新行符)。假定有个文件test.txt包含以下几行内容:
要想匹配行首的字符要使用抑扬字符(^)——又是也被叫做插入符。例如,想找到text.txt中行首"he"打头的行,你可能会先用简单表达式he,但是这会匹配第三行的the,所以要使用正则表达式^he,它只匹配在行首出现的h。
有时候指定“除了×××都匹配”会比较容易达到目的,当抑扬字符(^)出现在方括号中是,它表示“排除”,例如要匹配he,但是排除前面是tors的情性(也就是the和she),可以使用:[^st]he。
可以使用方括号来指定多个字符区间。例如正则表达式[A-Za-z]匹配任何字母,包括大写和小写的;正则表达式[A-Za-z][A-Za-z]*匹配一个字母后面接着0或者多个字母(大写或者小写)。当然我们也可以用元字符+做到同样的事情,也就是:[A-Za-z]+,和[A-Za-z][A-Za-z]*完全等价。但是要注意元字符+并不是所有支持正则表达式的程序都支持的。关于这一点可以参考后面的正则表达式语法支持情况。
要指定特定数量的匹配,要使用大括号(注意必须使用反斜杠来转义)。想匹配所有100和1000的实例而排除10和10000,可以使用:10\{2,3\},这个正则表达式匹配数字1后面跟着2或者3个0的模式。在这个元字符的使用中一个有用的变化是忽略第二个数字,例如正则表达式0\{3,\}将匹配至少3个连续的0。
简单的例子
这里有一些有代表性的、比较简单的例子。
| vi 命令 | 作用 |
| :%s/ */ /g | 把一个或者多个空格替换为一个空格。 |
| :%s/ *$// | 去掉行尾的所有空格。 |
| :%s/^/ / | 在每一行头上加入一个空格。 |
| :%s/^[0-9][0-9]* // | 去掉行首的所有数字字符。 |
| :%s/b[aeio]g/bug/g | 将所有的bag、beg、big和bog改为bug。 |
| :%s/t\([aou]\)g/h\1t/g | 将所有tag、tog和tug分别改为hat、hot和hug(注意用group的用法和使用\1引用前面被匹配的字符)。 |
中级的例子(神奇的咒语)
例1
将所有方法foo(a,b,c)的实例改为foo(b,a,c)。这里a、b和c可以是任何提供给方法foo()的参数。也就是说我们要实现这样的转换:
| 之前 | 之后 | |
| foo(10,7,2) | foo(7,10,2) | |
| foo(x+13,y-2,10) | foo(y-2,x+13,10) | |
| foo( bar(8), x+y+z, 5) | foo( x+y+z, bar(8), 5) |
下面这条替换命令能够实现这一魔法:
现在让我们把它打散来加以分析。写出这个表达式的基本思路是找出foo()和它的括号中的三个参数的位置。第一个参数是用这个表达式来识别的::\([^,]*\),我们可以从里向外来分析它:
| [^,] | 除了逗号之外的任何字符 | |
| [^,]* | 0或者多个非逗号字符 | |
| \([^,]*\) | 将这些非逗号字符标记为\1,这样可以在之后的替换模式表达式中引用它 | |
| \([^,]*\), | 我们必须找到0或者多个非逗号字符后面跟着一个逗号,并且非逗号字符那部分要标记出来以备后用。 |
现在正是指出一个使用正则表达式常见错误的最佳时机。为什么我们要使用[^,]*这样的一个表达式,而不是更加简单直接的写法,例如:.*,来匹配第一个参数呢?设想我们使用模式.*来匹配字符串"10,7,2",它应该匹配"10,"还是"10,7,"?为了解决这个两义性(ambiguity),正则表达式规定一律按照最长的串来,在上面的例子中就是"10,7,",显然这样就找出了两个参数而不是我们期望的一个。所以,我们要使用[^,]*来强制取出第一个逗号之前的部分。
这个表达式我们已经分析到了:foo(\([^,]*\),这一段可以简单的翻译为“当你找到foo(就把其后直到第一个逗号之前的部分标记为\1”。然后我们使用同样的办法标记第二个参数为\2。对第三个参数的标记方法也是一样,只是我们要搜索所有的字符直到右括号。我们并没有必要去搜索第三个参数,因为我们不需要调整它的位置,但是这样的模式能够保证我们只去替换那些有三个参数的foo()方法调用,在foo()是一个重载(overoading)方法时这种明确的模式往往是比较保险的。然后,在替换部分,我们找到foo()的对应实例,然后利用标记好的部分进行替换,是的第一和第二个参数交换位置。
例2
假设有一个CSV(comma separated value)文件,里面有一些我们需要的信息,但是格式却有问题,目前数据的列顺序是:姓名,公司名,州名缩写,邮政编码,现在我们希望讲这些数据重新组织,以便在我们的某个软件中使用,需要的格式为:姓名,州名缩写-邮政编码,公司名。也就是说,我们要调整列顺序,还要合并两个列来构成一个新列。另外,我们的软件不能接受逗号前后面有任何空格(包括空格和制表符)所以我们还必须要去掉逗号前后的所有空格。这里有几行我们现在的数据:
下面就是第一个替换命令:
下面这个替换命令则用来去除空格:
例3
假设有一个多字符的片断重复出现,例如:Billy tried really hard而你想把"really"、"really really",以及任意数量连续出现的"really"字符串换成一个简单的"very"(simple is good!),那么以下命令:
Sally tried really really hard
Timmy tried really really really hard
Johnny tried really really really really hard
:%s/\(really \)\(really \)*/very /就会把上述的文本变成:
Billy tried very hard表达式\(really \)*匹配0或多个连续的"really "(注意结尾有个空格),而\(really \)\(really \)*匹配1个或多个连续的"really "实例。
Sally tried very hard
Timmy tried very hard
Johnny tried very hard
困难的例子(不可思议的象形文字)
Coming soon.
不同工具中的正则表达式
OK,你已经准备使用RE(regular expressions,正则表达式),但是你并准备使用vi。所以,在这里我们给出一些在其他工具中使用RE的例子。另外,我还会总结一下你在不同程序之间使用RE可能发现的区别。当然,你也可以在Visual C++编辑器中使用RE。选择Edit->Replace,然后选择"Regular expression"选择框,Find What输入框对应上面介绍的vi命令:%s/pat1/pat2/g中的pat1部分,而Replace输入框对应pat2部分。但是,为了得到vi的执行范围和g选项,你要使用Replace All或者适当的手工Find Next and Replace(译者按:知道为啥有人骂微软弱智了吧,虽然VC中可以选中一个范围的文本,然后在其中执行替换,但是总之不够vi那么灵活和典雅)。
sed
Sed是StreamEDitor的缩写,是Unix下常用的基于文件和管道的编辑工具,可以在手册中得到关于sed的详细信息。
这里是一些有趣的sed脚本,假定我们正在处理一个叫做price.txt的文件。注意这些编辑并不会改变源文件,sed只是处理源文件的每一行并把结果显示在标准输出中(当然很容易使用重定向来定制):
| sed脚本 | 描述 | |
| sed 's/^$/d' price.txt | 删除所有空行 | |
| sed 's/^[ \t]*$/d' price.txt | 删除所有只包含空格或者制表符的行 | |
| sed 's/"//g' price.txt | 删除所有引号 |
awk
awk是一种编程语言,可以用来对文本数据进行复杂的分析和处理。可以在手册中得到关于awk的详细信息。这个古怪的名字是它作者们的姓的缩写(Aho,Weinberger和Kernighan)。在Aho,Weinberger和Kernighan的书The AWK Programming Language中有很多很好的awk的例子,请不要让下面这些微不足道的脚本例子限制你对awk强大能力的理解。我们同样假定我们针对price.txt文件进行处理,跟sed一样,awk也只是把结果显示在终端上。
| awk脚本 | 描述 | |
| awk '$0 !~ /^$/' price.txt | 删除所有空行 | |
| awk 'NF > 0' price.txt | awk中一个更好的删除所有行的办法 | |
| awk '$2 ~ /^[JT]/ {print $3}' price.txt | 打印所有第二个字段是'J'或者'T'打头的行中的第三个字段 | |
| awk '$2 !~ /[Mm]isc/ {print $3 + $4}' price.txt | 针对所有第二个字段不包含'Misc'或者'misc'的行,打印第3和第4列的和(假定为数字) | |
| awk '$3 !~ /^[0-9]+\.[0-9]*$/ {print $0}' price.txt | 打印所有第三个字段不是数字的行,这里数字是指d.d或者d这样的形式,其中d是0到9的任何数字 | |
| awk '$2 ~ /John|Fred/ {print $0}' price.txt | 如果第二个字段包含'John'或者'Fred'则打印整行 |
grep
grep是一个用来在一个或者多个文件或者输入流中使用RE进行查找的程序。它的name编程语言可以用来针对文件和管道进行处理。可以在手册中得到关于grep的完整信息。这个同样古怪的名字来源于vi的一个命令,g/re/p,意思是globalregularexpressionprint。下面的例子中我们假定在文件phone.txt中包含以下的文本,——其格式是姓加一个逗号,然后是名,然后是一个制表符,然后是电话号码:
Francis, John 5-3871
Wong, Fred 4-4123
Jones, Thomas 1-4122
Salazar, Richard 5-2522
| grep命令 | 描述 | |
| grep '\t5-...1' phone.txt | 把所有电话号码以5开头以1结束的行打印出来,注意制表符是用\t表示的 | |
| grep '^S[^ ]* R' phone.txt | 打印所有姓以S打头和名以R打头的行 | |
| grep '^[JW]' phone.txt | 打印所有姓开头是J或者W的行 | |
| grep ', ....\t' phone.txt | 打印所有姓是4个字符的行,注意制表符是用\t表示的 | |
| grep -v '^[JW]' phone.txt | 打印所有不以J或者W开头的行 | |
| grep '^[M-Z]' phone.txt | 打印所有姓的开头是M到Z之间任一字符的行 | |
| grep '^[M-Z].*[12]' phone.txt | 打印所有姓的开头是M到Z之间任一字符,并且点号号码结尾是1或者2的行 |
egrep
egrep是grep的一个扩展版本,它在它的正则表达式中支持更多的元字符。下面的例子中我们假定在文件phone.txt中包含以下的文本,——其格式是姓加一个逗号,然后是名,然后是一个制表符,然后是电话号码:| egrep command | Description | |
| egrep '(John|Fred)' phone.txt | 打印所有包含名字John或者Fred的行 | |
| egrep 'John|22$|^W' phone.txt | 打印所有包含John 或者以22结束或者以W的行 | |
| egrep 'net(work)?s' report.txt | 从report.txt中找到所有包含networks或者nets的行 |
正则表达式语法支持情况
| 命令或环境 | . | [ ] | ^ | $ | \( \) | \{ \} | ? | + | | | ( ) |
| vi | X | X | X | X | X | |||||
| Visual C++ | X | X | X | X | X | |||||
| awk | X | X | X | X | X | X | X | X | ||
| sed | X | X | X | X | X | X | ||||
| Tcl | X | X | X | X | X | X | X | X | X | |
| ex | X | X | X | X | X | X | ||||
| grep | X | X | X | X | X | X | ||||
| egrep | X | X | X | X | X | X | X | X | X | |
| fgrep | X | X | X | X | X | |||||
| perl | X | X | X | X | X | X | X | X | X |
vi替换命令简介
Vi的替换命令:s表示其后是一个替换命令。
pat1 这是要查找的一个正则表达式,这篇文章中有一大堆例子。
g可选标志,带这个标志表示替换将针对行中每个匹配的串进行,否则则只替换行中第一个匹配串。
2006年12月16日 星期六 上午 10:42
正则表达式 |
三 : python正则表达式
1. 正则表达式基础
1.1. 简单介绍
正 则表达式并不是Python的一部分。[www.61k.com]正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方 法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用 担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: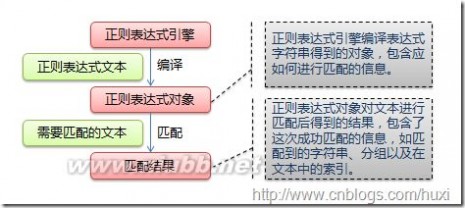
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法: 
1.2. 数量词的贪婪模式与非贪婪模式
正 则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪 的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量 词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义 字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分 别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的 正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表 达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
?
1 2 3 4 |
|
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行 re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以 简写为:
?
1 2 |
|
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
方法:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
实例方法[ | re模块方法]:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
?
1 2 3 4 5 6 7 |
|
?
1 2 3 4 5 6 7 |
|
?
1 2 3 4 5 6 7 8 |
|
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
分类:学习笔记,Python
绿色通道:好文要顶关注我收藏该文与我联系

AstralWind
关注 - 1
粉丝 - 113
+加关注
56
0
(请您对文章做出评价)
«上一篇:Python线程指南
»下一篇:Python字符编码详解
posted @ 2010-07-04 23:56AstralWind阅读(94325) 评论(39)编辑收藏

评论列表
回复引用
#1楼2010-07-06 14:08Lucker精彩,好文!
支持(1)反对(0)
回复引用
#2楼2010-12-17 11:20iTech超级好文,转载了
支持(1)反对(0)
回复引用
#3楼2010-12-17 11:24iTech此文实在是太好了,我转载了,点击率超级高啊,打破了历史水平啊!高的我都不好意思啊!我只是想收藏此精彩文章,没有其他的意思。
支持(0)反对(0)
回复引用
#4楼[楼主] 2010-12-17 21:35AstralWind@iTech
对大家有帮助就好,也没打算靠版权挣钱呵呵~
支持(1)反对(0)
回复引用
#5楼2011-05-06 10:59青怪很好的文章,学习了。谢谢!
支持(0)反对(0)
回复引用
#6楼2011-06-28 10:37Sackula[未注册用户]宇宙无敌好文~~~~~~~~
回复引用
#7楼2011-07-20 15:35vijay不错,收藏并转载
支持(0)反对(0)
回复引用
#8楼2011-07-31 03:50dawb[未注册用户]非常好,写的深入浅出
回复引用
#9楼2011-07-31 09:48lidashuang非常不错,博主第一图是用什么工具做的?
支持(0)反对(0)
回复引用
#10楼[楼主] 2011-07-31 12:54AstralWind@lidashuang
PowerPoint :)
支持(0)反对(0)
回复引用
#11楼2011-08-14 10:24junjie020[未注册用户]您好!
有一个问题关于python的条件表达式的
我发现,如果在条件表达式里面,使用别名,python是不行的(我使用的版本是2.7.2和3.2.1)
如 :
reobj = re.match(r"(?P<N1>8)(?(?P=N1)8)", "88")
这样是无法匹配的,如果使用:
reobj = re.match(r"(8)(?(1)8", "88")
这样是可以的,不知道楼主是否有试过这样使用别名来引用条件表达式呢?还是我有没有写错的?
希望指教!
回复引用
#12楼[楼主] 2011-08-15 09:43AstralWind@junjie020
你好!抱歉回复晚了,是这样,你第一个正则
?
1 |
|
?
1 |
|
支持(0)反对(0)
回复引用
#13楼2011-10-03 22:24shirnepython的正则很强大,学习收藏了
支持(0)反对(0)
回复引用
#14楼2011-11-07 11:59eason@pku不错.
支持(0)反对(0)
回复引用
#15楼2011-12-09 15:03qqzhao不错...
支持(0)反对(0)
回复引用
#16楼2011-12-19 17:16你能记住几个您好,能不能分享下文中的图片和表格是用什么软件画的,很好看啊
支持(0)反对(0)
回复引用
#17楼[楼主] 2011-12-19 18:46AstralWind@你能记住几个
ms office
支持(0)反对(0)
回复引用
#18楼2011-12-25 17:47会长好哇,我每次写正则表达式时,都来这看。脑子不行,记不住规则,只能随写随查
支持(0)反对(0)
回复引用
#19楼2011-12-26 17:02pyt123谢谢楼主分享
支持(0)反对(0)
回复引用
#20楼2012-01-19 10:01naslang[未注册用户]不错,受益了。
回复引用
#21楼2012-02-12 15:53ruyunlong[未注册用户]我也顶一下,哈哈,感谢楼主奉献
回复引用
#22楼2012-02-25 15:40dazi好东西 python 是个好东西 正则也是个好东西
支持(0)反对(0)
回复引用
#23楼2012-02-29 17:08mimicom这个我经常来看..... 呵呵...
支持(0)反对(0)
回复引用
#24楼2012-03-09 11:20mimicomm = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
奇怪... 怎么会有第三组? .
(?P<sign>.*) 这个是别名啊?.. 难道因为后面的 .* 也在括号里面?对应的后面的感叹号.
支持(0)反对(0)
回复引用
#25楼2012-03-09 11:26mimicom哦..明白了...
(?P<sign>.*)
sign是.*的别名...
支持(0)反对(0)
回复引用
#26楼2012-03-12 11:25villion文章太好了!!!
支持(0)反对(0)
回复引用
#27楼2012-06-29 10:02TonyKongcnblog博文的质量普遍很高啊。收藏了
支持(0)反对(0)
回复引用
#28楼2012-07-17 15:25小北北北就是java里面的Pattern Matcher的python实现
支持(0)反对(0)
回复引用
#29楼2012-09-07 08:10邓三皮靠!比书上讲得好,哈哈。 楼主太感谢你了,哈哈
支持(0)反对(0)
回复引用
#30楼2012-10-06 09:39Orangeink收藏了! 放到evernote里了。
求问博主,第一张图用什么软件制作的?
支持(0)反对(0)
回复引用
#31楼2012-10-07 15:31iamzhaiwei如何匹配不是以abc开头的单词?
我想到的办法是
p = re.compile(r'\b[d-zA-Z0-9]\w*\b')
支持(0)反对(0)
回复引用
#32楼2012-10-07 15:32iamzhaiwei有什么更好的办法吗?
支持(0)反对(0)
回复引用
#33楼2012-10-17 23:36MyDetail虽然写的很漂亮,当对我这个初学者,没有找到我要的点,为什么你的示例都用的常量啊,来个变量就更好啦
支持(1)反对(0)
回复引用
#34楼2012-12-07 14:42txwsqk这样的排版不管是自己看,还是别人看都看着舒服清晰明了,赞一个,果断收藏.
支持(0)反对(0)
回复引用
#35楼2013-03-09 21:49xiangzi888match方法不能匹配字串吗?re.match(r'hello', 'sd hellofgd ') 返回是空啊。。。
支持(0)反对(0)
回复引用
#36楼[楼主] 2013-03-09 23:22AstralWind@xiangzi888
严格地说,你这个需求指的是搜索,所以你应该用search()。
支持(0)反对(0)
回复引用
#37楼2013-04-04 17:38account51非常感谢博主,对Python中的RE终于能够理解一些了。有两个问题想请教一下博主,
1. 如果一个分组会匹配多个字串,比如:
(?:\((\w*)\))+
用来匹配:
(abc)(123)(xyz)
采用\1来获取分组时,只能得到最后一次匹配结果,也就是xyz.
怎样才能获取abc和123的值呢?
2. 记得在哪里看到过Perl可以实现将小写字符到大写字符的转换,写法大概类似于这样(记不清了,可能写得不对):s/[a-z]/[A-Z]
在python中正则支持这样的用法吗?也就是不借助Python本身的函数如uppercase()等,而用正则来实现一个字符集到另一个字符集之间的映射转换(不限于大小写字符之间的转换)。
先谢谢博主了!
支持(0)反对(0)
回复引用
#38楼2013-04-14 16:46moreeffort@xiangzi888
支持(0)反对(0)
回复引用
#39楼[楼主] 2013-04-16 20:28AstralWind@account51
四 : 正则表达式规则"[A-z]"与"[A-Za-z]"的差别
当我们要用正则表达式过滤出26个大小写英文字母时,会用到"[A-z]"或"[A-Za-z]"的过滤条件。如果认为这两个写法是一致的,那就要出岔子了。
请看ASCII字符表
| 八进制 | 十六进制 | 十进制 | 字符 | 八进制 | 十六进制 | 十进制 | 字符 |
|---|---|---|---|---|---|---|---|
| 00 | 00 | 0 | nul | 100 | 40 | 64 | @ |
| 01 | 01 | 1 | soh | 101 | 41 | 65 | A |
| 02 | 02 | 2 | stx | 102 | 42 | 66 | B |
| 03 | 03 | 3 | etx | 103 | 43 | 67 | C |
| 04 | 04 | 4 | eot | 104 | 44 | 68 | D |
| 05 | 05 | 5 | enq | 105 | 45 | 69 | E |
| 06 | 06 | 6 | ack | 106 | 46 | 70 | F |
| 07 | 07 | 7 | bel | 107 | 47 | 71 | G |
| 10 | 08 | 8 | bs | 110 | 48 | 72 | H |
| 11 | 09 | 9 | ht | 111 | 49 | 73 | I |
| 12 | 0a | 10 | nl | 112 | 4a | 74 | J |
| 13 | 0b | 11 | vt | 113 | 4b | 75 | K |
| 14 | 0c | 12 | ff | 114 | 4c | 76 | L |
| 15 | 0d | 13 | er | 115 | 4d | 77 | M |
| 16 | 0e | 14 | so | 116 | 4e | 78 | N |
| 17 | 0f | 15 | si | 117 | 4f | 79 | O |
| 20 | 10 | 16 | dle | 120 | 50 | 80 | P |
| 21 | 11 | 17 | dc1 | 121 | 51 | 81 | Q |
| 22 | 12 | 18 | dc2 | 122 | 52 | 82 | R |
| 23 | 13 | 19 | dc3 | 123 | 53 | 83 | S |
| 24 | 14 | 20 | dc4 | 124 | 54 | 84 | T |
| 25 | 15 | 21 | nak | 125 | 55 | 85 | U |
| 26 | 16 | 22 | syn | 126 | 56 | 86 | V |
| 27 | 17 | 23 | etb | 127 | 57 | 87 | W |
| 30 | 18 | 24 | can | 130 | 58 | 88 | X |
| 31 | 19 | 25 | em | 131 | 59 | 89 | Y |
| 32 | 1a | 26 | sub | 132 | 5a | 90 | Z |
| 33 | 1b | 27 | esc | 133 | 5b | 91 | [ |
| 34 | 1c | 28 | fs | 134 | 5c | 92 | \ |
| 35 | 1d | 29 | gs | 135 | 5d | 93 | ] |
| 36 | 1e | 30 | re | 136 | 5e | 94 | ^ |
| 37 | 1f | 31 | us | 137 | 5f | 95 | _ |
| 40 | 20 | 32 | sp | 140 | 60 | 96 | ' |
| 41 | 21 | 33 | ! | 141 | 61 | 97 | a |
| 42 | 22 | 34 | " | 142 | 62 | 98 | b |
| 43 | 23 | 35 | # | 143 | 63 | 99 | c |
| 44 | 24 | 36 | $ | 144 | 64 | 100 | d |
| 45 | 25 | 37 | % | 145 | 65 | 101 | e |
| 46 | 26 | 38 | & | 146 | 66 | 102 | f |
| 47 | 27 | 39 | ` | 147 | 67 | 103 | g |
| 50 | 28 | 40 | ( | 150 | 68 | 104 | h |
| 51 | 29 | 41 | ) | 151 | 69 | 105 | i |
| 52 | 2a | 42 | * | 152 | 6a | 106 | j |
| 53 | 2b | 43 | + | 153 | 6b | 107 | k |
| 54 | 2c | 44 | , | 154 | 6c | 108 | l |
| 55 | 2d | 45 | - | 155 | 6d | 109 | m |
| 56 | 2e | 46 | . | 156 | 6e | 110 | n |
| 57 | 2f | 47 | / | 157 | 6f | 111 | o |
| 60 | 30 | 48 | 0 | 160 | 70 | 112 | p |
| 61 | 31 | 49 | 1 | 161 | 71 | 113 | q |
| 62 | 32 | 50 | 2 | 162 | 72 | 114 | r |
| 63 | 33 | 51 | 3 | 163 | 73 | 115 | s |
| 64 | 34 | 52 | 4 | 164 | 74 | 116 | t |
| 65 | 35 | 53 | 5 | 165 | 75 | 117 | u |
| 66 | 36 | 54 | 6 | 166 | 76 | 118 | v |
| 67 | 37 | 55 | 7 | 167 | 77 | 119 | w |
| 70 | 38 | 56 | 8 | 170 | 78 | 120 | x |
| 71 | 39 | 57 | 9 | 171 | 79 | 121 | y |
| 72 | 3a | 58 | : | 172 | 7a | 122 | z |
| 73 | 3b | 59 | ; | 173 | 7b | 123 | { |
| 74 | 3c | 60 | < | 174 | 7c | 124 | | |
| 75 | 3d | 61 | = | 175 | 7d | 125 | } |
| 76 | 3e | 62 | > | 176 | 7e | 126 | ~ |
| 77 | 3f | 63 | ? | 177 | 7f | 127 | del |
注意A-z段的ASCII字符,红色的字符[\]^_'是夹在Z和a之间的。也就是说A-z,不但包含了26个大小写英文字符,还包含了几个符号字符。要是规则是用于验证电子邮件的,那么“..\..\"这样的字符串可是会通过的哦!
也就是说只有A-Za-z规则才是真正的26个大小写英文字符过滤规则。(www.61k.com]大家在使用时千万别麻痹大意哦
摘自 paiooo的专栏
五 : NSRegularExpression iOS自带的正则表达式
以前做验证邮箱,电话号码的时候通常用第三方的正则表达式或者NSPredicate(点这里查看以前的文章),在后期,苹果推出了自己的正则表达式来提供给开发者调用,很方便,功能也强大.
具体可以查看官方文档,包括如何书写进行匹配的正则表达式例子,这里我就不多加详述了,因为本人看那一堆符号好烦.....只好直接求助于谷歌了,下面只给出几个常用的.
#define KPhoneRegex @"\\d{3}-\\d{8}|\\d{3}-\\d{7}|\\d{4}-\\d{8}|\\d{4}-\\d{7}|1+[358]+\\d{9}|\\d{8}|\\d{7}"#define KWebRegex @"((http[s]{0,1}|ftp)://[a-zA-Z0-9\\.\\-]+\\.([a-zA-Z]{2,4})(:\\d+)?(/[a-zA-Z0-9\\.\\-~!@#$%^&*+?:_/=<>]*)?)|(www.[a-zA-Z0-9\\.\\-]+\\.([a-zA-Z]{2,4})(:\\d+)?(/[a-zA-Z0-9\\.\\-~!@#$%^&*+?:_/=<>]*)?)"#define KWebOtherRegex @"http+:[^\\s]*"#define KEmailRegex @"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4}"/** 1. 返回所有匹配结果的集合(适合,从一段字符串中提取我们想要匹配的所有数据) * - (NSArray *)matchesInString:(NSString *)string options:(NSMatchingOptions)options range:(NSRange)range; 2. 返回正确匹配的个数(通过等于0,来验证邮箱,电话什么的,代替NSPredicate) * - (NSUInteger)numberOfMatchesInString:(NSString *)string options:(NSMatchingOptions)options range:(NSRange)range; 3. 返回第一个匹配的结果。[www.61k.com]注意,匹配的结果保存在 NSTextCheckingResult 类型中 * - (NSTextCheckingResult *)firstMatchInString:(NSString *)string options:(NSMatchingOptions)options range:(NSRange)range; 4. 返回第一个正确匹配结果字符串的NSRange * - (NSRange)rangeOfFirstMatchInString:(NSString *)string options:(NSMatchingOptions)options range:(NSRange)range; 5. block方法 * - (void)enumerateMatchesInString:(NSString *)string options:(NSMatchingOptions)options range:(NSRange)range usingBlock:(void (^)(NSTextCheckingResult *result, NSMatchingFlags flags, BOOL *stop))block; *//** * enum { NSRegularExpressionCaseInsensitive = 1 << 0, // 不区分大小写的 NSRegularExpressionAllowCommentsAndWhitespace = 1 << 1, // 忽略空格和# - NSRegularExpressionIgnoreMetacharacters= 1 << 2, // 整体化 NSRegularExpressionDotMatchesLineSeparators= 1 << 3, // 匹配任何字符,包括行分隔符 NSRegularExpressionAnchorsMatchLines = 1 << 4, // 允许^和$在匹配的开始和结束行 NSRegularExpressionUseUnixLineSeparators = 1 << 5, // (查找范围为整个的话无效) NSRegularExpressionUseUnicodeWordBoundaries= 1 << 6// (查找范围为整个的话无效) }; typedef NSUInteger NSRegularExpressionOptions; */// 下面2个枚举貌似都没什么意义,除了在block方法中,一般情况下,直接给0吧/** * enum { NSMatchingReportProgress = 1 << 0, NSMatchingReportCompletion = 1 << 1, NSMatchingAnchored = 1 << 2, NSMatchingWithTransparentBounds = 1 << 3, NSMatchingWithoutAnchoringBounds = 1 << 4 }; typedef NSUInteger NSMatchingOptions; *//** 此枚举值只在5.block方法中用到 * enum { NSMatchingProgress = 1 << 0, NSMatchingCompleted = 1 << 1, NSMatchingHitEnd = 1 << 2, NSMatchingRequiredEnd= 1 << 3, NSMatchingInternalError = 1 << 4 }; typedef NSUInteger NSMatchingFlags; */// 测试字符串,把里面的电话号码解析出来NSString *urlString = @"哈哈哈哈呵呵呵s15279107723在这里啊啊啊啊s15279107716";NSError *error = NULL;// 根据匹配条件,创建了一个正则表达式(类方法,实例方法类似)NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:KPhoneRegex options:NSRegularExpressionCaseInsensitive error:&error];if (regex != nil) {// 3.....NSTextCheckingResult *firstMatch = [regex firstMatchInString:urlString options:0range:NSMakeRange(0, [urlString length])];if (firstMatch) {NSRange resultRange = [firstMatch rangeAtIndex:0];//从urlString中截取数据NSString *result = [urlString substringWithRange:resultRange];NSLog(@"result = %@",result);}// 2.....NSUInteger number = [regex numberOfMatchesInString:urlString options:0 range:NSMakeRange(0, [urlString length])];NSLog(@"number = %ld",number);// 5.....(坑爹的返回第一个匹配结果)[regex enumerateMatchesInString:urlString options:0 range:NSMakeRange(0, [urlString length]) usingBlock:^(NSTextCheckingResult *result, NSMatchingFlags flags, BOOL *stop) {NSLog(@"---%@",NSStringFromRange([result range]));if (flags != NSMatchingInternalError) {NSRange firstHalfRange = [result rangeAtIndex:0];if (firstHalfRange.length > 0) {NSString *resultString1 = [urlString substringWithRange:firstHalfRange];NSLog(@"result1 = %@",resultString1);}}*stop = YES;}];}// 替换掉你要匹配的字符串NSString *reString = [regex stringByReplacingMatchesInString:urlStringoptions:0range:NSMakeRange(0, [urlString length])withTemplate:@"(我就是替换的值)"];NSLog(@"reString = %@",reString);// 还有2个方法大家可以去尝试看看// 1.NSMutableArray *oneArray = [self _matchLinkWithStr:urlString withMatchStr:KPhoneRegex];for (NSString *phone in oneArray) {NSLog(@"phone = %@",phone);}// 1.....- (NSMutableArray *)_matchLinkWithStr:(NSString *)str withMatchStr:(NSString *)matchRegex;{NSError *error = NULL;NSRegularExpression *reg = [NSRegularExpression regularExpressionWithPattern:matchRegex options:NSRegularExpressionCaseInsensitive error:&error];NSArray *match = [reg matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, [str length])];NSMutableArray *rangeArr = [NSMutableArray array];// 取得所有的NSRange对象if(match.count != 0){for (NSTextCheckingResult *matc in match){NSRange range = [matc range];NSValue *value = [NSValue valueWithRange:range];[rangeArr addObject:value];}}// 将要匹配的值取出来,存入数组当中__block NSMutableArray *mulArr = [NSMutableArray array];[rangeArr enumerateObjectsUsingBlock:^(id obj, NSUInteger idx, BOOL *stop) {NSValue *value = (NSValue *)obj;NSRange range = [value rangeValue];[mulArr addObject:[str substringWithRange:range]];}];return mulArr;}@结果:
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1