一 : SQL语句:Group By总结
1. Group By 语句简介:
Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”。(www.61k.com)它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理。
P.S. 这里真是体会到了一个好的命名的力量,Group By从字面是直接去理解是非常好理解的。恩,以后在命名的环节一定要加把劲:)。话题扯远了。
2. Group By 的使用:
上面已经给出了对Group By语句的理解。基于这个理解和SQL Server 2000的联机帮助,下面对Group By语句的各种典型使用进行依次列举说明。
2.1 Group By [Expressions]:
这个恐怕是Group By语句最常见的用法了,Group By + [分组字段](可以有多个)。在执行了这个操作以后,数据集将根据分组字段的值将一个数据集划分成各个不同的小组。比如有如下数据集,其中水果名称(FruitName)和出产国家(ProductPlace)为联合主键:
FruitName | ProductPlace | Price |
Apple | China | $1.1 |
Apple | Japan | $2.1 |
Apple | USA | $2.5 |
Orange | China | $0.8 |
Banana | China | $3.1 |
Peach | USA | $3.0 |
如果我们想知道每个国家有多少种水果,那么我们可以通过如下SQL语句来完成:
SELECTCOUNT(*)AS水果种类,ProductPlaceAS出产国
FROMT_TEST_FRUITINFO
GROUPBYProductPlace
这个SQL语句就是使用了Group By + 分组字段的方式,那么这句SQL语句就可以解释成“我按照出产国家(ProductPlace)将数据集进行分组,然后分别按照各个组来统计各自的记录数量。”很好理解对吧。这里值得注意的是结果集中有两个返回字段,一个是ProductPlace(出产国), 一个是水果种类。如果我们这里水果种类不是用Count(*),而是类似如下写法的话:
SELECTFruitName,ProductPlaceFROMT_TEST_FRUITINFOGROUPBYProductPlace
那么SQL在执行此语句的时候会报如下的类似错误:
选择列表中的列'T_TEST_FRUITINFO.FruitName'无效,因为该列没有包含在聚合函数或GROUPBY子句中。
这就是我们需要注意的一点,如果在返回集字段中,这些字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。我们可以将Group By操作想象成如下的一个过程,首先系统根据SELECT 语句得到一个结果集,如最开始的那个水果、出产国家、单价的一个详细表。然后根据分组字段,将具有相同分组字段的记录归并成了一条记录。这个时候剩下的那些不存在于Group By语句后面作为分组依据的字段就有可能出现多个值,但是目前一种分组情况只有一条记录,一个数据格是无法放入多个数值的,所以这里就需要通过一定的处理将这些多值的列转化成单值,然后将其放在对应的数据格中,那么完成这个步骤的就是聚合函数。这就是为什么这些函数叫聚合函数(aggregate functions)了。
2.2 Group By All [expressions] :
Group By All + 分组字段, 这个和前面提到的Group By [Expressions]的形式多了一个关键字ALL。这个关键字只有在使用了where语句的,且where条件筛选掉了一些组的情况才可以看出效果。在SQL Server 2000的联机帮助中,对于Group By All是这样进行描述的:
如果使用ALL关键字,那么查询结果将包括由GROUPBY子句产生的所有组,即使某些组没有符合搜索条件的行。没有ALL关键字,包含GROUPBY子句的SELECT语句将不显示没有符合条件的行的组。
其中有这么一句话“如果使用ALL关键字,那么查询结果将包含由Group By子句产生的所有组...没有ALL关键字,那么不显示不符合条件的行组。”这句话听起来好像挺耳熟的,对了,好像和LEFT JOIN 和 RIGHT JOIN 有点像。其实这里是类比LEFT JOIN来进行理解的。还是基于如下这样一个数据集:
FruitName | ProductPlace | Price |
Apple | China | $1.1 |
Apple | Japan | $2.1 |
Apple | USA | $2.5 |
Orange | China | $0.8 |
Banana | China | $3.1 |
Peach | USA | $3.0 |
首先我们不使用带ALL关键字的Group By语句:
SELECTCOUNT(*)AS水果种类,ProductPlaceAS出产国
FROMT_TEST_FRUITINFO
WHERE(ProductPlace<>'Japan')
GROUPBYProductPlace
那么在最后结果中由于Japan不符合where语句,所以分组结果中将不会出现Japan。
现在我们加入ALL关键字:
SELECTCOUNT(*)AS水果种类,ProductPlaceAS出产国
FROMT_TEST_FRUITINFO
WHERE(ProductPlace<>'Japan')
GROUPBYALLProductPlace
重新运行后,我们可以看到Japan的分组,但是对应的“水果种类”不会进行真正的统计,聚合函数会根据返回值的类型用默认值0或者NULL来代替聚合函数的返回值。
2.3 GROUP BY [Expressions] WITH CUBE | ROLLUP:
首先需要说明的是Group By All 语句是不能和CUBE 和 ROLLUP 关键字一起使用的。
首先先说说CUBE关键字,以下是SQL Server 2000联机帮助中的说明:
指定在结果集内不仅包含由GROUPBY提供的正常行,还包含汇总行。在结果集内返回每个可能的组和子组组合的GROUPBY汇总行。GROUPBY汇总行在结果中显示为NULL,但可用来表示所有值。使用GROUPING函数确定结果集内的空值是否是GROUPBY汇总值。
结果集内的汇总行数取决于GROUPBY子句内包含的列数。GROUPBY子句中的每个操作数(列)绑定在分组NULL下,并且分组适用于所有其它操作数(列)。由于CUBE返回每个可能的组和子组组合,因此不论指定分组列时所使用的是什么顺序,行数都相同。
我们通常的Group By语句是按照其后所跟的所有字段进行分组,而如果加入了CUBE关键字以后,那么系统将根据所有字段进行分组的基础上,还会通过对所有这些分组字段所有可能存在的组合形成的分组条件进行分组计算。由于上面举的例子过于简单,这里就再适合了,现在我们的数据集将换一个场景,一个表中包含人员的基本信息:员工所在的部门编号(C_EMPLINFO_DEPTID)、员工性别(C_EMPLINFO_SEX)、员工姓名(C_EMPLINFO_NAME)等。那么我现在想知道每个部门各个性别的人数,那么我们可以通过如下语句得到:
SELECTC_EMPLINFO_DEPTID,C_EMPLINFO_SEX,COUNT(*)ASC_EMPLINFO_TOTALSTAFFNUM
FROMT_PERSONNEL_EMPLINFO
GROUPBYC_EMPLINFO_DEPTID,C_EMPLINFO_SEX
但是如果我现在希望知道:
1. 所有部门有多少人(这里相当于就不进行分组了,因为这里已经对员工的部门和性别没有做任何限制了,但是这的确也是一种分组条件的组合方式);
2. 每种性别有多人(这里实际上是仅仅根据性别(C_EMPLINFO_SEX)进行分组);
3. 每个部门有多少人(这里仅仅是根据部门(C_EMPLINFO_DEPTID)进行分组);那么我们就可以使用ROLLUP语句了。
SELECTC_EMPLINFO_DEPTID,C_EMPLINFO_SEX,COUNT(*)ASC_EMPLINFO_TOTALSTAFFNUM
FROMT_PERSONNEL_EMPLINFO
GROUPBYC_EMPLINFO_DEPTID,C_EMPLINFO_SEXWITHCUBE
那么这里你可以看到结果集中多出了很多行,而且结果集中的某一个字段或者多个字段、甚至全部的字段都为NULL,请仔细看一下你就会发现实际上这些记录就是完成了上面我所列举的所有统计数据的展现。使用过SQL Server 2005或者RDLC的朋友们一定对于矩阵的小计和分组功能有印象吧,是不是都可以通过这个得到答案。我想RDLC中对于分组和小计的计算就是通过Group By的CUBE和ROLLUP关键字来实现的。(个人意见,未证实)
CUBE关键字还有一个极为相似的兄弟ROLLUP, 同样我们先从这英文入手,ROLL UP是“向上卷”的意思,如果说CUBE的组合是绝对自由的,那么ROLLUP的组合就需要有点约束了。我们先来看看SQL Server 2000的联机中对ROLLUP关键字的定义:
指定在结果集内不仅包含由GROUPBY提供的正常行,还包含汇总行。按层次结构顺序,从组内的最低级别到最高级别汇总组。组的层次结构取决于指定分组列时所使用的顺序。更改分组列的顺序会影响在结果集内生成的行数。
那么这个顺序是什么呢?对了就是Group By 后面字段的顺序,排在靠近Group By的分组字段的级别高,然后是依次递减。如:Group By Column1, Column2, Column3。那么分组级别从高到低的顺序是:Column1 > Column2 > Column3。还是看我们前面的例子,SQL语句中我们仅仅将CUBE关键字替换成ROLLUP关键字,如:
SELECTC_EMPLINFO_DEPTID,C_EMPLINFO_SEX,COUNT(*)ASC_EMPLINFO_TOTALSTAFFNUM
FROMT_PERSONNEL_EMPLINFO
GROUPBYC_EMPLINFO_DEPTID,C_EMPLINFO_SEXWITHROLLUP
和CUBE相比,返回的数据行数减少了不少。:),仔细看一下,除了正常的Group By语句后,数据中还包含了:
1. 部门员工数;(向上卷了一次,这次先去掉了员工性别的分组限制)
2. 所有部门员工数;(向上又卷了依次,这次去掉了员工所在部门的分组限制)。
在现实的应用中,对于报表的一些统计功能是很有帮助的。
这里还有一个问题需要补充说明一下,如果我们使用ROLLUP或者CUBE关键字,那么将产生一些小计的行,这些行中被剔除在分组因素之外的字段将会被设置为NULL,那么还存在一种情况,比如在作为分组依据的列表中存在可空的行,那么NULL也会被作为一个分组表示出来,所以这里我们就不能仅仅通过NULL来判断是不是小计记录了。下面的例子展示了这里说得到的情况。还是我们前面提到的水果例子,现在我们在每种商品后面增加一个“折扣列”(Discount),用于显示对应商品的折扣,这个数值是可空的,也就是可以通过NULL来表示没有对应的折扣信息。数据集如下所示:
FruitName | ProductPlace | Price | Discount |
Apple | China | $1.1 | 0.8 |
Apple | Japan | $2.1 | 0.9 |
Apple | USA | $2.5 | 1.0 |
Orange | China | $0.8 | NULL |
Banana | China | $3.1 | NULL |
Peach | USA | $3.0 | NULL |
现在我们要统计“各种折扣对应有多少种商品,并总计商品的总数。”,那么我们可以通过如下的SQL语句来完成:
SELECTCOUNT(*)ASProductCount,Discount
FROMT_TEST_FRUITINFO
GROUPBYDiscountWITHROLLUP
好了,运行一下,你会发现数据都正常出来了,按照如上的数据集,结果如下所示:
ProductCount | Discount |
3 | NULL |
1 | 0.8 |
1 | 0.9 |
1 | 1.0 |
6 | NULL |
好了,各种折扣的商品数量都出来了,但是在显示“没有折扣商品”和“商品小计”的时候判断上确存在问题,因为存在两条Discount为Null的记录。是哪一条呢?通过分析数据我们知道第一条数据(3, Null)应该对应没有折扣商品的数量,而(6,Null)应该对应所有商品的数量。需要判断这两个具有不同意义的Null就需要引入一个聚合函数Grouping。现在我们把语句修改一下,在返回值中使用Grouping函数增加一列返回值,SQL语句如下:
SELECTCOUNT(*)ASProductCount,Discount,GROUPING(Discount)ASExpr1
FROMT_TEST_FRUITINFO
GROUPBYDiscountWITHROLLUP
这个时候,我们再看看运行的结果:
ProductCount | Discount | Expr1 |
3 | NULL | 0 |
1 | 0.8 | 0 |
1 | 0.9 | 0 |
1 | 1.0 | 0 |
6 | NULL | 1 |
对于根据指定字段Grouping中包含的字段进行小计的记录,这里会标记为1,我们就可以通过这个标记值将小计记录从判断那些由于ROLLUP或者CUBE关键字产生的行。Grouping(column_name)可以带一个参数,Grouping就会去判断对应的字段值的NULL是否是由ROLLUP或者CUBE产生的特殊NULL值,如果是那么就在由Grouping聚合函数产生的新列中将值设置为1。注意Grouping只会检查Column_name对应的NULL来决定是否将值设置为1,而不是完全由此列是否是由ROLLUP或者CUBE关键字自动添加来决定的。
2.2Group By 和 Having, Where ,Order by语句的执行顺序:
最后要说明一下的Group By, Having, Where, Order by几个语句的执行顺序。一个SQL语句往往会产生多个临时视图,那么这些关键字的执行顺序就非常重要了,因为你必须了解这个关键字是在对应视图形成前的字段进行操作还是对形成的临时视图进行操作,这个问题在使用了别名的视图尤其重要。以上列举的关键字是按照如下顺序进行执行的:Where, Group By, Having, Order by。首先where将最原始记录中不满足条件的记录删除(所以应该在where语句中尽量的将不符合条件的记录筛选掉,这样可以减少分组的次数),然后通过Group By关键字后面指定的分组条件将筛选得到的视图进行分组,接着系统根据Having关键字后面指定的筛选条件,将分组视图后不满足条件的记录筛选掉,然后按照Order By语句对视图进行排序,这样最终的结果就产生了。在这四个关键字中,只有在Order By语句中才可以使用最终视图的列名,如:
SELECTFruitName,ProductPlace,Price,IDASIDE,Discount
FROMT_TEST_FRUITINFO
WHERE(ProductPlace=N'china')
ORDERBYIDE
这里只有在ORDER BY语句中才可以使用IDE,其他条件语句中如果需要引用列名则只能使用ID,而不能使用IDE。
二 : Oracle行转列、列转行的Sql语句总结
多行转字符串
这个比较简单,用||或concat函数可以实现select concat(id,username) str from app_userselect id||username str from app_user
字符串转多列(www.61k.com)
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式字符串转多行
使用union all函数等方式wm_concat函数
首先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行,接下来上例子,看看这个神奇的函数如何应用准备测试数据
create table test(id number,name varchar2(20));insert into test values(1,'a');insert into test values(1,'b');insert into test values(1,'c');insert into test values(2,'d');insert into test values(2,'e');
效果1 : 行转列 ,默认逗号隔开
select wm_concat(name) name from test;

效果2: 把结果里的逗号替换成"|"
select replace(wm_concat(name),',','|') from test;
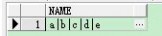
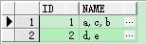
效果3: 按ID分组合并name
select id,wm_concat(name) name from test group by id;
-------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )select id, max(decode(rn, 1, name, null)) || max(decode(rn, 2, ',' || name, null)) || max(decode(rn, 3, ',' || name, null)) str from (select id,name,row_number() over(partition by id order by name) as rn from test) t group by id order by 1; -------- 适用范围:8i,9i,10g及以后版本 ( ROW_NUMBER + LEAD )select id, str from (select id,row_number() over(partition by id order by name) as rn,name || lead(',' || name, 1) over(partition by id order by name) || lead(',' || name, 2) over(partition by id order by name) || lead(',' || name, 3) over(partition by id order by name) as str from test) where rn = 1 order by 1; -------- 适用范围:10g及以后版本 ( MODEL )select id, substr(str, 2) str from test model return updated rows partition by(id) dimension by(row_number() over(partition by id order by name) as rn) measures (cast(name as varchar2(20)) as str) rules upsert iterate(3) until(presentv(str[iteration_number+2],1,0)=0) (str[0] = str[0] || ',' || str[iteration_number+1]) order by 1; -------- 适用范围:8i,9i,10g及以后版本 ( MAX + DECODE )select t.id id,max(substr(sys_connect_by_path(t.name,','),2)) str from (select id, name, row_number() over(partition by id order by name) rn from test) t start with rn = 1 connect by rn = prior rn + 1 and id = prior id group by t.id;</span>
懒人扩展用法:
案例:我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 当然有了,看我如果应用wm_concat来让这个需求变简单,假设我的APP_USER表中有(id,username,password,age)4个字段。查询结果如下/** 这里的表名默认区分大小写 */ select 'create or replace view as select '|| wm_concat(column_name) || ' from APP_USER' sqlStr from user_tab_columns where table_name='APP_USER';

利用系统表方式查询
select * from user_tab_columns

Oracle 11g 行列互换 pivot 和 unpivot 说明
在Oracle 11g中,Oracle 又增加了2个查询:pivot(行转列) 和unpivot(列转行)
参考:
google 一下,网上有一篇比较详细的文档:http://www.oracle-developer.net/display.php?id=506
pivot 列转行
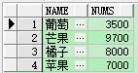
测试数据 (id,类型名称,销售数量),案例:根据水果的类型查询出一条数据显示出每种类型的销售数量。create table demo(id int,name varchar(20),nums int); ---- 创建表insert into demo values(1, '苹果', 1000);insert into demo values(2, '苹果', 2000);insert into demo values(3, '苹果', 4000);insert into demo values(4, '橘子', 5000);insert into demo values(5, '橘子', 3000);insert into demo values(6, '葡萄', 3500);insert into demo values(7, '芒果', 4200);insert into demo values(8, '芒果', 5500);扩展:oracle 行转列 列转行 / 行转列 列转行 / mysql 行转列 列转行

分组查询 (当然这是不符合查询一条数据的要求的)
select name, sum(nums) nums from demo group by name
行转列查询
select * from (select name, nums from demo) pivot (sum(nums) for name in ('苹果' 苹果, '橘子', '葡萄', '芒果'));

注意: pivot(聚合函数 for 列名 in(类型)) ,其中 in(‘’) 中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers
当然也可以不使用pivot函数,等同于下列语句,只是代码比较长,容易理解
select * from (select sum(nums) 苹果 from demo where name='苹果'),(select sum(nums) 橘子 from demo where name='橘子'), (select sum(nums) 葡萄 from demo where name='葡萄'),(select sum(nums) 芒果 from demo where name='芒果');
unpivot 行转列
顾名思义就是将多列转换成1列中去创建表和数据
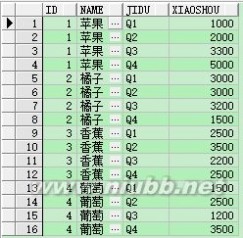
create table Fruit(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int);insert into Fruit values(1,'苹果',1000,2000,3300,5000);insert into Fruit values(2,'橘子',3000,3000,3200,1500);insert into Fruit values(3,'香蕉',2500,3500,2200,2500);insert into Fruit values(4,'葡萄',1500,2500,1200,3500);select * from Fruit

列转行查询
select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )注意: unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量
同样不使用unpivot也可以实现同样的效果,只是sql语句会很长,而且执行速度效率也没有前者高
select id, name ,'Q1' jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit funionselect id, name ,'Q2' jidu, (select q2 from fruit where id=f.id) xiaoshou from Fruit funionselect id, name ,'Q3' jidu, (select q3 from fruit where id=f.id) xiaoshou from Fruit funionselect id, name ,'Q4' jidu, (select q4 from fruit where id=f.id) xiaoshou from Fruit f
XML类型
上述pivot列转行示例中,你已经知道了需要查询的类型有哪些,用in()的方式包含,假设如果您不知道都有哪些值,您怎么构建查询呢?pivot操作中的另一个子句 XML 可用于解决此问题。该子句允许您以 XML 格式创建执行了 pivot 操作的输出,在此输出中,您可以指定一个特殊的子句 ANY 而非文字值
示例如下:
select * from ( select name, nums as "Purchase Frequency" from demo t) pivot xml ( sum(nums) for name in (any))


结论
Pivot为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用unpivot操作转换任何交叉表报表,以常规关系表的形式对其进行存储。Pivot可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域。
扩展:oracle 行转列 列转行 / 行转列 列转行 / mysql 行转列 列转行
三 : (转载)总结一下SQL语句中引号(')、quotedstr()、('')、f
| 总结一下SQL语句中引号(')、quotedstr()、('')、format()在SQL语句中的用法 |
总结一下SQL语句中引号(')、quotedstr()、('')、format()在SQL语句中的用法以 |
扩展:sql语句单引号 / sql语句中单引号 / sql语句引号
四 : 名言名句分类汇集
爱国篇
捐驱赴国难,视死忽如归.
利于国者爱之,害于国者恶之.
天下兴亡,匹夫有责. 顾炎武
祖国如有难,汝应作前锋. 陈毅
男儿七尺身躯,愿为祖国捐. 陈辉
一寸丹心图报国,两行清泪为思亲.
王师北定中原日,家祭无忘告乃翁. 陆游
祖国疆土,当以死守,不可以尺寸与人.
先天下之忧而忧;后天下之乐而乐. 范仲淹
人生自古谁无死,留取丹心照汗青. 文天祥
勤俭篇
贫而无谄,富而无骄. 子贡
静以修身,俭以养得. 诸葛亮
治家以勤俭为本. 明 冯梦龙
勤为无价之宝,慎是护身之符.
人生在勤,勤则不匮. 左传
勤能补拙,俭以养廉. 清 金缨
居安思危,解奢以俭. 唐 魏征
百行业为先,万恶懒为首. 清 梁启超
历览前贤国与家,成由勤俭破由奢. 李商隐
每一食,便念稼穑之艰难,每一衣,则思纺织之辛苦.
食可饱而不必珍,衣可暖而不必华,居可安而不必丽.
美德篇
不以穷变节,不以贱易志.
投我以桃,报之以李. 诗经
君子喻与义,小人喻与利. 论语
生当作人杰,死亦为鬼难. 李清照
君子成人之美,不成人之恶. 论语
出污泥而不染,濯清涟而不妖. 周敦颐
横眉冷对千夫指,俯首甘为孺子牛. 鲁迅
粉身碎骨浑不怕,要留清白在人间. 于谦
春蚕到死丝方尽,蜡炬成灰泪始干. 李商隐
勿以恶小而为之,勿以善小而不为.
谦虚篇
满招损,谦受益.
大勇若怯,大智若愚. 苏轼
不满足是向上的车轮. 鲁迅
虚心万事能成,自满十事九空.
知不足者好学,耻下问者自满.
人不可有傲气,但不可无傲骨. 徐悲鸿
劳动篇
人生在勤,不索何获 张衡
临渊羡鱼不如退而结网. 班固
劳动是一切知识的源泉. 陶铸
应该记住,我们的事业,需要的是手,而不是嘴. 童第周
锄禾日当午,汗滴禾下土.谁知盘中餐,粒粒皆辛苦. 李绅
立志做人篇
百学须先立志. 朱熹
言必行,行必果. 论语
人老心未老,人穷志未穷.
有志者事竟成. 后汉书
大丈夫宁可玉碎,不能瓦全.
有志不在年高,无志空活百岁.
燕雀安知鸿鹄之志哉! 《史记》
人无远虑,必有近忧. 《论语》
良药苦口利于病,忠言逆耳利于行.
得道者多助,失道者寡肋. 《孟子》
虽长不满七尺,而心雄万丈. 李白
心随朗月高,志与秋霜洁. 李世民
丈夫为志,穷当益壮. 马援
三军可夺帅也,匹夫不可夺志也. 孔子
志不强者智不达,言不信者行不果. 墨子
落红不是无情物,化作春泥更护花. 龚自珍
富贵不能淫,贫贱不能移,威武不能屈. 孟子
老骥伏枥,志在千里,烈士暮年,壮志不已. 曹操
珍惜时间篇
春宵一刻值千金.苏轼
少壮不努力,老大徒伤悲.
盛年不重来,一日难再晨.
吾生也有涯,而知也无涯. 庄周
勿谓寸阴短,既过难再获.
策马前途须努力,莫学龙钟虚叹息.
我生待明日,万事成蹉跎. 钱鹤滩
弃我去者,昨日之日不可留. 李白
莫等闲,白了少年头,空悲切. 岳飞
合理安排时间,就等于节约时间. 培根
少年易老学难成,一寸光阴不可轻 朱熹
黑发不知勤学早,白首方悔读书迟. 颜真卿
勿谓今日不学有来日,勿谓今年不学有来年.
做学问,苦读,学习篇
笨鸟先飞早入林.
读书百遍,其义自见.
为学患无疑,疑则进也.
学如逆水行舟,不进则退.
只要功夫深,铁杵磨成针.
善学者,假人之长以补其短.
它山之石,可以攻玉. 《诗经》
千里之行,始于足下. 《老子》
学而不厌,诲人不倦. 《论语》
三人行,必有我师焉. 《论语》
读书破万卷,下笔如有神. 杜甫
知之为知之,不知为不知是知也.
温故而知新,可以为师矣. 《论语》
世事洞明皆学问,人情练达既文章.
书不记,熟读可记;义不精,细思可精.
学而不思则罔,思而不学则殆. 《论语》
纸上得来终觉浅,绝知此事要躬行. 陆游
问渠哪得清如许,为有源头活水来. 朱熹
业精于勤荒于嬉,行成于思毁于随. 韩愈
勤能补拙是良训,一分辛劳一分才. 华罗庚
玉不琢,不成器;人不学,不知道. 《礼记》
合作篇
人心齐,泰山移.
水涨船高,柴多火旺.
知己知彼,将心比心.
独脚难行,孤掌难鸣.
三个臭皮匠,赛过诸葛亮.
远水难救近火,远亲不如近邻.
一个篱笆三个桩,一个好汉三个帮.
一花独放不是春,万紫千红春满园.
亲情,友谊篇
近朱者赤,近墨者黑.
四海皆兄弟,谁为行路人.
路遥知马力,日久见人心.
海内存知己,天涯若比邻. 王勃
但愿人长久,千里共婵娟. 苏轼
君子之交淡如水,小人之交酒肉亲.
谚语宝典
求神不如求人 ,拍马屁,没志气.
莲花开在污泥中, 人才出在贫寒家.
好花不浇不盛开, 小树不修不成才.
严是爱,松是害, 不管不教要变坏.
瓜好吃不在大小, 人健康不在胖瘦.
牛大压不死虱子.
邻居好,赛金宝.
笑一笑,十年少.
小不忍则乱大谋.
挂羊头,卖狗肉.
老虎吃人不吐骨.
一钱难倒英雄汉.
酒香不怕巷子深.
一步走错百步歪.
聪明反被聪明误.
浪子回头金不换.
黄金有价人无价.
若要好,大让小.
绣花枕头稻草蕊.
创业容易守业难.
狗记路,猫记家.
不是冤家不聚头.
有钱不买来年货.
身在福中不知福.
开好花,结好果.
牵一发而动全身.
一石激起千层浪.
红花还得绿叶扶.
打肿脸儿充胖子.
站得高,看得远.
磨刀不误砍柴工.
船到江心补漏迟.
一寸山河一寸金.
一泡鸡屎坏缸酱.
瘦死的骆驼比马大.
小泥鳅掀不起大浪.
癞蛤蟆想吃天鹅肉.
有钱的王八大三辈.
好虎架不住一群狼.
三月三,鲈鱼上岸滩.
麻雀虽小,五胀俱全.
差之豪厘,谬以千里.
开得早,不如来得巧.
人老病多,树老根多.
书要精读,田要细管.
一份耕耘,一份收获.
人过留名,雁过留声.
一日为师,终身为父.
一人得道,鸡犬升天.
五 : SQL基础语句总结
写在前面:本节主要讲述一些基本的,常用的SQL语句,而非数据库方面的基本知识。数据库方面的知识留待以后再讲,现在就我们平常常用的一些SQL语句展开论述。
本节会涉及到SQL的基本句法,SQL的执行顺序,SQL之间的组合,动态SQL语句四个方面。这四个方面之间没有前后顺序之分,是相辅相成,其内在还是有很多联系的。
一. 四种基本的SQL语句
1. 查询
select * from table
2. 更新
update table set field=value
3. 插入
insert [into] table (field) values(value)
4. 删除
delete [from] table
二.语句的执行顺序
1.语法分析
分析语句中语法是否符合规范,衡量语句中各表达式的意义。
2.语义分析
检查语句中涉及的所有数据库对象是否存在,且用户有相应的权限。
3.选择优化器
不同的数据库有不同的算法(这个涉及到数据结构),数据库会根据自己的理解(数据库本身)为 SQL语句选择不同的优化器,不同的优化器会选择不同的“执行计划”
4.运行“执行计划”
根据“执行计划”执行SQL语句。
以上所述是数据执行时的大体路线。
5.select 语句的执行顺序
借用ItZik Ben-Gan、Lubor Kollar、Dejan Sarka所著的《Sql Server 2005 技术内幕:T-SQL查询》的一段话足以说明:
(8) select (9) distinct (11) <top_specification > <select_list>
(1)from<lef t_table>
(3) <join_type> join <right_table>
(2) on <join _condition>
(4) where <where_condition>
(5)group by <group_by_list>
(6) with {cube|rollup}
(7)having(having_condition)
(10) order by <order_by_condition>
从这个顺序可以看出,所有的查询语句都是从from开始执行的。在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的基础。
第一步:from
首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表vt1 .
第二步:on
接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2 .
第三步:join
如果是outer join 那么这一步就将添加外部行,left outer jion 就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3.
第四步:多表
如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3.
第五步:where
应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4,在这有个比较重要的细节不得不说一下,对于包含outer join子句的查询,就有一个让人感到困惑的问题,到底在on筛选器还是用where筛选器指定逻辑表达式呢?on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的。
第六步:group by
分组,生成虚拟表 vt4
第七步:having
对vt4应用having筛选器,生成虚拟表 vt5
第八步:select
处理select 列表,生成虚拟表vt6
第九步:distinct
将vt6 中重复的行去掉,生成虚拟表vt7
第十步:order by
将vt7中的行按order by 子句中的列列表排序,生成一个游标vc8
第十一步:top
从vc8的开始处选择指定数量或比例的行,生成虚拟表vt9,并返回给调用者
三. SQL语句扩展
1.select
1.1 选择性插入语句
1.1.1 Insert into table1 (field1 ) Select field2 from table2
要求table1必须存在。
1.1.2 select field1 into table1 from table2
要求table1不存在,在运行时会自动创建表名为table1,字段名为field1的一个表。
1.2打开其它数据源
/* OracleSvr为链接服务器名 ,本示例假定已经创建了一个名为 ORCLDB 的 Oracle 数据库别名。*/
EXEC sp_addlinkedserver 'OracleSvr', --链接服务器名OracleSvr,sysname类型
'MSDAORA', --provider_name数据源提供程序,此处为oracle
'ORCLDB' --数据源名称
GO
Select * from OPENQUERY(OracleSvr, 'SELECT name, id FROM joe.titles')
如果有多个sql server实例:
SELECT *FROM [servernameinstancename.]pubs.dbo.authors.
注意:一个对象的完整名称包括四个标识符:服务器名称、数据库名称、所有者名称和对象名称。其格式如下:
[ [ [ server. ] [ database ] .] [ owner_name ] .] object_name
中间的名称可以省略,但是.不可以省略。如:server…object_name
2.update
2.1多表更新
Update table1 set table1.field 1=table2.field2 from
table1,table2 /*猜测下连接方式全联接 FULL [OUTER] JOIN */
where table1.field3= table2 .filed3
知识:SQL Server的update语句中from后可跟多个表,Oracle则不支持该用法
Oracle 中:Update table1 set table1.field1=
(select table2.field2 from table2 where .field3= table2 .filed3)
3.insert
3.1 插入语句的规范问题
在sql server 2000,sql server 2005中
标准语句:insert into table(field) values (value)
提示:在access中不正确,原因sql语句不规范,因此在书写sql语句的过程中一定要按正规的语法来写。
4.delete
4.1标准删除
标准语句:delete from table where condition
提示:同insert
4.2其它删除
4.2.1 truncate
语法:truncate table table_name
删除表中所有行,不记录单个行删除操作,不记录日志,,所有速度比Delete快。
4.2.2 drop
语句: Drop table table_name
删除表及相关,有fk约束的不能删,先去年fk;系统表不能使用。
5.order by
功能:排序
技巧:order by newid() 随机排序
四. 动态SQL语句
4.1基本原则
4.1.1预编译问题
在EXECUTE执行之前,数据库不会编译 EXECUTE 语句内的语句,动态SQL语句就是放到存储过程中,它也不会预先编译。
4.1.2什么时候使用动态SQL语句
字段名,表名,数据库名作为变量时,必须用动态SQl语句
4.2.exec[ute]
4.2.1语法
exec (‘select * from table_name where name=’’’+@name+’’’’) --括号不能少
4.2.2传递参数
--假设存储过程test_sp中需要一个参数:类型nvarchar(50) 名称 @parm
Declare @parms nvarchar(50)
Set @parms=’测试变量’
Exec test_sp [@parm=]@parms –方括号内的可以省略
如果是批处理中的第一句,则可以省略Exec
4.2.3输出参数
declare @num int, @field int,
@sqls nvarchar(4000)
Set @field=1
set @sqls='select @a=count(*) from table_name where field=@field'
exec sp_executesql @sqls,N'@a int output,@field int',@num output ,@field
select @num
4.3.sp_executesql
语法:exec[ute] sp_executesql N’select * from table_name where field=@field’,N’@field int’,@field=1
使用sp_exexutesql比使用exec更有效率.
结束语:以上是SQL中常用的语句,及其执行时的顺序。不管是SQL Server系列,mysql,access,Oracle系列这些都基本相同。如果要在数据库方面做高深的研究,则多看一下其自带的帮助,多练习,多看一些数据库原理方面的书。(来源:风雨人生)
本文标题:sql分类汇总语句-SQL语句:Group By总结61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1