一 : 火车头采集器怎么采集文章?
有时候我们看到一个网站的文章,想要把这些文章保存下来,一篇一篇的复制保存很麻烦,这个时候就需要用到火车头采集器把文章采集下来保存了。下面介绍一下如何用火车头采集器采集文章。
第一步采集网址,下载好火车头采集器后打开,新建一个任务,任务名随意。把需要采集的网站文章列表页网址添加到起始网址。从图中看出该列表页有34页,每页有N篇文章。
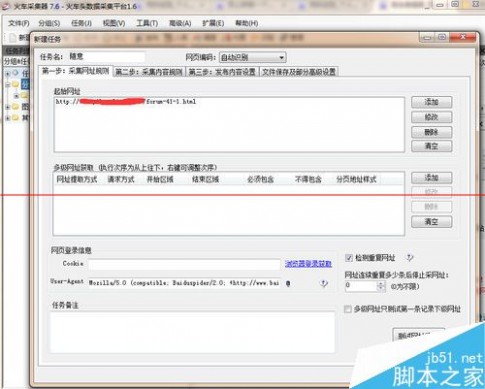

列表页会一级网址,添加多级网址获取,从而获取二级网址(文章页网址)
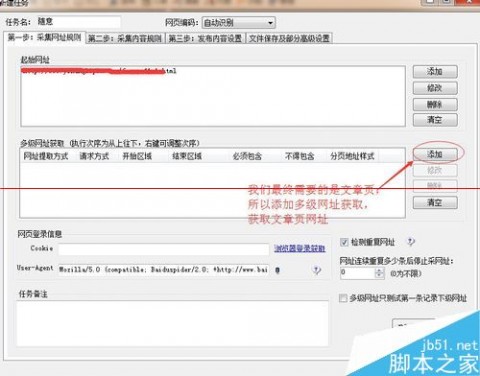
设置列表分页获取,3个地方分别是:分页源代码前面和后面还有中间位置。这一步用于获取列表页面链接,因为有34个列表页面。设置完保存。
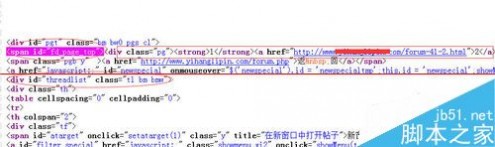

网址获取选项,这一步用于获取列表页上面文章页的链接,根据自己需要设置需要截取的部分和根据网址的结构设置包含与不包含某些字符。为空即没限制,设置完保存。

设置好链接采集规则后,可以测试网址,看测试结果调整规则。看图可以看到采集链接规则从起始链接到全面列表页再到列表页上的文章页链接都已经成功采集。

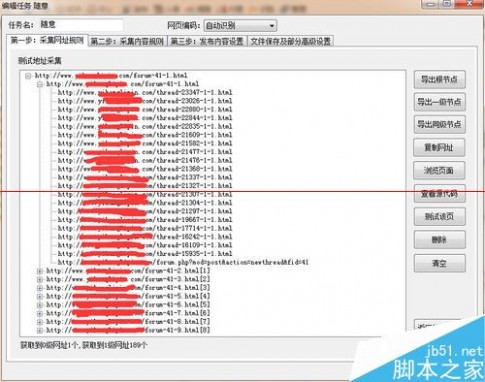
第二步是采集内容,首先修改标题规则,在页面源代码里面找到标题的代码,把标题前后代码负责过去截取出标题。保存。

修改内容采集规则,跟标题规则差不多,也是源代码里面找到内容的前后代码。这里内容会有一些其他html标签,所以得添加一个html标签排除的规则。
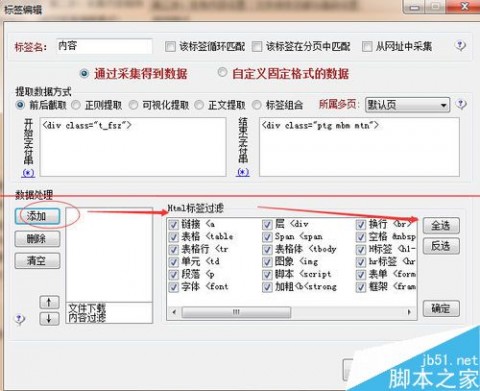
完成后,测试看一下结果,从测试结果来调试规则,直到测试结果是自己想要的内容为止。

第三步是采集导出。前面1、2两步把规则设置好,最后就要把文章导出了。先做一个导出的模版。
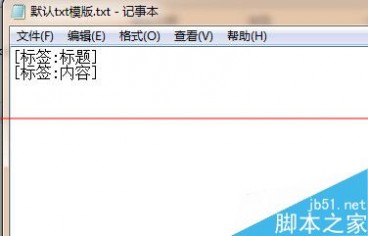
然后选择方式二,把每一篇文章都分别记录到一个txt文本,保存位置自己选择,模板选择刚刚做好的导出模版.保存的文件名用文章标题为命名。其他默认,保存。

把采集网址,采集内容,发布3个选项框都勾选,然后开始采集。完成后文本就自动生成在刚刚保存的文件夹里面了。


火车头采集器采集文章教程到此就完成了,由于每个网站都是不一样的,所以这里只能用一个网站演示,只是一个方法思路,自己采集文章还需要灵活变通。
二 : shopex采集发布接口 shopex火车头数据采集器(20120812更新) 使用火车
一直想在shopex中实现以下功能:(欢迎广大网友交流 qq:158393237)
1 找供应商采购谈判 给你进货价
2 一键采集供应商给你的所有商品(批量采集产品价格、批量采集多图、批量发布、批量去水印、批量打上你的店标和logo)
3 “叮”的一声 ,1万条来自不同地区供应商的产品全部发布到你的网站了,而且都是真真实实的成本价、销售价业务数据,及时报告库存不足,那么剩下的是不是就剩下网络营销了呢?
ShopEx采集发布接口 For 火车采集器
2012-08-12 更新后接口版本升级为ShopEx_SP1_build20100921,请大家核对版本,快客的接口用户可享受免费升级服务
快客的此版本接口已通过至少20个不同服务器网站测试,并赢得大量用户好评,请大家放心使用
ShopEx采集程序简介
功能简介
更新日志:
2012-08-12更新(重要)
Bug性更新:
功能性更新:
产品部分截图演示
发布后前台效果截图(ShopEx默认模板)

后台效果图
后台效果1
后台效果2
详细参数发布演示(京东)
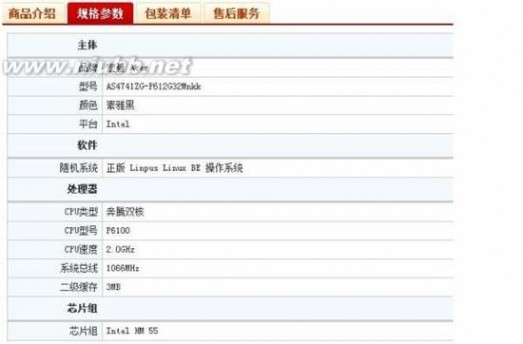
京东商城详细参数表
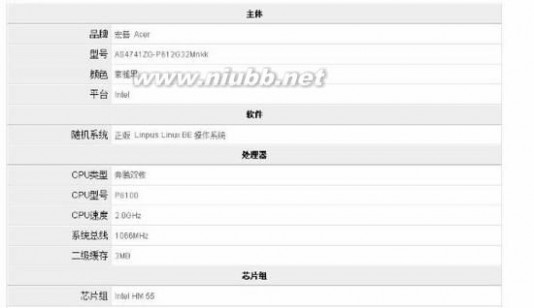 完美发布详细参数表发布到ShopEx
完美发布详细参数表发布到ShopEx
其它采集接口目录:
入库代码:
//供应商来源货位 供应商名称-网址-qq号码-旺旺-电话-地点
$store_place="快客-www.kk580.com-1055746587-13765152798-深圳";
$brief="该商品属于核心渠道批发类,380元起批,不限制单价可以混批,淘宝代理商也可自行选择单件起批类型。如无此注明,均为单件起批,核心渠道批发类对应编号为9245fe4a-d402-451c-b9ed-9c1a04247482";
//商品入库
$query = "insert into sdb_goods (cat_id,type_id,goods_type,brand_id,brand,image_default,thumbnail_pic,small_pic,big_pic,image_file,brief,intro,mktprice,cost,price,bn,name,weight,unit,store,store_place,score,spec,pdt_desc,spec_desc,uptime,last_modify) VALUES('$fenlei','1','normal','$brand_id','$brand','','$insertarraythumbnail','$insertsmall','$insertarybigpic','','$brief','$intro','$mktprice','0','$price','$bn','$name','$goodsWeight','$jldw','100','$store_place','0','','','','$time','$time')";
$rs=mysql_query($query);
if($rs) echo "成功!"; else echo mysql_error()."入库错误";
三 : 五大免费采集器哪个好,火车头,海纳,ET,三人行,狂人采集
在目前的站长圈内,比较流行的采集工具有很多,但是总结起来,比较出名的免费的就这么几个:火车头,海纳,ET,三人行,狂人。
下面我们对这几款采集工具作一个简单的评比。
1.火车头 基本上人人都知道,那就放第一位,要多说两句。
火车头应该是国内采集软件最成功的典型之一,使用人数包括收费用户数量上应该是最多的
特色:简单,功能强大,速度快,支持的网站最丰富,支持丰富扩展
优点:功能比较齐全,采集速度比较快,主要针对cms,短时间可以采集很多,过滤,替换都不错,比较详细;很多人写接口、规则和发布模块,接口比较齐全,其中有个叫尘缘的人,几乎开发目前所有PHP类CMS的接口;支持的扩展非常好用,如果你是一位懂技术的站,可以使用PHP或者C#开发任意功能的扩展,实再令人好生难忘;附件采集功能完善。
技术:技术主要是论坛支持,帮助文件多,上手容易。有收费、免费版本
缺点:功能增多,软件越来越大,比较占用内存和CPU资源,资源回收控制得不好
2.三人行(狂人) 主要针对论坛的采集,功能比较完善
先申明,不知道三人行和狂人是什么关系,但界面和功能都是一个模子出来的。
特色:针对各大论坛,搬家,移动,速度快,准确度高
优点:还是针对论坛,适合开论坛的
技术:收费技术,免费有广告
缺点:超级复杂,上手难,对cms支持比较差
3.ET工具
特色:无人值守,稳定,资源占用最低,基本上可以叫安静
优点:无人值守,自动更新,适合长期做站,用户群主要集中在长期做站潜水站长。软件清晰,必备功能也很齐全,关键是软件免费,听说已经增加采集中英文翻译功能。
技术:论坛支持,软件本身免费,但是也提供收费服务。帮助文件较少,上手不容易
缺点:对论坛和CMS的支持一般
4.海纳
特色:海量,关键词抓取,可以预览采集内容,不用写规则
优点:海量,可以抓取网站很多一个关键词文章,似乎适合做网站的专题,特别是文章类、博客类
技术:无论坛 收费,免费有功能限制
缺点:分类不方便,也就说采集文章归类不方便,要手动(自动容易混淆),特定接口,采集的内容有限
5.狂人
特色:可以让你的新论坛一开始就会有大量的会员.
优点:非常适合采集discuz论坛
缺点:过于专一,兼容性不好。
总结:追求功能齐全的,似乎应该选择火车头,火车头被称之为“无所不能”,初期作站,可以迅速采集很多的资源,充实网站内容。如果做论坛,那选择三人行,没错了,可以实现采集论坛,回复,搬家等多项论坛功能。长期做站,当然选择ET了,花点时间,弄懂,是个长期受益的事情。写好规则,设置好过滤替换,然后可以像开QQ一样,长期运行,不费内存,自动采集更新,分类明确,采集内容完整,可是说,一个站,一个站长+ET足够了。至于海纳,似乎不写规则,上手容易,但是对文章的发布上,不能如ET一劳
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1