一 : Google 爬虫如何抓取 Javascript 的?
我们测试了谷歌爬虫是如何抓取 JavaScript,下面就是我们从中学习到的知识。
认为 Google 不能处理 JavaScript ?再想想吧。Audette Audette 分享了一系列测试结果,他和他同事测试了什么类型的 JavaScript 功能会被 Google 抓取和收录。

概述
1. 我们进行了一系列测试,已证实 Google 能以多种方式执行和收录 JavaScript。我们也确认 Google 能渲染整个页面并读取 DOM,由此能收录动态生成的内容。
2. DOM 中的 SEO 信号(页面标题、meta 描述、canonical 标签、meta robots 标签等)都被关注到。动态插入 DOM 的内容都也能被抓取和收录。此外,在某些案例中,DOM 甚至可能比 HTML 源码语句更优先。虽然这需要做更多的工作,但这是我们好几个测试中的一个。
引言:Google 执行 JavaScript & 读取 DOM
早在 2008 年, Google 就 成功抓取 JavaScript,但很可能局限于某种方式。
而在今天,可以明确的是,Google 不仅能制定出他们抓取和收录的 JavaScript 类型,而且在渲染整个 web 页面上取得了显著进步(特别在最近的 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队想更好地理解谷歌爬虫能抓取和收录什么类型的 JavaSscript 事件。经过研究,我们发现令人瞠目的结果,并已证实 Google 不仅能执行各种 JavaScript 事件,而且能收录动态生成的内容。怎么样做到的?Google 能读取 DOM。
DOM 是什么?
很多搞 SEO 的都不理解什么是 Document Object Model(DOM)。

当浏览器请求页面时会发生什么,而 DOM 又是如何参与进来的。
当用于 web 浏览器,DOM 本质上是一个应用程序的接口,或 API,用于标记和构造数据(如 HTML 和 XML)。该接口允许 web 浏览器将它们进行组合而构成文档。
DOM 也定义了如何对结构进行获取和操作。虽然 DOM 是与语言无关的 API (不是捆绑在特定编程语言或库),但它普遍应用于 web 应用程序的 JavaScript 和 动态内容。
DOM 代表了接口,或“桥梁”,将 web 页面与编程语言连接起来。解析 HTML 和执行 JavaScript 的结果就是 DOM。web 页面的内容不(不仅)是源码,是 DOM。这使它变得非常重要。
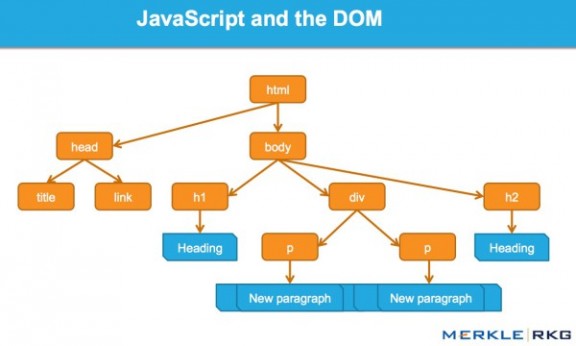
JavaScript 是如何通过 DOM 接口工作的。
我们兴奋地发现 Google 能够读取 DOM,并能解析信号和动态插入的内容,例如 title 标签、页面文本、head 标签和 meta 注解(如:rel = canonical)。可阅读其中的完整细节。
关于这一系列测试、及结果
因为想知道什么样的 JavaScript 功能会被抓取和收录,我们单独对 谷歌爬虫 创建一系列测试。通过创建控件,确保 URL 活动能被独立理解。下面,让我们详细划分出一些有趣的测试结果。它们被分为 5 类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入 Meta 数据 和页面元素
一个带有 rel = “nofollow” 的重要例子
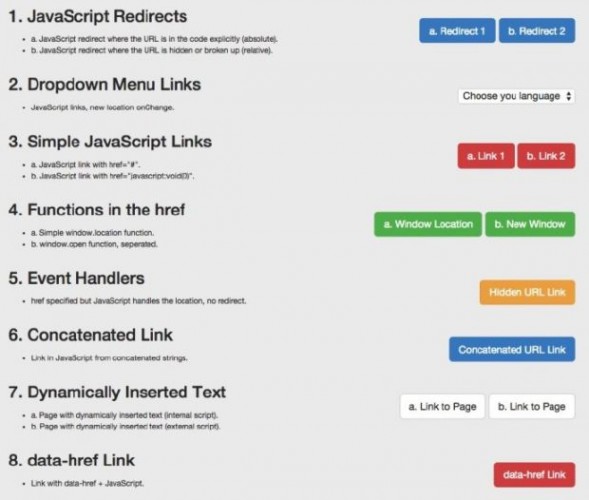
例子:一个用来测试谷歌爬虫理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向,用不同方式表示的 URL 会有什么样结果呢?我们选择了window.location 对象进行两个测试:Test A 以绝对路径 URL 调用 window.location,而 Test B 使用相对路径。
结果:该重定向很快被 Google 跟踪。从收录来看,它们被解释为 301 - 最终状态的 URL 取代了 Google 收录里的重定向 URL。
在随后的测试中,我们在一个权威网页上,利用完全相同的内容,完成一次利用 JavaScript 重定向到同一个站点的新页面。而原始 URL 是排在 Google 热门查询的首页。
结果:果然,重定向被 Google 跟踪,而原始页面并没有被收录。而新 URL 被收录了,并立刻排在相同查询页面内的相同位置。这让我们很惊喜,以排名的角度上看,视乎表明了JavaScript 重定向行为(有时)很像永久性的 301 重定向。
下次,你的客户想要为他们的网站完成 JavaScript 重定向移动,你可能不需要回答,或回答:“请不要”。因为这似乎有一个转让排名信号的关系。支持这一结论是引用了 Google 指南:
使用 JavaScript 为用户进行重定向,可能是一个合法的做法。例如,如果你将已登录用户重定向到一个内部页面,你可以使用 JavaScript 完成这一操作。当仔细检查 JavaScript 或其他重定向方法时,以确保你的站点遵循我们的指南,并考虑到其意图。记住 301 重定向跳转到你网站下是最好的,但如果你没有权限访问你网站服务器,你可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们用多种编码方式测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史上的搜素引擎一直不能跟踪这类型的链接。我们想确定 onchange 事件处理器是否会被跟踪。重要的是,这只是执行特定的类型,而我们需要是:其它改动后的影响,而不像上面 JavaScript 重定向的强制操作。
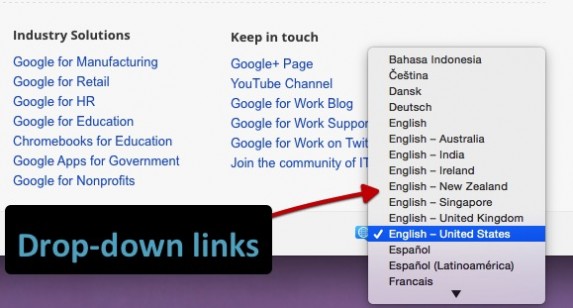
例子: Google Work 页面的语言选择下拉菜单。
结果:链接被完整地抓取和跟踪。
我们也测试了常见的 JavaScript 链接。下面是最常见类型的 JavaScript 链接,而传统的 SEO 则推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键-值对(AVP),但在一个标签内(“onClick”)
作用 href 内部 AVP(“javascript : window.location”)
作用于 a 标签外部,但在 href 内调用 AVP(“javascript : openlink()”)
……
结果:链接被完整抓取和跟踪。
我们下一个测试是更进一步地测试事件处理器,如上面测试的 onchange。具体地说,我们希望利用鼠标移动的事件处理器,然后隐藏 URL 变量 ,该变量只在事件处理函数(在该案例是 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完整抓取和跟踪。
构造链接:我们知道 Google 能执行 JavaScript,但想确认它们是否能读取代码里的变量。所以在该测试中,我们连接能构造 URL 字符串的字符。
结果:链接被完整抓取和跟踪。
3. 动态插入内容
很明显,这些都是重点:动态插入文本、图像、链接和导航。优质的文本内容对搜索引擎理解网页主题和内容是至关重要的。在这个动态网站的时代,它的重要性是无需质疑的。
这些测试,设计出来是为了检查在两个不同场景下动态插入文本的结果。
1. 测试搜索引擎能否统计动态插入的文本,而文本是来自页面 HTML 源码内的。
2. 测试搜索引擎能否统计动态插入的文本,而文本是来自页面 HTML 源码外的(在一个外部 JavaScript 文件内)。
结果:在两个案例中,文本都能被抓取和收录,并且页面是根据该内容进行排名。爽!
为了了解更多相关信息,我们测试了一个通过 JavaScript 编写的客户端全局导航,而导航里的链接都是通过 document.writeIn 函数插入,并且确定它们能被完全抓取和跟踪。应该指出的是:Google 能解释使用 AngularJS 框架 和 HTML5 History API(pushState)构建的网站,能渲染和收录它,并能像传统静态网页一样排名。这就是 不禁止谷歌爬虫 获取外部文件和 JavaScript 的重要性,而且这也许是 Google 正在从 《支持 Ajax 的 SEO 指南》 中移除它的原因。当你能简单地渲染整个页面时候,谁还需要 HTML 快照呢?
经过测试后发现,不管什么类型的内容,都是同样的结果。例如,图像加载到 DOM 后会被抓取和收录。我们甚至做了这样的一个测试:通过动态生成 data-vocabulary.org 结构数据来制作 breadcrumb(面包屑导航),并将其插入 DOM。结果呢? 成功插入后的面包屑出现在搜索结果中了 (search engine results page)。
值得注意的是,Google 现在 推荐用 JSON-LD 标记 形成结构化数据。我敢肯定将来会出现更多基于此的东西。
4. 动态插入 Meta 数据 & 页面元素
我们将各种对 SEO 至关重要的标签动态插入到 DOM:
Title 元素
Meta 描述
Meta robots
Canonical tags
结果:在所有案例中,标签都能被抓取,其表现就像 HTML 源码里的元素一样。
一个有趣的补充实验帮助我们理解优先顺序。当存在冲突信号时,哪一个会胜出呢?如果源码里有 noindex、nofollow 标签,而 DOM 里有 noindex、follow 标签的话,将会发生什么呢?在这协议里,HTTP x-robots 响应头部的行为如何作为另一个变量?这将是未来综合测试的一部分。然而,我们的测试显示:当冲突时,Google 会无视源码里的标签,而支持 DOM。
5. 一个带有 rel =“nofollow” 的重要例子
我们想测试 Google 如何应对出现在源码和 DOM 的链路级别的 nofollow 属性。我们也因此创建了一个没有应用 nofollow 的控件。
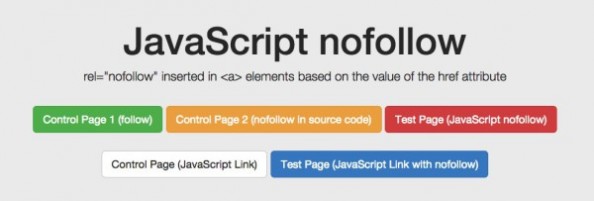
对于 nofollow ,我们分别单独测试源码 vs DOM 生成的注解。
源码里的 nofollow 正如我们所期待的那样运行(链接没被跟踪)。而 DOM 里的 nofollow 却失效(链接被跟踪,并且页面被收录)。为什么?因为在 DOM 里修改 href 元素的操作发生得太晚了:Google 在执行添加 rel=”nofollow” 的 JavaScript 函数前,已准备好抓取链接和队列等待着 URL。然而,如果将带有 href =”nofollow”的 a 元素插入到 DOM,nofollow 和链接因在同一时刻插入,所以会被跟踪。
结果
从历史角度上看,各种 SEO 推荐是在任何可能的时候,要尽可能专注 ‘纯文本’ 内容。而动态生成内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对 Google 不再是问题。 JavaScript 链接以类似普通的 HTML 链接方式运行(这只是表面,而我们不知道幕后程序进行了什么操作)。
JavaScript 重定向都会以类似于 301 重定向方式对待。
动态插入内容,甚至 meta 标签,如 rel canonical 注解,无论在 HTML 源码,还是在最初 HTML 被解析后触发 JavaScript 生成 DOM ,都以同等方式对待。
Google 视乎能完全渲染页面和理解 DOM ,而不仅是源码。实在是令人可不思议!(记得允许谷歌爬虫获取那些外部文件和 JavaScript。)
Google 已经在创新方面,以惊人的速度将其它搜索引擎甩在身后。我们希望看到其它搜索引擎能有同样类型的创新。如果他们要保持竞争力,并在 web 新时代取得实质性进展,这意味着它们要更好地支持 HTML5、JavaScript 和 动态网站。
对于 SEO,那些没有理解上述基本概念和 Google 技术的人,应该好好研究和学习,以赶上当前技术。如果你不把 DOM 考虑在内,您可能会丢失一半份额。
二 : Python爬虫(一)--豆瓣电影抓站小结(成功抓取Top100电影)
python爬虫学习给自己定下的第一个小目标, 加油!
也希望能得到python大大们的指点, 感谢!
1. 豆瓣抓站流程
分析url特征(菜鸟阶段)
对需要抓取的数据设计正则表达式
处理HTML中一些特征字符,换行符等
注意异常的处理和字符编码的处理
2. 实现的功能
简单的实现了抓取豆瓣电影Top100的电影名称
3. 后期工作展望
抓取更多的有用数据(如:准确抓取导演, 抓取一个电影评论)
使用多线程爬虫
学习第三方的爬虫框架(Scrapy)
深入理解HTML编码和文本处理
4. 输出结果
Top1 肖申克的救赎Top2 这个杀手不太冷Top3 阿甘正传Top4 霸王别姬Top5 美丽人生Top6 海上钢琴师Top7 辛德勒的名单Top8 千与千寻Top9 机器人总动员Top10 三傻大闹宝莱坞Top11 泰坦尼克号Top12 盗梦空间Top13 放牛班的春天Top14 龙猫Top15 忠犬八公的故事Top16 教父Top17 大话西游之大圣娶亲Top18 乱世佳人Top19 天堂电影院Top20 搏击俱乐部Top21 当幸福来敲门Top22 罗马假日Top23 楚门的世界Top24 海豚湾Top25 指环王3:王者无敌Top26 两杆大烟枪Top27 天空之城Top28 飞越疯人院Top29 触不可及Top30 飞屋环游记Top31 十二怒汉Top32 鬼子来了Top33 天使爱美丽To[www.61k.com]p34 大话西游之月光宝盒Top35 窃听风暴Top36 V字仇杀队Top37 怦然心动Top38 无间道Top39 闻香识女人Top40 蝙蝠侠:黑暗骑士Top41 美丽心灵Top42 指环王2:双塔奇兵Top43 指环王1:魔戒再现Top44 剪刀手爱德华Top45 活着Top46 教父2Top47 七宗罪Top48 勇敢的心Top49 情书Top50 哈尔的移动城堡Top51 熔炉Top52 美国往事Top53 死亡诗社Top54 音乐之声Top55 钢琴家Top56 小鞋子Top57 被嫌弃的松子的一生Top58 狮子王Top59 致命魔术Top60 玛丽和马克思Top61 低俗小说Top62 入殓师Top63 蝴蝶效应Top64 少年派的奇幻漂流Top65 沉默的羔羊Top66 大鱼Top67 射雕英雄传之东成西就Top68 阳光灿烂的日子Top69 本杰明·巴顿奇事Top70 幽灵公主Top71 第六感Top72 让子弹飞Top73 黑客帝国Top74 拯救大兵瑞恩Top75 上帝之城Top76 萤火虫之墓Top77 阳光姐妹淘Top78 心灵捕手Top79 饮食男女Top80 大闹天宫Top81 西西里的美丽传说Top82 海洋Top83 一一Top84 重庆森林Top85 燃情岁月Top86 爱在黎明破晓前Top87 爱在日落黄昏时Top88 风之谷Top89 春光乍泄Top90 虎口脱险Top91 加勒比海盗Top92 告白Top93 侧耳倾听Top94 甜蜜蜜Top95 阿凡达Top96 菊次郎的夏天Top97 驯龙高手Top98 真爱至上Top99 致命IDTop100 超脱5. 豆瓣抓站源代码
抓站源代码链接
个人使用的Python编码规范
python正则表达式小计
三 : 抓虫记
在我的自然标本收集册里,珍藏着几只甲虫。今天我打开册子,拿出精致的甲虫标本,放在鼻子下嗅了嗅,顿时,一股昆虫的清香迎面扑来,撞开我记忆的闸门。
那时一个夏天的傍晚,落日的余晖给大地镀上了一层金光,我和小安约好一起去捉昆虫。我们在校园里找了好几处地方,也没有它们的影子。我们来到了植物园里寻找,突然听见后面有“吱吱吱吱.....”,是什么声音?“是,蜘蛛!”我小心翼翼地向蜘蛛扑去,“哎呦!”小蜘蛛逃走了。我垂头丧气地说:“连一只小小的虫子也捉不着,真气死人!”小安笑着对我说:“别这样嘛,世上无难事,只怕有心人!学校捉不到,我们可以到别的地方去捉。来!我们走。”
不一会儿,我们又来到了一片田野里,那里绿草如茵,没膝的草苗随风起伏,像向我们点头微笑,一片生气勃勃的景象,真另人陶醉!小安蹦蹦跳跳地窜进了田野,跑了不远,突然回过头来叫我:“小莹,为什么不来找虫子呢?”“草苗这样高,我...我怕这里有蛇!”我说。小安拍拍胸膛说:“我确定这里没有蛇。”但我还是不敢走进去。这时候,小文来了,我问:“你也来捉虫子吗?”小文说:“是呀!你呢?”我说:“是,但我怕蛇。”小文说;“这里没有蛇,如果你不去试一试,怎么会知道呢?”我听完了小文的话之后,就鼓起了勇气,一步一步地向前走,嫩绿的小草瘙痒着我的小脚丫,多么舒服啊!正在这时侯,小安兴奋的大喊:“快来看看!这里有七只蚱蜢和六只甲虫。”我和小文连忙跑过去,只看见三只小甲虫在玩耍,三只在吃着小草呢!多么可爱!那七只蚱蜢正在打个你死我活呢!真厉害!我想:只要我细心观察,仔细地寻找,我也会满载而归的!
于是,我蹲下身子,把花儿和草丛扒开,这里看看,那里找找,细心地搜索,奇迹终于出现了,“我找到了!找到了!”我高兴得连蹦带跳,高声地欢呼,心里像吃了蜜一样甜滋滋的。
我把这几只甲虫珍藏着,每当打开收集本,肯定要看看我的甲虫,因为它让我知道:无论做什么事都要有耐心,细心,恒心加信心。
四 : SEO案例:浅析爬虫的不重复抓取策略
不重复抓取?有很多初学者可能会觉得。爬虫不是有深度优先和广度优先两种抓取策略吗?你这怎么又多出来一个不重复抓取策略呢?其实我这几天有不止一次听到了有人说要在不同页面增加同一页面链接,才能保证收录。我想真能保证吗?涉及收录问题的不止是抓没抓吧?也从而延伸出今天的这篇文章,不重复抓取策略,以说明在一定时间内的爬虫抓取是有这样规则的,当然还有很多其他的规则策略,以后有机会再说,例如优先抓取策略、网页重访策略等等。
回归正题,不重复抓取,就需要去判断是否重复。那么就需要记住之前的抓取行为,我们举一个简单的例子。你在我的QQ群(9060800)里看到我发了一个URL链接,然后你是先看到了我发的这个链接,然后才会点击并在浏览器打开看到具体内容。这个等于爬虫看到了后才会进行抓取。那怎么记录呢?我们下面看一张图:
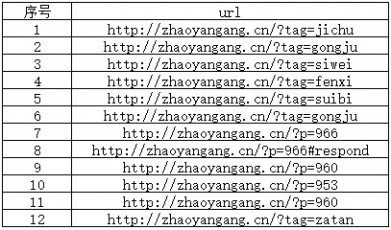
如上图,假设这是一个网页上所有的链接,当爬虫爬取这个页面的链接时就全部发现了。当然爬取(理解为发现链接)与抓取(理解为抓取网页)是同步进行的。一个发现了就告诉了另外一个,然后前面的继续爬,后面的继续抓。抓取完了就存起来,并标记上,如上图,我们发现第2条记录和第6条记录是重复的。那么当爬虫抓取第二条后,又爬取到了第6条就发现这条信息已经抓取过了,那么就不再抓取了。爬虫不是尽可能抓更多的东西吗?为什么还要判断重复的呢?
其实,我们可以想一下。互联网有多少网站又有多少网页呢?赵彦刚是真没查证过,但这个量级应该大的惊人了。而本身搜索引擎的爬取和抓取都是需要执行一段代码或一个函数。执行一次就代表着要耗费一丁点资源。如果抓取的重复量级达到百亿级别又会让爬虫做多少的无用功?耗费搜索引擎多大的成本?这成本就是钱,降低成本就是减少支出。当然不重复抓取不光体现在这里,但这个是最显而易见的。你要知道的就是类似于内容详情页的热门推荐、相关文章、随机推荐、最新文章的重复度有多大?是不是所有页面都一样?如果都一样,那么可以适当调整下,在不影响网站本身的用户体验前提下,去适当做一些调整。毕竟网站是给用户看的,搜索引擎只是获取流量的一个重要入口,一种营销较为重要的途径!
五 : Google 爬虫如何抓取 Javascript 的?
我们测试了谷歌爬虫是如何抓取 JavaScript,下面就是我们从中学习到的知识。
认为 Google 不能处理 JavaScript ?再想想吧。Audette Audette 分享了一系列测试结果,他和他同事测试了什么类型的 JavaScript 功能会被 Google 抓取和收录。

概述
1. 我们进行了一系列测试,已证实 Google 能以多种方式执行和收录 JavaScript。我们也确认 Google 能渲染整个页面并读取 DOM,由此能收录动态生成的内容。
2. DOM 中的 SEO 信号(页面标题、meta 描述、canonical 标签、meta robots 标签等)都被关注到。动态插入 DOM 的内容都也能被抓取和收录。此外,在某些案例中,DOM 甚至可能比 HTML 源码语句更优先。虽然这需要做更多的工作,但这是我们好几个测试中的一个。
引言:Google 执行 JavaScript & 读取 DOM
早在 2008 年, Google 就 成功抓取 JavaScript,但很可能局限于某种方式。
而在今天,可以明确的是,Google 不仅能制定出他们抓取和收录的 JavaScript 类型,而且在渲染整个 web 页面上取得了显著进步(特别在最近的 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队想更好地理解谷歌爬虫能抓取和收录什么类型的 JavaSscript 事件。经过研究,我们发现令人瞠目的结果,并已证实 Google 不仅能执行各种 JavaScript 事件,而且能收录动态生成的内容。怎么样做到的?Google 能读取 DOM。
DOM 是什么?
很多搞 SEO 的都不理解什么是 Document Object Model(DOM)。

当浏览器请求页面时会发生什么,而 DOM 又是如何参与进来的。
当用于 web 浏览器,DOM 本质上是一个应用程序的接口,或 API,用于标记和构造数据(如 HTML 和 XML)。该接口允许 web 浏览器将它们进行组合而构成文档。
DOM 也定义了如何对结构进行获取和操作。虽然 DOM 是与语言无关的 API (不是捆绑在特定编程语言或库),但它普遍应用于 web 应用程序的 JavaScript 和 动态内容。
DOM 代表了接口,或“桥梁”,将 web 页面与编程语言连接起来。解析 HTML 和执行 JavaScript 的结果就是 DOM。web 页面的内容不(不仅)是源码,是 DOM。这使它变得非常重要。
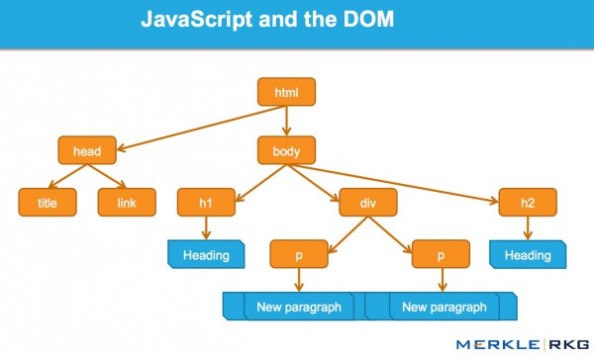
JavaScript 是如何通过 DOM 接口工作的。
我们兴奋地发现 Google 能够读取 DOM,并能解析信号和动态插入的内容,例如 title 标签、页面文本、head 标签和 meta 注解(如:rel = canonical)。可阅读其中的完整细节。
关于这一系列测试、及结果
因为想知道什么样的 JavaScript 功能会被抓取和收录,我们单独对 谷歌爬虫 创建一系列测试。通过创建控件,确保 URL 活动能被独立理解。下面,让我们详细划分出一些有趣的测试结果。它们被分为 5 类:
- JavaScript 重定向
- JavaScript 链接
- 动态插入内容
- 动态插入 Meta 数据 和页面元素
- 一个带有 rel = “nofollow” 的重要例子
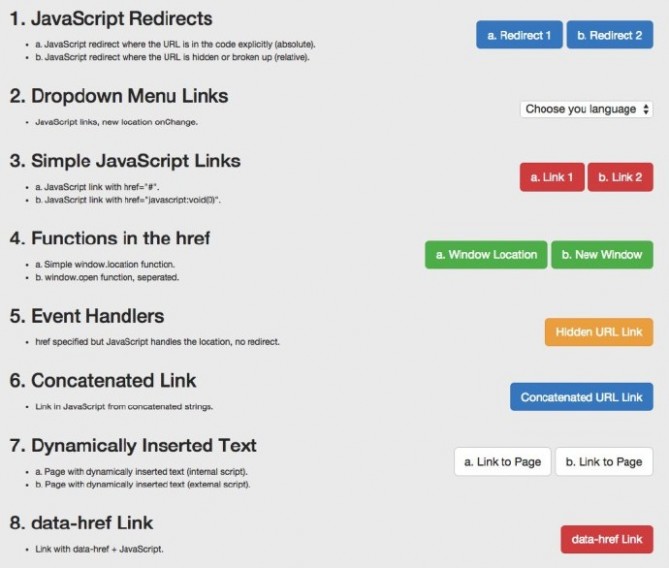
例子:一个用来测试谷歌爬虫理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向,用不同方式表示的 URL 会有什么样结果呢?我们选择了 window.location 对象进行两个测试:Test A 以绝对路径 URL 调用 window.location,而 Test B 使用相对路径。
结果:该重定向很快被 Google 跟踪。从收录来看,它们被解释为 301 - 最终状态的 URL 取代了 Google 收录里的重定向 URL。
在随后的测试中,我们在一个权威网页上,利用完全相同的内容,完成一次利用 JavaScript 重定向到同一个站点的新页面。而原始 URL 是排在 Google 热门查询的首页。
结果:果然,重定向被 Google 跟踪,而原始页面并没有被收录。而新 URL 被收录了,并立刻排在相同查询页面内的相同位置。这让我们很惊喜,以排名的角度上看,视乎表明了JavaScript 重定向行为(有时)很像永久性的 301 重定向。
下次,你的客户想要为他们的网站完成 JavaScript 重定向移动,你可能不需要回答,或回答:“请不要”。因为这似乎有一个转让排名信号的关系。支持这一结论是引用了 Google 指南:
使用 JavaScript 为用户进行重定向,可能是一个合法的做法。例如,如果你将已登录用户重定向到一个内部页面,你可以使用 JavaScript 完成这一操作。当仔细检查 JavaScript 或其他重定向方法时,以确保你的站点遵循我们的指南,并考虑到其意图。记住 301 重定向跳转到你网站下是最好的,但如果你没有权限访问你网站服务器,你可以为此使用 JavaScript 重定向。
注:相关网站建设技巧阅读请移步到建站教程频道。
2. JavaScript 链接
我们用多种编码方式测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史上的搜素引擎一直不能跟踪这类型的链接。我们想确定 onchange 事件处理器是否会被跟踪。重要的是,这只是执行特定的类型,而我们需要是:其它改动后的影响,而不像上面 JavaScript 重定向的强制操作。

例子: Google Work 页面的语言选择下拉菜单。
结果:链接被完整地抓取和跟踪。
我们也测试了常见的 JavaScript 链接。下面是最常见类型的 JavaScript 链接,而传统的 SEO 则推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键-值对(AVP),但在一个标签内(“onClick”)
作用 href 内部 AVP(“javascript : window.location”)
作用于 a 标签外部,但在 href 内调用 AVP(“javascript : openlink()”)
……
结果:链接被完整抓取和跟踪。
我们下一个测试是更进一步地测试事件处理器,如上面测试的 onchange。具体地说,我们希望利用鼠标移动的事件处理器,然后隐藏 URL 变量 ,该变量只在事件处理函数(在该案例是 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完整抓取和跟踪。
构造链接:我们知道 Google 能执行 JavaScript,但想确认它们是否能读取代码里的变量。所以在该测试中,我们连接能构造 URL 字符串的字符。
结果:链接被完整抓取和跟踪。
3. 动态插入内容
很明显,这些都是重点:动态插入文本、图像、链接和导航。优质的文本内容对搜索引擎理解网页主题和内容是至关重要的。在这个动态网站的时代,它的重要性是无需质疑的。
这些测试,设计出来是为了检查在两个不同场景下动态插入文本的结果。
1. 测试搜索引擎能否统计动态插入的文本,而文本是来自页面 HTML 源码内的。
2. 测试搜索引擎能否统计动态插入的文本,而文本是来自页面 HTML 源码外的(在一个外部 JavaScript 文件内)。
结果:在两个案例中,文本都能被抓取和收录,并且页面是根据该内容进行排名。爽!
为了了解更多相关信息,我们测试了一个通过 JavaScript 编写的客户端全局导航,而导航里的链接都是通过 document.writeIn 函数插入,并且确定它们能被完全抓取和跟踪。应该指出的是:Google 能解释使用 AngularJS 框架 和 HTML5 History API(pushState)构建的网站,能渲染和收录它,并能像传统静态网页一样排名。这就是 不禁止谷歌爬虫 获取外部文件和 JavaScript 的重要性,而且这也许是 Google 正在从 《支持 Ajax 的 SEO 指南》 中移除它的原因。当你能简单地渲染整个页面时候,谁还需要 HTML 快照呢?
经过测试后发现,不管什么类型的内容,都是同样的结果。例如,图像加载到 DOM 后会被抓取和收录。我们甚至做了这样的一个测试:通过动态生成 data-vocabulary.org 结构数据来制作 breadcrumb(面包屑导航),并将其插入 DOM。结果呢? 成功插入后的面包屑出现在搜索结果中了 (search engine results page)。
值得注意的是,Google 现在 推荐用 JSON-LD 标记 形成结构化数据。我敢肯定将来会出现更多基于此的东西。
4. 动态插入 Meta 数据 & 页面元素
我们将各种对 SEO 至关重要的标签动态插入到 DOM:
- Title 元素
- Meta 描述
- Meta robots
- Canonical tags
结果:在所有案例中,标签都能被抓取,其表现就像 HTML 源码里的元素一样。
一个有趣的补充实验帮助我们理解优先顺序。当存在冲突信号时,哪一个会胜出呢?如果源码里有 noindex、nofollow 标签,而 DOM 里有 noindex、follow 标签的话,将会发生什么呢?在这协议里,HTTP x-robots 响应头部的行为如何作为另一个变量?这将是未来综合测试的一部分。然而,我们的测试显示:当冲突时,Google 会无视源码里的标签,而支持 DOM。
5. 一个带有 rel =“nofollow” 的重要例子
我们想测试 Google 如何应对出现在源码和 DOM 的链路级别的 nofollow 属性。我们也因此创建了一个没有应用 nofollow 的控件。
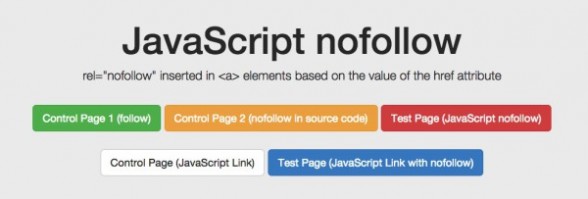
对于 nofollow ,我们分别单独测试源码 vs DOM 生成的注解。
源码里的 nofollow 正如我们所期待的那样运行(链接没被跟踪)。而 DOM 里的 nofollow 却失效(链接被跟踪,并且页面被收录)。为什么?因为在 DOM 里修改 href 元素的操作发生得太晚了:Google 在执行添加 rel=”nofollow” 的 JavaScript 函数前,已准备好抓取链接和队列等待着 URL。然而,如果将带有 href =”nofollow”的 a 元素插入到 DOM,nofollow 和链接因在同一时刻插入,所以会被跟踪。
结果
从历史角度上看,各种 SEO 推荐是在任何可能的时候,要尽可能专注 ‘纯文本’ 内容。而动态生成内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对 Google 不再是问题。 JavaScript 链接以类似普通的 HTML 链接方式运行(这只是表面,而我们不知道幕后程序进行了什么操作)。
- JavaScript 重定向都会以类似于 301 重定向方式对待。
- 动态插入内容,甚至 meta 标签,如 rel canonical 注解,无论在 HTML 源码,还是在最初 HTML 被解析后触发 JavaScript 生成 DOM ,都以同等方式对待。
- Google 视乎能完全渲染页面和理解 DOM ,而不仅是源码。实在是令人可不思议!(记得允许谷歌爬虫获取那些外部文件和 JavaScript。)
Google 已经在创新方面,以惊人的速度将其它搜索引擎甩在身后。我们希望看到其它搜索引擎能有同样类型的创新。如果他们要保持竞争力,并在 web 新时代取得实质性进展,这意味着它们要更好地支持 HTML5、JavaScript 和 动态网站。
对于 SEO,那些没有理解上述基本概念和 Google 技术的人,应该好好研究和学习,以赶上当前技术。如果你不把 DOM 考虑在内,您可能会丢失一半份额。
注:相关网站建设技巧阅读请移步到建站教程频道。
本文标题:爬虫抓取-Google 爬虫如何抓取 Javascript 的?61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1