一 : 利用微博开展网站推广、获取流量的利弊分析
诚然,时下发展最快的网络媒介无疑是微博,这种从09年开始的兴起的媒介现在正以迅雷不及掩耳之势,迅速占领信息分享、传播以及获取平台,这里面最为热门的当推新浪微博、腾讯微博。关于利用微博进行开展SEO工作、获取流量,也正成为时下的热点。
自从百度搜索引擎提供抓取微博内容以来,已经看到过不少关于利用微博进行推广、获取流量的文章,大概内容就是抓住实时热点(百度实时热点),在自己网站上发布实时热点相关内容,在腾讯、网易、搜狐微博上利用简短文字加以评论并添加网站文章地址。这样,在搜索相关热点内容时,会在下面的微博内容处显示微博内容:
这里不想就如何操作进行描述,只是说明一下自己的分析。
这种方式的优点:
一 实时热点一般关注度比较高,搜索人群也相对多
二 微博的简短文字加以利用可以更加吸引人的眼球,以点击查看详细内容;
通过高关注度的内容加以利用,可以更快捷的获取流量、推广网站,这点就是利用了实时内容搜索,搜索引擎提供的这种搜索方式,无疑推动了微博的进一步发布。
不足之外:
一 以上三个微博需要认证后方可以在百度搜索上看到。当然,认证需要一定条件。
二 百度搜索显示微博内容具有实时性,显示条目有限,当一个热点新闻过于白热化时,你发布的内容存在的时间会很短暂。
玩过微博的人都知道,认证需要一定的条件,不是真正的开放,自然也有一定的难度存在。现在的百度搜索微博的实时内容还只是针对认证用户,相信以后会有变动,毕竟这是一种尝试,还处于发展阶段。
百度推出实时搜索,加强了与微博的互动,相信百度推出此项措施也无非是加强与以上三方的一种合作方式。对于SEO来说,现在也是一种新鲜的尝试,也处于发展中,它的优点尽现,缺点也很明显。如何利用微博来更好的开展SEO工作,起码现在还是摸着石头过河。
石家庄易诚网络www.0311cn.com A5 原创,转载请保留!
二 : 网络流量分析24
第11期2002年11月
电 子 学 报
ACTAELECTRONICASINICAVol.30 No.11
Nov. 2002
网络流量宏观行为分析的一种时序分解模型
程 光,龚 俭,丁 伟
(东南大学计算机科学与工程系,江苏南京210096;江苏省计算机网络技术重点实验室,江苏南京210096)
摘 要: 大规模网络中的流量行为体现为一个相当复杂的非线性系统,目前国内外对它的研究还没有成熟的方
法.文章考虑网络流量非线性的特点,通过不同的数学模型将流量时间序列分解成趋势成分、周期成分、突变成分和随机成分.根据分解,利用相应的数学工具分别建模四个相对简单的子成分以仿真复杂流量.使用分解模型分析CER2NET主干网络和NSFNET主干网络的长期流量行为,并将分析结果同传统的ARIMA季节模型比较.通过比较仿真自相关函数和预报误差,发现分解模型在描述流量宏观行为时具有简单和高精度的优点.
关键词: 非线性;流量宏观行为;分解模型中图分类号: TP393107 文献标识码: A 文章编号: 037222112(2002)1121633205
ATime2SeriesDecomposedModelofNetworkTraffic
Macro2BehaviorAnalysis
CHENGGuang,GONGJian,DINGWei
(DepartmentofComputerScience&Engineering,SoutheastUniversity,Nanjing,Jiangsu210096,China;KeylabofComputerNetworkTechnologyJiangsuProvince,Nanjing,Jiangsu210096,China)
Abstract: Trafficbehaviorinalarge2scalenetworkisveryperplexingandcanbeviewedasacomplicatednon2linearsystem.Sofartheresearchontrafficbehaviordoesn’thaveawell2roundedmethod.Accordingtothecharacterofnon2linearnetworktraffic,thetraffictimeseriesisdecomposedintotrendcomponent,periodcomponent,mutationcomponentandrandomcomponent.Withsuchde2composition,acomplicatedtrafficcanbesimulatedbycompoundoffoursimplersub2serieswithdifferentmathematicaltools.Inordertocheckourmodel,thelong2termtrafficbehavioroftheCERNETbackbonenetworkandNSFNETbackbonenetworkareanalyzedus2ingthedecomposedmodel,andtheresultsarecomparedwithARIMAmodel.Accordingtotheautocorrelationfunctionvalueandpre2dictionerrorfunctionvalue,thedecomposedmodelhastheadvantageofsimplicityandhighprecisiontodescribethetrafficmarco2be2havior.
Keywords: non2linearity;trafficmacro2behavior;decomposedmodel
1 引言
大规模网络管理、规划、设计以及新一代网络体系结构的
设计等均离不开对网络流量行为(trafficbehavior)的理解.研究网络流量行为首先是要直接对测量流量数据进行统计分析,寻找统计规律,这方面代表性的工作是MCI的Thompson[1],他完成对MCI网络两个测量点的24小时、7天的流量进行详细分析.其次是在流量统计分析的基础上建立流量模型,如:94年Leland[2]等人对以太网测量数据进行统计分析发现以太网流量具有自相似性,并建立网络流量自相似模型.对网络流量行为特征的研究还可在不同测量时间粒度上展开.Paxson和Floyd[3]的研究发现,不同时间粒度流量服从不同的行为规律:毫秒级的超细时间粒度的流量行为由于主要受网络协议的影响,不体现自相似特征;小时级以上粗时间粒度的流量行为由于主要受外界因素的影响,也不具有自相似性,是一种非线性
复杂的过程;只有秒级细时间粒度的流量行为体现出自相似性.本文的研究是粗时间粒度下流量时间序列模型,其结果更多地体现网络行为的宏观特征,因此也称为宏观流量行为.
在描述网络流量行为的模型中,时间序列模型起着相当重要的作用.由于传统的宏观流量时序模型只能处理平稳过程和特殊的非平稳过程,所以描述流量行为误差较大.如:AR[4]模型、MA模型和ARMA[5]模型用于解决平稳过程,ARI2MA[5]模型、ARIMA季节模型[6]、小波分解法[7]等处理非平稳过程.由于大规模网络本身是复杂非线性系统,同时又受多种复杂外界因素的影响,其宏观流量行为往往复杂多变,数据中既含有多种周期类波动,又呈现非线性升、降趋势,还受到未知随机因素的干扰,而这些特点难以用传统模型来描述.
考虑网络流量宏观行为的特点,本文使用不同的数学工具将网络流量时序分解成结构相对简单的子成分,通过对各
收稿日期:2002202206;修回日期:2002207216
基金项目:国家自然科学基金重点项目(No190104031);国家863项目(No12001AA112060)
1634 电 子 学 报2002年
子成分的分别研究来获得复杂流量总体行为的认识,并描述
和预测流量行为的非线性规律.文章的最后还通过三组实测数据验证理论模型并同传统的ARIMA季节模型比较.实现分离流量序列X(t)中的突变成分B(t),得到不包含B(t)的新序列X1(t).212 流量趋势成分分解趋势成分A(t)分解模型借鉴灰色系统的GM(1,1)理论模型.GM(1,1)模型能从包含趋势成分、周期成分、随机成分复杂的流量序列X1(t)中分离出趋势成分A(t),趋势成分分解模型具体算法如下:
(1)建立累加方程.设流量序列X1(t)表示为下列流量序
2 网络流量分解模型
由于产生网络流量的用户行为受各种外界因素的影响,其上网行为具有一定的规律性和偶然性,同时大规模网络本身是一个非线性系统,因而产生的非线性宏观网络流量具有一定的规律性、突发性和偶然性.根据流量行为的这些特性,表示宏观非线性流量的时间序列X(t)可以分解为趋势成分
A(t)、周期成分P(t)、突变成分B(t)和随机成分R(t)组成,
列:
X1
(0)
={X100,X110,…,X1i0,…,X1n0}
()()()()
(7)
其中:X1(0)为分离突变成分后的流量序列X1(t),X1(i0)为第i时刻的流量速率,i∈[0,n].对式(7)1次累加生成X1(1)为:
X1
(1)
宏观流量时序表达式可分解如下:
(1)X(t)=B(t)+A(t)+P(t)+R(t)
其中趋势成分A(t)反映的是流量行为因网络用户或环境因素而引起的长期变化趋势.周期成分P(t)反映的是流量现象的周期性变化.突变成分B(t)是表示流量行为受到外部突变影响而形成的变化.趋势成分、周期成分和突变成分反映了流量时间序列变化中的确定性成分,随机成分R(t)又可进一步分解为:平稳时间序列成分S(t)和噪声N(t).
(2)R(t)=S(t)+N(t)
在流量时间序列的五个组成成分中,突变成分和噪声属于“无记忆”成分;而A(t)、P(t)和S(t)是有“记忆”的成分,它们分别反映X(t)的长期趋势、周期和平稳过程等三方面的客观行为规律.三种“记忆”可以分别建立数学模型:a(t)、p(t)和s(t),如果我们忽略影响建模的“无记忆”成分,则根据流量X(t)的分解模型可以合成模型x(t):
(3)x(t)=a(t)+p(t)+s(t)
根据流量分解模型(1)和(2),分别采用不同的数学工具将流量分解成五个组成子成分,将“记忆”子成分分别建模,并根据合成模型(3)建立原始序列的时序模型.211 流量突变成分分解
流量突变成分分解模型利用“中位数”是均值的鲁棒估计的事实.流量序列X(t)剔除突变成分算法如下:
(1)用流量序列X(t)构造一个新的序列X′(t),即:
(t)=middle(X(t-2),X(t-1),X(t),X(t+1),X(t+2))X′
(4)
其中,middle()是求括号列表序列中位数的函数,t∈[2,n-2];
(2)同(1)步从X′(t)的相邻的三个数据中选取中位数构
(t),即:成序列X″
(t)=middle(X′(t-1),X′(t),X′(t+1))(5)X″
其中,middle()函数意义同(1),t∈[3,n-3];(3)最后使用式(6)由序列X″(t)构成X??(t),
(t-1)/4+X″(t)/2+X″(t+1)/4(6)X??(t)=X″
其中,t∈[4,n-4];
(4)分析序列X(t)-X??(t),if|X(t)-X??(t)|>k,then用线性内插值法代替X(t),其中,t∈[4,n-4],k为预先确定值.
对[4,n-4]集合中的每个测量点按以上4步处理,即可
={X101,X111,…,X1i1,…,X1n1}=
()()()()
(8)
()
式中:
=X10,
(0)
()X1i1
t=0
∑X10
i
()t=X1i1-1+X1i0,i∈[1,n],X101
()()
()X1i1
实际是从0到i时刻这段时间内网络流量吞吐
量.
由于序列X1(1)接近指数曲线,故认为是光滑离散系数,可用微分方程描述.一阶带系数的微分方程表达式为:
dt
(1)
(1)
+aX1=b(9)
其解可写成
X1t
(1)
-()
)e=(X101-a
at
+
a
(10)
式中:参数a、b为待估参数,
(2)a、b参数估计.参数估计应用最小二乘法来求解,写成矩阵形式:其中
-X=
Y=XB
(11)
()()|X101+X111|
2
()()|X111(2)+X121|
2
11
,Y=
X11X12
(0(0)
-
…
()()-|X1n1-1+X1n1|2
1
…
X1n0
()
,B=
a则:B=(X′X)
-1
X′Y
(3)趋势成分模型a(t)
确定了参数a、b之后,可计算出流量X(t)中的A(t)的模型a(t)为:
()()
(12)a(t)=X1t1-X1t1[1,n]-1,t∈根据式(10)和(12),流量模型可表示为式(13)
a(t)=(e-a
()
-1)(X101-
-)ea
a(t-1)
,t∈[1,n](13)
令X2(t)=X1(t)-a(t)=P(t)+R(t)为分离出趋势成分后的剩余序列,X2(t)实际是X1(t)以A(t)为轴心的新序列,其优点是新的序列能突出P(t)成分的作用.
213 流量周期成分分解
周期成分分解模型将X2(t)序列看成是由不同周期的规则波动态叠加而成,因而在分离周期时,逐步分解出一些比较明显的周期波,然后叠加起来作为该时间序列的周期成分.
第 11 期程 光:网络流量宏观行为分析的一种时序分解模型1635
(1)列出X2(t)中可能存在的周期.在分析周期之前,事
先并不知道这一序列存在多少个周期,所以要根据序列长度,列出可能存在的周期,逐个试验,即:
K=
2
=
22
,n为偶数
(14)
,n为奇数
式中:βp,j(j=1,2,…,P)为自回归系数,P为模型阶数.算法描述如下:
(1)计算模型系数.自回归系数利用最小二乘法,建立Yule2Walker方程组:β1,1=γ1
k-1
γk-βk,k=
1-
式中:n+1为X2(t)序列长度;K为最大可能周期数.
(2)计算离均差平方和.将时间序列按每一试验周期排列,计算离均差平方和,包括排列组内离均差平方和(式15)及组间离均差平方和(式16).
kmm
22
(yij-x(15)Q2=∑∑??j),x??j=∑yij
j=1
i=1
k-1
β-1∑
kk
n-k
,kk-j
γ
,k=2,3,…,γk=
,jj
∑X3X3+
t
t
nt=1
k
j=1
β-1γ∑∑X32
t
βk,j=βk-1,j-βk,βkk-1,k-j,j=1,2,…,k-1
(19)
m
i=1
k
2
Q3
=
j=1
x-∑m(??
j
x),????x=
2
m
m
i=1
x∑??
i
(16)
式中,βi,j为自回归系数,γk为X3(t)的k阶样本自相关系数.
(2)计算模型阶数.AIC:
AIC=nln
式中:k为选择的周期长度,m为组内项数;yij为时间序列X2(t)按试验周期分组排列后的序列值,其自由度f2=n-k,其自由度f3=n-1.
(3)计算试验周期的方差比.试验周期的方差比计算公式为:
Q/fF=2
Q2/f2
2
(X3(t)
-X3)
2
n-P-1
(20)
(17)
(4)检验方差.选定某一信度α=0105,查F分布表得Fα,
式中:X3为X3(t)的均值;n为X3(t)序列长度;P为模型阶
数.
(3)平稳序列模型s(t).计算s(t)之前首先要定义s(0)之前的P个数据,根据的反向X3(t)赋值给s(t),得到观测点之前的数据s(-1),s(-2),…,s(-p).使用这些数据作为初始值,得到模型(21)
s(t)=βp,1s(t-1)+βp,2s(t-2)+…+βp,ps(t-p),
t∈[0,n] (21)
ifF>Fα,then试验周期存在;else,不存在该周期,执行第5
步.
(5)k从2直至K,逐一取值进行(2)-(4)步骤测试,直至
3 网络流量分析
为了验证上述分解模型,下面对三组不同时间粒度的实测网络流量进行分析并建模.一组来自于2001年上半年通过CERNET地区主干某路由器11天的流量(cernet01,时间粒度为小时,见图1),一组来自2001年上半年通过CERNET国家主干某路由器121天的流量(cernet02,时间粒度为日,见图2),另一组来自于1988年8月1日至1993年6月30日通过NSFNET国家主干流量[8](nsfnet,时间粒度为周,见图3).
无显著周期为止.214 流量随机成分分解
令X3(t)=X2(t)-p(t)=R(t)=S(t)+N(t),我们关心的是从随机成分中提取S(t)成分,建立s(t)模型.对平稳时间序列成分可建立自回归模型AR(P),
x(t)=βp,1x(t-1)+βp,2x(t-2)+…+βp,px(t-p)(18)
图1 cernet01时间序列 图2 cernet02时间序列 图3 nsfnet时间序列
311 各trace的分解模型参数
使用分解模型算法分别对三种trace建模,模型参数见表1所示,312 建模分析
网络流量长期行为基本特性可用自相关函数ACF(i)来反映.图2的cernet02trace时间序列图,由于趋势成分在总流量序列中起决定优势,将周期成分掩盖了,因此在图2中流量序列的周期行为不明显.图4为剔除B(t)和A(t)后剩余流量序列的自相关函数图,由于残余流量序列中周期成分占较
大比例,因此图4中的序列明显具有7天周期行为.
图5为将趋势成分、周期成分剔除后的自相关函数图,图5的残余序列自相关函数图具有托尾性质,当lag增大时,ACF趋近于0,这种被负指数控制的衰减形式,其图象如一条越来越小的尾巴,这种行为符合AR(p)自回归模型的性质.流量序列自相关函数图表明流量分解模型的合理性.313 与ARIMA季节模型的比较
将分解模型同ARIMA季节模型进行仿真建模和预测比较.cernet01和nsfnet两组trace进行预报比较,使用预报误差
1636 电 子 学 报2002年
error比较两种模型效果,error定义为式(22).cernet02trace进cernet01中n为240,r为24.nsfnet中n取253,r取52.
SSD(m)=
n-1
ni=1
行仿真效果比较,使用自相关函数无偏估计样本方差SSD比较两种模型的效果,SSD定义为(23).
1+r
∑(ACF
m
(i)-ACFs(i))2
(23)
SSD(m)表示模型m的自相关样本方差量,ACFm(i)表示模
i
error=
∑(X
-Xi)2
(22)
r
式(22)中,n为序列中用于建模的时间长度,r为预测的长度.
型m的第i阶自相关函数,ACFs(i)表示实测样本序列的第i阶自相关函数.该统计量反映了模型对序列自相关函数的描述效果,值越小,效果越好.
表1 cernet01、cernet02和nsfnettrace的分解模型参数表
分解模型参数
T
race
A
A(t)
B
P(t)
S(t)
B
AR(p)
周 期
2472652
A
cernet01Cernet02
-010009-010052
12111091491592
-010056010003-014057-016547
1521802501804841470951734
016863016842010639017024010196
010352011016010711010082-011535
-010090-010011010394
-011438-011706
Nsfnet-010181081962
图4 cernet02周期、 图5 cernet02随机 图6 分解模型与cernet02 图7 ARIMA季节模型与cernet02
随机自相关
成分自相关
的自相关函数
的自相关函数
三种trace的ARIMA季节模型分别为:
cernet01预报模型:ARIMA(2,0,2)×(0,1,0)24:参数(β1,β2,θ1,β2)=(011652,-01676,018705,-1294);
nsfnet预报模型[6]:ARIMA(2,2,1)×(2,2,0)52:参数(β1,β2,θ1,β3,β4)=(-01176822,-01000685,01993894,-01273511,01653531).
cernet02仿真模型:ARIMA(7,0,0)×(0,1,0)7:参数(β1,β2,…,β7)=(016606,011631,-010805,-011232,-010085,011721,-012153).
误差等于流量中的B(t)和N(t)成分,所以在描述流量时精度高于传统模型.
4 结论
本文研究大规模宏观网络流量的分解建模方法,并分别使用小时、日、周三种不同时间粒度的实测数据和仿真数据的自相关函数对该方法进行了验证.研究发现CERNET用户行为存在以日为周期和以小时为周期的行为,日周期行为的语义背景是比较清楚的,它反映了用户对上网时间的选择.而周为周期流量行为所反映的用户行为语义则较为复杂,它一定程度上反映了CERNET用户对网络的依赖性和使用的后效性.通过分解模型我们发现nsfnet流量不仅存在以年[6]为周期的特性,同时还存在半年为周期的特性.当然,对于流量周期行为产生原因的更深入研究需要进一步分析流量中不同网络应用组成成分及会话数等统计量的变化等因素.
分解模型同传统ARIMA季节模型的实验结果比较发现分解模型精度高于ARIMA模型一倍左右.分析其原因发现分解模型具有以下优点:首先,分解模型从多角度、多侧面、多个不同类型的子模型描述流量行为,而传统模型仅从某一方面描述流量行为性质;同时分解模型描述流量行为需要比传统模型更多的参数,分解模型的仿真误差只有与流量行为规律无关的“无记忆”成分B(t)和N(t),因此分解模型能比传统
对cernet02采用仿真技术,分别产生2种模型的样本,并与原始序列进行比较.图6是分解模型与cernet02自相关函数的比较,图7是ARIMA季节模型同cernet02自相关函数的比较.从图6和图7可知分解模型的仿真精度远高于ARIMA季节模型的仿真精度.
表2 cernet02各模型的SSD
统计量
模型SSD统计量分解模型0.000984ARIMA季节模型0.005471
表3 各模型的error统计量模型分解模型ARIMA模型
cernet01
error
nsfnet
error
618110126
209131421192
表2为cernet02仿真模型中的SSD统计量,表3为cer2net01和nsfnet预报error统计量.从表2和表3可知,本文的分解模型描述宏观流量序列是非常有效的.理论上分解模型的
第 11 期程 光:网络流量宏观行为分析的一种时序分解模型1637
模型更精确、更完整地在描述流量行为.其次,由于分解模型是由各模块组成,每个模块描述流量的某一方面性质,同传统模型相比,对每个模块分别建模较为简单,便于计算机软件实现.参考文献:
[1] KevinThompson,GregoryJMiller,RickWilder.Wide2areainternet
trafficpatternsandcharacteristics[J].IEEENetwork,1997,5(6):10-23.
[2] WELeland,MSTaqqu,WWillinger,DVWilson.Ontheself2similar
natureofethernettraffic[J].IEEE/ACMTransactiononNetworking,1994,2(1):1-15.
[3] VPaxson,SFlod.Wide2areatraffic:Thefailureofpoissonmodeling
[J].IEEE/ACMTransactionsonNetworking,1995,3(3):226-244.
[4] RichWolski.Forecastingnetworkperformancetosupportdynamic
schedulingusingthenetworkweatherservice[DB/OL].UCSDTech2nicalReport,TR2CS962494,1996,.
[5] SBasu,AMukherjee.Timeseriesmodelsforinternettraffic[A].
Proc.IEEEINFOCOM’96[C].SanFrancisco,CA:March,1996,2.611-620.
[6] NGroschwitz,GPolyzos.Atimeseriesmodeloflong2termtrafficonthe
NSFnetbackbone[A].InProceedingsoftheIEEEInternationalCon2ferenceonCommunications(ICC’94)[C].NewOrleans,LA:May1994.
[7] 徐科,徐金梧,班晓娟.基于小波分解的某些非平稳时间序列预
测方法[J].电子学报,2001,29(4):566-568.
[8] KClaffy,GCPolyzos,HWBraun.TrafficcharacteristicsoftheT1
nsfnetbackbone[A].proceedingsIEEEINFOCOM’93[C].SanFran2cisco,California:March282April1,1993.885-892.
作者简介
:
程 光 男,1973年2月出生于安徽黄山,东南大学计算机系博士研究生,研究方向:计算机网络行为学.email:gcheng@njnet.edu.
cn.
龚 俭 男,1957年8月出生于上海,东南大学计算机系博士生导师,研究方向:网络行为学,网络安全.email:jgong@njnet.edu.cn.
第八届中国密码学学术会议征文通知
第八届中国密码学学术会议拟定于2004年5月下旬在上海(具体时间待定)举行.热忱欢迎所有涉及密码学(数学的和非数学的)、信息安全理论和关键技术方面的研究论文提交本次会议交流.重要日期:
征文截止日期:2003年07月31日;文章录用通知:2003年10月31日;录用论文定稿:2003年11月20日征文要求:
提交论文必须是未公开发表并且未向学术刊物和其它学术会议投稿的最新研究成果,文稿可用中文书写,同时鼓励用英文书写,字数一般不超过6000.作者应将论文全文(务必注明作者的详细地址、联系电话和Email地址)的Word/PDF文档,或论文全文的打印稿一式三份寄至以下地址之一:
贵州大学计算机系 李祥 教授 上海交通大学计算机系 陈克非 教授贵州省贵阳市 上海市华山路1954号邮政编码:550025 邮政编码:200030Tel:0851-3621767 Tel:021-62932135Email:lixiang@gzu.edu.cn Email:kfchen@mail.sjtu.edu.cn会议论文集:
会议论文集将以“密码学进展2ChinaCrypt’2004”由著名学术出版社发行,会议还将推荐优秀英文论文在EI检索源学术刊物上发表.
其它联系信息:
欲进一步了解会议的有关信息,欢迎访问有关站点,也可直接与我们联系:
上海交通大学计算机科学与工程系 陈克非 教授Tel+Fax:021-62932135
三 : 网站推广 最容易被忽视的部分:流量分析
网站的运营状况是我们最关心的,其实也就是网站的流量和收入,而产生流量和收入的根源就是推广方法,所以我们大多数网站运营者把精力投入到了网站推广方法中去,所以对其他方面的因素所投入的精力就会相对较少了,但是当推广做到一定程度的时候就需要大家在另一个事情上投入一定精力了,那就是流量分析,但是很多网站运营者忽略了这一点,认为有流量就是好的,还是按照原来的方法来做,但是殊不知有些工作是在做无用功。
流量分析的好处我就不多说了,主要就是为了下一步的推广更有针对性,少做一些无用功。那么我们要说的就是流量分析要分析哪些方面,仅仅是来路吗,不是的,下面61阅读的小编和大家一起分享一下:
1、来路分析是流量分析的第一大要素
来路是我们分析流量的第一要素,因为来路可以看出我们在哪些地方的推广起到效果了,哪些地方的效果会更好一些,哪些地方可能会产生更好的效果值得我们进一步下力气来做,哪些地方我们该舍弃,顺便说一句:百度排名不一定适用于任何一种产品,只能说他适合大部分的产品,像一些优化难度非常大而百度推广点击费率又比较高的词语可能不如论坛或者微博营销带来的收益高,来得快。所以分析来路是流量分析的第一要素。
2、时间段分析是流量分析的第二要素
任何一个网站的被访问都是有一定的规律的,大部分的网站流量都会产生在白天,但是也有一些产品的流量会产生在晚上,比如电影类网站,大部分的流量会产生在晚上,因为白天大部分人都需要工作或做其他的事情,晚上回到家可以寻找不错的电影来看一下。而女装专卖网站的流量高峰会产生在上午11:00到下午2:00,再就是下午5:00到晚上10:00,因为这段时间很符合大部分女性的休息时间,随着网购越来越被热衷,广大女性朋友在业余时间除了选衣服就是在买包,要不就看看哪种化妆品不错。所以有针对性的推广投入会获得事半功倍的效果。再比如说我一个朋友运营的网站,是一个根治脚气的药物网站,大部分的流量产生在夜间,因为夜间是脚气最活跃的时候,当劳累一天静下来的时候,钻心的脚痒会让患者想起来寻找与脚气相关的东西。
3、地区分析是流量分析的第三个要素
有很多东西都是面向所有人群的,比如我们刚刚提到的电影,但是有些东西面向的区域性很强,比如电脑维修,监控设备安装等,地区性非常明显,所以在做推广的时候,就需要针对该区域进行,再比如某个地区性分类信息网站,可能每天有几百流量,但是我们希望大部分的流量来自于本地,如果这时候大部分的流量来自于外地,说明推广还是不到位,没有和你所面向的客户群建立联系,就需要及时调整推广方法了。
以上三点就是流量分析比较重要的三个重点,任何一个第三方流量统计平台统计的不仅仅是这些内容,还有一些其他更详细的内容,如当前在线,页面停留时间,访问的哪些页面等,但是与后期推广联系最紧密的就是以上三点了,所以老曹建议大家在进行下一步的推广之前,最好不断的对流量进行一下分析,这样才能保证下一步的推广更有针对性,让好钢用在刀刃上。
以上就是通过流量来分析如何把网站推广做到最细致,流量人群一但确定,推广起来就更加省时省力,谢谢大家阅读。
四 : 网站分析工具 通过流量特点来分析网站
这里先介绍一下内容浏览模块(主要指的是网站的页面浏览)下的各种度量,以及基于这些度量我们可以实现哪些细分。
我们在使用一些网站分析工具的时候会发现一般报表会被分成三大模块:用户访问、内容浏览和流量来源。每个分类都由各种分析度量组成了各类的展示报表,这里先介绍一下内容浏览模块(主要指的是网站的页面浏览)下的各种度量,以及基于这些度量我们可以实现哪些细分。
页面的基本度量
下面罗列的是一些页面的度量:
页面浏览次数(Pageviews)
页面被打开或请求的次数。
唯一页面浏览次数(Unique Pageviews)
这个是Google Analytics上面使用的一个度量,主要是避免页面的重复加载和刷新导致Pageviews虚高的情况,所以在同一个Visit当中重复打开同一个页面,该页面的Unique Pageviews始终只被记为1次。
访问次数(Visits)
页面的被访问次数,如果按照独立页面来计算每个页面的Visits,其实结果与上面的Unique Pageviews是一致的,所以很多网站能分析工具里面没有Unique Pageviews,而直接用Visits来衡量页面的唯一浏览量。但需要注意的是Visits也常被用作整个网站或者某些内容分类汇总的度量,在这种情况下,网站的总Visits和总Unique Pageviews是不一致的,比如Visit A访问了a-b-a-c4个页面,而Visit B只访问了a-b,那么对于a页面而言,Pageviews是3,Unique Pageviews是2,Visits也是2,但对于这个网站而言,Unique Pageviews是5,而Visits只有2个。
唯一访问用户数(Unique Visitors)
这个应该容易理解,就是进入这个页面的不同IP或者Cookie的个数。
页面停留时间(Time on Page)
用户浏览一个页面时在该页面逗留的时间,在度量页面时,更多的是根据用户取平均值,即页面平均停留时间(Avg. Time on Page)=所有用户浏览该页面时停留时间总和/浏览该页面的总用户数。
直接跳出访问数(Bounces)
也许你可以看到过很多关于这个定义的解释了,一般的网站分析工具,都会将从该页面进入网站并直接离开的访问称为Bounce。而这个度量更多的是以Bounce Rate的形式出现,即从该页面直接跳出的访问数/从该页面进入的访问数。
进入和离开次数(Entrances and Exits)
这个就顾名思义了,从该页面进入、离开的访问数,而一般会以Enter Rate和Exit Rate的形式出现,从该页面进入、离开的访问数/该页面的总访问数。

还有一些其它的页面度量,如新访问用户(New Visits)、目标价值(Goal Value)等。
需要关注的页面度量
我们会注意到一般的网站分析工具的结果展现会有许多不同的报表,并且各类报表中又会有重复或不重复的各类度量,当然每张报表可能都会有其不同的展示角度并提供不同的数据分析的用途。但也许我们日常无法全面地关注所有度量,一般都会根据网站的特点着重的关注某些跟网站运营状态息息相关的度量。Google Analytics内容模块的几张报表上一般会展现:
Pageviews、Unique Pageviews、Avg. Time on Page、Bounce Rate、%Exit(离开百分比)及$Index(目标价值指数)
下面列出的是我个人认为对于评价网站页面比较重要的几个度量,或者说是个人比较喜欢和关注的几个度量:
1. 访问量(Visits)或者唯一页面浏览次数(Unique Pageviews)
上面已经对这两个度量进行了介绍,它们对于单个页面而言计算得到的数值是一样的,只会在计算汇总的时候存在差异。那么为什么选择访问量,而不是页面浏览数或者唯一用户数呢?我的理解是在同一个Visit中,如果用户多次浏览同一页面,那么很有可能使用户喜欢刷新或重载页面,或者用户习惯于倒退操作而重复穿梭于你的网站,所以这些重复浏览对于评价页面的优劣比较没有意义;而如果是不同的Visit,即使是同一用户浏览了同一页面,那么我们更多地可以理解为用户对于上次看到的内容意犹未尽,想再仔细研究个究竟,这种页面浏览对于评价一个页面是有效的,所以我更偏向于选择页面的访问量Visits。
2. 崩失率(Bounce Rate)
好吧,无论你怎么称呼它,都不得不承认它的魅力十足,网站有很多相关的文章。
对于它的价值我是这样理解的,用户会直接跳出,无非3种情况:1.误闯;2.内容过于乏味;3.进入的页面也是网站的出口。所以在关注Bounce Rate的时候有必要进行特殊情况特殊分析,比如网站首页的Bounce相对比较高是可以理解的,因为作为网站最前端的大门,可能会有相当一部分用户误闯了进来;而网站的底层内容细节页面的Bounce Rate比较高有可能用户直接进入该页面,找到了需要的信息并离开了,也就是上面所说的第3种情况。而排除这两种特殊的访问,如果其他页面的Bounce Rate偏高,那么说明该页面有问题了。
3. 页面平均停留时间(Avg. Time on Page)
这个应该比较容易理解,用户需要获取你页面中的某些信息就会需要一定的浏览时间,当然根据页面提供的内容的长短和复杂度,平均停留时间也会存在一定的差异,但我们不需要关注这类情况,我们只需要揪出那些平均停留时间短到用户几乎无法对页面内容作出有效反应就已经离开了的那些页面,毫无疑问这些页面是有问题的。
页面细分
基于上面介绍的这些度量,我们可以选择任何的单个或者多个来对页面进行细分,我想到的有以下结果细分的方法:
基于Pageviews、Unique Pageviews、UniqueVisitors区分热门页面和冷门页面;
基于Avg. Time on Page区分有趣的内容和乏味的内容;
基于Bounce Rate及下一浏览页面的多样性来区分病态页面和枢纽页面;
基于Enter Rate和Exit Rate来识别网站的入口和出口页面;
……
当然,你还可以想到很多种其他细分的方法,只要细分的结果对你的网站而言是有价值的。这里举个简单的用多个度量组合进行细分的例子,选取的度量就是上面3个我认为值得关注的页面度量。既然涉及3个度量,大部分的平面坐标系的图表无法很好的展示,也许你也跟我一样想到了一类图表——气泡图,下面是一个简单展示:

横坐标标识访问量,纵坐标标识Bounce Rate,气泡的半径r标识页面平均停留时间,我们可以将页面细分成4类,分别对应4个象限,其中:
第一象限:较高的访问量和Bounce Rate,所以页面比较热门但并不能吸引所有进入的用户,也许你的网站的首页或者Landing Page正是处于这一象限,你可能需要优化下SEO的关键词或者购买相关性更高的广告或者关键词,也可以优化下你的首页和Landing Page,让它们更具吸引力以留住用户;
第二象限:如果你的网站有很多页面处于这个象限,那么你的网站正处在一个糟糕的状况下,而往往这一象限内的气泡也会比较小;
第三象限:其实在这一象限的某些页面是可以通过提升曝光率来提升它们的访问量,因为从Bounce Rate来看它们并不缺少吸引力;当然,如果某些内容只针对特定人群,而其他人群对它们的兴趣不高,那么处于第三象限也是一个正常的状况;
第四象限:这些页面集中了你的网站的一些黄金内容,看看它们到底在哪些方面吸引了这么多的用户,让其他页面也学习一下它们。
也许你还能想到其它更加有趣的页面细分方法,欢迎与我分享交流。
五 : 判断某个网站流量简单分析
很多站长可能都有一个习惯,看到某个自己感兴趣的网站,第一想知道的就是网站的流量和排名,那么一般我们通过什么来了解某一陌生网站的流量的具体情况呢?
去哪儿网的Karen有一天问我,有这么一个名叫24htl的网站(因本文涉及到网站的真实情况,因此为化名),如何能尽量准确地知道它的人气?——这的确是一个我从前未曾深究的问题,毕竟我的大部分分析是通过添加监测代码实现的,而在无法添加网站分析代码的情况下,我们能够获知一个陌生网站的准确流量吗?
问题的背后其实包含着十分重大的意义。在我们的商业环境中,遇到评估一个陌生网站流量是经常的事情。例如我的同事会考虑用什么样的网站更适合投放客户的广告,他们会需要研究网站的流量。而在进行竞争情报分析的时候,竞争对手网站的流量也是非常有价值的参考信息。所以,我相信,你也一定碰到了与Karen同样的问题,而且你也曾经试着自己去解决它。
那么我们该要如何才能简便易行的获得尽量精确的陌生网站(指你无法直接进行监测的网站)的流量呢?我会在下面把我的办法分享给大家。想请大家注意的是:除了我的这些办法外,一定还有更多更好的办法,希望有经验的你不吝赐教,让我们的思路不断拓宽。
Alexa和类似的流量工具
如果没有网站分析工具,要想获得网站的流量当然得依靠第三方。大家一定首先会想到Alexa,其实类似Alexa的工具还有WebSearch Ranking,Compete.com,QuantCast还有Ranking.com和Trafficestimate等等。这些工具的价值在于:
不过,他们的问题在于三点:
所以,我认为在中国使用舶来的网站排名工具是不太适宜的,当然,我相信投行的朋友们还是会看重它——尤其是当你的网站排名能比新浪和开心网还要靠前的时候。
嗯,不开玩笑了。想强调的一点是,如果大家非用这类工具不可,我更推荐Compete而不是Alexa。Compete的数据样本量比Alexa更大,数据来源也更综合,所以数据会更准确。而且它能够提供的数据维度更多,所以比Alexa要更实用。不过Compete没有网站排名,而Alexa有——如果你一定坚持排名比数据本身更重要的话,那还是Alexa吧,不过我觉得排名只不过是娱乐罢了。

图:Compete的界面
iResearch
既然不推荐Alexa等一票洋工具,那么,还是回归本土的iResearch(艾瑞)吧。艾瑞是国内一家著名的互联网研究机构,它的iUertracker通过在网友客户端装入上网行为监测软件来抽样各个网站的流量。由于样本几乎都在国内,因此iResearch能够获得比Alexa精确一些的数据。不过也有人诟病iResearch的样本选择和样本总量,认为它在用户互联网访问行为的数据上可能不具备代表性。另外,更关键的是,它的数据也不是免费的,因此它不太可能作为我们解决Karen问题的好工具——你总不能为了一年研究一两个网站的流量而花上几万元吧。当然,即使你付费,iResearch也不是万能的,小网站不在iResearch的收录范围内,因为它们的流量太小,有限的样本可能完全不会包括它们。
优点:
不足:
我认为,iResearch在研究不知名网站、小流量网站上并不适合,但对大网站则不妨一用。理论上,越是网友经常访问的网站,越有更大的样本量,数据也就相对准确。除了iResearch,类似的工具还有Nielson和ComScore。Nielson在国内也提供相关的付费数据服务。
Google Trends for Websites
相信大家都用过Google Trends,百度也有类似的工具,但是对于Google Trends for Websites可能会有朋友并未注意到。这个工具最大的特点是能够把网站长期的流量(Daily Unique Visitors)趋势显示在一个line chart(线图)上,这样可以从一个更广的时间维度来研究一个网站。当然,如果你在搜索框内输入多个网站的名字然后用逗号隔开的话,这个工具也能够为你提供不同网站间流量的比较。如下图所示:
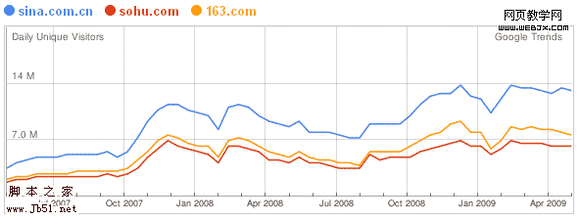
除了提供全部的流量趋势,它还能够显示出这个网站的访问者的地理位置分布,例如下图中左边的Regions数据。如果你点击China,会进一步显示具体的城市信息。而"Also visited“那一栏数据则显示了该网站的访问者还常常访问哪些其他的网站,如下图中新浪的访问者也最倾向于访问qq.com和Baidu。另外,最右边一列显示了访问新浪的访问者会最多的使用哪些关键词,不过似乎数据上有些滞后。

总体而言,这是一个很直观而且很易用的工具,并且有一些数据是其他工具所没有的,例如Also visited和Also serached for这两类数据——毕竟Google在这些数据上占有先天的优势。Google是如何获得流量数据的呢?我认为可能是利用了Google Bar(浏览器上的Google工具条),以及其他一些Google客户端工具,也可能是直接使用了Google Analytics的数据(Google Analytics数据的分享是opt on的)。具体怎么回事,Google官方给出了一些含混的回答。不管怎样,Google本身已经具有的某种垄断特质让我相信他们的数据要比其他类似网站的数据准确得多,在中国也是一样。
这个工具还不能让人满意的地方是:
尽管如此,Google Trends for Websites不失为一个进行竞争网站分析的好工具。
Google Ad Planner
Google Ad Planner是我在研究陌生网站流量上最喜欢的工具,倒不是因为它是为在线广告媒介服务的,而是因为它有直接的数据,而且涵盖了那些已经相当长尾的网站——例如我的这个网站:www.chinawebanalytics.cn。
利用Google Ad Planner来研究网站流量的方法非常简单,你完全不需要用它的那些Ad Planning的工具,你需要的只是登出你的Google账号,然后进入它的首页面。如下图所示:

在上面的输入栏中输入你想要研究的网站,就会得到如下的一个结果页面,
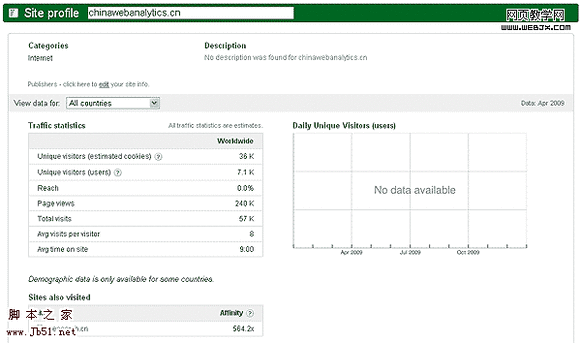
现在大家知道我的网站的流量了:)。图中的数据是月度的,看起来还不错,但是实际上跟GA上监测的数值还是有一定差异的。不过没关系,我们可以把它的数据当做原料,用它来进一步准确估计被研究网站的流量。相信你一定知道应该怎么做了!看看我的办法吧!
所以,曲线救国的方法真是各种研究方法的一句话精辟概括啊!
当然,这个方法也有一定的问题,同Google Trends for Websites一样,数据的精确性取决于Google获得数据的精确性。不过话说回来,百分之百精确的数据只是理论上的,只要能够产生正确insight和recommendation,那么这个数据就是准确(当然,不是精确)的
Google Ad Planner还有一些工具是极为强大的,例如能够对访问人群的Demographic(人口统计概貌)进行细分,可惜这个功能只针对美国人群进行统计,而不包括中国人。建议大家自己注册一个随便尝试一下。
其他一些站长统计工具
除了上面的这些工具能够帮助我们直接获得网站的一些流量数据,我们还可以利用一些更为间接,但是有可能更为有效的方法来评价一个网站的人气程度(毕竟流量本身也是衡量人气程度的一种而已,我们完全可以放开思路用别的方法来衡量人气)。
站长们喜欢用一些业界公认的指标来”炫耀“自己的网站。比如Google PR(Google Page Rank)——这是Google对网站重要性的评级,数字越大越好,最大值是10。我的网站是5,已经一年多了,到现在也没有再往上上一位。这说明每一个级别之间的差异其实是很巨大的,需要付出更多的努力赢得更多的真实流量才能达到。如果你的网站PR是6,那么恭喜你,你的网站已经进入了知名网站的行列。
除了PR,我们有时候也利用”反向链接“(就是有多少网站链向你)来查看一个网站的人气。当然,这个值也是越大越好,多多益善。你可以通过Google搜索引擎的高级功能来查询。另外,你还可以查看这个网站被搜索引擎收录的情况等等。这里介绍给大家一个网站:tool.chinaz.com,其中有不少实用工具,其中就包含我说的这些站长统计工具哦!
网站UGC内容研究
我会用到的最后一招,是研究网站的UGC内容,包括这个网站提供的BBS,提供的留言、询问、评价、打分等等功能,以及访问者的上传。这是一个网站是否hot的极好的风向标。毕竟,如果你的网站是一个电子商务网站,每天访问量超过10万,可是每天用户产生的产品询问不超过5个,那么我仍然会认为这个网站的人气不足。毕竟一个网站能够拉动访问者留下自己的想法是人气的直接体现。说到这里,想起来大学上课时候的情景,老师每天都点名记录考勤,大家不敢逃课,可是他的课实在乏味,所以就出现了全员满座却毫无人气的情况——因为大家全部在睡觉嘛……希望你的网站不要如同这个会催眠的老师。
用户UGC数量和网站的流量一般是成正比关系的,但是这个比例的多少则根据网站的类型不同而定。比如销售消费电子产品的B2C网站,可能对产品评价的比例是每10个购买产品的人,会有1~5个做出评价的,而每10个独立访问者又可能有1个人会购买商品,那么网站流量和UGC的比例大概是100:1到100:5,因此通过数UGC的数量能够大概估量这个网站的流量。
本文标题:网站流量分析-利用微博开展网站推广、获取流量的利弊分析61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1