一 : 百度程一仕:细节是大规模分布式存储架构的关键
“MosseFS和redis架构是最近比较热门的话题,百度在MosseFS和redis海量存储下进行架构改进和性能提升的关键在于优化升级与细节把控。”4月19日,百度运维部MFS组技术负责人,负责分布式文件系统MFS和分布式KV系统BDRP的二次开发维护的程一仕在第49期百度技术沙龙现场上说。
MosseFS和redis架构其实和hdfs的架构是一样的,它们都是google file system。本期百度技术沙龙,程一仕老师主要为大家分享了百度技术团队图和通过对MooseFS的单点master的架构升级来提升系统的性能和扩展性,进而支撑百度的众多业务。
本期恰逢百度技术沙龙4周年。4年来,百度技术沙龙一直致力于以“技术开放”的心态,分享行业领先的技术理念和技术实践。秉承“畅想、交流、争鸣、聚会”的理念,为互联网工程师、软件开发者提供一个快速学习和不断成长的平台。

百度运维部MFS组技术负责人程一仕说:“百度有共有集群,很多小产品线都会上来,我们做流量控制的初衷,是因为我们要防止一个产品线变得乱七八糟。”
独立开发架构 百度高度优化MosseFS和redis
在本期技术沙龙上,程一仕先向大家介绍了MosseFS和redis目前架构上出现的问题:一个是性能瓶颈,因为这个设计是非常强中心化的设计,它是分布式系统里面的状态,因此它的性能其实是非常耗的。另一个是错误处理,即扩展性问题。基于这两个问题,程一仕详细讲解了百度在MooseFS和redis下进行的改进和性能提升。
“我们做的第一个改进就是开发一个Shadow master,这个架构的设计是master会处理所有的写请求,shadow master会处理大部分的请求,它的变更不一定到master。为了避免没有请求,我们还在客户端做了一个简单的路由,路由的策略全部到master。”程一仕表示。
据程一仕介绍, 基于这个架构,理论上,master承担每秒10个万请求,shadow master能承担2万左右。而实际上master每处理10万个请求的话,shadow master可以处理7万到8万,也就是说整个服务的请求,shadow master可以分到40%之多。
对于第二个错误处理的问题,为了解决这个问题,程一仕和他的团队做了Slave,它主要负责在故障出现的时候做切换去接管整个集群。
“最开始的时候整个架构就是这样的,我们后面加了shadow master。后面又加了一个slave的东西,去做强一致的替换,我们在master上面做了一些工作。”程一仕解释道。
细节决定一切解决方案时不要怕“坑”
程一仕强调:“百度使用redis的代理中间层构建高可用的分布式redis集群来满足产品的低延迟以及大数据量的业务需求。这两个系统广泛应用于百度商业产品体系,LBS产品体系,数据库文件热备等在线业务,并支撑大量关键服务。”
在分享即将结束时,程一仕还跟大家分享了他的一些感悟,他强调,细节决定着一切,“分布式存储的架构没有什么变化,最重要的就是它的细节,它的细节非常麻烦,也非常多,一个处理不好,就会让一个集群挂掉。一个处理流程太长,这些东西在我个人看来没有什么很好的办法,只有不断的踩“坑”,所以我觉得需要在细节上面需要注意很多问题。”

程一仕强调细节非常重要。
另外, 程一仕鼓励大家在解决方案时不要“坑”。“我们觉得开源软软件很坑,是因为它没有资料。当你觉得坑的时候,你了解为什么坑,而不要只是说系统挂掉了,为什么挂,我也不知道,只是让你看代码,很多开源软件只有一万行或者是两万行,你看一个月就能够搞的非常清楚了,它有坑你就把它修掉。”
一位参加此次沙龙的观众表示,对于noSql,他是最近才去了解的,“我对于解决方案操作还不够熟练,听完陈老师的讲课后,很有收获。”这位观众说。
历时四载 百度技术沙龙广受追捧
本期技术沙龙恰好是百度技术沙龙4周年,现场很多听众都通过微博或微信为百度技术沙龙送上了祝福。主办方也为大家准备了50吋的大蛋糕共同庆生。
现场除了主讲的程一仕老师和陈伟老师,百度技术沙龙上海站讲师,曾在第43期百度技术沙龙亮相的陈晔老师也从上海赶来为百度技术沙龙庆生。

程一仕、陈伟和上海讲师陈晔共同揭开庆生蛋糕。
微信用户朱秋旭表示,和百度技术沙龙共同成长的日子里他收获了很多。微信网友mobei则表示“希望百度技术沙龙继续坚持下去,成为工程师们的精神家园 。”
在技术沙龙结束后,现场很多人都感到意犹未尽。他们纷纷添加百度技术沙龙的官方微信,并主动找程一仕交流大规模分布式存储的核心技术和原理。
百度技术沙龙是百度每月组织的一项技术开放交流活动,至今已经连续举办了4年,总共49期。百度技术沙龙一直致力于以“技术开放”的心态,分享行业领先的技术理念和技术实践。这种变革与分享、践行技术开放的行动得到了业内人士的广泛认可,目前北京的技术人员已经把百度技术沙龙当成了自己的精神家园。百度技术沙龙也希望日后能够有效推动中国互联网的技术发展与行业创新。
二 : 分布式缓存-Memcached
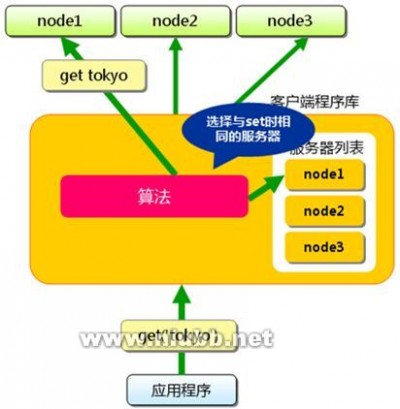
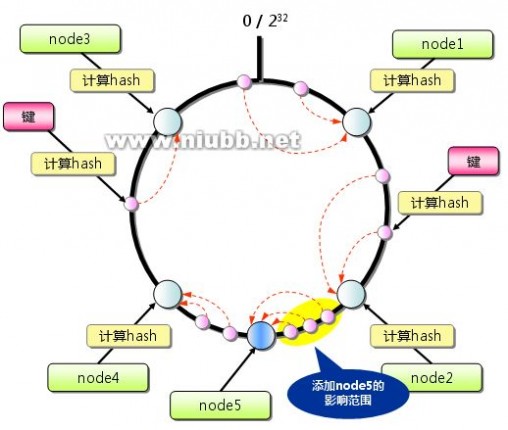
分布式缓存出于如下考虑,首先是缓存本身的水平线性扩展问题,其次是缓存大并发下的本身的性能问题,再次避免缓存的单点故障问题(多副本和副本一致性)。分布式缓存的核心技术包括首先是内存本身的管理问题,包括了内存的分配,管理和回收机制。其次是分布式管理和分布式算法,其次是缓存键值管理和路由。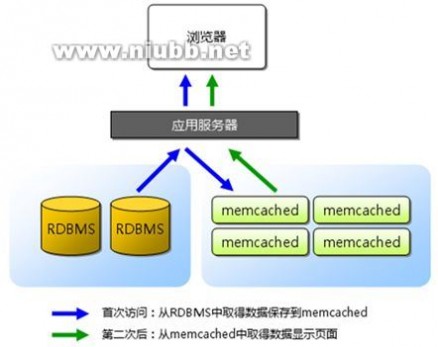


三 : 原创:.NET版分布式缓存Memcached测试实例
下面测试下分布式缓存Memcached软件,一直在学习关注大访问量网站的缓存是如何实现,之前看过Memcached的资料,忙于没有时间来真正测试一下,本文测试分布式缓存Memcached的环境如下:(两台电脑作为服务器)
第一台:
CPU:Inter(R) Pentium(R) 4 CPU 2.8G
内存:1G
系统:windows 7
IIS: IIS 7
IP:172.10.1.97
环境:本地
安装:memcached 1.2.1 for Win32
第二台:
CPU:Inter(R) Pentium(R) 4 CPU 3.0G
内存:2G
系统:windows Server 2003
IIS: IIS 6
IP:172.10.1.236
环境:远程
安装:memcached 1.2.1 for Win32
测试程序部署到本地环境(172.10.1.97),开发工具VS2008 .NET3.5
本文使用到memcached 1.2.1 for Win32下载地址:
http://jehiah.cz/projects/memcached-win32/
更多memcached版本大全请进入
好了,下面我们按步骤来测试:
第一、首先到把下载好的memcached 1.2.1解压到C:memcached目录,分别复制到两台服务器中。
第二、安装memcached服务,在命令提示符输入CD c:memcached进入到memcached目录,如下图:
之后输入memcached -h 回车,看帮助说明,接下来输入memcached -d install 回车即可自动安装memcached服务了,如下图:

安装memcached服务图
安装好安装memcached服务后,输入memcached -d start 回车启动memcached服务,如下图:

启动memcached服务图
在172.10.1.97与172.10.1.236两台电脑都按以上操作来安装启动memcached。
第三、下载.NET版memcached客户端API组件来写测试程序。
本文使用memcacheddotnet,下载地址如下:
http://sourceforge.net/projects/memcacheddotnet/
下载好之后把这些文件Commons.dll,ICSharpCode.SharpZipLib.dll,log4net.dll,Memcached.ClientLibrary.dll放到bin目录(少一个都不行),之后再到测试项目开发环境引用Memcached.ClientLibrary.dll,如下图

引用Memcached.ClientLibrary.dll图
第四、测试程序:
| 以下为引用的内容: using System; using System.Collections; using System.Text; // 须引用Memcached using Memcached.ClientLibrary; namespace test { public partial class _Default : System.Web.UI.Page { protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { if (Request["action"] == "clear") this.clear(); else this.test(); } } /// <summary> /// 清空缓存 /// </summary> public void clear() { string[] servers = { "172.10.1.97:11211", "172.10.1.236:11211" }; //初始化池 SockIOPool pool = SockIOPool.GetInstance(); pool.SetServers(servers); pool.InitConnections = 3; pool.MinConnections = 3; pool.MaxConnections = 5; pool.SocketConnectTimeout = 1000; pool.SocketTimeout = 3000; pool.MaintenanceSleep = 30; pool.Failover = true; pool.Nagle = false; pool.Initialize(); MemcachedClient mc = new Memcached.ClientLibrary.MemcachedClient(); mc.EnableCompression = false; mc.Delete("cache"); mc.Delete("endCache"); Response.Write("清空缓存成功"); } /// <summary> /// 测试缓存 /// </summary> public void test() { //分布Memcachedf服务IP 端口 string[] servers = { "172.10.1.97:11211","172.10.1.236:11211" }; //初始化池 SockIOPool pool = SockIOPool.GetInstance(); pool.SetServers(servers); pool.InitConnections = 3; pool.MinConnections = 3; pool.MaxConnections = 5; pool.SocketConnectTimeout = 1000; pool.SocketTimeout = 3000; pool.MaintenanceSleep = 30; pool.Failover = true; pool.Nagle = false; pool.Initialize(); //客户端实例 MemcachedClient mc = new Memcached.ClientLibrary.MemcachedClient(); mc.EnableCompression = false; StringBuilder sb = new StringBuilder(); //写入缓存 sb.AppendLine("写入缓存测试:"); sb.AppendLine("<br>_______________________________________<br>"); if (mc.KeyExists("cache")) { sb.AppendLine("缓存cache已存在"); } else { mc.Set("cache", "写入缓存时间:" DateTime.Now.ToString()); sb.AppendLine("缓存已成功写入到cache"); } sb.AppendLine("<br>_______________________________________<br>"); sb.AppendLine("读取缓存内容如下:<br>"); sb.AppendLine(mc.Get("cache").ToString()); //测试缓存过期 sb.AppendLine("<br>_______________________________________<br>"); if (mc.KeyExists("endCache")) { sb.AppendLine("缓存endCache已存在,过期时间为:" mc.Get("endCache").ToString()); } else { mc.Set("endCache", DateTime.Now.AddMinutes(1).ToString(), DateTime.Now.AddMinutes(1)); sb.AppendLine("缓存已更新写入到endCache,写入时间:" DateTime.Now.ToString() " 过期时间:" DateTime.Now.AddMinutes(1).ToString()); } //分析缓存状态 Hashtable ht = mc.Stats(); sb.AppendLine("<br>_______________________________________<br>"); sb.AppendLine("Memcached Stats:"); sb.AppendLine("<br>_______________________________________<br>"); foreach (DictionaryEntry de in ht) { Hashtable info = (Hashtable)de.Value; foreach (DictionaryEntry de2 in info) { sb.AppendLine(de2.Key.ToString() ": " de2.Value.ToString() "<br>"); } } Response.Write(sb.ToString()); } } |
第五、 运行看效果:

缓存效果图我在本地172.10.1.97运行memcached -d
stop来停止memcached服务,运行上面程序,一样正确,说明缓存也同样保存到远程172.10.1.236这台服务器了。这样简单就可以实现分布式缓存,使用缓存又多了一个选择,不必使用.NET自带的Application与cache了,访问量大的网站实现分布式缓存有很多好处。有什么问题请指正,下期再出其它教程。转载请注明文章来源及原始链接,谢谢合作!原文:
本文标题:大规模分布式存储pdf-百度程一仕:细节是大规模分布式存储架构的关键61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1