一 : 服务器监控6120c手机软件
二 : Nagios--运维监控软件--简易安装与配置(已经在信工服务器实现)
Nagios的主要功能特点简介:
- 监视网络服务 (SMTP, POP3, HTTP, NNTP, PING等)
- 监视主机资源 (进程, 磁盘等)
- 简单的插件设计可以轻松扩展Nagios的监视功能
- 服务等监视的并发处理
- 错误通知功能 (通过email, pager, 或其他用户自定义方法)
- 可指定自定义的事件处理控制器
- 可选的基于浏览器的WEB界面以方便系统管理人员查看网络状态,各种系统问题,以及日志等等
- 可以通过手机查看系统监控信息
它也有一个 Windows 下的客户端:
一、软件下载
Nagios安装至少也应该配置下Apache的Httpd服务器,否则没有界面,只能靠查看日志去找错误,那就是完全没有意外了
Nagios下载地址:http://www.nagios.org/download/
Httpd下载地址:http://mirror.bit.edu.cn/apache/httpd/
必须安装GCC!!! 其实,我们的apache可以直接用yum来安装,不必指定路径,就可以直接配置apache了。[www.61k.com)
二、安装软件过程
1、Nagios安装
#tar -zxvf nagios-2.6.tar.gz
#mkdir /usr/local/nagios
#./configure –prefix=/usr/local/nagios //设置安装的目录,可随自己喜欢
#make all
附图片

与别的软件安装稍有不同,nagios的安装要好几步才能完成
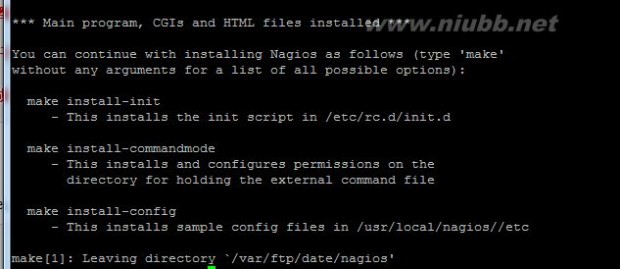
#make install //安装主要的程序、CGI及HTML文件; #make install-commandmode //给外部命令访问nagios配置文件的权限; #make install-config //把配置文件的例子复制到nagios的安装目录,按照安装向导的提示
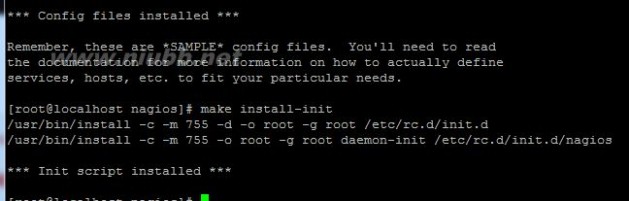
#make install-init //作用是把nagios做成一个运行脚本在/etc/rc.d/init.d安装启动脚本
正确图解:

若make install出现如下问题
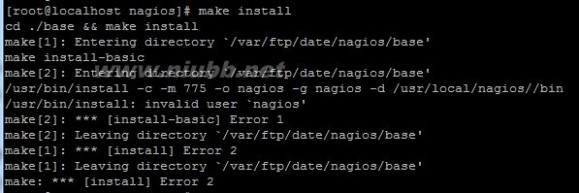
原因:由于系统找不到nagios这个用户
解决办法:直接找到“第三、配置用户” 进行配置即可
验证程序是否被正确安装。
切换目录到安装路径,看是否存在 etc、bin、 sbin、 share、 var 这五个目录,其中也可能存在一个libexec,但里面没有文档,如果存在则可以表明程序被正确的安装到系统了
#cd /usr/local/nagios
#ls
bin etc sbin share libexec var
下表是五个目录主要功能的简要说明:
bin | Nagios执行程序所在目录,这个目录只有一个文件nagios |
etc | Nagios配置文件位置,初始安装完后,只有几个*.cfg-sample文件 |
sbin | Nagios Cgi文件所在目录,也就是执行外部命令所需文件所在的目录 |
Share | Nagios网页文件所在的目录 |
Var | Nagios日志文件、spid 等文件所在的目录 |
2、插件安装
Nagios的插件在 www.nagios.org 上可以找到,接着我们用wget下载它,除了下载常用的插件外,我们还可以根据实际要求编写自己的插件
#wgethttp://prdownloads.sourceforge.net/sourceforge/nagiosplug/nagios-plugins-1.4.16.tar.gz
安装它是很简单
#tar -zxvfnagios-plugins-1.4.16.tar.gz
# ./configure -prefix=/usr/local/nagios #make #make install
说明:安装路径是/usr/local/nagios ,完成后,在目录/usr/local/nagios生成目录 libexec 里面有很多文件
图解
扩展:nagios监控多台服务器 / nagios监控服务器进程 / nagios监控服务器
3、安装web
Web服务不是nagios所必须的,但是如果nagios没有web,查看监控对象的对象将是非常费事和没有趣味的事情,只有通过查看nagios的日志来判断状态
在unix/linux世界,apache是web服务器的首选对象,其下载网站为 www.apache.org
#wgethttp://labs.mop.com/apache-mirror//httpd/httpd-2.2.22.tar.gz
#tar -zxvf httpd-2.2.22.tar.gz
#cd httpd-2.2.22
#mkdir /usr/local/apache/
#./configure –prefix=/usr/local/apache
#make
#make install
安装完成后,执行命令检查一下apache是否正确安装
#./usr/local/apache/bin/apachectl –t (用yum安装的,#apachectl -t)
说明:没有提示出错,那就是已经正确安装
假期出现如下错误:
Httpd Could not reliably determine the server`s fully qualified domain name
vi /usr/local/apache/httpd/conf/httpd.conf
加入一句 ServerName localhost:80
或将#ServerName www.example.com:80——>ServerNamewww.example.com:80
#/usr/local/apache/bin/apachectl restart重启即可
假若再出现如下情况:
(98)Address already in use: make_sock: could not bind to address [::]:80 (98)Address already in use: make_sock: could not bind to address 0.0.0.0:80
方法 :
#netstat -lnp | grep 80
#ps -aux | grep http
#ps -aux | grep apache
将看到的http及apache的进程kill
三、配置
引用(yahoon 的BLOG):
Nagios自己定义了一套规则用于配置文件,其中最重要的概念就是”对象”----object.通俗的理解:假定我们首先定义了”性别”这个对象,它的值只可能是男,女,人妖等等,然后定义某人为一个对象,例如张三,定义张三的时候有”性别”这个属性,它的值就必须来源了之前定义的性别这个对象,要么是男是女,或者是人妖.在Nagios里面定义了一些基本的对象,一般用到的有:
联系人 | contact | 出了问题像谁报告?一般当然是系统管理员了 |
监控时间段 | timeperiod | 7X24小时不间断还是周一至周五,或是自定义的其他时间段 |
被监控主机 | host | 所需要监控的服务器,当然可以是监控机自己 |
监控命令 | command | nagios发出的哪个指令来执行某个监控,这也是自己定义的 |
被监控的服务 | service | 例如主机是否存活,80端口是否开,磁盘使用情况或者自定义的服务等 |
另外,多个被监控主机可以定义为一个主机组,多个联系人可以被定义为一个联系人组,多个服务还能定义成一个服务组呢.
回到上面的例子,定义张三需要之前定义的性别,我们定义一个被监控的服务,当然就要指定被监控的主机,需要监控的时间段,要用哪个命令来完成这个监控操作,出了问题向哪个联系人报告.所有这些对象绝对多数都是需要我们手动定义的,这就是nagios的安装显得复杂的地方
1、添加Nagios用户(为了安全,不让root登录)
#useradd nagios (或useradd –g nagios nagios) #passwd nagios #groupadd nagiosG #usermod -G nagiosG nagios #usermod -G nagiosG apache //假若没有此用户,在安装完成httpd后再添加
2、添加目录权限
#mkdir /usr/local/nagios (没有就新建) #chown –R nagios.nagios /usr/local/nagios(或chown –R nagios:nagios /usr/local/nagios)
3、测试发送信息
(1)看sendmail是否正常,我们需要使用sendmail来发送故障报警信息,所以这个包必须能够正常工作
Sendmail分为服务器和客户端两部分,有2种发送报警邮件的方式:
A、nagios所在的机器通过sendmail客户端程序把邮件发送到专门的邮件服务器,再由邮件服务器把消息发送到用户邮箱。
B、邮件客户端和服务器端就用nagios所在系统sendmail。
第一种方式用起来非常规范,但更麻烦,例如需要做地址解析、修改邮件服务器的配置;另外还有一个问题-它还依赖别的系统,增加了故障点和复杂度。
第二种方法十分简单,只需启动sendmail服务即可,而且它不再依赖于别的系统和服务。
几乎所有的linux/unix发行版都默认安装sendmail,但我们必须要将 sendmail 服务运行起来。
#rpm -qa | grep sendmail //检查系统有没有安装sendmail #yum install -y sendmail* //假若没有就用yum来安装默认配置也可以了,如有需要也可以参考网上的相关配置
扩展:nagios监控多台服务器 / nagios监控服务器进程 / nagios监控服务器
#mail -s "hope" abc@mail.com < /tmp/test.ini另外一种方法:
安装sendmail组件
首先要确保sendmail相关组件的完整安装,我们可以使用如下的命令来完成sendmail的安装:
# yum install -y sendmail* # service sendmail start #setenforce 0 #service iptables stop # echo "aa" | mail abcde@163.com
(2)手机信息功能(待测)
假若公司是有自己的短信通道,直接把发送短信的客户端程序sms_send拷贝到目录/usr/local/bin/下。如果没有短信下发的网关通道,那怎么办呢?网络上有很多短信发送的客户端程序,很有名的就是smsclient,把它下载下来,解包后安装。不要忘记购买手机modem和手机卡,modem只支持SIM卡而不支持cdma。
安装完smsclient软件和硬件modem后,测试一下是否正常。如果没有modem又怎么办?办法还是有的:让你的手机号可以接受邮件,这需要你去营业厅开通这项功能。短信报警功能是最有用的功能,我们不可能成天盯着监视屏幕,也不可能成天接受电子邮件,但我们的手机却可以24小时在线,只要被监控对象发生故障,马上就可以收到故障报警短信。
4、Apache配置
修改apache的配置文件httpd.conf,把apache的运行用户和运行组改成nagios和nagiosG
#vim /usr/local/apache/conf/httpd.conf
往下把下面的行追加到文件httpd.conf的末尾:
#setting for nagios ScriptAlias /nagios/cgi-bin /usr/local/nagios/sbin <Directory "/usr/local/nagios/sbin"> #Cgi文件所在目录 AuthType Basic Options ExecCGI AllowOverride None Order allow,deny Allow from all AuthName "Nagios Access" AuthUserFile /usr/local/nagios/etc/htpasswd #验证文件路径 Require valid-user Alias /nagios /usr/local/nagios/share <Directory "/usr/local/nagios/share"> #nagios页面文件目录 AuthType Basic Options None AllowOverride None Order allow,deny Allow from all AuthName "nagios Access" AuthUserFile /usr/local/nagios/etc/htpasswd #验证文件路径 Require valid-user
生成用户验证文件:
# /usr/local/apache/bin/htpasswd –c /usr/local/nagios/etc/htpasswd sery (用yum安装的,#htpsswd -c ~~~~~~~)
#vim /usr/local/nagios/etc/htpasswd //第一个字段是刚生成的用户名,第二个是加密后的密码
配置完成后检查apache配置文件是否有语法错误
#/usr/local/apache/bin/apachctl –t
#/usr/local/apache/bin/apachctl start &
如何提示如下错误:
Syntax error on line 424 of /usr/local/apache/conf/httpd.conf:
AuthType not allowed here
原因是,你没有添加cgi文件及nagios文件相关的目录
在浏览器输入nagios 的访问地址(如:http://localhost/nagios 或 http://ip/nagios ),如果正常,将出现登录验证窗口等待用户输入
5、nagios配置
(1)修改配置文件:
Nagios的主配置文件是nagios.cfg
#vim /usr/local/nagios/etc/nagios.cfg
注释行
#cfg_file=/usr/local/nagios/etc/localhost.cfg
然后把下面几行的注释去掉及修改其他
cfg_file=/usr/local/nagios/etc/contactgroups.cfg //联系组配置文件路径
cfg_file=/usr/local/nagios/etc/contacts.cfg //联系人配置文件路径
cfg_file=/usr/local/nagios/etc/hostgroups.cfg //主机组配置文件路径
cfg_file=/usr/local/nagios/etc/hosts.cfg //主机配置文件路径
cfg_file=/usr/local/nagios/etc/services.cfg //服务配置文件路径
cfg_file=/usr/local/nagios/etc/timeperiods.cfg //监视时段配置文件路径
check_external_commands=0 ——> check_external_commands=1 //改为这行的作用是允许执行在web界面下重启nagios、停止主机/服务检查等操作
command_check_interval=1 ——> command_check_interval=10s
若发现/usr/local/nagios/etc并没有文件hosts.cfg等一干文件,稍后手动创建它们
接下来修改修改配置文件/usr/local/nagios/etc/cgi.cfg,它的作用是控制相关cgi脚本 ,必须default_user_name=sery,再后面的修改
use_authentication=1
authorized_for_system_information=nagiosadmin,sery authorized_for_configuration_information=nagiosadmin,sery authorized_for_system_commands=sery #多个用户之间用逗号隔开 authorized_for_all_services=nagiosadmin,sery authorized_for_all_hosts=nagiosadmin,sery authorized_for_all_service_commands=nagiosadmin,sery authorized_for_allwww.61k.comcommands=nagiosadmin,sery
(2)修改的配置文件 misccommands.cfg(主要功能是用来发送报警短信和报警邮件)
#host-notify-by-sms //发送短信报警 define command { command_name host-notify-by-sms command_line /usr/local/bin/sms_send "Host $HOSTSTATE$ alert for $HOSTNAME$! on '$DATETIME$' " $CONTACTPAGER$ } #service notify by sms //发送短信报警 define command { command_name service-notify-by-sms command_line /usr/local/bin/sms_send "'$HOSTADDRESS$' $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$" $CONTACTPAGER$ }扩展:nagios监控多台服务器 / nagios监控服务器进程 / nagios监控服务器
主机和服务的邮件报警通知已经在文件中,不须更改,也可以把短信和邮件报警通知这些配置块写到文件commands.cfg中,效果是一样的
(3)增加新的配置文件
#vim timeperiods.cfg
其内容
define timeperiod{ timeperiod_name 24x7 alias 24 Hours A Day, 7 Days A Week sunday 00:00-24:00 monday 00:00-24:00 tuesday 00:00-24:00 wednesday 00:00-24:00 thursday 00:00-24:00 friday 00:00-24:00 saturday 00:00-24:00 }(4)再创建的配置文件是
#vim contacts.cfg
内容
define contact { contact_name sa //不要有空格 alias system administrator service_notification_period 24x7 host_notification_period 24x7 service_notification_options w,u,c,r host_notification_options d,u,r service_notification_commands service-notify-by-sms,service- notify-by-email //这个命令读配置文件miscommands.cfg host_notification_commands host-notify-by-email,host-noti fy-by-sms //这个命令读配置文件miscommands.cfg email sery@163.com pager 13333333333 //手机号,收报警短信 } //不要把这个符号写掉了 define contact { contact_name sery alias system administrator service_notification_period 24x7 host_notification_period 24x7 service_notification_options w,u,c,r host_notification_options d,u,r service_notification_commands service-notify-by-sms,service- notify-by-email host_notification_commands host-notify-by-email,host-noti fy-by-sms email sery@sohu.com pager 13312345678 }
//如果有更多联系人的话,照这个格式在后面追加即可说明:服务通知选项(service_notification_options)与主机通知选项(host_notification_options)
分为:w-warning , u-unknown,c-critical,r-recovery;d-down,u-unreachable
引用解释各主要含义:
service_notification_period 24x7 服务出了状况通知的时间段,这个时间段就是上面在timeperiods.cfg中定义的. |
host_notification_period 24x7 主机出了状况通知的时间段, 这个时间段就是上面在timeperiods.cfg中定义的 |
service_notification_options w,u,c,r 当服务出现w—报警(warning),u—未知(unkown),c—严重(critical),或者r—从异常情况恢复正常,在这四种情况下通知联系人. |
host_notification_options d,u,r 当主机出现d—当机(down),u—返回不可达(unreachable),r—从异常情况恢复正常,在这3种情况下通知联系人 |
service_notification_commands notify-by-email 服务出问题通知采用的命令notify-by-email,这个命令是在commands.cfg中定义的,作用是给联系人发邮件.至于commands.cfg之后将专门介绍 |
host_notification_commands host-notify-by-email 同上,主机出问题时采用的也是发邮件的方式通知联系人 |
email yahoon@test.com 很明显,联系的人email地址 |
pager 133xxxx 联系人的手机,如果支持短信的通知的话,这个就很有用了. |
alias是联系人别名,address是地址 意义不大. |
(5)再创建的配置文件
#vim contactgroups.cfg
内容如下
define contactgroup { contactgroup_name sagroup //不要用空格 alias system administrator group members sa sery //本例有2个成员 }
//多个成员之间用逗号做分界符,如果有更多的联系组,就依相同的格式在文件中追加余下的组(6)重要配置文件
#vim hosts.cfg
定义的两个主机的基本样式
#define monitor host ################################################################# # Wangjing IDC servers # ################################################################# define host { host_name nagios-server alias nagios server //别名 address 61.x..x.49 contact_groups sagroup //多个联系组用逗号分隔,数据来源于contactgroups.cfg check_command check-host-alive //监控的命令check-host-alive,这个命令来自commands.cfg,用来监控主机是否存活 max_check_attempts 5 //检查失败后重试的次数 notification_interval 10 //提醒的间隔,其值可调,大小什么值合适需自己测定 notification_period 24x7 //提醒的周期, 24x7,同样来自于我们之前在timeperiods.cfg中定义的 notification_options d,u,r //指定什么情况下提醒,具体含义见之前contacts.cfg部分的介绍 } define host { host_name 24-25 alias server 24-25 address 202.X.24.25 contact_groups sagroup check_command check-host-alive //down机就发报警通知 max_check_attempts 5 notification_interval 10 notification_period 24x7 notification_options d,u,r }扩展:nagios监控多台服务器 / nagios监控服务器进程 / nagios监控服务器
//更多的主机依此格式逐个追加进来小技巧:如果是连续的ip段,最好自己写个脚本生成hosts.cfg文件,为了以后维护方便,尽可能在文件中使用易读的注释
(7)再一个重量级的配置文件是
#vim services.cfg
样式文件
#service definition ############################################################## # Wangjing IDC servers service for host-live # ############################################################## define service { host_name nagios-server //被监控的主机名,来源:hosts.cfg service_description check-host-alive //监控项目的描述(也可以说是这个项目的名称),我们这里定义的是监控这个主机是不是存活 check_period 24x7 max_check_attempts 4 normal_check_interval 3 retry_check_interval 2 contact_groups sagroup //联系人组,来源:contactgroups.cfg notification_interval 10 notification_period 24x7 notification_options w,u,c,r check_command check-host-alive //检查主机是否存活 } define service { host_name 24-25 service_description check_tcp 80 check_period 24x7 max_check_attempts 4 normal_check_interval 3 retry_check_interval 2 contact_groups sagroup notification_interval 10 notification_period 24x7 notification_options w,u,c,r check_command check_tcp!80 //检查tcp 80端口服务是否正常 }书写时要注意的是,check_tcp与要监控的服务端口之间要用”!”做分隔符。如果服务太多,以应该考虑用脚本来生成
(8)主机组配置文件
#vim hostgroups.cfg
(可选的项目,建立在文件hosts之上)
内容如下
define hostgroup { hostgroup_name sa-servers alias sa servers members nagios-server,24-25 //用逗号间隔多个主机 }所有的文件配置基本完成,现在来检查所有配置文件的正确性!!!!
#/usr/local/nagios/bin/nagios –v /usr/local/nagios/etc/nagios.cfg
正确的话,将会出现如下内容
Total Warnings: 0 Total Errors: 0 Things look okay - No serious problems were detected during the pre-flight check
问题总结:
1、最好将上面那些代码的所有注解都去掉或换行!
2、当出现如下错误时:
Error: Service notification command ‘notify-by-email’ specified for contact ‘sery’ is not defined anywhere! Error: Host notification command ‘host-notify-by-email’ specified for contact ‘sery’ is not defined anywhere!
请在commands.cfg中加入如下内容
# ‘notify-host-by-email’ command definition define command{ command_name host-notify-by-email command_line /usr/bin/printf “%b” “***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState:$HOSTSTATE$\nAddress: $HOSTADDRESS$\nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$\n” | /bin/mail -s “** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **” $CONTACTEMAIL$ } # ’service_notification_commands’ command definition define command{ command_name service-notify-by-email command_line /usr/bin/printf “%b” “***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$” | /bin/mail -s “** $NOTIFICATIONTYPE$ Service Alert: $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **” $CONTACTEMAIL$ }这样问题就会解决了!是因为command中没有定义那两个东东~~~~
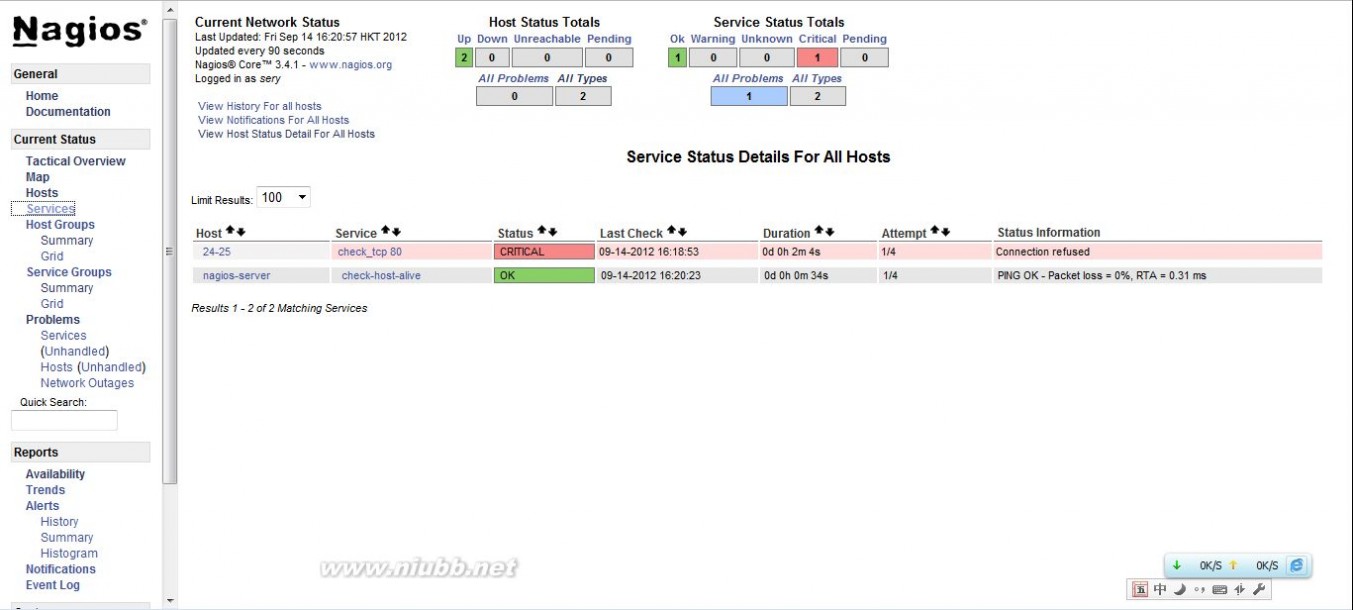
附一张结果图!
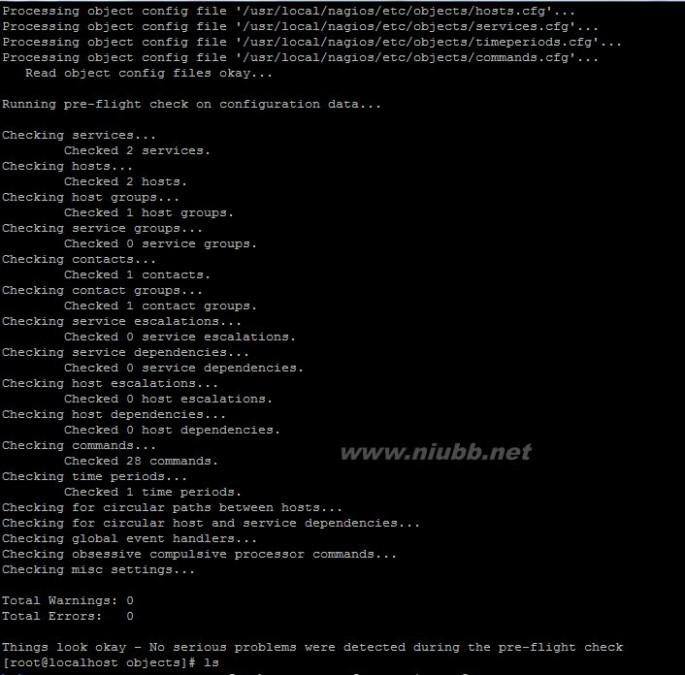
最后测试
打开本地浏览器输入输入 http://localhost/nagios,再输验证所需的用户名和密码,就可点击页面右边的相关连接来查看各种状态及管理它们了
试试在里面删除某些嗠,我们一会就会收到报警短信和报警邮件,然后在把测试所有的服务开启或把拔下来的网线查上去,片刻后,网页里的红色报警表格消失,手机短信或邮件通知故障恢复,如果你的情况也这样,那么真正大功告成
还有更多的内容可以去Nagios的官网去了解!http://www.nagios.com/
感想:花了很多很多的时间才搞掂,无语了!!!
问题1:
如果提示“You don't have permission to access /nagios/ on this server” 那绝对是你没有配置好php
#yum install -y php
问题2:
如果提示“Whoops! Error: Could not read object configuration data! ”,这是因为没有启动nagios后台进程,执行以下命令
扩展:nagios监控多台服务器 / nagios监控服务器进程 / nagios监控服务器
#/usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg
最好上传几张成功的图片!哈哈~~~~
文章参考:
文章参考:http://yahoon.blog.51cto.com/13184/41300
扩展:nagios监控多台服务器 / nagios监控服务器进程 / nagios监控服务器
三 : Zabbix 如何监控服务器硬件信息?
做为Linux系统工程师,在服务器的维护管理当中,除了对系统进行维护管理之外,最重要的还要对服务器的硬件进行监控,比如服务器Raid状态是否正常(如果Raid卡出问题,会影响数据的读写速度),服务器硬盘是否正常(如果硬盘坏掉,严重的情况会丢失数据),服务器电源是否有故障等。除此之外还要对服务器的CPU,内存,处理器等重要设备的温度进行监控,如果温度超过服务器的临界温度则进行报警通知。
HP的服务器在硬件管理方面提供了自己管理工具hpacucli,通过该工具可以查看HP服务器的RAID信息,服务器硬盘等信息。
1)安装hpacucli工具(下载地址:HP hpacucli管理工具)
- [root@monitor~]#rpm-ivhhpacucli-9.40-12.0.x86_64.rpm
2)查看服务器RAID信息,硬盘是否正常。
- [root@monitor~]#hpacuclictrlallshowconfig
- SmartArrayP410iinSlot0(Embedded)(sn:5001438018042FF0)
- arrayA(SAS,UnusedSpace:0MB)
- logicaldrive1(279.4GB,RAID1,OK)
- physicaldrive1I:1:1(port1I:box1:bay1,SAS,300GB,OK)
- physicaldrive1I:1:2(port1I:box1:bay2,SAS,300GB,OK)
3)通过hpacucli ctrl all show config detail命令可以详细地查看RAID和硬盘的信息。
- [root@monitor~]#hpacuclictrlallshowconfigdetail
- SmartArrayP410iinSlot0(Embedded)
- BusInterface:PCI
- Slot:0
- SerialNumber:5001438018042FF0
- CacheSerialNumber:PBCDH0CRH1FH62
- RAID6(ADG)Status:Disabled
- ControllerStatus:OK
- ChassisSlot:
- HardwareRevision:RevC
- FirmwareVersion:5.14
- RebuildPriority:Medium
- ExpandPriority:Medium
- SurfaceScanDelay:15secs
- MonitorandPerformanceDelay:60min
- ElevatorSort:Enabled
- DegradedPerformanceOptimization:Disabled
- InconsistencyRepairPolicy:Disabled
- PostPromptTimeout:0secs
- CacheBoardPresent:True
- CacheStatus:OK
- AcceleratorRatio:25%Read/75%Write
- DriveWriteCache:Disabled
- TotalCacheSize:512MB
- No-BatteryWriteCache:Disabled
- CacheBackupPowerSource:Capacitors
- Battery/CapacitorCount:1
- Battery/CapacitorStatus:OK
- SATANCQSupported:True
- Array:A
- InterfaceType:SAS
- UnusedSpace:0MB
- Status:OK
- LogicalDrive:1
- Size:279.4GB
- FaultTolerance:RAID1
- Heads:255
- SectorsPerTrack:32
- Cylinders:65535
- StripeSize:128KB
- Status:OK
- ArrayAccelerator:Enabled
- UniqueIdentifier:600508B1001034373220202020200002
- DiskName:/dev/cciss/c0d0
- MountPoints:/boot99MB
- LogicalDriveLabel:A00ADBD9PR7AMU1472898D
- MirrorGroup0:
- physicaldrive1I:1:1(port1I:box1:bay1,SAS,300GB,OK)
- MirrorGroup1:
- physicaldrive1I:1:2(port1I:box1:bay2,SAS,300GB,OK)
- physicaldrive1I:1:1
- Port:1I
- Box:1
- Bay:1
- Status:OK
- DriveType:DataDrive
- InterfaceType:SAS
- Size:300GB
- RotationalSpeed:10000
- FirmwareRevision:HPD4
- SerialNumber:ECA1PC80GTS31234
- Model:HPEG0300FBDSP
- PHYCount:2
- PHYTransferRate:6.0GBPS,Unknown
- physicaldrive1I:1:2
- Port:1I
- Box:1
- Bay:2
- Status:OK
- DriveType:DataDrive
- InterfaceType:SAS
- Size:300GB
- RotationalSpeed:10000
- FirmwareRevision:HPD7
- SerialNumber:PMX6902D
- Model:HPEG0300FBDBR
- PHYCount:2
- PHYTransferRate:6.0GBPS,Unknown
HP官方还有一个hpasmcli管理工具,可以很详细查看服务器CPU,内存,处理器,电源等的温度信息。
1)安装hpasmcli工具(下载地址:HP hpasmcli管理工具)
- [root@monitor~]#rpm-ivhhp-health-9.40-1602.44.rhel6.x86_64.rpm
2)通过工具hpasmcli可以查看服务器各部件的温度信息,其中Temp表示各部件当前的温度,Threshold表示临界温度,当当前温度超过临界温度的时候就要注意啦。
- [root@monitor~]#hpasmcli-s'showtemp'
- SensorLocationTempThreshold
- ---------------------------
- #1AMBIENT23C/73F42C/107F
- #2CPU#140C/104F82C/179F
- #3CPU#240C/104F82C/179F
- #4MEMORY_BD33C/91F87C/188F
- #5MEMORY_BD33C/91F78C/172F
- #6MEMORY_BD-87C/188F
- #7MEMORY_BD32C/89F78C/172F
- #8MEMORY_BD32C/89F87C/188F
- #9MEMORY_BD32C/89F78C/172F
- #10MEMORY_BD-87C/188F
- #11MEMORY_BD32C/89F78C/172F
- #12POWER_SUPPLY_BAY33C/91F59C/138F
- #13POWER_SUPPLY_BAY47C/116F73C/163F
- #14MEMORY_BD29C/84F72C/161F
- #15PROCESSOR_ZONE32C/89F73C/163F
- #16PROCESSOR_ZONE30C/86F64C/147F
- #17MEMORY_BD28C/82F63C/145F
- #18PROCESSOR_ZONE39C/102F69C/156F
- #19SYSTEM_BD35C/95F69C/156F
- #20SYSTEM_BD38C/100F71C/159F
- #21SYSTEM_BD44C/111F65C/149F
- #22SYSTEM_BD45C/113F71C/159F
- #23SYSTEM_BD39C/102F69C/156F
- #24SYSTEM_BD47C/116F69C/156F
- #25SYSTEM_BD35C/95F63C/145F
- #26SYSTEM_BD45C/113F66C/150F
- #27SCSI_BACKPLANE_ZONE35C/95F60C/140F
- #28SYSTEM_BD73C/163F110C/230F
3)通过hpasmcli -s 'show'查看类似于help的帮助信息,监控的时候要重点关注 DIMM(内存)、FANS(风扇)、POWERSUPPLY(电源模块)、SERVER(系统)、CPU、TEMP(温度)等信息。
- [root@monitor~]#hpasmcli-s'show'
- InvalidArguments
- SHOWASR
- SHOWBOOT
- SHOWDIMM[SPD]
- SHOWF1
- SHOWFANS
- SHOWHT
- SHOWIML
- SHOWIPL
- SHOWNAME
- SHOWPORTMAP
- SHOWPOWERMETER
- SHOWPOWERSUPPLY
- SHOWPXE
- SHOWSERIAL[BIOS|EMBEDDED|VIRTUAL]
- SHOWSERVER
- SHOWTEMP
- SHOWTPM
- SHOWUID
- SHOWWOL
4)hpasmcli几种常用的例子。
由于各种服务器的厂商不同,管理工具不同,因此Zabbix对服务器硬件方面没有很详细,全面的解决方案。之前dl528888写过zabbix通过omsa工具监控DEL服务器,也是一种很好的思路,我也借鉴过,这里非常感谢。
Zabbix监控总结起来有两种思路:第一就是server通过agentd方式获取数据,这种方式需要定义UserParameter参数,即KEY。第二就是server通过trapper的方式获取数据,即agentd将数据主动sender给server或者proxy。我这里是通过第二种traper的方式监控的。第一种方式server有时候会取不到数据:
- becamenotsupported:Receivedvalue[]isnotsuitableforvaluetype[Numeric(unsigned)]anddatatype[Decimal]
会产生上面的错误。
首先查看我监控的脚本,由于是通过traper的思路进行监控,log_file文件依次定义了要监控服务器的主机名(hostname),监控项key以及监控的值。
- [root@monitorscripts]#cathpacuclizabbix.sh
- #!/bin/sh
- #createbysfzhang20140517
- #ThisscriptsmonitoringHPserver,suchassmartarraystatus,Hardwareinformationandservertemperature。
- zabbix_server="*.*.*.*"#IPfromZabbixServerorproxywheredatashouldbesendto.
- zabbix_sender="/usr/local/zabbix/bin/zabbix_sender"
- log_file='/tmp/hpacuclizabbix.log'#Inthefiletodefinethemonitorhost,keyandvalue
- hpacucli='/usr/sbin/hpacucli'
- options='ctrlallshowconfigdetail'
- hpacucli_log="/tmp/result.log"
- PATH=$PATH:/usr/sbin:/sbin
- ${hpacucli}${options}>${hpacucli_log}
- Cache_status=`cat${hpacucli_log}|awk'/CacheStatus:/{print$NF}'`
- Controller_status=`cat${hpacucli_log}|awk'/ControllerStatus:/{print$NF}'`
- Battery_capacitor_status=`cat${hpacucli_log}|awk'/Battery\/CapacitorStatus:/{print$NF}'`
- Physicaldrive_status=$(awk-vtotal=`hpacuclictrlslot=0pdallshowstatus|grepphysicaldrive|wc-l`-vnormal=`hpacuclictrlslot=0pdallshowstatus|awk'/physicaldrive/{if($NF=="OK")count+=1}END{printcount}'`'BEGIN{if(total==normal){print"OK"}else{print"NO"}}')
- Memory_status=$(awk-vtotal=`hpasmcli-s'SHOWDIMM'|grep-i'Status'|wc-l`-vnormal=`hpasmcli-s'SHOWDIMM'|awk'/Status:/{if($NF=="Ok")count+=1}END{printcount}'`'BEGIN{if(total==normal){print"OK"}else{print"NO"}}')
- Fans_status=$(awk-vtotal=`hpasmcli-s'SHOWFANS'|grep"#"|wc-l`-vnormal=`hpasmcli-s'SHOWFANS'|awk'/#/{if($3=="Yes")count+=1}END{printcount}'`'BEGIN{if(total==normal){print"OK"}else{print"NO"}}')
- Power_status=$(awk-vtotal=`hpasmcli-s'SHOWPOWERSUPPLY'|grep"Powersupply"|wc-l`-vnormal=`hpasmcli-s'SHOWPOWERSUPPLY'|awk'/Condition:/{if($NF=="Ok")count+=1}END{printcount}'`'BEGIN{if(total==normal){print"OK"}else{print"NO"}}')
- Processor_status=$(awk-vtotal=`hpasmcli-s'SHOWSERVER'|grep"Processor:"|wc-l`-vnormal=`hpasmcli-s'SHOWSERVER'|awk'/Status/{if($NF=="Ok")count+=1}END{printcount}'`'BEGIN{if(total==normal){print"OK"}else{print"NO"}}')
- Power_temp_num=$(hpasmcli-s'SHOWTEMP'|awk'/POWER_SUPPLY_BAY/{print$3}'|awk-F"C"'{print$1}'|awk'BEGIN{max=0}{if($1>max)max=$1fi}END{printmax}')
- Ambient_temp_num=$(hpasmcli-s'SHOWTEMP'|awk'/AMBIENT/{print$3}'|awk-F"C"'{print$1}')
- Cpu_temp_num=$(hpasmcli-s'SHOWTEMP'|awk'/CPU/{print$3}'|awk-F"C"'{print$1}'|awk'BEGIN{max=0}{if($1>max)max=$1fi}END{printmax}')
- Memory_temp_num=$(hpasmcli-s'SHOWTEMP'|awk'/MEMORY_BD/{print$3}'|awk-F"C"'{print$1}'|awk'BEGIN{max=0}{if($1>max)max=$1fi}END{printmax}')
- System_temp_num=$(hpasmcli-s'SHOWTEMP'|awk'/SYSTEM_BD/{print$3}'|awk-F"C"'{print$1}'|awk'BEGIN{max=0}{if($1>max)max=$1fi}END{printmax}')
- Processor_temp_num=$(hpasmcli-s'SHOWTEMP'|awk'/PROCESSOR_ZONE/{print$3}'|awk-F"C"'{print$1}'|awk'BEGIN{max=0}{if($1>max)max=$1fi}END{printmax}')
- echo$HOSTNAMEhp_smart_array.cache_status$Cache_status>${log_file}
- echo$HOSTNAMEhp_smart_array.controller_status$Controller_status>>${log_file}
- echo$HOSTNAMEhp_smart_array.battery_capacitor_status$Battery_capacitor_status>>${log_file}
- echo$HOSTNAMEhp_hardware.hpysicaldrive_status$Physicaldrive_status>>${log_file}
- echo$HOSTNAMEhp_hardware.memory_status$Memory_status>>${log_file}
- echo$HOSTNAMEhp_hardware.fans_status$Fans_status>>${log_file}
- echo$HOSTNAMEhp_hardware.power_status$Power_status>>${log_file}
- echo$HOSTNAMEhp_hardware.processor_status$Processor_status>>${log_file}
- echo$HOSTNAMEhp_power.temp_num$Power_temp_num>>${log_file}
- echo$HOSTNAMEhp_ambient.temp_num$Ambient_temp_num>>${log_file}
- echo$HOSTNAMEhp_cpu.temp_num$Cpu_temp_num>>${log_file}
- echo$HOSTNAMEhp_memory.temp_num$Memory_temp_num>>${log_file}
- echo$HOSTNAMEhp_system.temp_num$System_temp_num>>${log_file}
- echo$HOSTNAMEhp_processor.temp_num$Processor_temp_num>>${log_file}
- $zabbix_sender-z$zabbix_server-i${log_file}>/tmp/zabbix.temp
最后只需开启crontab,5分钟运行一次。
- [root@monitor~]echo"*/5****/etc/zabbix/scripts/hpacuclizabbix.sh">>/var/spool/cron/root
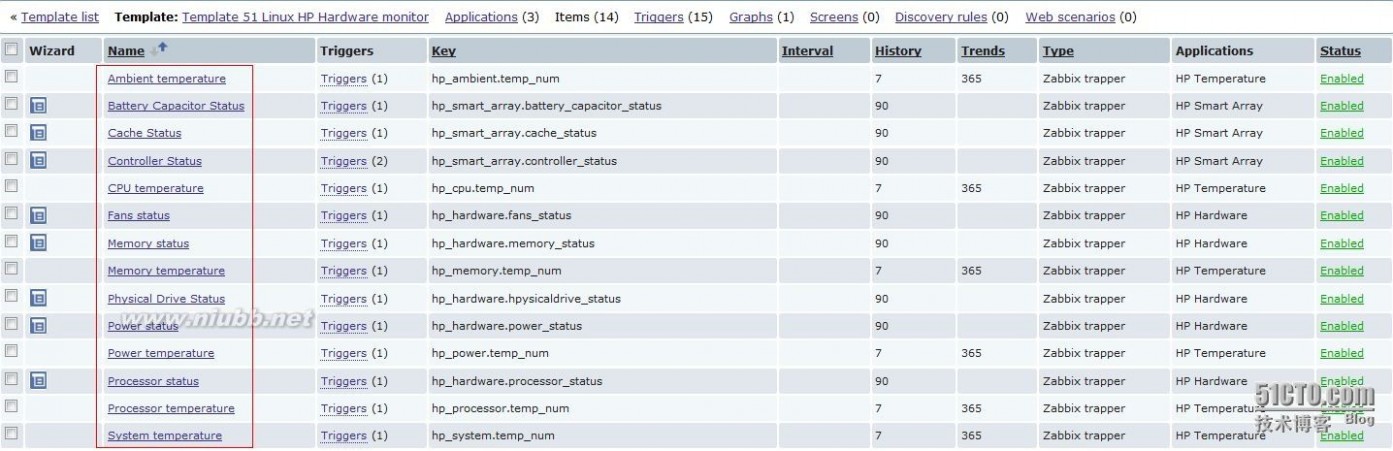
查看zabbix监控HP服务器硬件KEY的定义,数据的收集都是通过trapper的方式收集的。
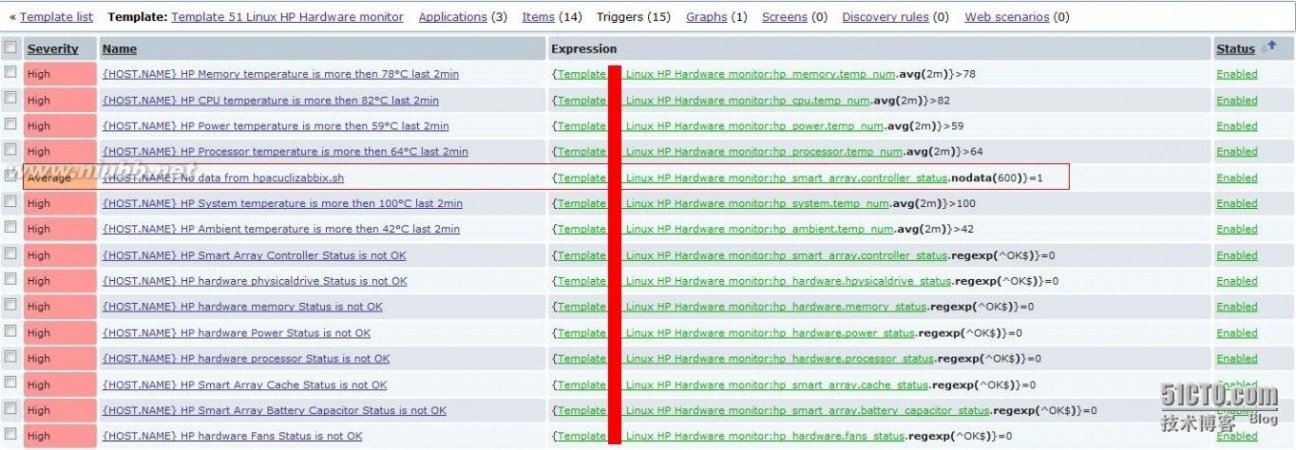
查看zabbix监控HP服务器硬件triggers定义,其中nodata(600)这个trigger是为了防止被监控端数据采集出问题而设置的,比如crontab不正常,脚本被误删除等等。如果server10分钟之内收集不到被监控端的数据就会报警。
在zabbix server lastdata查看zabbix server 通过trapper收到的数据。
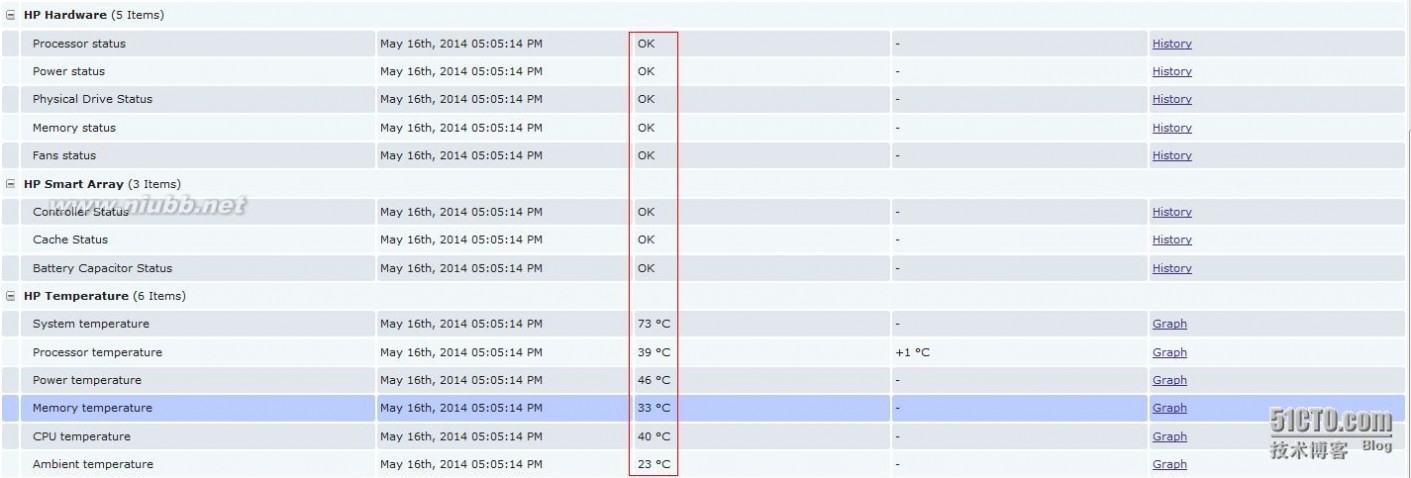
查看被监控端服务器各部件温度信息。
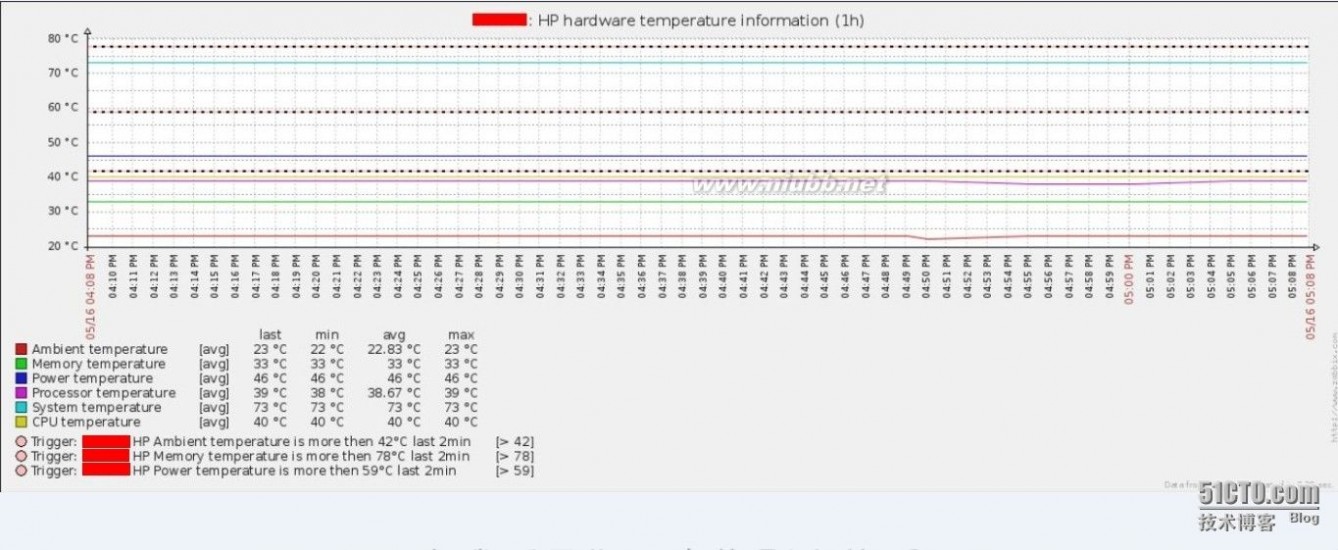
当被监控端出问题时Zabbix会及时报警。

说明:Zabbix监控HP服务器硬件操作方法:
1)在HP服务器上面安装hpacucli和hpasmcli管理工具。
2)修改hpacuclizabbix.sh脚本的zabbix_server ip地址,指定为自己的server或者proxy的地址,并把该脚本添加到crontab。
3)导入附件中的模板,Link到要监控的主机上面即可。
4)如果有其它问题,欢迎多多交流。
本文标题:服务器监控软件-服务器监控6120c手机软件61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1