一 : 人工神经网络
人工神经网络( Artificial Neural Networks, 简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connectionist Model)
人工神经网络( Artificial Neural Networks, 简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connectionist Model),是对人脑或自然神经网络(Natural Neural Network)若干基本特性的抽象和模拟。人工神经网络以对大脑的生理研究成果为基础的,其目的在于模拟大脑的某些机理与机制,实现某个方面的功能。国际著名的神经网络研究专家,第一家神经计算机公司的创立者与领导人Hecht Nielsen给人工神经网络下的定义就是:“人工神经网络是由人工建立的以有向图为拓扑结构的动态系统,它通过对连续或断续的输入作状态相应而进行信息处理。” 这一定义是恰当的。 人工神经网络的研究,可以追溯到 1957年Rosenblatt提出的感知器模型(Perceptron) 。它几乎与人工智能——AI(Artificial Intelligence)同时起步,但30余年来却并未取得人工智能那样巨大的成功,中间经历了一段长时间的萧条。直到80年代,获得了关于人工神经网络切实可行的算法,以及以Von Neumann体系为依托的传统算法在知识处理方面日益显露出其力不从心后,人们才重新对人工神经网络发生了兴趣,导致神经网络的复兴。 目前在神经网络研究方法上已形成多个流派,最富有成果的研究工作包括:多层网络BP算法,Hopfield网络模型,自适应共振理论,自组织特征映射理论等。人工神经网络是在现代神经科学的基础上提出来的。它虽然反映了人脑功能的基本特征,但远不是自然神经网络的逼真描写,而只是它的某种简化抽象和模拟。
。www.61k.com”人工神经网络的以下几个突出的优点使它近年来引起人们的极大关注:
(1)可以充分逼近任意复杂的非线性关系;
(2)所有定量或定性的信息都等势分布贮存于网络内的各神经元,故有很强的鲁棒性和容错性;
(3)采用并行分布处理方法,使得快速进行大量运算成为可能;
(4)可学习和自适应不知道或不确定的系统;
(5)能够同时处理定量、定性知识。
人工神经网络的特点和优越性,主要表现在三个方面:
第一,具有自学习功能。例如实现图像识别时,只在先把许多不同的图像样板和对应的应识别的结果输入人工神经网络,网络就会通过自学习功能,慢慢学会识别类似的图像。自学习功能对于预测有特别重要的意义。预期未来的人工神经网络计算机将为人类提供经济预测、市场预测、效益预测,其应用前途是很远大的。
第二,具有联想存储功能。用人工神经网络的反馈网络就可以实现这种联想。
第三,具有高速寻找优化解的能力。寻找一个复杂问题的优化解,往往需要很大的计算量,利用一个针对某问题而设计的反馈型人工神经网络,发挥计算机的高速运算能力,可能很快找到优化解。
神经网络的研究可以分为理论研究和应用研究两大方面。
理论研究可分为以下两类:
1).利用神经生理与认知科学研究人类思维以及智能机理。
2).利用神经基础理论的研究成果,用数理方法探索功能更加完善、性能更加优越的神经网络模型,深入研究网络算法和性能, 如:稳定性、收敛性、容错性、鲁棒性等;开发新的网络数理理论,如:神经网络动力学、非线性神经场等。
应用研究可分为以下两类:
1).神经网络的软件模拟和硬件实现的研究。
2).神经网络在各个领域中应用的研究。这些领域主要包括:
模式识别、信号处理、知识工程、专家系统、优化组合、机器人控制等。 随着神经网络理论本身以及相关理论、相关技术的不断发展,神经网络的应用定将更加深入。
神经网络近来越来越受到人们的关注,因为它为解决大复杂度问题提供了一种相对来说比较有效的简单方法。神经网络可以很容易的解决具有上百个参数的问题(当然实际生物体中存在的神经网络要比我们这里所说的程序模拟的神经网络要复杂的多)。神经网络常用于两类问题:分类和回归。
在结构上,可以把一个神经网络划分为输入层、输出层和隐含层(见图1)。输入层的每个节点对应一个个的预测变量。输出层的节点对应目标变量,可有多个。在输入层和输出层之间是隐含层(对神经网络使用者来说不可见),隐含层的层数和每层节点的个数决定了神经网络的复杂度。
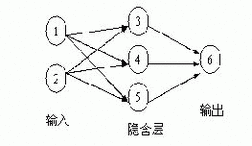
图1 一个神经元网络
除了输入层的节点,神经网络的每个节点都与很多它前面的节点(称为此节点的输入节点)连接在一起,每个连接对应一个权重Wxy,此节点的值就是通过它所有输入节点的值与对应连接权重乘积的和作为一个函数的输入而得到,我们把这个函数称为活动函数或挤压函数。如图2中节点4输出到节点6的值可通过如下计算得到:
W14*节点1的值+W24*节点2的值
神经网络的每个节点都可表示成预测变量(节点1,2)的值或值的组合(节点3-6)。注意节点6的值已经不再是节点1、2的线性组合,因为数据在隐含层中传递时使用了活动函数。实际上如果没有活动函数的话,神经元网络就等价于一个线性回归函数,如果此活动函数是某种特定的非线性函数,那神经网络又等价于逻辑回归。
调整节点间连接的权重就是在建立(也称训练)神经网络时要做的工作。最早的也是最基本的权重调整方法是错误回馈法,现在较新的有变化坡度法、类牛顿法、Levenberg-Marquardt法、和遗传算法等。无论采用那种训练方法,都需要有一些参数来控制训练的过程,如防止训练过度和控制训练的速度。

图2 带权重Wxy的神经元网络
决定神经网络拓扑结构(或体系结构)的是隐含层及其所含节点的个数,以及节点之间的连接方式。要从头开始设计一个神经网络,必须要决定隐含层和节点的数目,活动函数的形式,以及对权重做那些限制等,当然如果采用成熟软件工具的话,他会帮你决定这些事情。
在诸多类型的神经网络中,最常用的是前向传播式神经网络,也就是我们前面图示中所描绘的那种。我们下面详细讨论一下,为讨论方便假定只含有一层隐含节点。
可以认为错误回馈式训练法是变化坡度法的简化,其过程如下:
前向传播:数据从输入到输出的过程是一个从前向后的传播过程,后一节点的值通过它前面相连的节点传过来,然后把值按照各个连接权重的大小加权输入活动函数再得到新的值,进一步传播到下一个节点。
回馈:当节点的输出值与我们预期的值不同,也就是发生错误时,神经网络就要 “学习”(从错误中学习)。我们可以把节点间连接的权重看成后一节点对前一节点的“信任” 程度(他自己向下一节点的输出更容易受他前面哪个节点输入的影响)。学习的方法是采用惩罚的方法,过程如下:如果一节点输出发生错误,那么他看他的错误是受哪个(些)输入节点的影响而造成的,是不是他最信任的节点(权重最高的节点)陷害了他(使他出错),如果是则要降低对他的信任值(降低权重),惩罚他们,同时升高那些做出正确建议节点的信任值。对那些收到惩罚的节点来说,他也需要用同样的方法来进一步惩罚它前面的节点。就这样把惩罚一步步向前传播直到输入节点为止。
对训练集中的每一条记录都要重复这个步骤,用前向传播得到输出值,如果发生错误,则用回馈法进行学习。当把训练集中的每一条记录都运行过一遍之后,我们称完成一个训练周期。要完成神经网络的训练可能需要很多个训练周期,经常是几百个。训练完成之后得到的神经网络就是在通过训练集发现的模型,描述了训练集中响应变量受预测变量影响的变化规律。
由于神经网络隐含层中的可变参数太多,如果训练时间足够长的话,神经网络很可能把训练集的所有细节信息都“记”下来,而不是建立一个忽略细节只具有规律性的模型,我们称这种情况为训练过度。显然这种“模型”对训练集会有很高的准确率,而一旦离开训练集应用到其他数据,很可能准确度急剧下降。为了防止这种训练过度的情况,我们必须知道在什么时候要停止训练。在有些软件实现中会在训练的同时用一个测试集来计算神经网络在此测试集上的正确率,一旦这个正确率不再升高甚至开始下降时,那么就认为现在神经网络已经达到做好的状态了可以停止训练。
图3中的曲线可以帮我们理解为什么利用测试集能防止训练过度的出现。在图中可以看到训练集和测试集的错误率在一开始都随着训练周期的增加不断降低,而测试集的错误率在达到一个谷底后反而开始上升,我们认为这个开始上升的时刻就是应该停止训练的时刻。
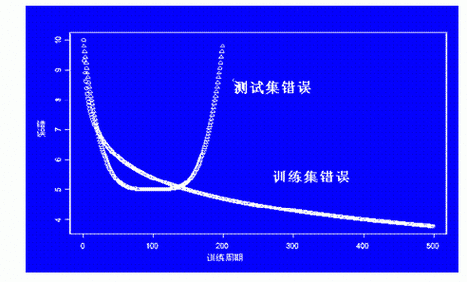
图3 神经网络在训练周期增加时准确度的变化情况
神经元网络和统计方法在本质上有很多差别。神经网络的参数可以比统计方法多很多。如图1中就有13个参数(9个权重和4个限制条件)。由于参数如此之多,参数通过各种各样的组合方式来影响输出结果,以至于很难对一个神经网络表示的模型做出直观的解释。实际上神经网络也正是当作“黑盒”来用的,不用去管 “盒子”里面是什么,只管用就行了。在大部分情况下,这种限制条件是可以接受的。比如银行可能需要一个笔迹识别软件,但他没必要知道为什么这些线条组合在一起就是一个人的签名,而另外一个相似的则不是。在很多复杂度很高的问题如化学试验、机器人、金融市场的模拟、和语言图像的识别,等领域神经网络都取得了很好的效果。
神经网络的另一个优点是很容易在并行计算机上实现,可以把他的节点分配到不同的CPU上并行计算。
在使用神经网络时有几点需要注意:第一,神经网络很难解释,目前还没有能对神经网络做出显而易见解释的方法学。
第二,神经网络会学习过度,在训练神经网络时一定要恰当的使用一些能严格衡量神经网络的方法,如前面提到的测试集方法和交叉验证法等。这主要是由于神经网络太灵活、可变参数太多,如果给足够的时间,他几乎可以“记住”任何事情。
第三,除非问题非常简单,训练一个神经网络可能需要相当可观的时间才能完成。当然,一旦神经网络建立好了,在用它做预测时运行时还是很快得。
第四,建立神经网络需要做的数据准备工作量很大。一个很有误导性的神话就是不管用什么数据神经网络都能很好的工作并做出准确的预测。这是不确切的,要想得到准确度高的模型必须认真的进行数据清洗、整理、转换、选择等工作,对任何数据挖掘技术都是这样,神经网络尤其注重这一点。比如神经网络要求所有的输入变量都必须是0-1(或-1 -- +1)之间的实数,因此像“地区”之类文本数据必须先做必要的处理之后才能用作神经网络的输入。
二 : 人工神经网络简单介绍_胖子大侠
人工神经网络的概念:人工神经网络(Artificial Neural Networks,ANN),1种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。人工神经网络具有自学习和自适应的能力,可以通过预先提供的一批相互对应的输入-输出数据,分析掌握两者之间潜在的规律,最终根据这些规律,用新的输入数据来推算输出结果,这种学习分析的过程被称为“训练”。(引自《环球科学》2007年第一期《神经语言:老鼠胡须下的秘密》)。它是由大量处理单元互联组成的非线性、自适应信息处理系统。它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。
基本特征:并行处理、自适应性、自组织性、自学习性和联想记忆及鲁棒性。(石 英,郭靖芬,基于理想方案的BP神经网络土地利用规划方案评价【J】,南昌大学学报,2008.2)
鲁棒性:鲁棒性就是系统的健壮性。它是在异常和危险情况下系统生存的关键。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,是指控制系统在一定(结构,大小)的参数摄动下,维持某些性能的特性。根据对性能的不同定义,可分为稳定鲁棒性和性能鲁棒性。以闭环系统的鲁棒性作为目标设计得到的固定控制器称为鲁棒控制器。
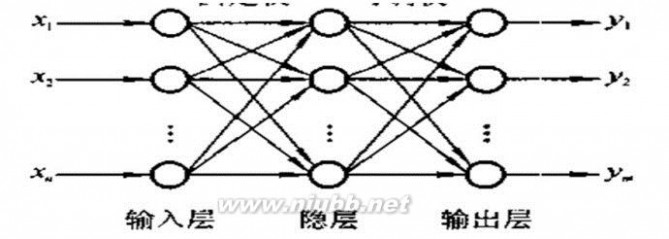
神经元处理单元:网络中处理单元的类型分为3类:输入单元、输出单元和隐单元。输入单元接受外部世界的信号与数据;输出单元实现系统处理结果的输出;隐单元是处在输入和输出单元之间,不能由系统外部观察的单元。
生物神经网络:
生物神经网络的6个特性:
[www.61k.com)
软件:MatLab软件
神经网络的模型:BP模型,该模型是1986年由Rumelhart提出的。
(吴承祯、洪伟、何东进,桤柏混交林密度变化规律的人工神经网络模型研究【J】,西北植物学报,1999)
反向传播模型又叫反向传播神经网络或BP模型,它是1种前馈型人工神经网络。由于含有1个隐层的神经网络可以逼近任何连续函数,所以这里只考虑含有1个隐层的反向传播神经网络(简称BP网)。BP网的信息传播方向是前馈的,即从输入层→隐含层→输出层。它的结构是分层次的,各层次的神经元之间形成全互连接,各层次内的神经元之间没有连接。
对于输入层的神经元,其输出与输入相同。如对神经元i,输入为xi,输出为ui,则ui=xi。
对于隐含层和输出层的神经元,其输入和输出关系为:
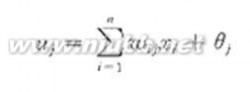 (1)
(1)
式中:wij为神经元i与神经元j的连接权;θj为阈值。
yj=f(uj)=1/[1+exp(-uj)] (2)
式中:yj为神经元j的输出(状态值);f(.)为映射函数,其形式取为
yj=1/[1+exp(-uj)]
yj在区间[0,1]上取值,由于
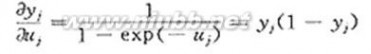 (3)
(3)
当yj→0或yj→1时,yj/uj最小,即yj对uj的变化率最小;当yj→1/2时,yj对uj的变化率最大。
以下称输入层和隐含层神经元的连接权为第一连接权,称隐含层和输出层神经元的连接权为第二层连接权,连接权和阈值统称为权值。
BP学习算法
BP算法是有导师的δ学习律:
在对BP网进行训练时,首先要提供一组学习样本(x1,x2,…,xp),与相对应的教师(理想输出)为(t1,t2,…,tp)。当网络的所有实际输出与理想输出一致时,表明训练结束,否则通过实际输出与理想输出的误差来修改连接权值与相应的阈值。
BP学习算法如下:
(1)对权值进行初始化,即随机地给全部权值赋以初始值(很小的随机数);
(2)在已知P个学习样本中,顺序地将其输入BP网中,并输入相应的教师;
(3)按(1)式和(2)式计算实际输出yk;
(4)计算每次学习的误差(tkp-ykp)和总的误差E。
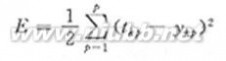 (4)
(4)
(5)修改权值;
(6)按新权值重新计算,直到达到误差精度要求为止,否则回到(2);
BP算法对权值的修改采用梯度法,即使总误差不断减小。反向调整连接权值wij和阈值θj修正量的第n+1次迭代算式为:
 (5)
(5)
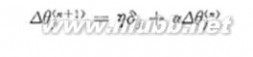 (6)
(6)
61阅读| 精彩专题| 最新文章| 热门文章| 苏ICP备13036349号-1