一 : Python学习2
python中有三种内部数据结构:列表、元组、字典(using_list.py,using_tuple.py, using——dict.py)
list:列表。[www.61k.com)shoplist = ['apple', 'mango', 'carrot', 'banana']
方法,尾部添加shoplist.append('rice'),排序shoplist.sort(),删除del shoplist[i]
1 # Filename: using_list.py
2 # This is my shopping list
3 shoplist = ['apple', 'mango', 'carrot', 'banana']
4 print 'i have', len(shoplist), 'items to choose'
5 print 'these items are:',
6 for item in shoplist:
7 print item,
8 print '\nI also have to buy rice'
9 shoplist.append('rice')
10 print 'my shoplist now is', shoplist
11 print 'i will sort my list now'
12 shoplist.sort()
13 print 'Sorted shopping list is', shoplist
14 print 'The first item i will buy is', shoplist[0]
15 olditem = shoplist[0]
16 del shoplist[0]
17 print 'i bought the', olditem
18 print 'My shopping list is now', shoplist
测试结果:
i have 4 items to choose
these items are: apple mango carrot banana
I also have to buy rice
my shoplist now is ['apple', 'mango', 'carrot', 'banana', 'rice']
i will sort my list now
Sorted shopping list is ['apple', 'banana', 'carrot', 'mango', 'rice']
The first item i will buy is apple
i bought the apple
My shopping list is now ['banana', 'carrot', 'mango', 'rice']
tuple:元组。与列表类似,只是不能被修改。
zoo = ('wolf', 'elephant', 'penguin') new_zoo = ('monkey', 'dolphin', zoo)
元组在打印语句中应用:name = 'Mike' age = 22 print '%s is years old ' %(name, age)
1 # Filename: using_tuple.py
2 zoo = ('wolf', 'elephant', 'penguin')
3 print 'number of animals in the zoo is', len(zoo)
4 new_zoo = ('monkey', 'dolphin', zoo)
5 print 'number of animals in the new zoo is', len(new_zoo)
6 print 'all animals in the new zoo are', new_zoo
7 print 'Animals brought from old zoo are', new_zoo[2]
8 print 'last animal brought from old zoo is', new_zoo[2][2]
测试结果:
number of animals in the zoo is 3
number of animals in the new zoo is 3
all animals in the new zoo are ('monkey', 'dolphin', ('wolf', 'elephant', 'penguin'))
Animals brought from old zoo are ('wolf', 'elephant', 'penguin')
last animal brought from old zoo is penguin
dict:字典。由键值对构成,键不可改变,值可修改。 d = {key1 : value1, key2 : value2}
方法:ab.items(),ab.has_key('Guido'),删除del
items()方法返回一个元组的列表
1 # Filename: using_dict.py
2 ab = {'Swaroop' : 'swaroopch@byteofpython.info',
3 'Larry' : 'larry@wall.org',
4 'Matsumoto' : 'matz@ruby-lang.org',
5 'Spammer' : 'spammer@hotmail.com'}
6 print "Swaroop's address is %s" %ab['Swaroop']
7
8 # Adding a key/value pair
9 ab['Guido'] = 'guido@python.org'
10 print '\nThere are %d contacts in the address-book\n' %len(ab)
11 for name, address in ab.items():
12 print 'Contact %s at %s' %(name, address)
13 if 'Guido' in ab: # ab.has_key('Guido')
14 print "\nGuido's address is %s" %ab['Guido']
测试结果:
Swaroop's address is swaroopch@byteofpython.info
There are 5 contacts in the address-book
Contact Swaroop at swaroopch@byteofpython.info
Contact Matsumoto at matz@ruby-lang.org
Contact Larry at larry@wall.org
Contact Spammer at spammer@hotmail.com
Contact Guido at guido@python.org
Guido's address is guido@python.org
序列(seq.py)
元组、列表都是序列。共性:索引操作符、切片操作符
索引可以是负数,此时从尾端开始计数。
切片开始位置在序列切片位置中,结束位置被排除在外
1 # FIlename: seq.py
2 shoplist = ['apple', 'mango', 'carrot', 'banana']
3 # Indexing or Subscriprion operation
4 print 'Item 0 is', shoplist[0]
5 print 'Item 1 is', shoplist[1]
6 print 'Item 2 is', shoplist[2]
7 print 'Item 3 is', shoplist[3]
8 print 'Item -1 is', shoplist[-1]
9 print 'Item -2 is', shoplist[-2]
10
11 # slicing on a list
12 print 'Item 1 to 3 is', shoplist[1:3]
13 print 'Item 2 to end is', shoplist[2:]
14 print 'Item 1 to -1 is', shoplist[1:-1]
15 print 'Item start to end is', shoplist[:]
16
17 # slicing on a string
18 name = 'swaroop'
19 print 'characters 1 to 3 is', name[1:3]
20 print 'characters 2 to end is', name[2:]
21 print 'characters 1 to -1 is', name[1:-1]
22 print 'characters start to end is', name[:]
测试结果:
Item 0 is apple
Item 1 is mango
Item 2 is carrot
Item 3 is banana
Item -1 is banana
Item -2 is carrot扩展:学习python2还是3 / python学习手册 / python学习
Item 1 to 3 is ['mango', 'carrot']
Item 2 to end is ['carrot', 'banana']
Item 1 to -1 is ['mango', 'carrot']
Item start to end is ['apple', 'mango', 'carrot', 'banana']
characters 1 to 3 is wa
characters 2 to end is aroop
characters 1 to -1 is waroo
characters start to end is swaroop
参考(类似c#引用)(reference.py)
mylist = shoplist, 引用
mylist = shoplist[:], 完全复制
1 # Filename: reference.py
2 print 'Simple Assignment'
3 shoplist = ['apple', 'mango', 'carrot', 'banana']
4 # mylist is just another name pointed to the same object!
5 mylist = shoplist
6 del shoplist[0]
7 print 'shoplist is', shoplist
8 print 'mylist is', mylist
9 # make a copy by doing a full slice
10 mylist = shoplist[:]
11 del mylist[0]
12 print 'shoplist is', shoplist
13 print 'mylst is', mylist
测试结果:
Simple Assignment
shoplist is ['mango', 'carrot', 'banana']
mylist is ['mango', 'carrot', 'banana']
shoplist is ['mango', 'carrot', 'banana']
mylst is ['carrot', 'banana']
字符串str类的方法(str_methods.py)
startwith():测试字符串是否以指定字符串开始
in:测试字符串是否含有指定字符串
find():返回指定字符串在字符串中的位置,没有则返回-1
join():可作为序列的连接字符串
1 # Filename: str_methods.py
2 name = 'Swaroop'
3 if name.startswith('Swa'):
4 print 'Yes, the string strats with "Swa"'
5 if 'a' in name:
6 print 'Yes, it contains the string "a"'
7 if name.find('war') != -1:
8 print 'Yes, it contains the string "war"'
9 delimiter = '_*_'
10 mylist = ['Brazil', 'Russia', 'India', 'China']
11 print delimiter.join(mylist)
测试结果:
Yes, the string strats with "Swa"
Yes, it contains the string "a"
Yes, it contains the string "war"
Brazil_*_Russia_*_India_*_China
扩展:学习python2还是3 / python学习手册 / python学习
二 : Python自然语言处理学习笔记(61):7.2 分块
7.2 Chunking 分块
The basic technique we will use for entity detection ischunking, which segments and labels multi-token sequences as illustrated inFigure 7.2. The smaller boxes show the word-level tokenization and part-of-speech tagging, while the large boxes show higher-level chunking. Each of these larger boxes is called achunk. Like tokenization, which omits whitespace, chunking usually selects a subset of the tokens(标记的子集). Also like tokenization, the pieces produced by a chunker do not overlap in the source text.
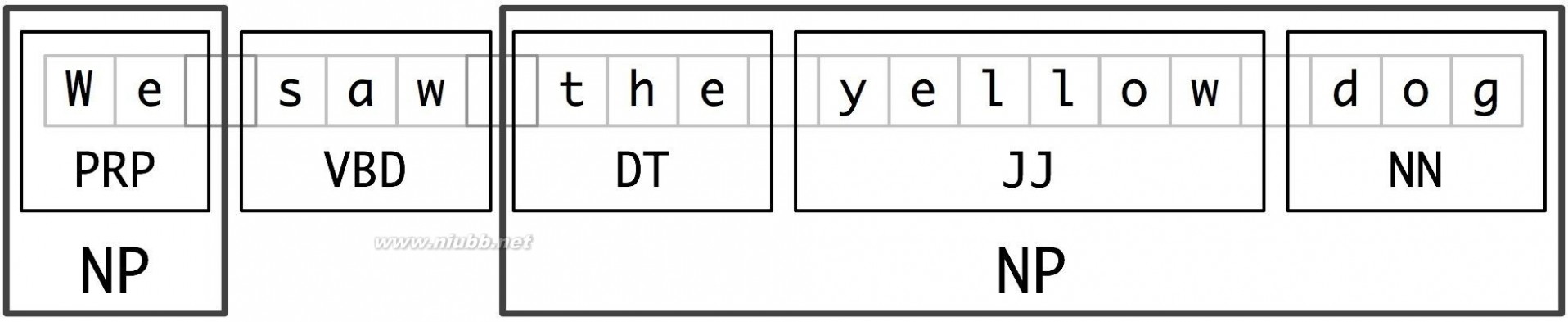
Figure 7.2: Segmentation and Labeling at both the Token and Chunk Levels
In this section, we will explore chunking in some depth, beginning with the definition and representation of chunks. We will see regular expression and n-gram approaches to chunking, and will develop and evaluate chunkers using the CoNLL-2000 chunking corpus. We will then return inSection (5)andSection 7.6to the tasks of named entity recognition and relation extraction.
Noun Phrase Chunking 名词短语分块
We will begin by considering the task ofnoun phrase chunking, orNP-chunking, where we search for chunks corresponding to individual noun phrases. For example, here is some Wall Street Journal text with NP-chunks marked using brackets:
(2) | [ The/DT market/NN ] for/IN [ system-management/NN software/NN ] for/IN [ Digital/NNP ] [ 's/POS hardware/NN ] is/VBZ fragmented/JJ enough/RB that/IN [ a/DT giant/NN ] such/JJ as/IN [ Computer/NNP Associates/NNPS ] should/MD do/VB well/RB there/RB ./. |
As we can see, NP-chunks are often smaller pieces than complete noun phrases. For example, the market for system-management software for Digital's hardware is a single noun phrase (containing two nested noun phrases), but it is captured in NP-chunks by the simpler chunk the market. One of the motivations for this difference is that NP-chunks are defined so as not to contain other NP-chunks. Consequently, any prepositional phrases(介词短语) or subordinate clauses(从句) that modify a nominal(名词性词) will not be included in the corresponding NP-chunk, since they almost certainly contain further noun phrases.
One of the most useful sources of information for NP-chunking is part-of-speech tags. This is one of the motivations for performing part-of-speech tagging in our information extraction system. We demonstrate this approach using an example sentence that has been part-of-speech tagged inExample 7.3. In order to create an NP-chunker, we will first define achunk grammar(分块语法), consisting of rules that indicate how sentences should be chunked. In this case, we will define a simple grammar with a single regular-expression rule. This rule says that an NP chunk should be formed whenever the chunker finds an optional determiner (DT) followed by any number of adjectives (JJ) and then a noun (NN). Using this grammar, we create a chunk parser, and test it on our example sentence. The result is a tree, which we can either print, or display graphically.
| ||
Example 7.3 (code_chunkex.py): |

Figure 7.3: Example of a Simple Regular Expression Based NP Chunker.
Tag Patterns标签
The rules that make up a chunk grammar usetag patternsto describe sequences of tagged words. A tag pattern is a sequence of part-of-speech tags delimited using angle brackets, e.g. <DT>?<JJ>*<NN>. Tag patterns are similar to regular expression patterns (Section 3.4). Now, consider the following noun phrases from the Wall Street Journal:
扩展:python自然语言处理 / python 自然语言 / python自然语言处理包
another/DT sharp/JJ dive/NN
trade/NN figures/NNS
any/DT new/JJ policy/NN measures/NNS
earlier/JJR stages/NNS
Panamanian/JJ dictator/NN Manuel/NNP Noriega/NNP
We can match these noun phrases using a slight refinement of the first tag pattern above, i.e. <DT>?<JJ.*>*<NN.*>+. This will chunk any sequence of tokens beginning with an optional determiner, followed by zero or more adjectives of any type (including relative adjectives like earlier/JJR), followed by one or more nouns of any type. However, it is easy to find many more complicated examples which this rule will not cover:
his/PRP$ Mansion/NNP House/NNP speech/NN
the/DT price/NN cutting/VBG
3/CD %/NN to/TO 4/CD %/NN
more/JJR than/IN 10/CD %/NN
the/DT fastest/JJS developing/VBG trends/NNS
's/POS skill/NN
Note
Your Turn:Try to come up with tag patterns to cover these cases. Test them using the graphical interface nltk.app.chunkparser(). Continue to refine your tag patterns with the help of the feedback given by this tool.
Chunking with Regular Expressions用正则表达式分块
To find the chunk structure for a given sentence, the RegexpParser chunker begins with a flat structure in which no tokens are chunked. The chunking rules are applied in turn, successively updating the chunk structure. Once all of the rules have been invoked, the resulting chunk structure is returned.
Example 7.4shows a simple chunk grammar consisting of two rules. The first rule matches an optional determiner or possessive pronoun(所有格代名词), zero or more adjectives, then a noun. The second rule matches one or more proper nouns(专有名词). We also define an example sentence to be chunked, and run the chunker on this input.
| ||
| ||
Example 7.4 (code_chunker1.py):Figure 7.4: Simple Noun Phrase Chunker |
Note
The $ symbol is a special character in regular expressions, and must be backslash escaped in order to match the tag PP$. 在正则表达式中$是一个特殊符号,必须使用转义符\来匹配PP$标志。(www.61k.com]
If a tag pattern matches at overlapping locations, the leftmost match takes precedence(最左边匹配拥有优先). For example, if we apply a rule that matches two consecutive nouns to a text containing three consecutive nouns, then only the first two nouns will be chunked:
|
Once we have created the chunk for money market, we have removed the context that would have permitted fund to be included in a chunk. This issue would have been avoided with a more permissive(宽容的) chunk rule, e.g. NP: {<NN>+}.
Note
We have added a comment to each of our chunk rules. These are optional; when they are present, the chunker prints these comments as part of its tracing output.
扩展:python自然语言处理 / python 自然语言 / python自然语言处理包
Exploring Text Corpora探索文本语料库InSection 5.2we saw how we could interrogate(询问) a tagged corpus to extract phrases matching a particular sequence of part-of-speech tags. We can do the same work more easily with a chunker, as follows:
|
Note
Your Turn:Encapsulate(封装) the above example inside a function find_chunks() that takes a chunk string like "CHUNK: {<V.*> <TO> <V.*>}" as an argument. Use it to search the corpus for several other patterns, such as four or more nouns in a row, e.g. "NOUNS: {<N.*>{4,}}"
Chinking分块
Sometimes it is easier to define what we want to exclude from a chunk. We can define achinkto be a sequence of tokens that is not included in a chunk. In the following example, barked/VBD at/IN is a chink:
[ the/DT little/JJ yellow/JJ dog/NN ] barked/VBD at/IN [ the/DT cat/NN ]
Chinking is the process of removing a sequence of tokens from a chunk. If the matching sequence of tokens spans(贯穿) an entire chunk, then the whole chunk is removed; if the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where there was only one before. If the sequence is at the periphery(外围) of the chunk, these tokens are removed, and a smaller chunk remains. These three possibilities are illustrated inTable 7.3.
` ` | Entire chunk | Middle of a chunk | End of a chunk |
Input | [a/DT little/JJ dog/NN] | [a/DT little/JJ dog/NN] | [a/DT little/JJ dog/NN] |
Operation | Chink "DT JJ NN" | Chink "JJ" | Chink "NN" |
Pattern | }DT JJ NN{ | }JJ{ | }NN{ |
Output | a/DT little/JJ dog/NN | [a/DT] little/JJ [dog/NN] | [a/DT little/JJ] dog/NN |
InExample 7.5, we put the entire sentence into a single chunk, then excise the chinks.
| ||
| ||
Example 7.5 (code_chinker.py):Figure 7.5: Simple Chinker 扩展:python自然语言处理 / python 自然语言 / python自然语言处理包 |
Representing Chunks: Tags vs Trees 表示块:标签与树
As befits their intermediate(中间的) status between tagging and parsing (Chapter 8), chunk structures can be represented using either tags or trees. The most widespread file representation usesIOB tags(IOB标记). In this scheme, each token is tagged with one of three special chunk tags, I (inside), O (outside), or B (begin). A token is tagged as B if it marks the beginning of a chunk. Subsequent tokens within the chunk are tagged I. All other tokens are tagged O. The B and I tags are suffixed with the chunk type, e.g. B-NP, I-NP. Of course, it is not necessary to specify a chunk type for tokens that appear outside a chunk, so these are just labeled O. An example of this scheme is shown inFigure 7.6.

Figure 7.6: Tag Representation of Chunk Structures
IOB tags have become the standard way to represent chunk structures in files, and we will also be using this format. Here is how the information inFigure 7.6would appear in a file:
We PRP B-NP
saw VBD O
the DT B-NP
little JJ I-NP
yellow JJ I-NP
dog NN I-NP
In this representation there is one token per line, each with its part-of-speech tag and chunk tag. This format permits us to represent more than one chunk type, so long as the chunks do not overlap. As we saw earlier, chunk structures can also be represented using trees. These have the benefit that each chunk is a constituent(组成) that can be manipulated directly. An example is shown inFigure 7.7.

Figure 7.7: Tree Representation of Chunk Structures
Note
NLTK uses trees for its internal representation(内部表示)of chunks, but provides methods for reading and writing such trees to the IOB format.
扩展:python自然语言处理 / python 自然语言 / python自然语言处理包
三 : Python自然语言处理学习笔记(9):2.1 访问文本语料库
Updated 1st 2011.8.6
CHAPTER 2
Accessing Text Corpora and Lexical Resources
访问文本语料库和词汇资源
Practical work in Natural Language Processing typically uses large bodies of linguistic data, orcorpora. The goal of this chapter is to answer the following questions:
1. What are some useful text corpora and lexical resources, and how can we access them with Python?
什么是有用的文本预料可和词汇资源,我们如何通过Python访问它们?
2. Which Python constructs are most helpful for this work?
Python构造的哪个方面对于这一项工作是最有帮助的?
3. How do we avoid repeating ourselves when writing Python code?
在写Python代码的时候,我们如何避免重复?
This chapter continues to present programming concepts by example, in the context of a linguistic processing task. We will wait until later before exploring each Python construct systematically. Don’t worry if you see an example that contains something unfamiliar; simply try it out and see what it does, and—if you’re game(勇敢的)—modify it by substituting(代替) some part of the code with a different text or word. This way you will associate(联系) a task with a programming idiom, and learn the hows and whys later.
2.1 Accessing Text Corpora访问文本语料库
As just mentioned, a text corpus is a large body of text. Many corpora are designed to contain a careful balance of material in one or more genres. We examined some small text collections in Chapter 1, such as the speeches known as the US Presidential Inaugural Addresses. This particular corpus actually contains dozens of individual texts—one per address—but for convenience we glued them end-to-end and treated them as a single text. Chapter 1 also used various predefined texts that we accessed by typing from book import *. However, since we want to be able to work with other texts, this section examines a variety of text corpora. We’ll see how to select individual texts, and how to work with them.
Gutenberg Corpus
NLTK includes a small selection of texts from the Project Gutenberg electronic text archive(古腾堡电子文本存档), which contains some 25,000(现在是36,000了) free electronic books, hosted at http://www.gutenberg.org/. We begin by getting the Python interpreter to load the NLTK package, then ask to see nltk.corpus.gutenberg.fileids(), the file identifiers in this corpus:
>>> import nltk
>>> nltk.corpus.gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt','chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
Let’s pick out the first of these texts—Emma by Jane Austen—and give it a short name, emma, then find out how many words it contains:
>>> emma = nltk.corpus.gutenberg.words('austen-emma.txt')
>>> len(emma)
192427
In Section 1.1, we showed how you could carry out concordancing of a text such as text1 with the command text1.concordance(). However, this assumes that you are using one of the nine texts obtained as a result of doing from nltk.book import *. Now that you have started examining data from nltk.corpus, as in the previous example, you have to employ the following pair of statements to perform concordancing and other tasks from Section 1.1:
>>> emma = nltk.Text(nltk.corpus.gutenberg.words('austen-emma.txt'))
>>> emma.concordance("surprize")
When we defined emma, we invoked the words() function of the gutenberg object in NLTK’s corpus package. But since it is cumbersome(累赘的) to type such long names all the time, Python provides another version of the import statement, as follows:
>>> from nltk.corpus import gutenberg
>>> gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', ...]
>>> emma = gutenberg.words('austen-emma.txt')
Let’s write a short program to display other information about each text, by looping over all the values of fileid(文件标识) corresponding to the gutenberg file identifiers listed earlier and then computing statistics for each text. For a compact output display, we will make sure that the numbers are all integers, using int().
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
>>> for fileid in gutenberg.fileids():
... num_chars = len(gutenberg.raw(fileid)) ①
... num_words = len(gutenberg.words(fileid))
... num_sents = len(gutenberg.sents(fileid))
... num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)]))
... print int(num_chars/num_words), int(num_words/num_sents), int(num_words/num_vocab), fileid
...
4 21 26 austen-emma.txt
4 23 16 austen-persuasion.txt
4 24 22 austen-sense.txt
4 33 79 bible-kjv.txt
4 18 5 blake-poems.txt
4 17 14 bryant-stories.txt
4 17 12 burgess-busterbrown.txt
4 16 12 carroll-alice.txt
4 17 11 chesterton-ball.txt
4 19 11 chesterton-brown.txt
4 16 10 chesterton-thursday.txt
4 18 24 edgeworth-parents.txt
4 24 15 melville-moby_dick.txt
4 52 10 milton-paradise.txt
4 12 8 shakespeare-caesar.txt
4 13 7 shakespeare-hamlet.txt
4 13 6 shakespeare-macbeth.txt
4 35 12 whitman-leaves.txt
This program displays three statistics for each text: average word length平均字长, average sentence length平均句长, and the number of times each vocabulary item appears in the text on average本文中每个词汇平均出现数量 (our lexical diversity score我们的词汇多样性得分). Observe that average word length appears to be a general property of English, since it has a recurrent(周期性的) value of 4. (In fact, the average word length is really 3, not 4, since the num_chars variable counts space characters.) By contrast average sentence length and lexical diversity appear to be characteristics of particular authors.
The previous example also showed how we can access the “raw” text of the book①, not split up into tokens. The raw() function gives us the contents of the file without any linguistic processing(对文件的内容不进行任何语言处理). So, for example, len(gutenberg.raw('blake-poems.txt') tells us how many letters occur in the text, including the spaces between words. The sents() function divides the text up into its sentences, where each sentence is a list of words(把文本分割成句子,每个句子是一个由单词组成的列表):
>>> macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt')
>>> macbeth_sentences
[['[', 'The', 'Tragedie', 'of', 'Macbeth', 'by', 'William', 'Shakespeare', '1603', ']'], ['Actus', 'Primus', '.'], ...]
>>> macbeth_sentences[1037]
['Good', 'night', ',', 'and', 'better', 'health', 'Attend', 'his', 'Maiesty']
>>> longest_len = max([len(s) for s in macbeth_sentences])
>>> [s for s in macbeth_sentences if len(s) == longest_len]
[['Doubtfull', 'it', 'stood', ',', 'As', 'two', 'spent', 'Swimmers', ',', 'that', 'doe', 'cling', 'together', ',', 'And', 'choake', 'their', 'Art', ':', 'The', 'mercilesse', 'Macdonwald', ...], ...]
Most NLTK corpus readers include a variety of access methods apart from words(), raw(), and sents(). Richer linguistic content is available from some corpora, such as part-of-speech tags, dialogue tags, syntactic trees, and so forth; we will see these in later chapters.
Web and Chat Text Web和聊天文本
Although Project Gutenberg contains thousands of books, it represents established literature. It is important to consider less formal language as well. NLTK’s small collection of web text includes content from a Firefox discussion forum, conversations overheard(无意听到的) in New York, the movie script of Pirates of the Carribean(加勒比海盗), personal advertisements, and wine reviews:
>>> from nltk.corpus import webtext
>>> for fileid in webtext.fileids():
... print fileid, webtext.raw(fileid)[:65], '...'
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
There is also a corpus of instant messaging chat sessions, originally collected by the Naval Postgraduate School for research on automatic detection of Internet predators(捕食者).The corpus contains over 10,000 posts(帖子), anonymized by replacing usernames with generic names(通用名) of the form “UserNNN”, and manually edited to remove any other identifying information. The corpus is organized into 15 files, where each file contains several hundred posts collected on a given date, for an age-specific chatroom (teens, 20s, 30s, 40s, plus a generic adults chatroom). The filename contains the date, chat-room, and number of posts; e.g., 10-19-20s_706posts.xml contains 706 posts gathered from the 20s chat room on 10/19/2006.
>>> from nltk.corpus import nps_chat
>>> chatroom = nps_chat.posts('10-19-20s_706posts.xml')
>>> chatroom[123]
['i', 'do', "n't", 'want', 'hot', 'pics', 'of', 'a', 'female', ',','I', 'can', 'look', 'in', 'a', 'mirror','.']
Brown Corpus 布朗语料库
The Brown Corpus was the first million-word electronic corpus of English, created in 1961 at Brown University. This corpus contains text from 500 sources, and the sources have been categorized by genre, such as news, editorial, and so on. Table 2-1 gives an example of each genre (for a complete list, see).
| ID | File | Genre | Description |
|---|---|---|---|
| A16 | ca16 | news | Chicago Tribune: Society Reportage |
| B02 | cb02 | editorial | Christian Science Monitor: Editorials |
| C17 | cc17 | reviews | Time Magazine: Reviews |
| D12 | cd12 | religion | Underwood: Probing the Ethics of Realtors |
| E36 | ce36 | hobbies | Norling: Renting a Car in Europe |
| F25 | cf25 | lore | Boroff: Jewish Teenage Culture |
| G22 | cg22 | belles_lettres | Reiner: Coping with Runaway Technology |
| H15 | ch15 | government | US Office of Civil and Defence Mobilization: The Family Fallout Shelter |
| J17 | cj19 | learned | Mosteller: Probability with Statistical Applications |
| K04 | ck04 | fiction | W.E.B. Du Bois: Worlds of Color |
| L13 | cl13 | mystery | Hitchens: Footsteps in the Night |
| M01 | cm01 | science_fiction | Heinlein: Stranger in a Strange Land |
| N14 | cn15 | adventure | Field: Rattlesnake Ridge |
| P12 | cp12 | romance | Callaghan: A Passion in Rome |
| R06 | cr06 | humor | Thurber: The Future, If Any, of Comedy |
Table 2-1. Example document for each section of the Brown Corpus
We can access the corpus as a list of words or a list of sentences (where each sentence is itself just a list of words). We can optionally specify particular categories or files to read:
>>> from nltk.corpus import brown
>>> brown.categories()
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies',
'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance',
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
The Brown Corpus is a convenient resource for studying systematic differences between genres, a kind of linguistic inquiry(语言学研究) known as stylistics(文体学). Let’s compare genres in their usage of modal verbs. The first step is to produce the counts for a particular genre. Remember to import nltk before doing the following:
>>> from nltk.corpus import brown
>>> news_text = brown.words(categories='news')
>>> fdist = nltk.FreqDist([w.lower() for w in news_text])
>>> modals = ['can', 'could', 'may', 'might', 'must', 'will']
>>> for m in modals:
... print m + ':', fdist[m],
...
can: 94 could: 87 may: 93 might: 38 must: 53 will: 389
 Your Turn: Choose a different section of the Brown Corpus, and adapt the preceding example to count a selection of wh words, such as what, when, where, who and why.
Your Turn: Choose a different section of the Brown Corpus, and adapt the preceding example to count a selection of wh words, such as what, when, where, who and why.
Next, we need to obtain counts for each genre of interest. We’ll use NLTK’s support for conditional frequency distributions. These are presented systematically in Section 2.2, where we also unpick(拆散) the following code line by line. For the moment, you can ignore the details and just concentrate on the output(忽略细节,专注于结果).
>>> cfd = nltk.ConditionalFreqDist(
... (genre, word)
... for genre in brown.categories()
... for word in brown.words(categories=genre))
>>> genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
>>> modals = ['can', 'could', 'may', 'might', 'must', 'will']
>>> cfd.tabulate(conditions=genres, samples=modals)
can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
Observe that the most frequent modal in the news genre is will, while the most frequent modal in the romance genre is could. Would you have predicted this? The idea that word counts might distinguish(区分) genres will be taken up(采纳) again in Chapter 6.
Reuters Corpus 路透社语料库
The Reuters Corpus contains 10,788 news documents totaling 1.3 million words. The documents have been classified into 90 topics, and grouped into two sets, called “training” and “test”(训练和测试); thus, the text with fileid 'test/14826' is a document drawn from the test set. This split(分割) is for training and testing algorithms that automatically detect the topic of a document, as we will see in Chapter 6.
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
>>> from nltk.corpus import reuters
>>> reuters.fileids()
['test/14826', 'test/14828', 'test/14829', 'test/14832', ...]
>>> reuters.categories()
['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa',
'coconut', 'coconut-oil', 'coffee', 'copper', 'copra-cake', 'corn',
'cotton', 'cotton-oil', 'cpi', 'cpu', 'crude', 'dfl', 'dlr', ...]
Unlike the Brown Corpus, categories in the Reuters Corpus overlap with each other(相互覆盖,也就是内容有重复), simply because a news story often covers multiple topics. We can ask for the topics covered by one or more documents, or for the documents included in one or more categories. For convenience, the corpus methods accept a single fileid or a list of fileids.
>>> reuters.categories('training/9865')
['barley', 'corn', 'grain', 'wheat']
>>> reuters.categories(['training/9865', 'training/9880'])
['barley', 'corn', 'grain', 'money-fx', 'wheat']
>>> reuters.fileids('barley')
['test/15618', 'test/15649', 'test/15676', 'test/15728', 'test/15871', ...]
>>> reuters.fileids(['barley', 'corn'])
['test/14832', 'test/14858', 'test/15033', 'test/15043', 'test/15106',
'test/15287', 'test/15341', 'test/15618', 'test/15618', 'test/15648', ...]
Similarly, we can specify the words or sentences we want in terms of(按照) files or categories. The first handful(少数) of words in each of these texts are the titles, which by convention(按照惯例) are stored as uppercase.
>>> reuters.words('training/9865')[:14]
['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', 'BIDS',
'DETAILED', 'French', 'operators', 'have', 'requested', 'licences', 'to', 'export']
>>> reuters.words(['training/9865', 'training/9880'])
['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', ...]
>>> reuters.words(categories='barley')
['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', ...]
>>> reuters.words(categories=['barley', 'corn'])
['THAI', 'TRADE', 'DEFICIT', 'WIDENS', 'IN', 'FIRST', ...]
Inaugural Address Corpus 就职演说语料库
In Section 1.1, we looked at the Inaugural Address Corpus, but treated it as a single text. The graph in Figure 1-2 used “word offset”(单词位移) as one of the axes; this is the numerical index of the word in the corpus, counting from the first word of the first address. However, the corpus is actually a collection of 55 texts, one for each presidential address. An interesting property of this collection is its time dimension(时间维度,奥巴马的也有):
>>> from nltk.corpus import inaugural
>>> inaugural.fileids()
['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', ...]
>>> [fileid[:4] for fileid in inaugural.fileids()]
['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', ...]
Notice that the year of each text appears in its filename. To get the year out of the filename, we extracted the first four characters, using fileid[:4].
Let’s look at how the words America and citizen are used over time. The following code converts the words in the Inaugural corpus to lowercase using w.lower()①, then checks whether they start with either of the “targets” america or citizen using startswith()①. Thus it will count words such as American’s and Citizens. We’ll learn about conditional frequency distributions in Section 2.2; for now, just consider the output, shown in Figure 2-1.
>>> cfd = nltk.ConditionalFreqDist(
... (target, file[:4])
... for fileid in inaugural.fileids()
... for w in inaugural.words(fileid)
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
运行有问题,类型错误
Traceback (most recent call last):
File "E:/Test/NLTK/2.1.py", line 6, in <module>
for fileid in inaugural.fileids()
File "C:\Python26\lib\site-packages\nltk\probability.py", line 1740, in __init__
for (cond, sample) in cond_samples:
File "E:/Test/NLTK/2.1.py", line 9, in <genexpr>
if w.lower().startswith(target))
TypeError: 'type' object is unsubscriptable
Figure 2-1. Plot of a conditional frequency distribution: All words in the Inaugural Address Corpus that begin with america or citizen are counted; separate counts are kept for each address; these are plotted so that trends in usage over time can be observed; counts are not normalized for document length.
Annotated Text Corpora 注释文本语料库
Many text corpora contain linguistic annotations, representing part-of-speech tags, named entities, syntactic structures(句法结构), semantic roles(语义角色), and so forth. NLTK provides convenient ways to access several of these corpora, and has data packages containing corpora and corpus samples, freely downloadable for use in teaching and research. Table 2-2 lists some of the corpora. For information about downloading them, seehttp://www.nltk.org/data.For more examples of how to access NLTK corpora, please consult the Corpus HOWTO athttp://www.nltk.org/howto.
Table 2-2. Some of the corpora and corpus samples distributed with NLTK| Corpus | Compiler | Contents |
|---|---|---|
| Brown Corpus | Francis, Kucera | 15 genres, 1.15M words, tagged, categorized |
| CESS Treebanks | CLiC-UB | 1M words, tagged and parsed (Catalan, Spanish) |
| Chat-80 Data Files | Pereira & Warren | World Geographic Database |
| CMU Pronouncing Dictionary | CMU | 127k entries |
| CoNLL 2000 Chunking Data | CoNLL | 270k words, tagged and chunked |
| CoNLL 2002 Named Entity | CoNLL | 700k words, pos- and named-entity-tagged (Dutch, Spanish) |
| CoNLL 2007 Dependency Treebanks (sel) | CoNLL | 150k words, dependency parsed (Basque, Catalan) |
| Dependency Treebank | Narad | Dependency parsed version of Penn Treebank sample |
| Floresta Treebank | Diana Santos et al | 9k sentences, tagged and parsed (Portuguese) |
| Gazetteer Lists | Various | Lists of cities and countries |
| Genesis Corpus | Misc web sources | 6 texts, 200k words, 6 languages |
| Gutenberg (selections) | Hart, Newby, et al | 18 texts, 2M words |
| Inaugural Address Corpus | CSpan | US Presidential Inaugural Addresses (1789-present) |
| Indian POS-Tagged Corpus | Kumaran et al | 60k words, tagged (Bangla, Hindi, Marathi, Telugu) |
| MacMorpho Corpus | NILC, USP, Brazil | 1M words, tagged (Brazilian Portuguese) |
| Movie Reviews | Pang, Lee | 2k movie reviews with sentiment polarity classification |
| Names Corpus | Kantrowitz, Ross | 8k male and female names |
| NIST 1999 Info Extr (selections) | Garofolo | 63k words, newswire and named-entity SGML markup |
| NPS Chat Corpus | Forsyth, Martell | 10k IM chat posts, POS-tagged and dialogue-act tagged |
| PP Attachment Corpus | Ratnaparkhi | 28k prepositional phrases, tagged as noun or verb modifiers |
| Proposition Bank | Palmer | 113k propositions, 3300 verb frames |
| Question Classification | Li, Roth | 6k questions, categorized |
| Reuters Corpus | Reuters | 1.3M words, 10k news documents, categorized |
| Roget's Thesaurus | Project Gutenberg | 200k words, formatted text |
| RTE Textual Entailment | Dagan et al | 8k sentence pairs, categorized |
| SEMCOR | Rus, Mihalcea | 880k words, part-of-speech and sense tagged |
| Senseval 2 Corpus | Pedersen | 600k words, part-of-speech and sense tagged |
| Shakespeare texts (selections) | Bosak | 8 books in XML format |
| State of the Union Corpus | CSPAN | 485k words, formatted text |
| Stopwords Corpus | Porter et al | 2,400 stopwords for 11 languages |
| Swadesh Corpus | Wiktionary | comparative wordlists in 24 languages |
| Switchboard Corpus (selections) | LDC | 36 phonecalls, transcribed, parsed |
| Univ Decl of Human Rights | United Nations | 480k words, 300+ languages |
| Penn Treebank (selections) | LDC | 40k words, tagged and parsed |
| TIMIT Corpus (selections) | NIST/LDC | audio files and transcripts for 16 speakers |
| VerbNet 2.1 | Palmer et al | 5k verbs, hierarchically organized, linked to WordNet |
| Wordlist Corpus | OpenOffice.org et al | 960k words and 20k affixes for 8 languages |
| WordNet 3.0 (English) | Miller, Fellbaum | 145k synonym sets |
Corpora in Other Languages 其他语言的语料库
NLTK comes with corpora for many languages, though in some cases you will need to learn how to manipulate character encodings in Python before using these corpora (see Section 3.3).
>>> nltk.corpus.cess_esp.words()
['El', 'grupo', 'estatal', 'Electricit\xe9_de_France', ...]
>>> nltk.corpus.floresta.words()
['Um', 'revivalismo', 'refrescante', 'O', '7_e_Meio', ...]
>>> nltk.corpus.indian.words('hindi.pos')
['\xe0\xa4\xaa\xe0\xa5\x82\xe0\xa4\xb0\xe0\xa5\x8d\xe0\xa4\xa3',
'\xe0\xa4\xaa\xe0\xa5\x8d\xe0\xa4\xb0\xe0\xa4\xa4\xe0\xa4\xbf\xe0\xa4\xac\xe0\xa4
\x82\xe0\xa4\xa7', ...]
>>> nltk.corpus.udhr.fileids()
['Abkhaz-Cyrillic+Abkh', 'Abkhaz-UTF8', 'Achehnese-Latin1', 'Achuar-Shiwiar-Latin1',
'Adja-UTF8', 'Afaan_Oromo_Oromiffa-Latin1', 'Afrikaans-Latin1', 'Aguaruna-Latin1',
'Akuapem_Twi-UTF8', 'Albanian_Shqip-Latin1', 'Amahuaca', 'Amahuaca-Latin1', ...]
>>> nltk.corpus.udhr.words('Javanese-Latin1')[11:]
[u'Saben', u'umat', u'manungsa', u'lair', u'kanthi', ...]
The last of these corpora, udhr, contains the Universal Declaration of Human Rights(国际人权宣言)in over 300 languages. The fileids for this corpus include information about the character encoding used in the file, such as UTF8 or Latin1. Let’s use a conditional frequency distribution to examine the differences in word lengths for a selection of languages included in the udhr corpus. The output is shown in Figure 2-2 (run the program yourself to see a color plot). Note that True and False are Python’s built-in Boolean values.
>>> from nltk.corpus import udhr
>>> languages = ['Chickasaw', 'English', 'German_Deutsch',
... 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
>>> cfd = nltk.ConditionalFreqDist(
... (lang, len(word))
... for lang in languages
... for word in udhr.words(lang + '-Latin1'))
>>> cfd.plot(cumulative=True)
Figure 2-2. Cumulative word length distributions: Six translations of the Universal Declaration of Human Rights are processed; this graph shows that words having five or fewer letters account for about 80% of Ibibio text, 60% of German text, and 25% of Inuktitut text.
 Your Turn: Pick a language of interest in udhr.fileids(), and define a variable raw_text = udhr.raw(Language-Latin1). Now plot a frequency distribution of the letters of the text using nltk.FreqDist(raw_text).plot().
Your Turn: Pick a language of interest in udhr.fileids(), and define a variable raw_text = udhr.raw(Language-Latin1). Now plot a frequency distribution of the letters of the text using nltk.FreqDist(raw_text).plot().
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
不知道为什么Chinese_Mandarin-UTF8不能用,留下该问题继续看
Unfortunately, for many languages, substantial corpora are not yet available. Often there is insufficient(不足的) government or industrial support for developing language resources, and individual efforts are piecemeal(零碎的) and hard to discover or reuse. Some languages have no established writing system, or are endangered. (See Section 2.7 for suggestions on how to locate(查找) language resources.)
Text Corpus Structure文本语料库结构
We have seen a variety of corpus structures so far; these are summarized in Figure 2-3. The simplest kind lacks any structure: it is just a collection of texts. Often, texts are grouped into categories that might correspond to genre, source, author, language, etc. Sometimes these categories overlap, notably(尤其) in the case of topical(时事问题) categories, as a text can be relevant to more than one topic. Occasionally, text collections have temporal structure(时态结构), news collections being the most common example. NLTK’s corpus readers support efficient access to a variety of corpora, and can be used to work with new corpora. Table 2-3 lists functionality provided by the corpus readers.
Figure 2-3. Common structures for text corpora: The simplest kind of corpus is a collection of isolated texts with no particular organization; some corpora are structured into categories, such as genre (Brown Corpus); some categorizations overlap, such as topic categories (Reuters Corpus); other corpora represent language use over time (Inaugural Address Corpus).4种不同类型的语料库
Table 2-3. Basic corpus functionality defined in NLTK: More documentation can be found using help(nltk.corpus.reader) and by reading the online Corpus HOWTO athttp://www.nltk.org/howto.
Example | Description |
fileids() | The files of the corpus |
fileids([categories]) | The files of the corpus corresponding to these categories |
categories() | The categories of the corpus |
categories([fileids]) | The categories of the corpus corresponding to these files |
raw() | The raw content of the corpus |
raw(fileids=[f1,f2,f3]) | The raw content of the specified files |
raw(categories=[c1,c2]) | The raw content of the specified categories |
words() | The words of the whole corpus |
words(fileids=[f1,f2,f3]) | The words of the specified fileids |
words(categories=[c1,c2]) | The words of the specified categories |
sents() | The sentences of the specified categories |
sents(fileids=[f1,f2,f3]) | The sentences of the specified fileids |
sents(categories=[c1,c2]) | The sentences of the specified categories |
abspath(fileid) | The location of the given file on disk |
encoding(fileid) | The encoding of the file (if known) |
open(fileid) | Open a stream for reading the given corpus file |
root() | The path to the root of locally installed corpus |
readme() | The contents of the README file of the corpus |
We illustrate the difference between some of the corpus access methods here:
>>> raw = gutenberg.raw("burgess-busterbrown.txt")
>>> raw[1:20] #这个按单个字符算的
'The Adventures of B'
>>> words = gutenberg.words("burgess-busterbrown.txt")
>>> words[1:20] #这个按单个词和符号数字算的
['The', 'Adventures', 'of', 'Buster', 'Bear', 'by', 'Thornton', 'W', '.',
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
Loading Your Own Corpus 装载你自己的语料库
If you have a your own collection of text files that you would like to access using the methods discussed earlier, you can easily load them with the help of NLTK’s Plain textCorpusReader. Check the location of your files on your file system; in the following example, we have taken this to be the directory /usr/share/dict(这是Linux的吧). Whatever the location, set this to be the value of corpus_root①. The second parameter of the PlaintextCorpusReader initializer②can be a list of fileids, like ['a.txt', 'test/b.txt'], or a pattern that matches all fileids, like '[abc]/.*\.txt' (see Section 3.4 for information about regular expressions).
>>> from nltk.corpus import PlaintextCorpusReader
>>> corpus_root = '/usr/share/dict' ①
>>> wordlists = PlaintextCorpusReader(corpus_root, '.*') ②
>>> wordlists.fileids()
['README', 'connectives', 'propernames', 'web2', 'web2a', 'words']
>>> wordlists.words('connectives')
['the', 'of', 'and', 'to', 'a', 'in', 'that', 'is', ...]
As another example, suppose you have your own local copy of Penn Treebank (release 3), in C:\corpora. We can use the BracketParseCorpusReader to access this corpus. We specify the corpus_root to be the location of the parsed Wall Street Journal component of the corpus①, and give a file_pattern that matches the files contained within its subfolders② (using forward slashes斜杠).
>>> from nltk.corpus import BracketParseCorpusReader
>>> corpus_root = r"C:\corpora\penntreebank\parsed\mrg\wsj" ①
>>> file_pattern = r".*/wsj_.*\.mrg" ②
>>> ptb = BracketParseCorpusReader(corpus_root, file_pattern)
>>> ptb.fileids()
['00/wsj_0001.mrg','00/wsj_0002.mrg', '00/wsj_0003.mrg', '00/wsj_0004.mrg', ...]
>>> len(ptb.sents())
49208
>>> ptb.sents(fileids='20/wsj_2013.mrg')[19]
['The', '55-year-old', 'Mr.', 'Noriega', 'is', "n't", 'as', 'smooth', 'as', 'the',
'shah', 'of', 'Iran', ',', 'as', 'well-born', 'as', 'Nicaragua', "'s", 'Anastasio',
'Somoza', ',', 'as', 'imperial', 'as', 'Ferdinand', 'Marcos', 'of', 'the', 'Philippines',
'or', 'as', 'bloody', 'as', 'Haiti', "'s", 'Baby', Doc', 'Duvalier', '.']
扩展:python 中文语料库 / python 语料库 / 文本分类语料库
四 : opencv-python 学习笔记1:简单的图片处理
转载请注明:@小五义http://www.cnblogs.com/xiaowuyi QQ群:64770604
一、主要函数
1、 cv2.imread():读入图片,共两个参数,第一个参数为要读入的图片文件名,第二个参数为如何读取图片,包括cv2.IMREAD_COLOR:读入一副彩色图片;cv2.IMREAD_GRAYSCALE:以灰度模式读入图片;cv2.IMREAD_UNCHANGED:读入一幅图片,并包括其alpha通道。(www.61k.com)
2、cv2.imshow():创建一个窗口显示图片,共两个参数,第一个参数表示窗口名字,可以创建多个窗口中,但是每个窗口不能重名;第二个参数是读入的图片。
3、cv2.waitKey():键盘绑定函数,共一个参数,表示等待毫秒数,将等待特定的几毫秒,看键盘是否有输入,返回值为ASCII值。如果其参数为0,则表示无限期的等待键盘输入。
4、cv2.destroyAllWindows():删除建立的全部窗口。
5、cv2.destroyWindows():删除指定的窗口。
6、cv2.imwrite():保存图片,共两个参数,第一个为保存文件名,第二个为读入图片。
二、实例
1、以下面的图片为例

2、显示并保存彩色图片
# -*- coding: utf-8 -*- """ @xiaowuyi:http://www.cnblogs.com/xiaowuyi """ import cv2 img=cv2.imread('1.jpg',cv2.IMREAD_COLOR)# 读入彩色图片 cv2.imshow('image',img)#建立image窗口显示图片 k=cv2.waitKey(0)#无限期等待输入 if k==27:#如果输入ESC退出 cv2.destroyAllWindows() elif k==ord('s'):#如果输入s,保存 cv2.imwrite('test.png',img) print "OK!" cv2.destroyAllWindows()显示结果:

3、显示并保存黑白图片
# -*- coding: utf-8 -*- """ @xiaowuyi:http://www.cnblogs.com/xiaowuyi """ import cv2 img=cv2.imread('1.jpg',cv2.IMREAD_GRAYSCALE)# 读入彩色图片 cv2.imshow('image',img)#建立image窗口显示图片 k=cv2.waitKey(0)#无限期等待输入 if k==27:#如果输入ESC退出 cv2.destroyAllWindows() elif k==ord('s'): cv2.imwrite('test.png',img) print "OK!" cv2.destroyAllWindows()显示结果:

五 : python 系统学习笔记(三)---function
函数:
一、什么是函数
很多时候,Python程序中的语句都会组织成函数的形式。通俗地说,函数就是完成特定功能的一个语句组,这组语句可以作为一个单位使用,并且给它取一个名字,这样,我们就可以通过函数名在程序的不同地方多次执行(这通常叫做函数调用),却不需要在所有地方都重复编写这些语句。另外,每次使用函数时可以提供不同的参数作为输入,以便对不同的数据进行处理;函数处理后,还可以将相应的结果反馈给我们。
有些函数是用户自己编写的,通常我们称之为自定义函数;此外,系统也自带了一些函数,还有一些第三方编写的函数,如其他程序员编写的一些函数,我们称为预定义的Python函数,对于这些现成的函数用户可以直接拿来使用。
二、为什么使用函数
我们之所以使用函数,主要是出于两个方面的考虑:一是为了降低编程的难度,通常将一个复杂的大问题分解成一系列更简单的小问题,然后将小问题继续划分成更小的问题,当问题细化为足够简单时,我们就可以分而治之。这时,我们可以使用函数来处理特定的问题,各个小问题解决了,大问题也就迎刃而解了。二是代码重用。我们定义的函数可以在一个程序的多个位置使用,也可以用于多个程序。此外,我们还可以把函数放到一个模块中供其他程序员使用,同时,我们也可以使用其他程序员定义的函数。这就避免了重复劳动,提供了工作效率。
基本语法
def fun(n,m,...)
....
....
....
(return n)
关于return
1,return可以有,可以没有,
2,没有return的方法返回None,
3,return后面没有表达式也是返回None,
4,函数无法到达结尾也返回None。
关于变量与方法
1,定义的方法名会在“当前符号表”中注册,这样系统就知道这个方法名为一个方法,将
方法赋值给一个变量,这个变量则变成了对应的方法。
2,与我们以前学习的程序层次一样的,每个层次都有自己的符号表。内层符号表是可以
使用外层符号表中的东西,但是已经不是一个层次的,所以没有什么关系,意思是说,
上层联系下层只能通过参数,下层联系上层只能是返回值。并且到现在为止,我们只知
道有值传递。也就是说,函数内部与外部完全没有什么关系。
3,也就是说,到现在为止,函数层与上层之间没有任何关系,它有自己的符号表,参数
只能从上层得到值,却不能改变上层的内容,一切在函数内部使用的变量都是函数本身
的与上层无关。也就是说函数基本不能主动改变上层的东西。
函数是重用的程序段。它们允许你给一块语句一个名称,然后你可以在你的程序的任何地方使用这个名称任意多次地运行这个语句块。这被称为调用函数。我们已经使用了许多内建的函数,比如len和range。
函数通过def关键字定义。def关键字后跟一个函数的标识符名称,然后跟一对圆括号。圆括号之中可以包括一些变量名,该行以冒号结尾。接下来是一块语句,它们是函数体。
1、定义函数:
例如:
[python]
<span># Filename: function1.py
def sayHello():
print('Hello World!') # block belonging to the function
# End of function
sayHello() # call the function
sayHello() # call the function again
</span>
输出:
C:\Users\Administrator>python D:\python\function1.py
Hello World!
Hello World!
工作原理:
我们使用上面解释的语法定义了一个称为sayHello的函数。这个函数不使用任何参数,因此在圆括号中没有声明任何变量。参数对于函数而言,只是给函数的输入,以便于我们可以传递不同的值给函数,然后得到相应的结果。我们在上程序中调用了两次相同的函数从而避免了对同一程序段写两次。
2、函数形参:
函数取得的参数是你提供给函数的值,这样函数就可以利用这些值做一些事情。这些参数就像变量一样,只不过它们的值是在我们调用函数的时候定义的,而非在函数本身内赋值。
参数在函数定义的圆括号对内指定,用逗号分割。当我们调用函数的时候,我们以同样的方式提供值。注意我们使用过的术语——函数中的参数名称为形参而你提供给函数调用的值称为实参。
使用函数形参:
例如:
[python]
<span># Filename: func_param.py
def printMax(a, b):
if a > b:
print(a, 'is maximum')
elif a == b:
print(a, 'is equal to', b)
else:
print(b, 'is maximum')
printMax(3, 4) # directly give literal values
x = 5
y = 7
printMax(x, y) # give variables as arguments
</span>
输出:
C:\Users\Administrator>python D:\python\func_param.py
4 is maximum
7 is maximum
工作原理:
这里,我们定义了一个称为printMax的函数,这个函数需要两个形参,a和b。我们使用if..else语句找出两者之中较大的一个数,并且打印较大的那个数。
在第一个printMax使用中,我们直接把数,即实参,提供给函数。在第二个使用中,我们使用变量调用函数。printMax(x, y)使实参x的值赋给形参a,实参y的值赋给形参b。在两次调用中,printMax函数的工作完全相同。
3、局部变量:
当你在函数定义内声明变量的时候,它们与函数外具有相同名称的其他变量没有任何关系,即变量名称对于函数来说是 局部 的。这称为变量的作用域 。所有变量的作用域是它们被定义的块,从它们的名称被定义的那点开始。
例如:
[python]
<span># Filename: func_local.py
x = 50
def func(x):
print('x is', x)
x = 2
print('Changed local x to', x)
func(x)
print('x is still', x)
</span>
输出:
C:\Users\Administrator>python D:\python\func_local.py
x is 50
Changed local x to 2
x is still 50
工作原理:
在函数中,我们第一次使用x的 值 的时候,Python使用函数声明的形参的值。
接下来,我们把值2赋给x。x是函数的局部变量。所以,当我们在函数内改变x的值的时候,在主块中定义的x不受影响。
在最后一个print语句中,我们证明了主块中的x的值确实没有受到影响。
4、全局变量:
如果你想要为一个定义在函数外的变量赋值,那么你就得告诉Python这个变量名不是局部的,而是全局的。我们使用global语句完成这一功能。没有global语句,是不可能为定义在函数外的变量赋值的。
你可以使用定义在函数外的变量的值(假设在函数内没有同名的变量)。然而,并不推荐这样做,并且我们应该尽量避免这样做,因为这使得程序的读者会不清楚这个变量是在哪里定义的。使用global语句可以清楚地表明变量是在外面的块定义的。
我们可以这样使用:
[python]
<span># Filename: func_global.py
x = 50
def func():
global x
print('x is', x)
x = 2
print('Changed global x to', x)
func()
print('Value of x is', x)
</span>
输出:
C:\Users\Administrator>python D:\python\func_global.py
x is 50
Changed global x to 2
Value of x is 2
工作原理:
global语句被用来声明x是全局的——因此,当我们在函数内把值赋给x的时候,这个变化也反映在我们在主块中使用x的值的时候。
你可以使用同一个global语句指定多个全局变量。例如global x, y, z。
5、外部变量:
上面我们已经知道如何使用局部变量和全局变量,还有一个外部变量是在以上两种变量之间的变量。当我们在函数内声明了外部变量则在函数中就可见了。
由于任何东西在python内都是可执行代码,所以你可以在任何位置定义函数,就如以下例子中的func_inner()定义在func_outer()内也是可以的。
以下例子说明如何使用外部变量:
[python
<span># Filename: func_nonlocal.py
def func_outer():
x = 2
print('x is', x)
def func_inner():
nonlocal x
x = 5
func_inner()
print('Changed local x to', x)
func_outer()
</span>
输出:
C:\Users\Administrator>python D:\python\func_nonlocal.py
x is 2
Changed local x to 5
工作原理:
当我们在func_inner()函数中的时候,在函数func_outer()内第一行定义的变量x既不是内部变量(它不在func_inner块内)也不是全局变量(它也不在主程序块内),这时我们使用nonlocal x声明我们需要使用这个变量。
你可以尝试改变声明方式,然后观察这几种变量的区别。
6、默认参数值
对于一些函数,你可能希望它的一些参数是可选的,如果用户不想要为这些参数提供值的话,这些参数就使用默认值。这个功能借助于默认参数值完成。你可以在函数定义的形参名后加上赋值运算符(=)和默认值,从而给形参指定默认参数值。
注意,默认参数值应该是一个常数。更加准确的说,默认参数值应该是不可变的。
使用默认参数值:
例如:
[python]
<span># Filename: func_default.py
def say(message, times = 1):
print(message * times)
say('Hello')
say('World', 5)
</span>
输出:
C:\Users\Administrator>python D:\python\func_default.py
Hello
WorldWorldWorldWorldWorld
工作原理:
名为say的函数用来打印一个字符串任意所需的次数。如果我们不提供一个值,那么默认地,字符串将只被打印一遍。我们通过给形参times指定默认参数值1来实现这一功能。
在第一次使用say的时候,我们只提供一个字符串,函数只打印一次字符串。在第二次使用say的时候,我们提供了字符串和参数5,表明我们想要打印这个字符串消息5遍。
注:
只有在形参表末尾的那些参数可以有默认参数值,即你不能在声明函数形参的时候,先声明有默认值的形参而后声明没有默认值的形参。
这是因为赋给形参的值是根据位置而赋值的。例如,def func(a, b=5)是有效的,但是def func(a=5, b)是无效的。
7、关键字(Keyword)参数:
如果你的某个函数有许多参数,而你只想指定其中的一部分,那么你可以通过命名来为这些参数赋值——这被称作关键字参数,我们使用名字(关键字)而不是位置(我们前面所一直使用的方法)来给函数指定实参。
这样做有两个优势:一,由于我们不必担心参数的顺序,使用函数变得更加简单了;二、假设其他参数都有默认值,我们可以只给我们想要的那些参数赋值。
使用关键参数:
[python]
<span># Filename: func_key.py
def func(a, b=5, c=10):
print('a is', a, 'and b is', b, 'and c is', c)
func(3, 7)
func(25, c=24)
func(c=50, a=100)</span>
输出:
C:\Users\Administrator>python D:\python\func_key.py
a is 3 and b is 7 and c is 10
a is 25 and b is 5 and c is 24
a is 100 and b is 5 and c is 50
工作原理:
名为func的函数有一个没有默认值的参数,和两个有默认值的参数。
在第一次使用函数的时候, func(3, 7),参数a得到值3,参数b得到值7,而参数c使用默认值10。
在第二次使用函数func(25, c=24)的时候,根据实参的位置变量a得到值25。根据命名,即关键参数,参数c得到值24。变量b根据默认值,为5。
在第三次使用func(c=50, a=100)的时候,我们使用关键参数来完全指定参数值。注意,尽管函数定义中,a在c之前定义,我们仍然可以在a之前指定参数c的值。
8、可变(VarArgs)参数:
有些时候你可能希望定义一个可以接受任意个数参数的函数,你可以使用星号来完成。
例如:
[python]
<span># Filename: total.py
def total(initial=5, *numbers, **keywords):
count = initial
for number in numbers:
count += number
for key in keywords:
count += keywords[key]
return count
print(total(10, 1, 2, 3, vegetables=50, fruits=100))
</span>
输出:
C:\Users\Administrator>python D:\python\total.py
166
工作原理:
当我们以星号声明一个形参,如*param,从这个位置开始到结束的实参都将被收集在'param'元组内,类似的,当我们以双星号声明一个形参,例如**param,则从这个位置开始到结束的实参都将会被收集在一个叫'param'的字典中。
对于元组和字典,我们后面有详细讲解。
9、关键字限定(Keyword-only)参数:
如果我们希望某些关键形参只能通过关键字实参的到而不是通过位置得到,我们可以将其声明在星号参数后面。
例如:
[python]
<span># Filename: keyword_only.py
def total(initial=5, *numbers, extra_number):
count = initial
for number in numbers:
count += number
count += extra_number
print(count)
total(10, 1, 2, 3, extra_number=50)
total(10, 1, 2, 3)
# Raises error because we have not supplied a default argument value for 'extra_number'
</span>
输出:
C:\Users\Administrator>python D:\python\keyword_only.py
66
Traceback (most recent call last):
File "D:\python\keyword_only.py", line 11, in <module>
total(10, 1, 2, 3)
TypeError: total() needs keyword-only argument extra_number
工作原理:
在星号形参后声明的形成就成了关键字限定参数。如果没有为这些实参提供一个默认值,那么必须在调用函数时以关键字实参为其赋值,否则将引发错误,如上例所示。
注意这里用到的x+=y等同于x=x+y。如果你不需要星号形参只需要关键字限定形参则可以省略星号形参的参数名,如total(initial=5, *, extra_number)。
10、return语句
return语句用来从一个函数返回即跳出函数。我们也可选从函数返回一个值。
例如:
[python]
<span># Filename: func_return.py
def maximum(x, y):
if x > y:
return x
elif x == y:
return 'The numbers are equal'
else:
return y
print(maximum(2, 3))</span>
输出:
C:\Users\Administrator>python D:\python\func_return.py
3
工作原理:
maximum函数返回参数中的最大值,在这里是提供给函数的数。它使用简单的if..else语句来找出较大的值,然后返回那个值。
注意,没有返回值的return语句等价于return None。None是Python中表示没有任何东西的特殊类型。例如,如果一个变量的值为None,可以表示它没有值。
除非你提供你自己的return语句,每个函数都在结尾暗含有return None语句。通过运行print someFunction(),你可以明白这一点,函数someFunction没有使用return语句,如同:
[python]
<span>def someFunction():
pass
print(someFunction())
</span>
输出就是None。
提示:python已经包含了一个被称作max的内建函数,它的功能即是寻找最大值,你可以尽可能使用这个函数。
11、文档字符串(DocStrings):
Python有一个很奇妙的特性,称为文档字符串,它通常被简称为docstrings。DocStrings是一个重要的工具,由于它帮助你的程序文档更加简单易懂。你甚至可以在程序运行的时候,从函数恢复文档字符串!
例如:
[python]
<span># Filename: func_doc.py
def printMax(x, y): www.2cto.com
'''''Prints the maximum of two numbers.
The two values must be integers.'''
x = int(x) # convert to integers, if possible
y = int(y)
if x > y:
print(x, 'is maximum')
else:
print(y, 'is maximum')
printMax(3, 5)
print(printMax.__doc__)
</span>
本文标题:python学习笔记-Python学习261阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1