一 : 高考期间妈妈和儿子陪读住,这个事真的吗?
高考期间妈妈和儿子陪读住,这个事真的吗?
网上说:
高考期间妈妈千万不要和儿子陪读住!
现在母子那事的不少,我开旅店的见识多了去了,特别是那种当妈的30左右不算太大,还有点姿色的偏多,进屋开完房间,过会儿里面就喘息连连,出来就跟没事人似的
特别是那些,高考期间陪读的母亲和儿子,孩子压力大,母亲对孩子百依百顺的,夏天而且母亲年龄也不算大,一般穿个丝袜,有点姿色,皮肤还好点的,特容易诱惑孩子,
特别是一般都住旅馆单间的,很容易因为受到隔壁处对象的小年轻的激烈干扰,发生这样的情况,给我这个开旅店的打败了!
我原先就碰到一对母子,母亲也就35,挎个包穿个薄连衣裙黑丝袜,孩子虽长的比我都高,但也看起来听话,高考嘛房间紧张,我就把她俩安排到一小年轻的隔壁,半夜小年轻的那屋喘息连连啊,过一阵了,我以为过去了,我准备睡觉,就感觉早上来的那陪读的那娘俩那屋,动静不对劲,像是在床上扑腾嘎吱扑腾的那种,我还以为在床上打架了?过了好一会儿,居然有做爱的那种声了,我艹!绝不会听错,天打五雷轰!我开多少年旅店了,我都开门听了,害的我一夜没睡啊(我的屋就在她们屋对面,这孩子得折腾他她4、5次),第二天我看见那母亲借我梳子梳头,头发有点乱,脖子上有嘴印,丝袜也有丁点破了,估计她儿子没少折腾这一宿 这社会我服了 这也学人家日本啊
这就是当前的一些不正当的社会现象吧.
二 : 你应该了解的 一些web缓存相关的概念.
说明:本帖主要针对各个环节的缓存代理,以及本地用户代理(浏览器)上的缓存策略.
ps:应舍瓦大大要求,从我的evernote里翻找出这篇和cache相关的东西. 难免有错漏指出,欢迎指正.
代理服务器简分类:(并不太全,仅当科普, 了解代理在web中的重要作用是有必要的.这里仅仅是简单介绍下.)
缓存角度分类:
(1) 缓存代理 : 根据某种约定,缓存曾经请求过的数据
(2) 常规代理 : 只转发请求的那一种.并不缓存数据的代理
控制方分类:
(1) 反向代理:(对于原始服务器来说,反向代理即是一个客户端)
a) 服务提供者主观使用,并控制.
b) 相对其他客户端来说,离原始服务器最近(主观上)
c) 转发请求,缓存,用于负载均衡.
d) 屏蔽其他客户端与原始服务器的直接联,避免原始服务器被直接攻击
e) CDN的应用(严格来说,CDN已经并非纯粹意义上的反向代理了.)
(2) 非反向代理: (非服务提供者所控制)
其他分类:
(1) 用户代理
a) 浏览器
b) 各类终端机
c) 搜索引擎爬虫.
(2) 透明代理
(3) 拦截代理
(4) http代理
(5) socket代理(UDP,FTP…etc)
缓存相关的约定,HTTP协议、相关概念
HTTP1.1协议:
继承自http1.0,在其基础上扩展或修改而产生. 比如1.0中Date标头,允许使用的RFC1036日期格式,的千年虫问题的修正.悲剧的是,有些明显的错误,无法矫正,比如一个著名的拼写错误. Referer 标头的拼写错误.一直沿用至今.因其,已经被广泛应用.在实际使用上,又无伤大雅,所以也就被继续将错就错了.
实体: 用于表示一个,请求或响应的消息中的一个资源,如post提交的表单内容,或请求服务器上的abc.jpg时,abc.jpg就代表一个实体.对于一个实体响应来说,除去响应标头外所剩余的部分,即是实体主体部分,比如abc.jpg的真实2进制数据.
标头(头域):
(1) 请求标头 : 在一个请求中使用的相关标头,用于添加附加信息,或对被请求服务器增加限制.
(2) 响应标头 : 用于添加相关响应的附加信息.
(3) 实体标头 : 提供实体相关的附加信息,如果修改时间,实体的大小等等.
(4) 常规标头 : (通用标头)在请求和响应中都可以使用的一些常规标头,如HTTP1.0所定义的Date.和 Pragma(是的,这并不是一个实体标头,它仅仅是试图与客户端,包括代理,进行协商,不要使用缓存的副本.).
补充:HTTP1.1的常规标头:
Date,Pragma,Cache-Control,Connection,Transfer-Encoding,Upgrade,Trailer,Via,Warning
缓存相关标头:
. Expires (实体标头,HTTP 1.0+)
一个GMT时间,试图告知客户端,在此日期内,可以信任并使用对应缓存中的副本,缺点是,一但客户端日期不准确.则可能导致失效.
.Pragma : no-cache(常规标头,http1.0+)
对Pragma定义的唯一的伪指令,同http1.1的Cache-Control : no-cache
.Last-Modified(实体标头,HTTP1.0+)
一个GMT时间,告知,被请求实体的最后修改时间.用于客户端校验其缓存副本是否仍然可以信任.与其相关的两个条件请求标头:
(1) If-Modified-Since:(此标头,仅对Get方法有意义)
如果实体在指定时间后,没有修改则返回一个304,否则返回一个常规的Get请求的响应(比如200). 另外,如果该标头的值是一个非法的值,那么也同样返回一个常规的Get请求的响应.
PS:用户代理发起 If-Modified-Since尝试握手的条件,可能会有不同,比如IE系,如果该实体第一次响应头中包含Cache-Control:no-cache.则 IE不会使用If-Modified-Since请求资源.而其他浏览器则会. 但是如果使用Cache-Control:no-store.则所有用户代理的表现一致.都不使用If-Modified-Since(因为no-store的语义十分强烈.不允许任何缓存,这个在后续有专门介绍.)
(2) If-Unmodified-Since:
如果实体在指定时间后,没有任何修改,那么就可以直接执行该请求使用方法的对应行为. 而如果有修改,则返回一个412 Precondition Failed状态码,并且抛弃该方法对应的行为操作(GET方法除外).
. Cache-Control : (常规标头,HTTP1.1)
.public:(仅为响应标头) 响应:告知任何途径的缓存者,可以无条件的缓存该响应. .private(仅为响应标头) 响应:告知缓存者(据我所知,是指用户代理,常见浏览器的本地缓存.用户也是指,系统用户.但也许,不应排除,某些网关,可以识别每个终端用户的情况),只针对单个用户缓存响应. 且可以具体指定某个字段.如private –“username”,则响应头中,名为username的标头内容,不会被共享缓存. .no-cache: 请求: 告知缓存者,必须原原本本的转发原始请求,并告知任何缓存者,别直接拿你缓存的副本,糊弄人.你需要去转发我的请求,并验证你的缓存(如果有的话).对应名词:端对端重载. 响应: 允许缓存者缓存副本.那么其实际价值是,总是强制缓存者,校验缓存的新鲜度.一旦确认新鲜,则可以使用缓存副本作为响应. no-cache,还可以指定某个包含字段,比如一个典型应用,no-cache=Set-Cookie. 这样做的结果,就是告知缓存者,对于Set-Cookie字段,你不要使用缓存内容.而是使用新滴.其他内容则可以使用缓存. .no-store: 请求:告知,请求和响应都禁止被缓存.(也许是出于隐私考虑) 响应:同上. .max-age: 请求:强制响应缓存者,根据该值,校验新鲜性.即与自身的Age值,与请求时间做比较.如果超出max-age值,则强制去服务器端验证.以确保返回一个新鲜的响应.其功能本质上与传统的Expires类似,但区别在于Expires是根据某个特定日期值做比较.一但缓存者自身的时间不准确.则结果可能就是错误的.而max-age,显然无此问题. Max-age的优先级也是高于Expires的. 响应:同上类似,只不过发出方不一样. .max-stale: 请求:意思是,我允许缓存者,发送一个,过期不超过指定秒数的,陈旧的缓存. 响应:同上. .must-revalidate(仅为响应标头) 响应:意思是,如果缓存过了新鲜期,则必须重新验证.而不是试图返回一个不在新鲜期的缓存.与no-cache的区别在于,no-cache,完全无视新鲜期的概念.总是强制重新验证.理论上,must-revalidate更节省流量,但相比no-cache,可能并不总是那么精准.因为即使缓存者,认为是新鲜的,也不能保证服务器端没有做过更新.如果缓存者是一个缓存代理服务器,如果其试图重新验证时,无法连接上原始服务器,则也不允许返回一个不新鲜的,缓存中的副本.而是必须返回一个504 Gateway timeout. .proxy-revalidate(仅为响应标头) 响应:限制上与must-revalidate类似.区别在于受体的范围.proxy-revalidate,是要排除掉用户代理的缓存的.即,其规则并不应用于用户代理的本地缓存上. .min-fresh(仅为请求标头) 请求:告知缓存者,如果当前时间加上min-fresh的值,超了该缓存的过期时间.则要给我一个新的.其实个人觉得,其功能上有点和max-age类似.但是更大的是语义上的区别. .only-if-cached:(仅为请求标头) 请求:告知缓存者,我希望内容来自缓存,我并不关心被缓存响应,是否是新鲜的. .s-maxage(仅为响应标头) 响应:与max-age的唯一区别是,s-maxage仅仅应用于共享缓存.而不引用于用户代理的本地缓存,等针对单用户的缓存. 另外,s-maxage的优先级要高于max-age. .cache-extension (cache-extension是一个泛化的代称.它指所有自定义,或者说扩展的,指令,客户端和服务器端都可以自定义扩展Cache-Control相关的指令.) 那么,实际上我们可以这样 Cache-Control:max-age=300, custom-directive = xxx, public. 这样我们就定义了一个被统称为cache-extension的扩展指令.该指令如果对应的客户端或服务器端,不认识,就会忽略掉. 扩展指令中一个常见的东西是 none-check post-check 和 pre-check. 这玩意是IE5被加入的. 所以如果响应头中有这几个扩展指令,那么IE就会认得他们, 我经常在一些 为了解决 no-cache + gzip 命中ie6 JSONP 请求,导致脚本不执行bug的方案中见到这几个扩展指令,其目的是为了让IE放弃使用本地缓存. 我倒是觉得,对IE6放弃使用gzip,是更合理的做法. 当然缺点也很明显, 如果是cdn部署静态资源.显然这样做会很困难. bug描述: IE6,某些情况下,开启gzip的资源,会不渲染或不执行(如果是.js的话.) 会引发此bug的条件: 1. 首先,必须由a页面脚本导致跳转到b页面 : 即 a页面有 location.href = b页面.(点链接,form post,replace, assign等方式都会导致问题,包括target=_blank弹窗的情况) 2. b页面自身,或其使用动态创建脚本(硬编码script src=xxx 也会有此问题) 的响应头中包含下面情况: cache-control 包含下列伪指令: (1) no-store (2) no-cache + 其他与缓存新鲜度检验有关头共存时, 如 max-age=xxx (xxx无所谓.0 或3000都会触发,) 或 no-cache + must-revalidate甚至是,no-cache, pre-check=0等情况.. (3) no-cache独立存在时,体现为一种不稳定情况.即当访问页面被cache时,可能会触发.但也不是100%.仅仅是偶尔... 遇到以上情况,页面可能会不渲染,而脚本可能会不执行. ps: 本bug ,与 http1.0 头域 : Pragma : no-cache ,无关. 解决办法: 1. 放弃压缩. 2. 放弃cache-control 中的 no-cache,no-store头域. 比如 单独使用max-age=0.并对不支持http1.0的老浏览器配合Expires = 一个过期时间. 关于这个bug的msdn的描述: To work around this problem, you can do either of the following: If you use a Cache-Control: no-cache HTTP header to prevent the files from caching, remove that header. In some situations, if you substitute an Expires HTTP header, you do not trigger the problem. 显然,微软给了我们两条路,去掉no-cache头,或者使用Expires指定过期时间,强制使其过期代替no-cache, 或者别压缩. 而pre-check=0.显然可以代替Expires做到这件事. 关于这几个扩展指令的, 参考msdn 的描述:http://msdn.microsoft.com/en-us/library/ms533020%28VS.85%29.aspx#Use_Cache-Control_Extensions
一张图: 简单来说, 就是控制IE,如何使用本地缓存 ,如果缓存时间,超过post-check的值,就要保证下一次请求该资源,去要验证过的新鲜的.而pre-check则是超过了,就马上给个新的. no-check就无需解释了.. .no-transform 请求:告知代理,不要更改媒体类型,比如jpg,被你改成png. 响应:同上. |
.Etag :(实体标头,HTTP1.1)
通过[Mog95],(
遗憾的是,该地址,现在似乎访问不能.)生成一段可代表实体版本的字串.默认就是一段hash + 时间戳的形式.其实我们是可以使用自己的算法来生成Etag值.比如md5.
PS:Apache的默认Etag包含Inode,Mtime,Size三部分.而且Etag有强弱之分.比如一般的弱Etag,是以W/开头的,如:W/”abcde12”,这部分不是我们关注的焦点.因为弱Etag和强Etag的区别只在于算法.比如某种弱Etag关注的时间精度,为秒.而我们在项目中,最常见的做法是使用MD5.是一种忽略时间维度的,强Etag.为的是保证精确度.以及负载均衡设备的同步.除非我们的项目有特殊需求.但是往往我们可以根据需求,来调整算法.而不是沿用一些传统的弱Etag算法.
这东西,是要和客户端的两个请求标头配合使用的:
(1) If-Match:
语义:如果有匹配,或者值为”*”,才可以能去执行,请求所使用的方法,所对应的行为.
If-Match,可以看做是一个过滤器,主要应用于资源多版本共存的解决方案.比如服务器端对同一实体,有多个版本.那么客户端,即可按照指定版本来获取实体.
If-Match的值就是对应指定版本的Etag值.这个值可以是多选的.典型的应用场景是,客户端使用put方式请求服务器端,并带有多个If-Match的值.服务器端检查所有该实体的版本.找到匹配项,就立刻更新服务器端的对应版本.如果无一匹配,则发送一个412 Precondition Failed状态码.
(2) If-None-Match:
语义:如果有任何匹配,或值是”*”,并且原始服务器存在其请求的实体,则不允许执行该请求所使用放的对应行为,如果此时,该请求使用的get,或head方法.则返回一个304状态码.以及其他一些相关的缓存控制的标头.
与If-Match相反 .但它的典型应用,也是我们要关注的部分.支持http1.1的现代浏览器,以及web server,应用If-None-Match头用于,缓存新鲜度校验.典型应用场景就是,一但原始服务器的某个响应中包含Etag时,如果浏览器本地缓存了该实体.那么在第二次的常规的get或head请求时,就会自动带上 If-None-Match头.当原始服务器上该实体的版本对应的Etag值与之匹配时,则原始服务器会返回304状态码.然后浏览器认为本地缓存是新鲜的.则继续使用缓存的实体. 但,其实Etag的本意是版本管理.而并不是缓存有效性校验.这应该是一个衍生出来的使用方式. 而这种方式相比Last-Modified校验方式的好处是,如果我们消除时间戳部分,仅使用hash作为Etag值. 就可以方便做负载均衡同步.
.Age(响应标头,HTTP1.1)
Age标头,对于原始服务器来说,用于指明,当前资源被生成了多久,即存活期.而对于一个缓存代理服务器来说,它表示缓存副本,被缓存了多久.缓存代理服务器,必须生成Age头.其值以秒为单位.且可能为负值.
.Vary(响应标头,HTTP1.1)
Vary标头,用于列出一组响应标头,用于缓存者从其缓存副本中筛选合适的变体.举个例子来说,不同的请求方法,导致对同一资源的响应有区别.这就导致缓存者有多份缓存副本.那么Vary所列出的标头项,就是选择副本时的一个重要依据. 比如Vary:Accept-Language.那么如果新的请求中的Accept-Language标头的值,而原始请求(被缓存的那个)中并未包含与之匹配的Accept-Language的标头的话.那就必须放弃该副本.而是把请求转发到原始服务器.
另一个Vary的典型应用是,Vary:Accept-Encoding.这样做的意义在于,某些用户使用的浏览器,可能不支持一些特定的压缩算法.那么当这个用户途径的某个共享的缓存代理服务器,所缓存的使用了某种压缩算法的响应,就不能直接返回给该用户.如果服务器端,并没有配置这个标头,那就可能产生悲剧.即用户的浏览器无法解压缩返回的资源.导致各种异常状况的出现.
范围相关标头.以及缓存的意义.
请求标头:
.Range : 1000- | -1000 | 0 - Content-Length
Range头可以指定像服务器(并不一定总是原始服务器,比如一个缓存代理服务器)端获取范围内的数据,这种格式是很松散的,可以用”,”逗号分割范围的一种表达式.比如1-100,-1 这就表示要获取第一到100个字节,以及最后一个字节的部分.又或者 50-则表示50个字节之后的所有数据搭配可以很灵活.不过,当使用多个范围的Range标头时,假设范围都是合法的(不存在越界的情况,如果越界,则可能返回417 Requested Range Not Satisfiable状态码).则服务器响应时,会修改响应中的Content-Type标头为 如下格式:
Content-Type : multipart/byteranges;boundary=----ROPE----
----ROPE----
Content-Type:image/jpeg
Content-Range:bytes 0-100/2000
此处为0-100的数据
----ROPE----
Content-Type:image/jpeg
Content-Range:xxx-xxx/2000
xxx-xxx范围的数据.
----ROPE----
好吧,以上这些不是我们关心的重点.我们关心的是和缓存有关的情况,其实对于任何客户端(包括用户代理,以及各类缓存服务器)来说.如果它明确的知道自己想要某一部分范围的数据.就可以使用Range标头. 但事实上,比如对于浏览器来说,一般情况下,只有当服务器端的响应中包含Accept-Ranges:bytes标头时,才可能会在有断点续传需求的时候,自动使用Range头去请求实体.而代只有在响应中,明确出现Accept-Ranges:none时.才会完全避免客户端(包括缓存代理服务器),使用Range标头去获取部分数据.这是要区别看待的.
PS:Range头,还可以在GET方式下与If-Unmodified-Since标头配合,进行条件请求.其行为类似于If-Range头中使用日期格式做新鲜度校验.
.If-Range : 实体的Etag值 | date日期值.
配合Range使用的条件请求标头,该标头的值可以是被请求实体的Etag值,又或者是其Last-Modified的日期.客户端所缓存的部分数据,是新鲜的,服务器端才会,以206方式返回这部分数据.否则,以200方式返回全部数据.
响应标头:
.Accept-Ranges : bytes | none
用于说明,服务器是否支持范围请求.一般,我们常常为图片等资源设置Accept-Ranges:bytes标头.以便使客户端,可以使用断点续传功能.当然,这一切的前提是,客户端之前有缓存部分数据.或者换个角度说,如果服务器端明确声明,不允许缓存某个实体.那么断点续传也就无从说起了. 所以正确的服务器端配置.是一切的基础.
.Content-Range : bytes 0-xxxx/xxxx
标明当前服务器端返回数据的范围. /xxxx部分是总长度.
HTTP响应类别:
.信息类:1xx(信息类响应头,是在1.1中才被真正具体定义.我们暂时不关注它.)
.成功类:2xx
.重定向类:3xx (我们目前只关注304,是的,304是属于重定向类的,我们姑且理解为,重定向到客户端缓存副本上去.)
.客户机错误类:4xx
.服务器错误类:5xx
1. 寿命:
即响应的寿命,指从原始服务器发出实体后所经历的时间,或者是重新验证,证明某缓存仍处于最新状态(可信赖)之后,所经历的时间. 参考响应头中的 Age,其单位是秒.
2. 过期时间:
对于一个缓存实体来说,其过期时间,是由原始服务器设定的.(参考响应头中的Expires,Cache-Control:max-age…等)一但发现过期,则缓存,必须重新验证实体,才能决定是否使用缓存中对应的实体副本,作为响应.如果原始服务器,未设定过期时间,则缓存可以自己做主,设置一个它认为合适的过期时间(就浏览器来说,IE浏览器再这里实现的与众不同,非IE的主流浏览器,不会自作主张的设置一个自认为合适的过期时间,或者说他们总是认为这样的实体.不应该被缓存下来.而IE,则会有一个会话级的缓存.实际上也不是真正有一个过期时间了.所谓会话级缓存,即浏览器不关闭的情况下,始终去读取浏览器本地的缓存.而不会去试图做任何验证的工作.)
3. 新鲜期和陈旧性:(此概念为服务器端概念)
一个HTTP响应是在服务器端某个特定时刻生成的.原始服务器决定这个响应在多长时间内,是确定新鲜的.在这个新鲜期内,相同实体的请求.可以使用原来生成的那个内容作为响应.即服务器端缓存.一但原始服务器端确认某相同实体的响应,已过了新鲜期.即处于陈旧状态.则原始服务器,需要进一步处理这个响应,比如重新生成响应,或者验证是否可以继续使用该响应.并重新设置其新鲜期.
4. 有效性:
缓存,可以与服务器联系,来验证某个缓存副本,是否是可信赖的最新状态.这种检查,被称为有效性重验证.重验证也可以针对代理服务器进行,而不一定总要和原始服务器进行验证.
5. 可缓存性(缓存能力):
缓存者, 必须决定是否存对一个响应,进行缓存.这取决于很多因素,比如原始服务器是否允许响应被缓存,是否设置了缓存过期时间.而有时候即缓存者缓存了一个响应.它仍然需要对该响应,进行验证,以确保该缓存是新鲜的.缓存能力和响应验证,是紧密相关的.
那么协议就是全部么?用户代理就那听话么? 我们理所当然的写一些东西的时候就可靠了么?
下面这段是我的evernote中翻找出来的一段和缓存有关的坑爹的例子.也算给我们自己提个醒. 用户代理可能应为某些原因,给我们造成一些困扰. 所以切记想当然. 一切应以实测为准. 同样.代理服务器也完全可以违背http协议相关的缓存策略.所以 理论上很多东西,都是不可信的:
demo:
document.onclick = function () {
var img = new Image;
document.body.appendChild(img);
img.src=https://passport.baidu.com/?verifypic";
alert(img.complete)
//CollectGarbage();
}IE7+,opera 如果src是一个静态不变的地址.则 不会再发起请求(无视http缓存相关头域).而直去取缓存文件 。(www.61k.com) 而且是完全不走network 模块的那种. 所以甚至httpWatch也不会抓到 cache 的项.
因为该img 会被保存在内存中. 即使 没有 img句柄,而直接是一个 new Image().src=xxx 也是如此. 并且 无论图片资源是否强制缓存.http头指定该资源不缓存,亦如此. 这也是为什么IE6有另外某个必须保持new Image句柄的原因.因为IE6 和 IE7+对new Image的策略完全不同, IE6是不会在内存中保持new Image对象的(这也是为什么ie6会有后面提到的那个问题的本质原因.).而 IE7+会在内存中缓存该对象. 并以url作为索引.opera12-也是如此.
所以,如果是借助new Image 上报,即使image资源的http 相关缓存头,配置正确(no-cache,no-store,expires过期).在IE7+和Opera12-中,也应该使用随机数.来绕过浏览器 内存缓存new Image的坑. 但是不能因此而放弃配置正确的http缓存策略先关头. 因为这才是正道. 符合语义的做法. 随机数是为了修正用户代理的错误. 不能混淆或相互代替. 另外随机数,也可能是为了解决另外一个问题, 仍然和IE系列有关,比如未指定相关缓存头域情况下,IE系默认对资源有会话级缓存的bug.
而ie6 , 一个简单的 new Image().src=xxx 的上报. 会可能在GC(浏览器主动触发,如因页面渲染触发的GC,而不是主动调用CollectGarbage方法)时abort 掉这个请求.(此问题其他浏览器,IE7+都不存在.)
即使是
var img = new Image();
img.src= xxx 也如此
解决办法:
var log = function(){
var list = [];
return function(src){
var index = list.push(new Image) -1;
list[index].onload = function(){
list[index] = list[index].onload = null;
}
list[index ].src = src;
}
}();
但是要注意的问题是: 0 content length or not image mimeTypes . 不会触发onload. 也就是说,上面的代码.有可能不会及时回收资源.这取决于上报的服务器的配置了. 也许可以借助onerror来综合解决。但我个人认为.这里不会造成内存泄露. 就算你一个页面有100次上报,也无所谓. 而且 对于ie7 - ie10 pp2(更高版本还不好说)来说 .总是在内存中自动缓存每个new Image对象,那么是否我们主动使其持有句柄,其实意义也都不大了.
三 : 组三屏显示器前你应该知道的那些事儿
内容来自 什么值得买:http://www.61k.com
组三屏显示器前你应该知道的那些事儿
随着LCD价格的不断走低,以及越来越多的玩家不再满足更高的帧数和更大的屏幕,开始了新一轮的视觉飨宴——更宽广的视域。
首先,除了你要有一台电脑,还要回答一个问题:为什么是三屏?我个人认为有两种答案:
第一种:人双眼的水平视角最大可达188度,两眼重合视域为124度,也就是下图中的∠cyg。这是普通情况。聚焦模式下,单眼的视角可以是∠bLl,双眼叠合区就是∠kwl。从图上也很容易看出来,如果把线段bf当做一个场景,正好被点k和l分成三个区域,紧盯kl的时候,正好可以用余光瞟见bk和lf。“多余”的两块屏幕正好可以为我们显示通常状态下被省略的“周围”。
1 / 7
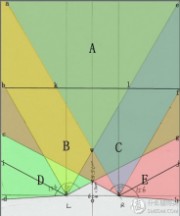
内容来自 什么值得买:http://www.61k.com第二种:如果不是三屏而是双屏四屏的话,视域正中间会有一道缝……你一定会抓狂的!
2 / 7

内容来自 什么值得买:http://www.61k.com
简而言之:从玩游戏的角度来说,我们很难忍受双屏,又没有必要四屏,只有三屏才适合人类的视角——中间主屏幕对应主视点,两边用来扩充视野。
……至于女朋友或者孩儿他妈是否认同我这个观点不在本文讨论范围中。
接下来,如果你有一个深明大义的女朋友或者孩儿他妈,碰巧又有那么一点买房嫌少买烟嫌多的钱,那么就要考虑怎么样才能把它们仨串在一起了。目前全世界公认的方案有两个:
第一个:N卡SLI。必须高兴的是,NVIDIA为我们提供了可实现三屏输出的NVIDIA
Surround平面三屏环绕技术
。但!!前提是至少两张显卡SLI。有人问,我的N卡上有两个DVI还有一个HDMI接口,是不是就可以接三台显示器了呢?答案是肯定的,接是肯定可以接的,不过只会显示两个屏幕的内容。N卡的GPU在出厂的时候就被设置好了,只能最多输出两个屏幕的内容。有的第三方厂商用加芯片的方式绕开了限制,实现过单卡三屏的显卡,但是因为实在太小众,出了一阵就没有再出过了。目前的中端显卡比如GTX660都已不再提供SLI接口了~~合伙越级的事情也干不了了。要么单卡,要么多卡,否则真不推荐N卡了。
第二个:A卡单卡。良心的AMD为世人开发出来最多支持单卡6屏的ATI
Eyefinity多屏输出技术(最新的已经是Eyefinity 3.0了),并且从Radeon
HD5000系列开始,每张卡都能至少支持单卡3屏输出,即便是低端入门卡!
网上有详细的设置图文介绍,这里就不废话了。说说我组三屏的经验吧。
刚开始的时候,我使用两张华硕GTX560 SE-DC-1536MD5来SLI,单张显卡显存1.5GB,SLI后显存还是1.5G(因为是并联的说)。这个方案对电源要求不是太高,我的航嘉额定450W就能带动(I53470默频,16G
DDR3,三星840PRO)。但是有一天,我心血来潮用两张华硕GTX650换了一张同品牌R9 270X 4G,刚好可以继续使用现在的电源,性(能)噪(音)比也完全能接受,再说我也不是跑分党,270X对绝大多数游戏来说,已经足够了。
3 / 7
内容来自 什么值得买:http://www.61k.com
显卡升级前后确实发现不少差别,下面大致说下:
性能:原来的SLI简单的用鲁大师跑分,10w出头,换了270X以后,一下就15w多了。两张560SESLI的效果也就和660差不多,比起R9 270X确实还要差不少。
温度:都差不多,双卡50~60度,单卡还是50~60度
实际体验:SLI的时候打暗黑3还有卡顿,特别是怪多的时候,毕竟只有1.5G显存可用;270X就完全没有这个情况,4G显存杠杠的。
桌面工具栏:SLI的系统桌面工具栏更像MAC系统的DOCK,只在中间屏幕的下方,而且不知道是否个体现象,工具栏会在开机后随机出现在上方或下方……或离屏幕底部一个栏宽的位置;270X的工具栏在底部横向伸展到三个屏幕,稳定。
设置难易程度:平心而论,各有千秋。N卡的方案对接缝处的画面补偿做得很好,可以根据显示器的边框和因摆放带来的视差做很细微的调整,甚至可以自己设置任意分辨率,但在双屏的时候只能是扩展显示,要跨越显示只能三屏;而A卡对多屏的组合方式做得很好,可以双屏跨越,也可以三屏跨越,也有画面补偿,还有纵向屏幕拼接!!。
最后,屏幕的选择——这个不必多说,总之远离TN屏就是了。刚开始的时候,我用了三台三星的

S24系列显示器,因为是TN屏,环形摆放的话色差很严重:
后来换了dell的U2414H,超窄边框果然是为多屏而生!
4 / 7

内容来自 什么值得买:http://www.61k.com
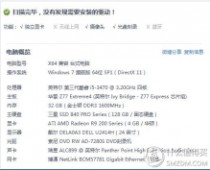
最后晒个配置:桌面截图,求1024.
5 / 7

内容来自 什么值得买:http://www.61k.com
—完—
本文来自什么值得买,原文链接: 6 / 7

内容来自 什么值得买:http://www.61k.com
“什么值得买”(http://www.61k.com)是一个中立的,致力于帮助广大网友买到更有性价比网购产品的分享平台,每天为网友们提供严谨的、准确的、新鲜的、丰富的网购产品特价资讯。我们的信息大部分来自于网友爆料,经过编辑审核后的内容也会得到大量网友的评价,这是一个大家帮助大家的互动社区。 我们的核心价值:让用户在对的时间、对的平台、买对的商品。 7 / 7
本文标题:你真的知道应该陪爸妈做哪些事情吗?-高考期间妈妈和儿子陪读住,这个事真的吗?61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1
